vit explain
1.0.0
Repositori ini mengimplementasikan metode untuk dijelaskan dalam transformator penglihatan.
Lihat juga https://jacobgil.github.io/deEplearning/vision-transformer-explainability
Peluncuran perhatian.
Peluncuran Perhatian Gradien untuk Penjelasan Khusus Kelas. Ini adalah upaya kami untuk membangun lebih lanjut dan meningkatkan peluncuran perhatian.
Aliran perhatian TBD sedang dalam proses.
Termasuk beberapa tweak dan trik untuk membuatnya berfungsi:
from vit_grad_rollout import VITAttentionGradRollout
model = torch . hub . load ( 'facebookresearch/deit:main' ,
'deit_tiny_patch16_224' , pretrained = True )
grad_rollout = VITAttentionGradRollout ( model , discard_ratio = 0.9 , head_fusion = 'max' )
mask = grad_rollout ( input_tensor , category_index = 243 ) python vit_explain.py --image_path <image path> --head_fusion <mean, min or max> --discard_ratio <number between 0 and 1> --category_index <category_index>
Jika Category_index tidak ditentukan, peluncuran perhatian akan digunakan, jika tidak, peluncuran perhatian gradien akan digunakan.
Perhatikan bahwa secara default, ini menggunakan model 'mungil' dari pelatihan transformator gambar yang efisien data & distilasi melalui perhatian yang di-host pada Torch Hub.
| Gambar | Peluncuran perhatian vanilla | Dengan Decard_Ratio+Max Fusion |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |
 |  |  |
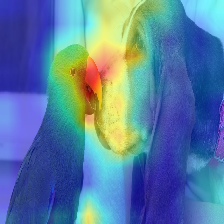
Perhatian yang mengalir dalam transformator melewati informasi milik kelas yang berbeda. Gradient Roll out memungkinkan kami melihat lokasi apa yang diperhatikan jaringan juga, tetapi itu tidak memberi tahu kami apa -apa jika akhirnya menggunakan lokasi tersebut untuk klasifikasi akhir.
Kami dapat melipatgandakan perhatian dengan gradien output kelas target, dan mengambil rata -rata di antara kepala perhatian (sambil menutupi perhatian negatif) untuk hanya menjaga perhatian yang berkontribusi pada kategori target (atau kategori).




--discard_ratio <value between 0 and 1>
Menghapus kebisingan dengan menjaga perhatian terkuat.
Hasil untuk nilai yang berbeda:


Metode peluncuran perhatian menunjukkan bahwa perhatian rata -rata mengakses perhatian kepala,
Tapi secara emperis sepertinya mengambil nilai minimum, atau nilai maksimum yang dikombinasikan dengan --Scard_ratio, bekerja lebih baik.
--head_fusion <mean, min or max>
| Gambar | Berarti fusi | Fusion min |
|---|---|---|
| |  |
Mengukur aliran perhatian dalam transformator
Timm: Kumpulan model yang hebat di Pytorch dan khususnya implementasi Vision Transformer
Sebuah gambar bernilai 16x16 kata: transformer untuk pengenalan gambar pada skala
Kredit untuk https://github.com/jeonsworld/vit-pytorch karena menjadi titik awal yang baik.
pip install timm


