vit explain
1.0.0
Этот репозиторий реализует методы объяснения в трансформаторах зрения.
См. Также https://jacobgil.github.io/deeplearning/vision-transformer- Исполнение
Внимание развертывания.
Градиент внимания развертывание для конкретного класса объясняемость. Это наша попытка дальнейшего развития и улучшить развертывание внимания.
Поток внимания TBD находится в стадии разработки.
Включает в себя некоторые изменения и уловки, чтобы заставить его работать:
from vit_grad_rollout import VITAttentionGradRollout
model = torch . hub . load ( 'facebookresearch/deit:main' ,
'deit_tiny_patch16_224' , pretrained = True )
grad_rollout = VITAttentionGradRollout ( model , discard_ratio = 0.9 , head_fusion = 'max' )
mask = grad_rollout ( input_tensor , category_index = 243 ) python vit_explain.py --image_path <image path> --head_fusion <mean, min or max> --discard_ratio <number between 0 and 1> --category_index <category_index>
Если Category_index не указан, будет использоваться развертывание внимания, в противном случае будет использоваться развертывание внимания градиента.
Обратите внимание, что по умолчанию это использует «крошечную» модель из обучающих данных, эффективных данных и дистилляции изображений, с помощью внимания, размещенного в факеле.
| Изображение | Ванильный развертывание внимания | С Discard_Ratio+Max Fusion |
|---|---|---|
 |  |  |
 |  |  |
 |  | 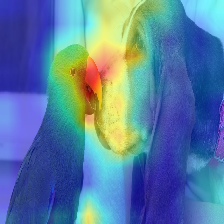 |
 |  |  |
Внимание, которое течет в трансформаторе, передает информацию, принадлежащую различным классам. Gradient Rollout позволяет нам увидеть, в каких местах сеть тоже обращала внимание, но она ничего не говорит о том, если она в конечном итоге использует эти местоположения для окончательной классификации.
Мы можем умножить внимание на градиент вывода целевого класса и принять среднее значение среди голов внимания (при маскировке негативного внимания), чтобы сохранить только внимание, которое способствует целевой категории (или категориям).




--discard_ratio <value between 0 and 1>
Удаляет шум, сохраняя самое сильное внимание.
Результаты для разных значений:


Метод развертывания внимания предполагает привлечение среднего внимания, уделяя внимания головы,
Но императивно похоже на минимальное значение или максимальное значение в сочетании с -discard_ratio, работает лучше.
--head_fusion <mean, min or max>
| Изображение | Среднее слияние | Мин слияние |
|---|---|---|
| |  |
Количественная оценка потока внимания в трансформаторах
Тимм: отличная коллекция моделей в Pytorch и особенно реализация Vision Transformer
Изображение стоит 16x16 слов: трансформаторы для распознавания изображений в масштабе
Кредит для https://github.com/jeonsworld/vit-pytorch за хорошую отправную точку.
pip install timm


