vit explain
1.0.0
Dieses Repository implementiert Methoden zur Erklärung bei Sehtransformatoren.
Siehe auch https://jacobgil.github.io/deeplearning/vision-transformer- explainability
Aufmerksamkeit Rollout.
Gradienten -Aufmerksamkeitsrollout für die klassenspezifische Erklärung. Dies ist unser Versuch, weiter aufzubauen und die Aufmerksamkeitsanpassung zu verbessern.
Der Aufmerksamkeitsfluss ist in Arbeit.
Beinhaltet einige Verbesserungen und Tricks, um es zum Laufen zu bringen:
from vit_grad_rollout import VITAttentionGradRollout
model = torch . hub . load ( 'facebookresearch/deit:main' ,
'deit_tiny_patch16_224' , pretrained = True )
grad_rollout = VITAttentionGradRollout ( model , discard_ratio = 0.9 , head_fusion = 'max' )
mask = grad_rollout ( input_tensor , category_index = 243 ) python vit_explain.py --image_path <image path> --head_fusion <mean, min or max> --discard_ratio <number between 0 and 1> --category_index <category_index>
Wenn Category_index nicht angegeben ist, wird die Aufmerksamkeitsrollout verwendet, andernfalls wird die Aufmerksamkeitsrollout für die Aufmerksamkeitsgrade verwendet.
Beachten Sie, dass dies standardmäßig das "Tiny" -Modell aus dem Training dateneffizienten Bildtransformatoren und Destillation durch Aufmerksamkeit verwendet, die auf dem Torch Hub gehostet werden.
| Bild | Vanille -Aufmerksamkeitsrollout | Mit Decard_ratio+Max Fusion |
|---|---|---|
 |  |  |
 |  |  |
 |  | 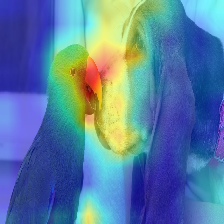 |
 |  |  |
Die Aufmerksamkeit, die im Transformator fließt, geht entlang von Informationen zu verschiedenen Klassen. Lassen Sie uns durch den Gradient Roll Out sehen, an welchen Standorten auch das Netzwerk aufmerksam geachtet hat, aber es sagt uns nichts darüber aus, ob es diese Standorte für die endgültige Klassifizierung verwendet hat.
Wir können die Aufmerksamkeit mit dem Gradienten der Zielklassenausgabe multiplizieren und den Durchschnitt unter den Aufmerksamkeitsköpfen (gleichzeitig negative Dehnung abmask), um nur die Aufmerksamkeit zu halten, die zur Zielkategorie (oder Kategorien) beiträgt.




--discard_ratio <value between 0 and 1>
Entfernt Lärm, indem Sie die stärksten Aufmerksamkeiten behalten.
Ergebnisse für verschiedene Werte:


Die Aufmerksamkeits -Rollout -Methode legt nahe, dass die durchschnittliche Aufmerksamkeit die Aufmerksamkeitsköpfe auf sich zieht.
Aber kaiserlich sieht es so aus, als würde man den Mindestwert oder den Maximalwert in Kombination mit -Discard_ratio, besser funktioniert.
--head_fusion <mean, min or max>
| Bild | Mittelwerte | Min Fusion |
|---|---|---|
| |  |
Aufmerksamkeitsfluss bei Transformatoren quantifizieren
Timm: Eine großartige Sammlung von Modellen in Pytorch und insbesondere in der Implementierung von Vision Transformer
Ein Bild ist 16x16 Wörter wert: Transformatoren für die Bilderkennung im Maßstab
Gutschrift für https://github.com/jeonsworld/vit-pytorch für ein guter Ausgangspunkt.
pip install timm


