ransomware preencryption detector
1.0.0
安全的浏览设施,可检测预加密执行步骤中的勒索软件,而不会对主机实例施加任何危险。
请参阅页面底部的视觉指南。
仅在2020年,勒索软件“商业”为网络罪犯带来了200亿美元。这个令人震惊的数字每年都在逐渐上升,现有的解决方案无法应对这一威胁。根据网络犯罪杂志的报道,该数字假设当前趋势可能会上升,到2031年可能会增长2650亿美元。
勒索软件成功背后的原因是什么?如今,防病毒软件与其第一型原型没有太大差异。它们根据已知的恶意软件的签名库(哈希)库进行操作,这些恶意软件由于研究,蜜罐或更多且更多地归功于Virustotal在线工具而收集。但是,如果给定的防病毒软件不知道恶意软件,尤其是勒索软件样本该怎么办? - 然后,防病毒软件不会阻止恶意程序损坏计算机,因为库中不存在其签名。
我们建议使用Windows System API调用和其他系统信息来检测恶意行为并保护最终用户免于下载和运行恶意软件/勒索软件。数据收集
在获取数据进行分析和合作之前,我们必须找到GOOD WAFER,恶意软件和勒索软件样本。为了找到后者,我们已经使用了所有可能的选项,从Google和Github开始,再到Darknet Hacking网站。总的来说,我们收集了X Goodware,X恶意软件和X勒索软件样本。
最终,由于杜鹃花盒(https://cuckoosandbox.org),我们制作了报告数据集。该沙盒软件对文件执行过程中在操作系统中运行的内部流程提供了详细且有价值的见解。
报告遵循JSON文件结构。可以描述如下:主文件结构:

在对我们与杜鹃一起获得的数据进行了深入分析之后,考虑到它可能因一种情况而异,我们同意提取特定值,这些值将在本文稍后描述。
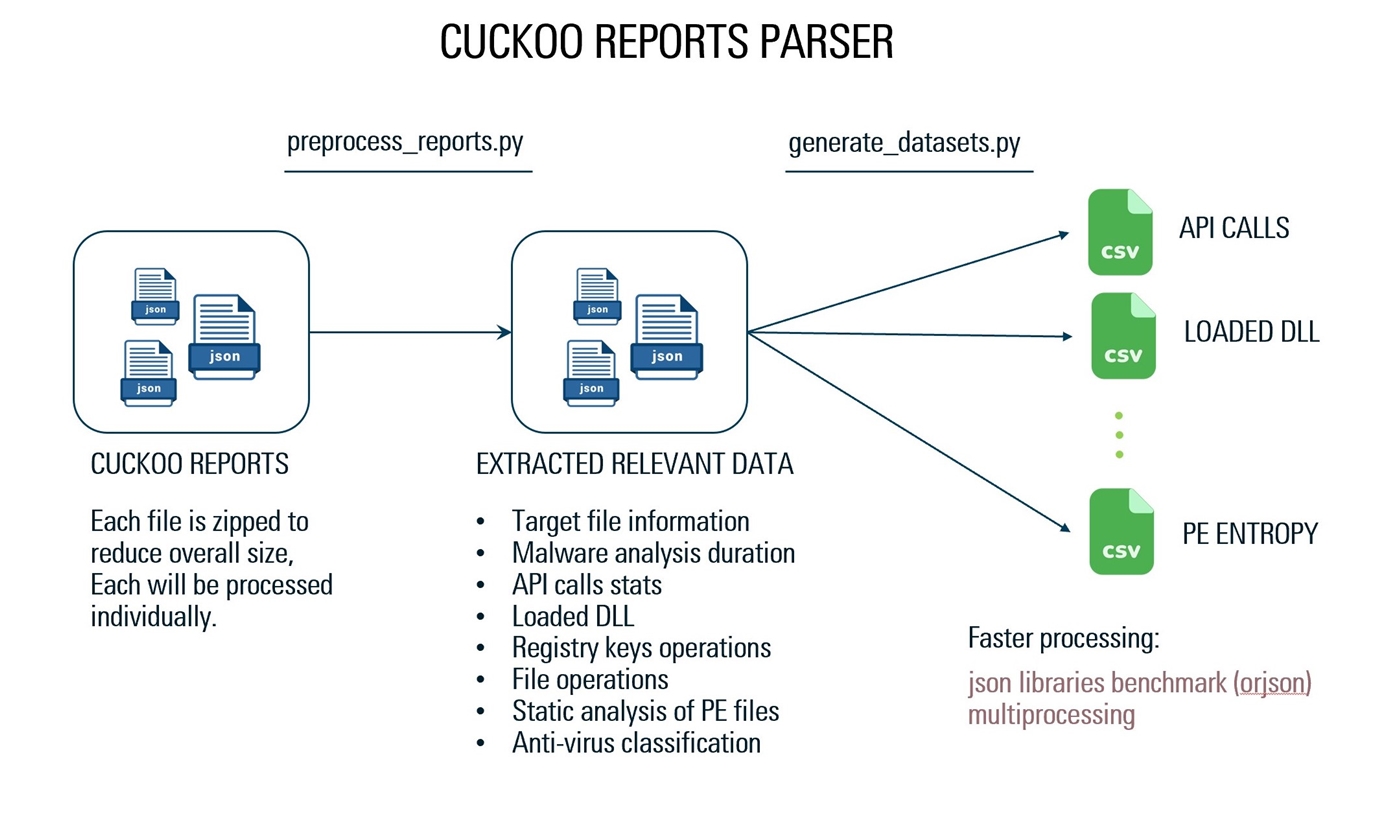
我们已经使用自定义JSON解析器从报告中检索所需的数据。它是使用报告JSON结构,Orjson库和多处理,从1000个JSON报告中提取数据的实现,总计20 GB的数据仅需125秒。 (一个文件的大小为1.1千兆字节,需要39秒的处理)
妥协的指标(IOC)是“识别系统或网络上潜在恶意活动的系统日志条目或文件中发现的法医数据的片段”。妥协援助信息安全和IT专业人员的指标,以检测数据泄露,恶意软件感染或其他威胁活动。通过监视妥协的指标,组织可以检测攻击并迅速采取行动,以防止违规行为发生或通过在较早阶段停止攻击来限制损害。
API调用系统呼叫通过应用程序程序接口(API)向用户程序提供操作系统的服务。它提供了过程和操作系统之间的接口,以允许用户级进程请求操作系统的服务。系统调用是内核系统的唯一入口点。
DLL代表“动态链接库”。 DLL(。dll)文件包含Windows程序可以访问的功能库和其他信息库。启动程序时,将链接到必要的链接。有些DLL随Windows操作系统附带,而安装新程序时添加了一些DLL。
文件操作文件是一种抽象数据类型。要正确定义文件,我们需要考虑可以在文件上执行的操作。六个基本文件操作。 OS可以提供系统调用以创建,写入,读取,重新定位,删除和截断文件。
注册表密钥操作注册表键是类似于文件夹的容器对象。注册表值是类似于文件的非载体对象。密钥可能包含值和子键。用类似于Windows的路径名的语法引用键,并使用后斜切指示层次结构级别。
PE导入PE或便携式可执行文件是Windows可执行文件格式。研究PE格式有助于我们了解Windows内部功能如何使我们变得更好的程序员。对于想要找出经常混淆的二进制文件的复杂细节的反向工程师来说,这一点更为重要。每当您执行文件时,Windows Loader都会首先从磁盘加载PE文件并将其映射到内存中。 PE文件的存储映射称为模块。重要的是要注意,加载程序不仅可以将整个内容从磁盘复制到内存。取而代之的是,加载程序查看标题中的各种值,以在文件中查找PE的不同部分,然后将其部分映射到内存。 (http://ulsrl.org/pe-portable-executable/)
恶意软件生态系统中低渗透包装方案的患病率和影响是一种常见的对手杠杆,这是包装二进制文件。包装可执行文件类似于应用压缩或加密,并且可以抑制某些技术检测包装恶意软件的能力。传统上,高熵是包装工的出现的一个明显标志,但是许多恶意软件分析师可能会遇到低凝聚包装工。许多受欢迎的工具(例如,PEID,MANALYZE,检测到它),与恶意软件相关的课程,甚至有关该主题的参考书,肯定包装的恶意软件通常会显示出很高的熵。结果,许多研究人员在他们的分析程序中使用了这种启发式。众所周知,通常用于检测包装工的工具是基于签名匹配的,有时可能结合了其他启发式方法,但是同样,结果并不完全忠实,因为流通的许多签名都容易发生误报。 Cisco Talos Intelligence Group-综合威胁情报:新研究论文:恶意软件生态系统中低渗透包装方案的流行和影响
除了分类算法之外,由于在线可用的勒索软件样品严重缺乏,我们将不得不使用Smote(合成少数族裔过度采样技术)等技术处理不平衡的分类,以及用于不平衡数据的袋装和增强技术。
我们还打算尝试使用聚类算法来检查我们是否可以识别勒索软件以外的恶意软件类型集群,例如:蠕虫,木马,间谍软件,老鼠,偷窃者,银行家等。
我们已经为我们的体系结构使用了AWS,因为它与以服务器为导向的经典相比具有许多好处,包括易于可扩展性,按需计算功率,各种内置工具。主要组成部分是:
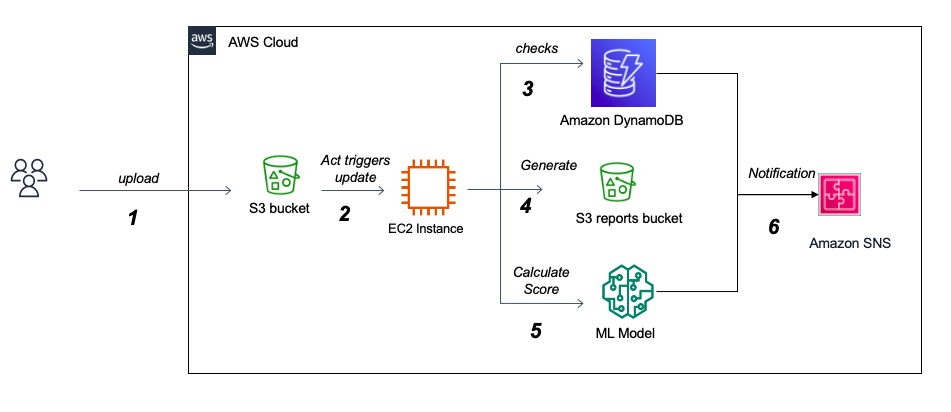
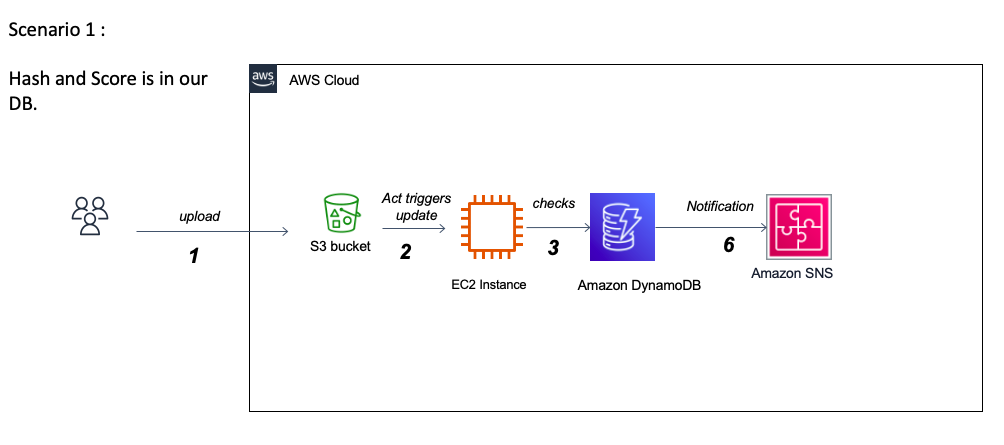
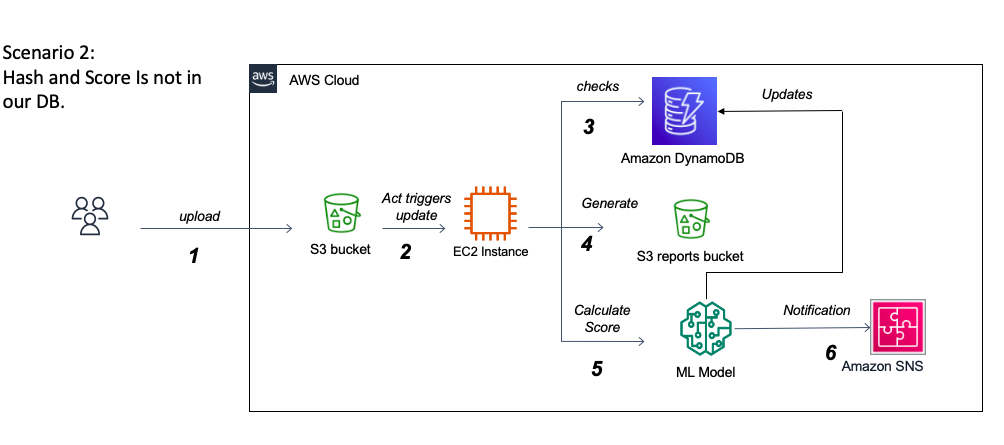
该项目的最大挑战之一是处理杜鹃分析JSON报告。一方面,它们的尺寸最多可以达到500-700兆字节,这要求我们找出一种内存效率且快速的加载和处理方法。另一方面,了解报告的广泛嵌套结构并解释每个部分的含义很好地带来了挑战,并且可能需要操作系统专家的帮助。实际上,杜鹃提供了非常详细的报告,概述了在现实的孤立环境中执行文件的行为,并且由于这种详细的性质以及向每个提交文件的报告的自适应结构进行分析,杜鹃没有足够的文档在其官方网站上对报告内容的文档。由于数据主要具有反映Windows环境中文件行为的1000多个可能功能的分类,因此挑战将是成功确定可以区分勒索软件和良好软件的重要功能。这需要USTO正确研究重要性并实施不同的变量选择算法。我们还将处理变量多重共线性的潜在问题,并探索各种维度降低方法。当该分类变量属于较大类别时,最终性的一个重要问题是功能消除的相关性。处理多级分类变量的另一个挑战是,训练数据集并未提供所有可能类的详尽列表。部署后,模型很可能会面对看不见的课程。例如,有1000多个Windows API调用,到目前为止,收集的数据集仅包含大约250个。处理这个问题将需要我们探索多种策略来处理看不见的课程以实现最佳性能。另一种选择是通过增量学习技术在生产中使用新数据进行模型再培训。
请从github下载我们的代码,并按照下面的说明进行操作
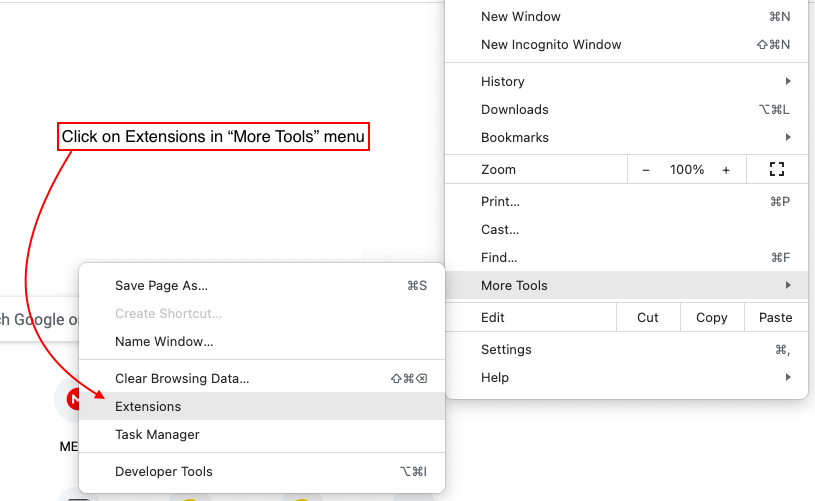
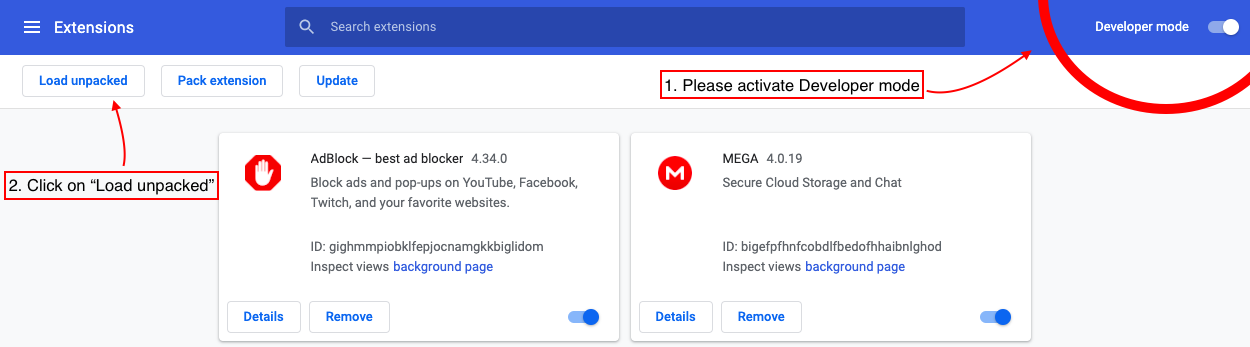
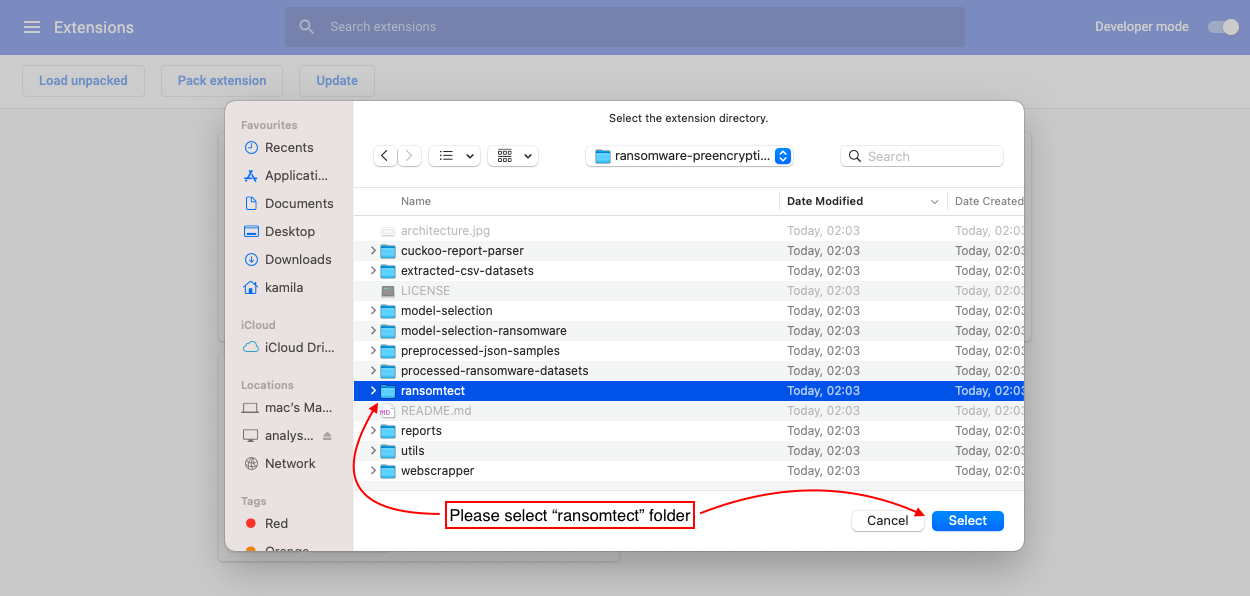
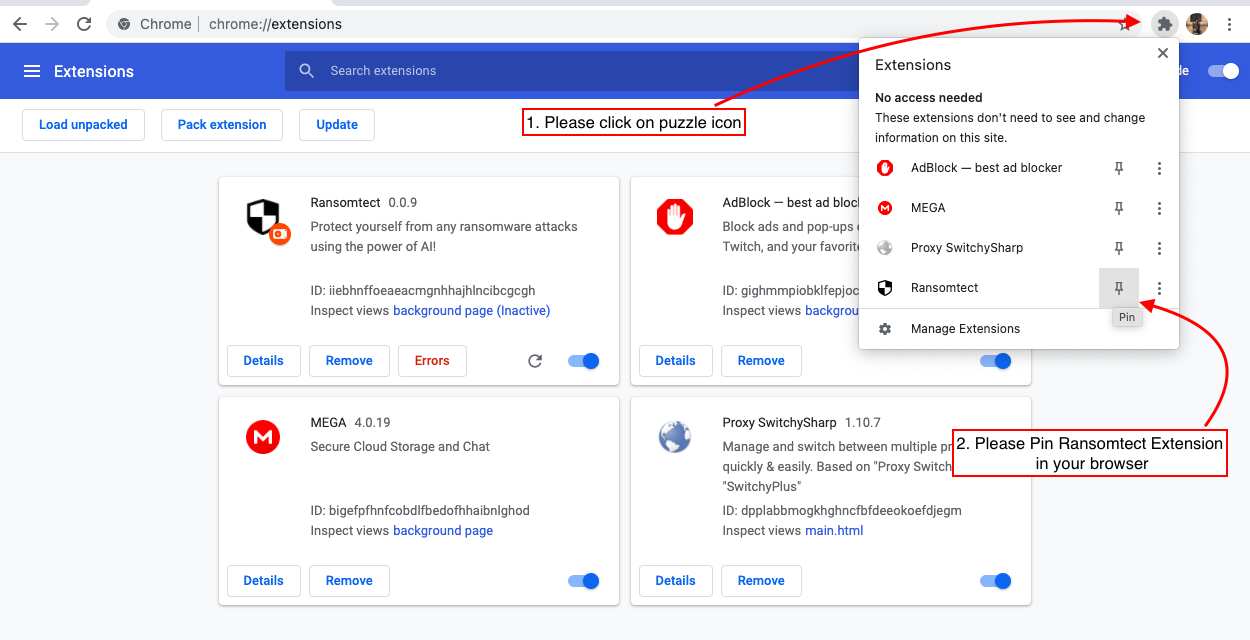 6。
6。 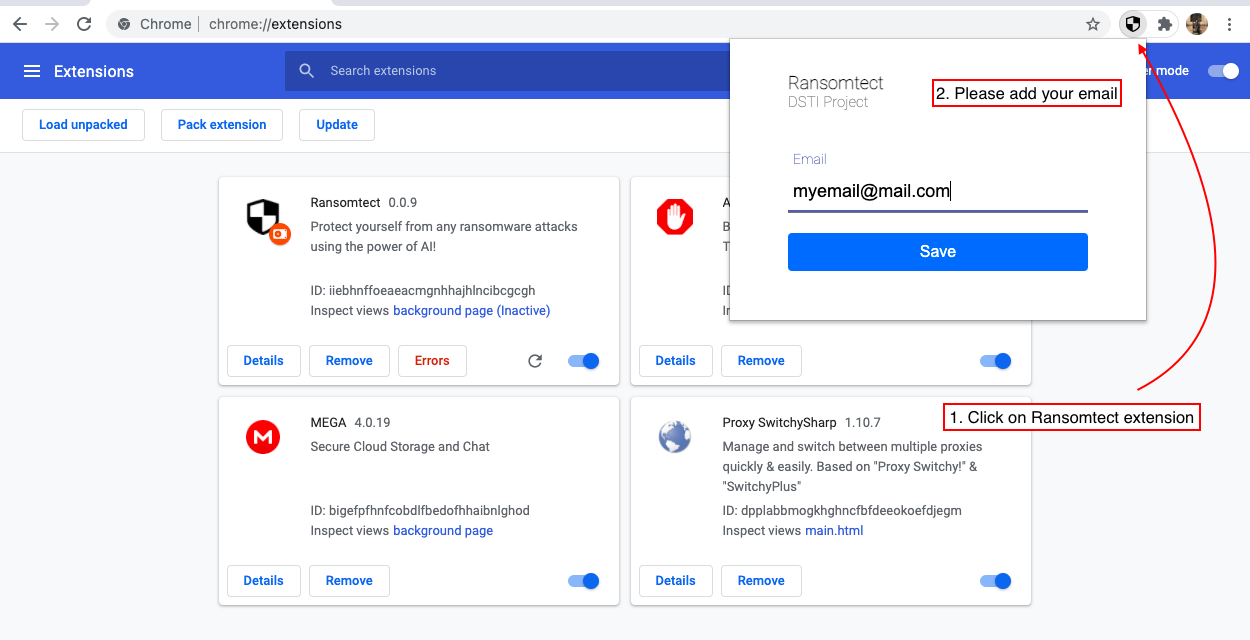
你很好!享受安全的浏览! 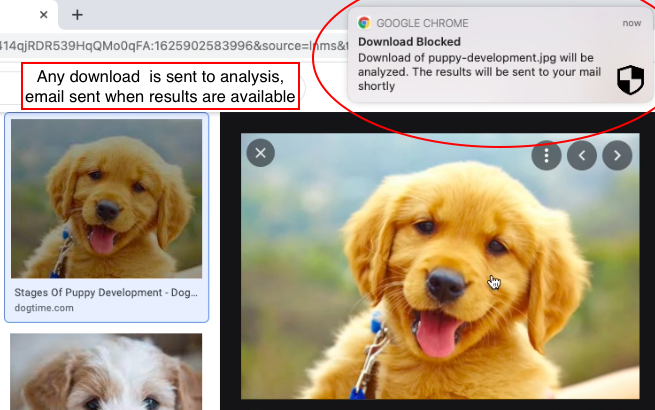
请注意,您将以这种格式接收电子邮件: 


