vit explain
1.0.0
Este repositório implementa métodos para explicar os transformadores de visão.
Consulte também https://jacobgil.github.io/deeplearning/vision-transformer-xplainability
ATENÇÃO DO ATENÇÃO.
Atenção de gradiente para explicar a explicação específica da classe. Esta é a nossa tentativa de desenvolver e melhorar ainda mais a atenção.
O fluxo de atenção da TBD está em andamento.
Inclui alguns ajustes e truques para que ele funcione:
from vit_grad_rollout import VITAttentionGradRollout
model = torch . hub . load ( 'facebookresearch/deit:main' ,
'deit_tiny_patch16_224' , pretrained = True )
grad_rollout = VITAttentionGradRollout ( model , discard_ratio = 0.9 , head_fusion = 'max' )
mask = grad_rollout ( input_tensor , category_index = 243 ) python vit_explain.py --image_path <image path> --head_fusion <mean, min or max> --discard_ratio <number between 0 and 1> --category_index <category_index>
Se category_index não for especificado, será usado o lançamento de atenção, caso contrário, será usado o lançamento de atenção do gradiente.
Observe que, por padrão, isso usa o modelo 'minúsculo' de transformadores de imagem com eficiência de dados e destilação com eficiência de dados através da atenção hospedada no hub da tocha.
| Imagem | Atenção de baunilha | Com descarte_ratio+max fusion |
|---|---|---|
 |  |  |
 |  |  |
 |  | 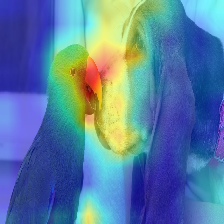 |
 |  |  |
A atenção que flui no transformador passa ao longo de informações pertencentes a diferentes classes. O GRADIENT ROLL Out permite ver quais locais a rede também prestou atenção, mas não nos diz nada se acabou usando esses locais para a classificação final.
Podemos multiplicar a atenção com o gradiente da saída da classe alvo e levar a média entre as cabeças de atenção (enquanto mascaram as atenções negativas) para manter apenas a atenção que contribui para a categoria de destino (ou categorias).




--discard_ratio <value between 0 and 1>
Remove o barulho, mantendo as atenções mais fortes.
Resultados para diferentes valores:


O método de atendimento de atenção sugere levar a atenção média que aceita as cabeças de atenção,
Mas empericamente parece que assumir o valor mínimo, ou o valor máximo combinado com - -Discard_ratio, funciona melhor.
--head_fusion <mean, min or max>
| Imagem | Fusão média | Min Fusion |
|---|---|---|
| |  |
Quantificando o fluxo de atenção nos transformadores
Timm: Uma ótima coleção de modelos em Pytorch e especialmente a implementação do Transformador de visão
Uma imagem vale 16x16 palavras: transformadores para reconhecimento de imagem em escala
Crédito para https://github.com/jeonsworld/vit-pytorch por ser um bom ponto de partida.
pip install timm


