vit explain
1.0.0
Este repositorio implementa métodos de explicación en los transformadores de visión.
Ver también https://jacobgil.github.io/deeplearning/visision-transformer-explanability
Role de atención.
Despliaje de atención de gradiente para la explicabilidad específica de la clase. Este es nuestro intento de construir y mejorar la implementación de atención.
El flujo de atención de TBD es trabajo en progreso.
Incluye algunos ajustes y trucos para que funcione:
from vit_grad_rollout import VITAttentionGradRollout
model = torch . hub . load ( 'facebookresearch/deit:main' ,
'deit_tiny_patch16_224' , pretrained = True )
grad_rollout = VITAttentionGradRollout ( model , discard_ratio = 0.9 , head_fusion = 'max' )
mask = grad_rollout ( input_tensor , category_index = 243 ) python vit_explain.py --image_path <image path> --head_fusion <mean, min or max> --discard_ratio <number between 0 and 1> --category_index <category_index>
Si no se especifica Category_Index, se utilizará el despliegue de atención, de lo contrario, se utilizará el despliegue de atención del gradiente.
Observe que, de forma predeterminada, esto utiliza el modelo 'pequeño' de los transformadores de imágenes y la destilación de imágenes eficientes en los datos de entrenamiento a través de la atención alojada en la antorcha.
| Imagen | Deslizo de atención de vainilla | Con DISCARD_RATIO+MAX FUSION |
|---|---|---|
 |  |  |
 |  |  |
 |  | 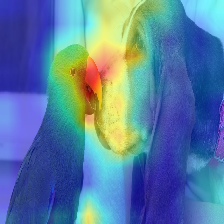 |
 |  |  |
La atención que fluye en el transformador pasa a lo largo de la información que pertenece a diferentes clases. El despliegue de gradiente nos permite ver qué ubicaciones también prestó atención la red, pero no nos dice nada sobre si terminó usando esas ubicaciones para la clasificación final.
Podemos multiplicar la atención con el gradiente de la salida de la clase objetivo y tomar el promedio entre los cabezales de atención (al tiempo que enmascaramos las atenciones negativas) para mantener solo la atención que contribuye a la categoría objetivo (o categorías).




--discard_ratio <value between 0 and 1>
Elimina el ruido manteniendo las atenciones más fuertes.
Resultados para diferentes valores:


El método de despliegue de atención sugiere que la atención promedio se acumula los cabezales de atención,
Pero empéricamente parece que tomar el valor mínimo, o el valor máximo combinado con --discard_ratio, funciona mejor.
--head_fusion <mean, min or max>
| Imagen | Fusión media | Min Fusión |
|---|---|---|
| |  |
Cuantificando el flujo de atención en los transformadores
TIMM: Una gran colección de modelos en Pytorch y especialmente la implementación del transformador de visión
Una imagen vale 16x16 palabras: transformadores para el reconocimiento de imágenes a escala
Crédito por https://github.com/jeonsworld/vit-pytorch por ser un buen punto de partida.
pip install timm


