vit explain
1.0.0
ที่เก็บนี้ใช้วิธีการอธิบายความสามารถในการมองเห็น
ดูเพิ่มเติมที่ https://jacobgil.github.io/deeplearning/vision-transformer-explainability
ความสนใจเปิดตัว
ความสนใจในการไล่ระดับความสนใจสำหรับการอธิบายเฉพาะชั้นเรียน นี่คือความพยายามของเราในการสร้างและปรับปรุงการเปิดตัวความสนใจ
การไหลของความสนใจของ TBD กำลังดำเนินการอยู่
รวมถึงการปรับแต่งและเทคนิคบางอย่างเพื่อให้มันทำงานได้:
from vit_grad_rollout import VITAttentionGradRollout
model = torch . hub . load ( 'facebookresearch/deit:main' ,
'deit_tiny_patch16_224' , pretrained = True )
grad_rollout = VITAttentionGradRollout ( model , discard_ratio = 0.9 , head_fusion = 'max' )
mask = grad_rollout ( input_tensor , category_index = 243 ) python vit_explain.py --image_path <image path> --head_fusion <mean, min or max> --discard_ratio <number between 0 and 1> --category_index <category_index>
หากไม่ได้ระบุ category_index จะมีการใช้การเปิดตัวความสนใจมิฉะนั้นจะใช้การเปิดตัวการไล่ระดับความสนใจ
ขอให้สังเกตว่าโดยค่าเริ่มต้นสิ่งนี้จะใช้โมเดล 'เล็ก' จากการฝึกอบรมการฝึกฝนภาพและการกลั่นภาพที่ประหยัดข้อมูลผ่านความสนใจที่โฮสต์บนฮับไฟฉาย
| ภาพ | การเปิดตัววานิลลาความสนใจ | ด้วย discard_ratio+max fusion |
|---|---|---|
 |  |  |
 |  |  |
 |  | 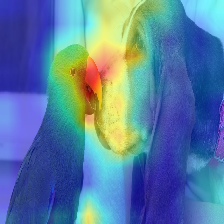 |
 |  |  |
ความสนใจที่ไหลในหม้อแปลงส่งผ่านข้อมูลที่อยู่ในชั้นเรียนที่แตกต่างกัน การไล่ระดับสีออกมาช่วยให้เราเห็นสถานที่ที่เครือข่ายให้ความสนใจด้วย แต่มันไม่ได้บอกอะไรเราเกี่ยวกับถ้ามันจบลงด้วยการใช้สถานที่เหล่านั้นสำหรับการจำแนกขั้นสุดท้าย
เราสามารถเพิ่มความสนใจด้วยการไล่ระดับสีของเอาท์พุทระดับเป้าหมายและใช้ค่าเฉลี่ยในหัวความสนใจ (ในขณะที่ปิดบังความสนใจเชิงลบ) เพื่อให้ความสนใจเฉพาะที่ก่อให้เกิดหมวดหมู่เป้าหมาย (หรือหมวดหมู่)




--discard_ratio <value between 0 and 1>
ขจัดเสียงรบกวนโดยรักษาความสนใจที่แข็งแกร่งที่สุด
ผลลัพธ์สำหรับค่าที่แตกต่างกัน:


วิธีการเปิดตัวความสนใจแสดงให้เห็นว่าการให้ความสนใจโดยเฉลี่ยทำให้เกิดหัวความสนใจ
แต่อุณหภูมิดูเหมือนว่าจะใช้ค่าต่ำสุดหรือค่าสูงสุดรวมกับ -discard_ratio ทำงานได้ดีขึ้น
--head_fusion <mean, min or max>
| ภาพ | ค่าเฉลี่ยฟิวชั่น | มินฟิวชั่น |
|---|---|---|
| |  |
ปริมาณความสนใจในการไหลในหม้อแปลง
TIMM: คอลเลกชันที่ยอดเยี่ยมของโมเดลใน Pytorch และโดยเฉพาะอย่างยิ่งการใช้งาน Vision Transformer
ภาพมีค่า 16x16 คำ: หม้อแปลงสำหรับการจดจำภาพในระดับ
เครดิตสำหรับ https://github.com/jeonsworld/vit-pytorch สำหรับการเป็นจุดเริ่มต้นที่ดี
pip install timm


