ransomware preencryption detector
1.0.0
安全的瀏覽設施,可檢測預加密執行步驟中的勒索軟件,而不會對主機實例施加任何危險。
請參閱頁面底部的視覺指南。
僅在2020年,勒索軟件“商業”為網絡罪犯帶來了200億美元。這個令人震驚的數字每年都在逐漸上升,現有的解決方案無法應對這一威脅。根據網絡犯罪雜誌的報導,該數字假設當前趨勢可能會上升,到2031年可能會增長2650億美元。
勒索軟件成功背後的原因是什麼?如今,防病毒軟件與其第一型原型沒有太大差異。它們根據已知的惡意軟件的簽名庫(哈希)庫進行操作,這些惡意軟件由於研究,蜜罐或更多且更多地歸功於Virustotal在線工具而收集。但是,如果給定的防病毒軟件不知道惡意軟件,尤其是勒索軟件樣本該怎麼辦? - 然後,防病毒軟件不會阻止惡意程序損壞計算機,因為庫中不存在其簽名。
我們建議使用Windows System API調用和其他系統信息來檢測惡意行為並保護最終用戶免於下載和運行惡意軟件/勒索軟件。數據收集
在獲取數據進行分析和合作之前,我們必須找到GOOD WAFER,惡意軟件和勒索軟件樣本。為了找到後者,我們已經使用了所有可能的選項,從Google和Github開始,再到Darknet Hacking網站。總的來說,我們收集了X Goodware,X惡意軟件和X勒索軟件樣本。
最終,由於杜鵑花盒(https://cuckoosandbox.org),我們製作了報告數據集。該沙盒軟件對文件執行過程中在操作系統中運行的內部流程提供了詳細且有價值的見解。
報告遵循JSON文件結構。可以描述如下:主文件結構:

在對我們與杜鵑一起獲得的數據進行了深入分析之後,考慮到它可能因一種情況而異,我們同意提取特定值,這些值將在本文稍後描述。
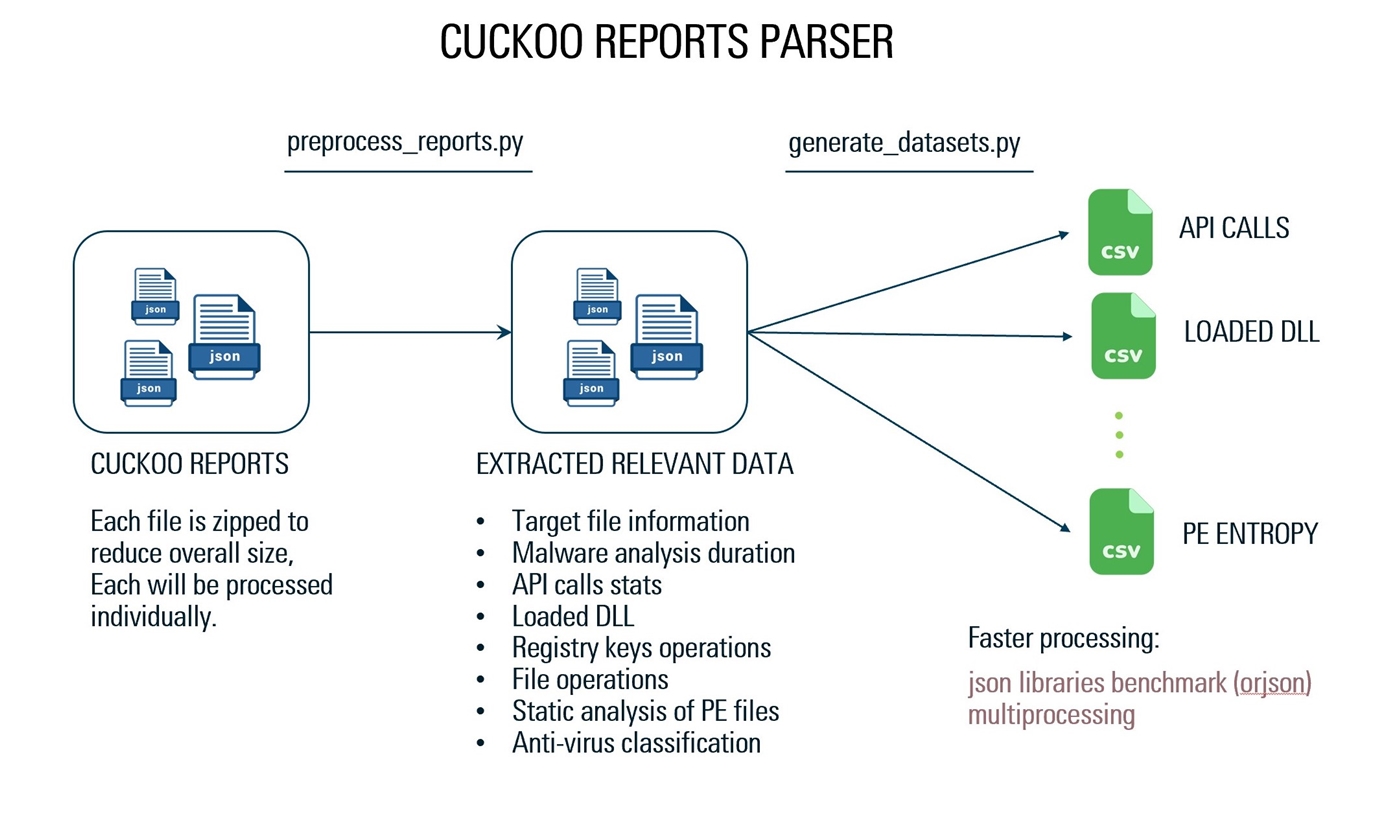
我們已經使用自定義JSON解析器從報告中檢索所需的數據。它是使用報告JSON結構,Orjson庫和多處理,從1000個JSON報告中提取數據的實現,總計20 GB的數據僅需125秒。 (一個文件的大小為1.1千兆字節,需要39秒的處理)
妥協的指標(IOC)是“識別系統或網絡上潛在惡意活動的系統日誌條目或文件中發現的法醫數據的片段”。妥協援助信息安全和IT專業人員的指標,以檢測數據洩露,惡意軟件感染或其他威脅活動。通過監視妥協的指標,組織可以檢測攻擊並迅速採取行動,以防止違規行為發生或通過在較早階段停止攻擊來限制損害。
API調用系統呼叫通過應用程序程序接口(API)向用戶程序提供操作系統的服務。它提供了過程和操作系統之間的接口,以允許用戶級進程請求操作系統的服務。系統調用是內核系統的唯一入口點。
DLL代表“動態鏈接庫”。 DLL(。dll)文件包含Windows程序可以訪問的功能庫和其他信息庫。啟動程序時,將鏈接到必要的鏈接。有些DLL隨Windows操作系統附帶,而安裝新程序時添加了一些DLL。
文件操作文件是一種抽像數據類型。要正確定義文件,我們需要考慮可以在文件上執行的操作。六個基本文件操作。 OS可以提供系統調用以創建,寫入,讀取,重新定位,刪除和截斷文件。
註冊表密鑰操作註冊表鍵是類似於文件夾的容器對象。註冊表值是類似於文件的非載體對象。密鑰可能包含值和子鍵。用類似於Windows的路徑名的語法引用鍵,並使用後斜切指示層次結構級別。
PE導入PE或便攜式可執行文件是Windows可執行文件格式。研究PE格式有助於我們了解Windows內部功能如何使我們變得更好的程序員。對於想要找出經常混淆的二進製文件的複雜細節的反向工程師來說,這一點更為重要。每當您執行文件時,Windows Loader都會首先從磁盤加載PE文件並將其映射到內存中。 PE文件的存儲映射稱為模塊。重要的是要注意,加載程序不僅可以將整個內容從磁盤複製到內存。取而代之的是,加載程序查看標題中的各種值,以在文件中查找PE的不同部分,然後將其部分映射到內存。 (http://ulsrl.org/pe-portable-executable/)
惡意軟件生態系統中低滲透包裝方案的患病率和影響是一種常見的對手槓桿,這是包裝二進製文件。包裝可執行文件類似於應用壓縮或加密,並且可以抑制某些技術檢測包裝惡意軟件的能力。傳統上,高熵是包裝工的出現的一個明顯標誌,但是許多惡意軟件分析師可能會遇到低凝聚包裝工。許多受歡迎的工具(例如,PEID,MANALYZE,檢測到它),與惡意軟件相關的課程,甚至有關該主題的參考書,肯定包裝的惡意軟件通常會顯示出很高的熵。結果,許多研究人員在他們的分析程序中使用了這種啟發式。眾所周知,通常用於檢測包裝工的工具是基於簽名匹配的,有時可能結合了其他啟發式方法,但是同樣,結果並不完全忠實,因為流通的許多簽名都容易發生誤報。 Cisco Talos Intelligence Group-綜合威脅情報:新研究論文:惡意軟件生態系統中低滲透包裝方案的流行和影響
除了分類算法之外,由於在線可用的勒索軟件樣品嚴重缺乏,我們將不得不使用Smote(合成少數族裔過度採樣技術)等技術處理不平衡的分類,以及用於不平衡數據的袋裝和增強技術。
我們還打算嘗試使用聚類算法來檢查我們是否可以識別勒索軟件以外的惡意軟件類型集群,例如:蠕蟲,木馬,間諜軟件,老鼠,偷竊者,銀行家等。
我們已經為我們的體系結構使用了AWS,因為它與以服務器為導向的經典相比具有許多好處,包括易於可擴展性,按需計算功率,各種內置工具。主要組成部分是:
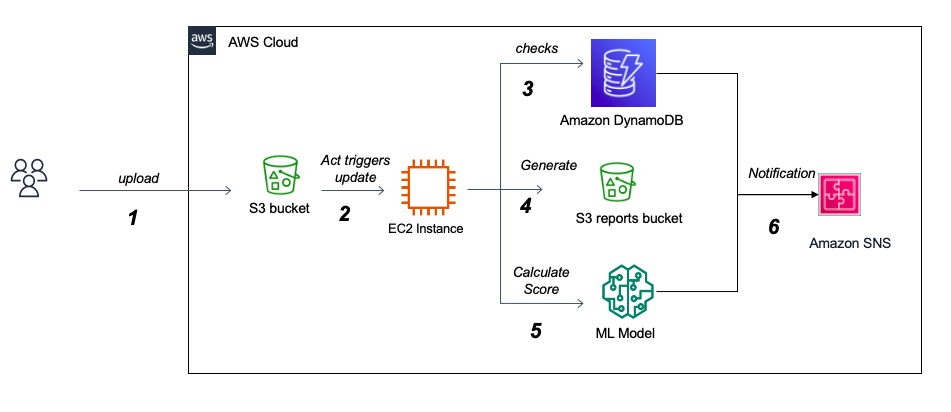
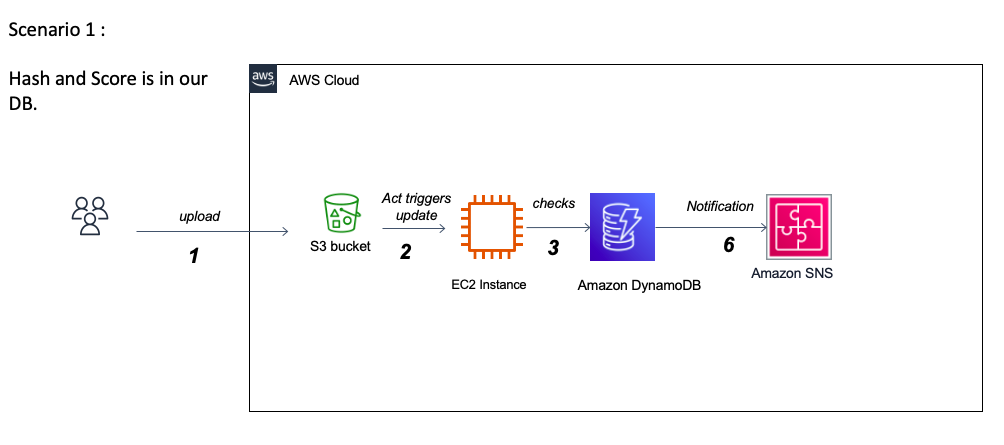
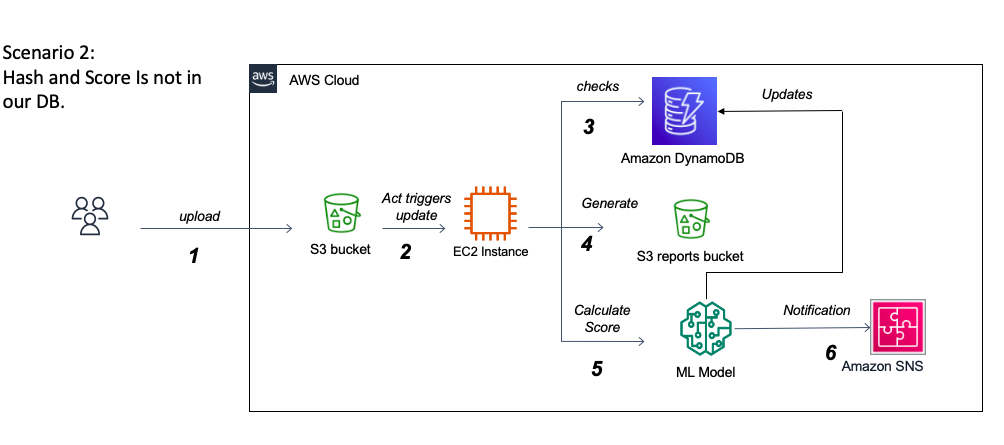
該項目的最大挑戰之一是處理杜鵑分析JSON報告。一方面,它們的尺寸最多可以達到500-700兆字節,這要求我們找出一種內存效率且快速的加載和處理方法。另一方面,了解報告的廣泛嵌套結構並解釋每個部分的含義很好地帶來了挑戰,並且可能需要操作系統專家的幫助。實際上,杜鵑提供了非常詳細的報告,概述了在現實的孤立環境中執行文件的行為,並且由於這種詳細的性質以及向每個提交文件的報告的自適應結構進行分析,杜鵑沒有足夠的文檔在其官方網站上對報告內容的文檔。由於數據主要具有反映Windows環境中文件行為的1000多個可能功能的分類,因此挑戰將是成功確定可以區分勒索軟件和良好軟件的重要功能。這需要USTO正確研究重要性並實施不同的變量選擇算法。我們還將處理變量多重共線性的潛在問題,並探索各種維度降低方法。當該分類變量屬於較大類別時,最終性的一個重要問題是功能消除的相關性。處理多級分類變量的另一個挑戰是,訓練數據集並未提供所有可能類的詳盡列表。部署後,模型很可能會面對看不見的課程。例如,有1000多個Windows API調用,到目前為止,收集的數據集僅包含大約250個。處理這個問題將需要我們探索多種策略來處理看不見的課程以實現最佳性能。另一種選擇是通過增量學習技術在生產中使用新數據進行模型再培訓。
請從github下載我們的代碼,並按照下面的說明進行操作
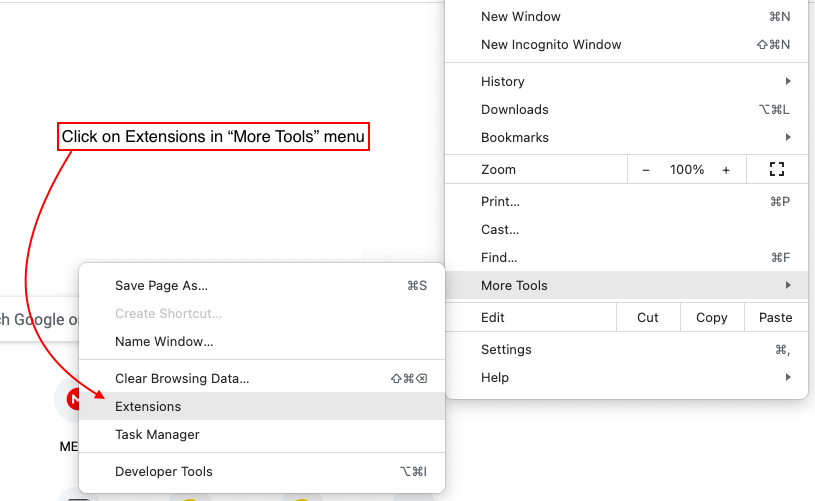
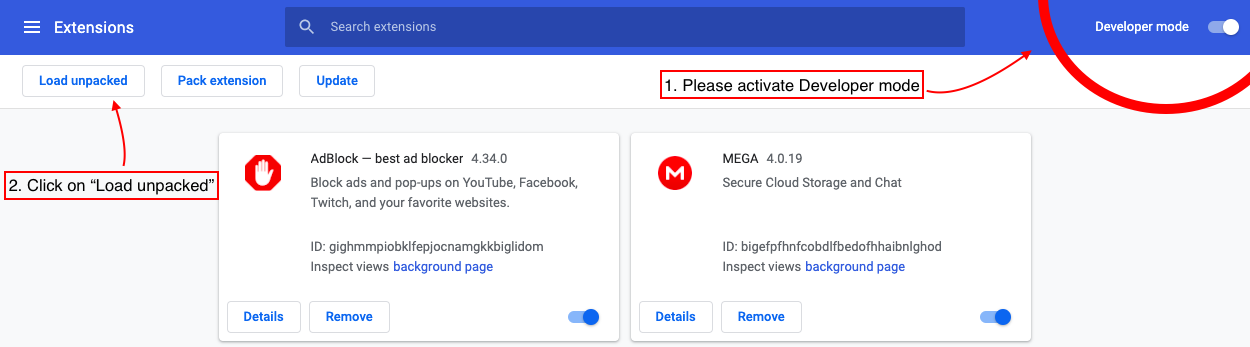
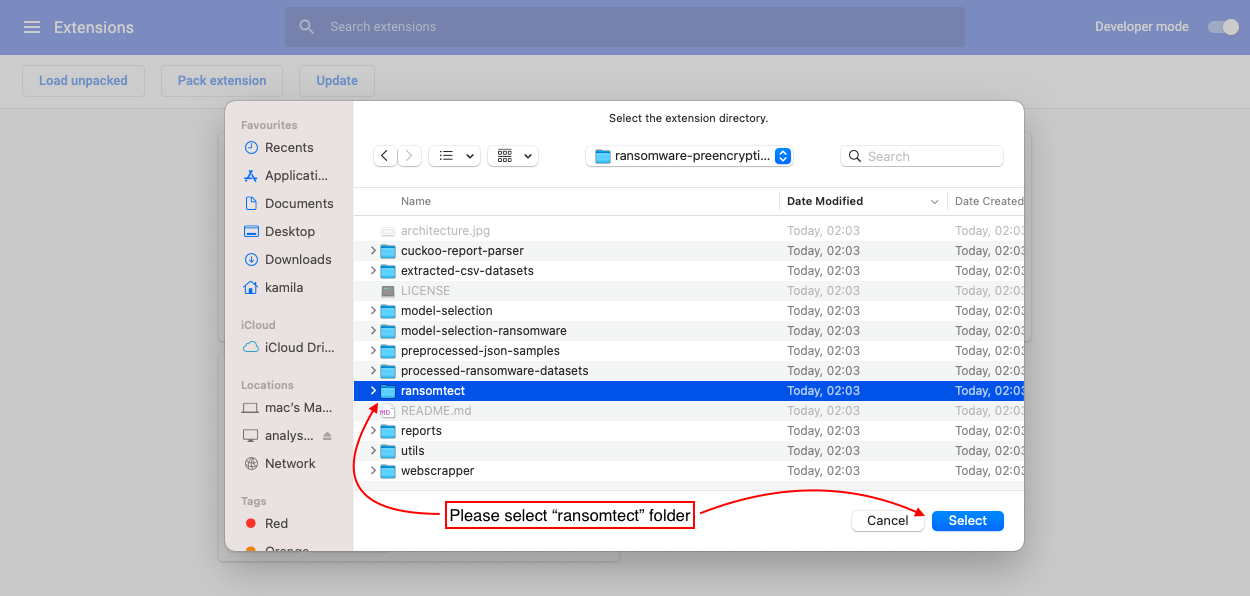
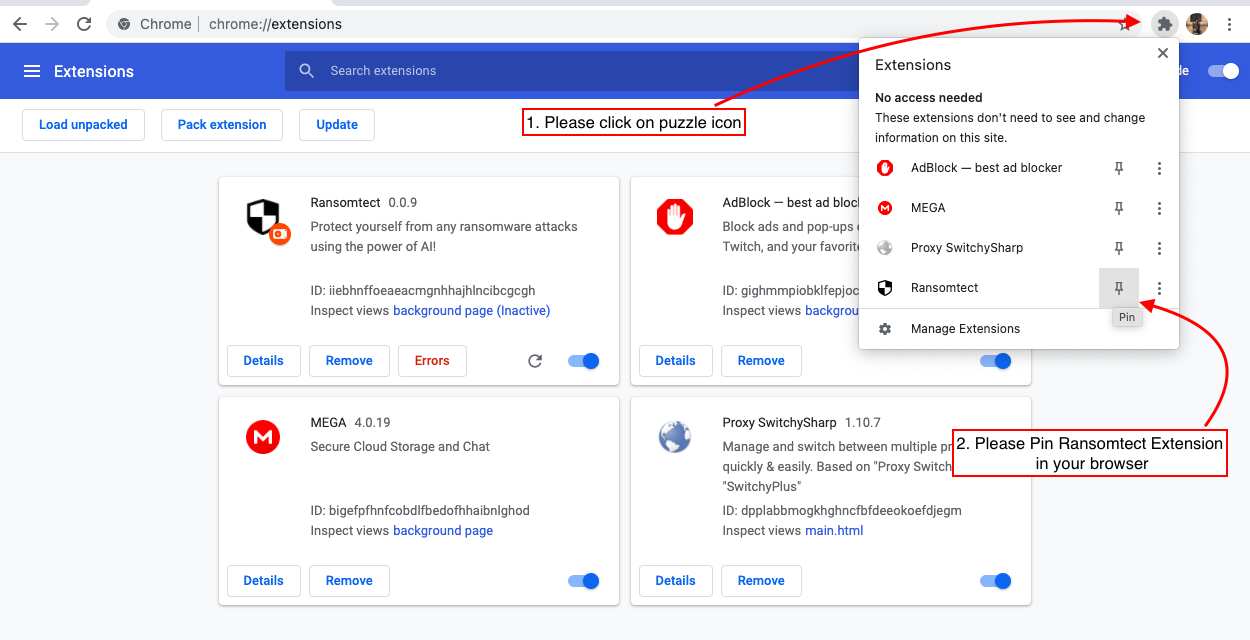 6。
6。 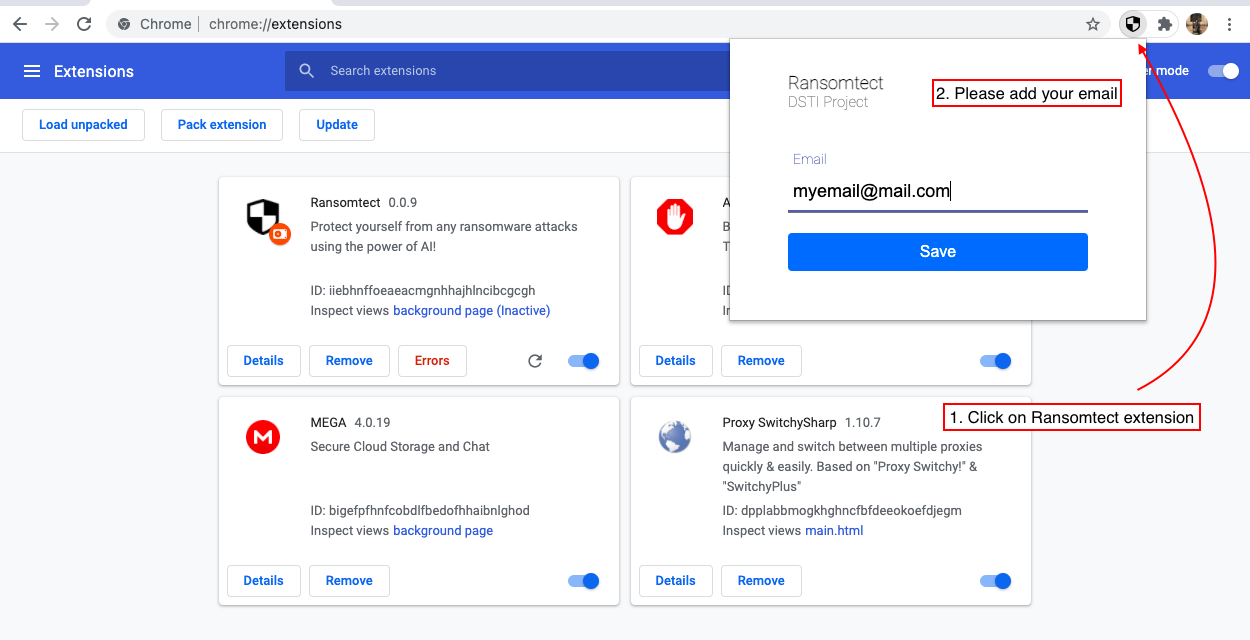
你很好!享受安全的瀏覽! 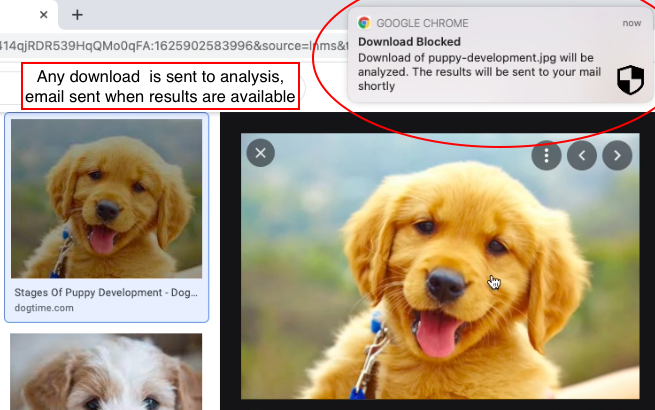
請注意,您將以這種格式接收電子郵件: 


