ransomware preencryption detector
1.0.0
Installation de navigation sûre qui détecte les ransomwares dans l'étape d'exécution de pré-incryption sans imposer un danger pour l'hôte.
Veuillez vous référer au guide visuel en bas de la page.
En 2020 seulement, «Business» ransomware a rapporté 20 milliards de dollars aux cybercriminels. Ce chiffre épouvantable augmente progressivement chaque année et les solutions existantes ne sont pas en mesure de lutter contre cette menace. Selon Cybercrime Magazine, ce chiffre, en supposant que la tendance actuelle, peut augmenter et dépasser 265 milliards de dollars d'ici 2031. (Https://cybersecurityventures.com/global-ransomware-damage-costs-predit--preeach-250-billion-usd-by-2031/)
Quelle est la raison du succès de Ransomware? De nos jours, les logiciels antivirus ne diffèrent pas beaucoup de leurs premiers prototypes. Ils opèrent sur la base d'une bibliothèque de signatures (hachages) de logiciels malveillants connus qu'ils rassemblent en raison de recherches, de pots de miel ou de plus en plus grâce à l'outil Virustotal Online. Mais que se passe-t-il si le malware ou, en particulier, l'échantillon de ransomware n'est pas connu d'un antivirus donné? - alors l'antivirus n'empêchera pas le programme malveillant de nuire à l'ordinateur, car sa signature n'existe pas dans la bibliothèque.
Au lieu de compter sur la signature de chaque échantillon, nous proposons d'utiliser les appels d'API système Windows et d'autres informations système pour détecter le comportement malveillant et protéger l'utilisateur final contre le téléchargement et l'exécution de logiciels malveillants / ransomwares. Rassemblement de données
Avant d'obtenir des données pour analyser et travailler avec nous avons dû trouver des échantillons de goodware, de malware et de ransomwares. Pour trouver ce dernier, nous avons utilisé toutes les options possibles, en commençant par Google et GitHub et jusqu'à DarkNet Hacking Sites Web. Au total, nous avons rassemblé des échantillons X Goodware, X malware et x ransomware.
Finalement, nous avons produit un ensemble de données de rapports grâce à Cuckoo Sandbox (https://cuckoosandbox.org). Ce logiciel Sandbox fournit des informations détaillées et précieuses sur les processus internes exécutés dans le système d'exploitation pendant l'exécution des fichiers.
Les rapports suivent la structure des fichiers JSON. Il peut être décrit comme suit: Structure du fichier principal:

Après une analyse approfondie des données que nous avons acquises avec Cuckoo, en tenant compte du fait qu'elle peut varier d'un cas à un autre, nous avons convenu d'extraire des valeurs spécifiques que nous décrire plus loin dans l'article.
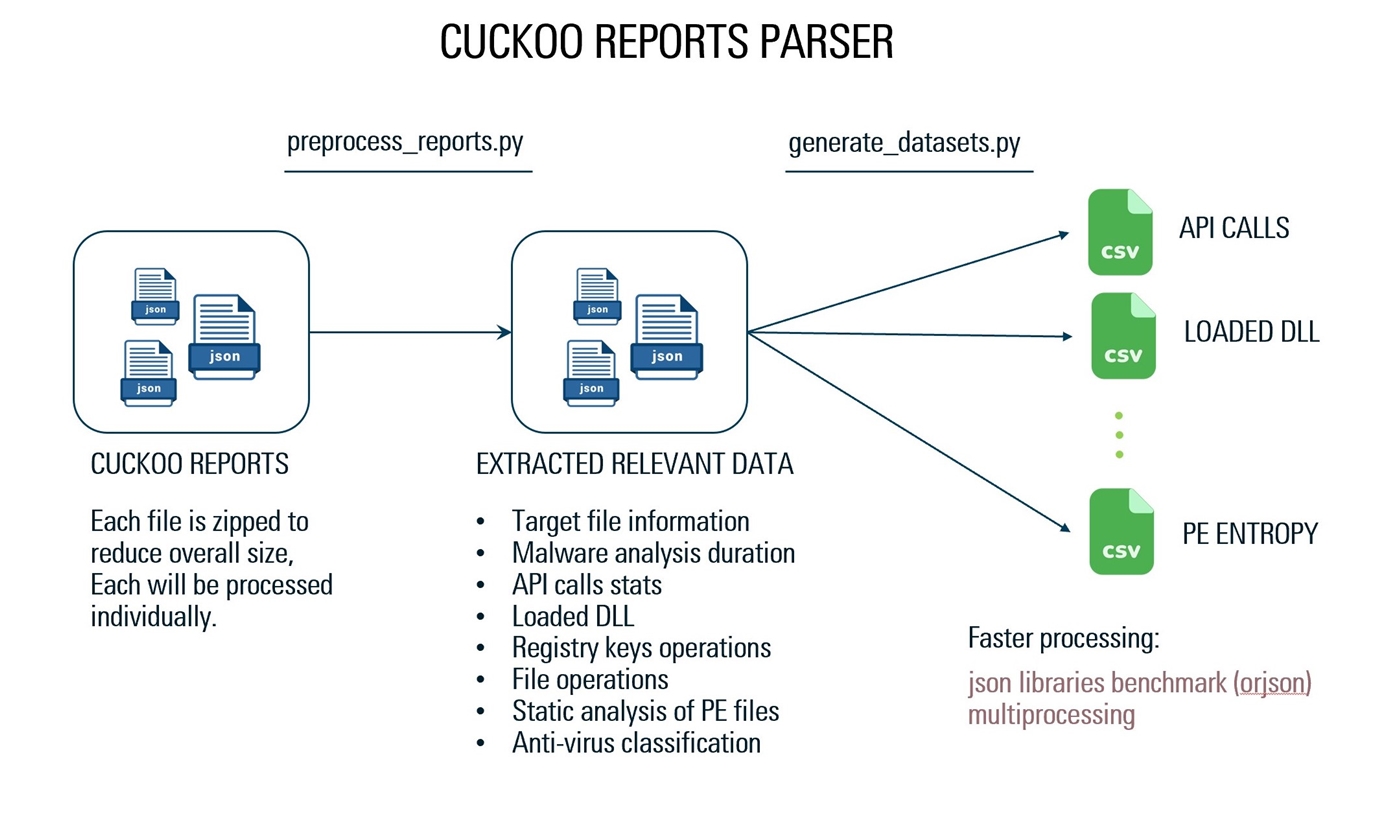
Nous avons utilisé un analyseur JSON personnalisé pour récupérer les données nécessaires à partir des rapports. C'est l'implémentation, en utilisant la structure JSON du rapport, la bibliothèque ORJSON et le multiprocessement, extrait les données de 1000 rapports JSON, totalisant 20 gigaoctets de taille n'a pris que 125 secondes. (Un fichier était de 1,1 gigaoctet et a pris 39 secondes à traiter)
Les indicateurs de compromis (IOC) sont «des éléments médico-légaux, tels que les données trouvées dans les entrées de journal système ou les fichiers, qui identifient une activité potentiellement malveillante sur un système ou un réseau.» Indicateurs de compromis sur la sécurité de l'information et des professionnels de l'information dans la détection des violations de données, des infections de logiciels malveillants ou une autre activité de menace. En surveillant les indicateurs de compromis, les organisations peuvent détecter les attaques et agir rapidement pour empêcher les violations de se produire ou limiter les dommages et intérêts en arrêtant les attaques à des stades antérieurs.
API CALS System Call fournit les services du système d'exploitation aux programmes utilisateur via l'interface du programme d'application (API). Il fournit une interface entre un processus et un système d'exploitation pour permettre aux processus au niveau de l'utilisateur de demander des services du système d'exploitation. Les appels système sont les seuls points d'entrée dans le système du noyau.
DLL signifie «Bibliothèque de liens dynamiques». Un fichier DLL (. DLL) contient une bibliothèque de fonctions et d'autres informations accessibles par un programme Windows. Lorsqu'un programme est lancé, les liens vers le nécessaire. Certaines DLL sont livrées avec le système d'exploitation Windows tandis que d'autres sont ajoutés lorsque de nouveaux programmes sont installés.
Opérations de fichiers Un fichier est un type de données abstrait. Pour définir correctement un fichier, nous devons considérer les opérations qui peuvent être effectuées sur des fichiers. Six opérations de fichiers de base. Le système d'exploitation peut fournir des appels système pour créer, écrire, lire, repositionner, supprimer et tronquer des fichiers.
Key Key Operations Les clés de registre sont des objets de conteneur similaires aux dossiers. Les valeurs de registre sont des objets non-contineurs similaires aux fichiers. Les clés peuvent contenir des valeurs et des sous-clés. Les touches sont référencées avec une syntaxe similaire aux noms de chemin de Windows, en utilisant des barres réalisateurs pour indiquer les niveaux de hiérarchie.
PE importe PE ou exécutable portable est le format de fichier exécutable Windows. L'étude du format PE nous aide à comprendre comment fonctionnent les internes de Windows qui, à leur tour, nous font de meilleurs programmeurs. Il est encore plus important pour les indexes qui souhaitent comprendre les détails complexes des binaires souvent obscurcis. Chaque fois que vous exécutez un fichier, le chargeur Windows chargeait d'abord le fichier PE à partir du disque et le mapperait en mémoire. La carte mémoire du fichier PE est appelée module. Il est important de noter que le chargeur peut non seulement copier le contenu entier du disque à la mémoire. Au lieu de cela, le chargeur examine les différentes valeurs de l'en-tête pour trouver différentes parties du PE dans le fichier, puis en met en mémoire des parties. (http://ulsrl.org/pe-portable-execuable/)
Prévalence et impact des schémas d'emballage à faible entropie dans l'écosystème des logiciels malveillants Un effet de levier des adversaires de techniques communes est les binaires d'emballage. L'emballage d'un exécutable est similaire à l'application de compression ou de chiffrement et peut inhiber la capacité de certaines technologies à détecter le malware emballé. L'entropie élevée est traditionnellement un signe révélateur de la présence d'un packer, mais de nombreux analystes de logiciels malveillants ont peut-être probablement rencontré des emballeurs à basse entropie plus d'une fois. De nombreux outils populaires (par exemple, Peid, Manalyze, le détectent facilement), les cours liés aux logiciels malveillants et même les livres de référence sur le sujet, affirment que les logiciels malveillants emballés montrent souvent une entropie élevée. En conséquence, de nombreux chercheurs utilisent cette heuristique dans leurs routines d'analyse. Il est également bien connu que les outils généralement utilisés pour détecter les packers sont basés sur une correspondance de signature et peuvent parfois combiner d'autres heuristiques, mais encore une fois, les résultats ne sont pas complètement fidèles, car beaucoup de signatures qui circulent sont sujettes à de faux positifs. Cisco Talos Intelligence Group - Intelligence complète des menaces: nouveau document de recherche: prévalence et impact des schémas d'emballage à faible entropie dans l'écosystème des logiciels malveillants
En plus des algorithmes de classification, car il y a une grave pénurie d'échantillons de ransomwares disponibles en ligne, nous devrons faire face à la classification déséquilibrée en utilisant des techniques telles que SMOTE (technique de suréchantillonnage des minorités synthétiques) ainsi que les techniques d'ensachage et de renforcement des données déséquilibrées.
Nous avons également l'intention d'essayer des algorithmes de clustering pour vérifier si nous pouvons identifier des grappes de types de logiciels malveillants, autres que les ransomwares, tels que: vers, chevaux de Troie, logiciels espions, rats, voleurs, banquiers, etc.
Nous avons utilisé AWS pour notre architecture car il présente de nombreux avantages par rapport à celui-ci classique sur les serveurs, y compris la facilité d'évolutivité, la puissance de calcul en demande, la variété d'outils intégrés. Les principaux composants sont:
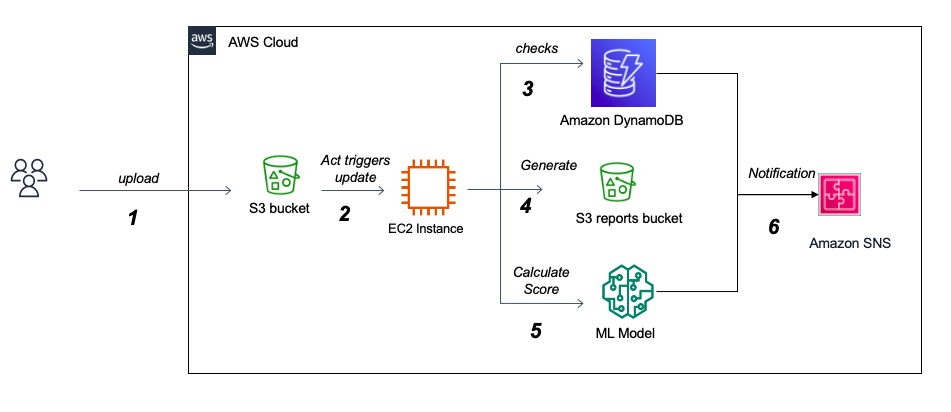
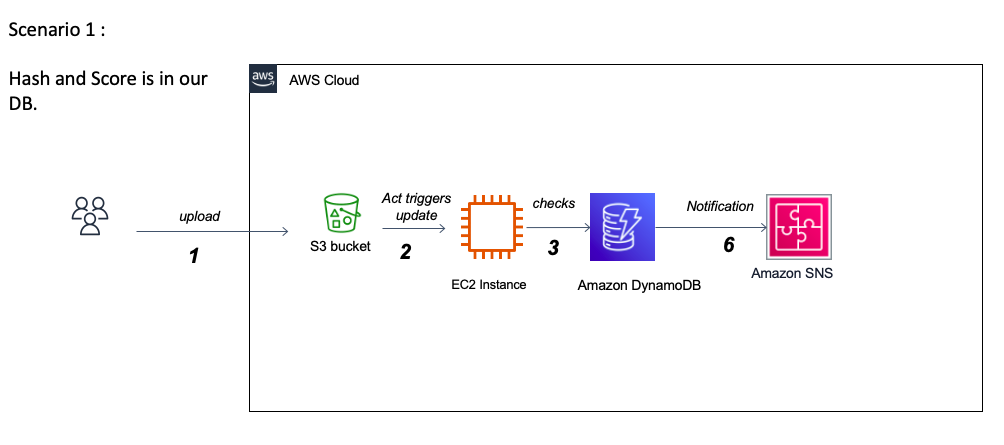
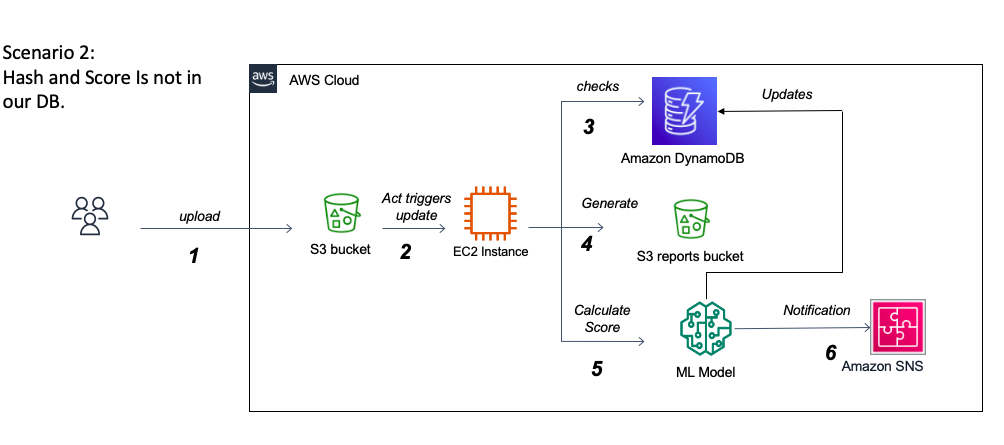
L'un des grands défis de ce projet est de traiter les rapports de Cuckoo Analysis JSON. D'une part, leur taille peut atteindre jusqu'à 500 à 700 mégaoctets, ce qui nous oblige à déterminer un moyen efficace et rapide de les charger et de les traiter. D'un autre côté, comprendre la vaste structure imbriquée des rapports et interpréter la signification de chaque section pose bien un défi et peut nécessiter l'aide d'un expert en systèmes d'exploitation. En fait, Cucou fournit des rapports très détaillés décrivant le comportement du fichier lorsqu'il est exécuté dans un environnement isolé réaliste, et en raison de cette nature détaillée et de la structure adaptative des rapports à chaque fichier soumis pour analyse, le coucou n'a pas suffisamment de documentation du contenu des rapports sur leur site Web officiel. Étant donné que les données sont principalement catégoriques avec plus de 1000 fonctionnalités possibles qui reflètent le comportement du fichier dans un environnement Windows, le défi serait d'identifier avec succès les fonctionnalités importantes qui peuvent différencier les ransomwares et les goodware. Cela nécessite que l'USTO étudie correctement l'importance des fonctionnalités et implémente différents algorithmes de sélection de variables. Nous traiterons également le problème potentiel de la multicolinéarité des variables et explorerons diverses méthodes de réduction de la dimensionnalité. Une question importante dans cette éventualité serait la pertinence de l'élimination des fonctionnalités lorsque les variables catégorielles appartiennent à une catégorie plus grande. Un autre défi dans le traitement des variables catégoriques multi-classes est lorsque l'ensemble de données de formation ne fournit pas une liste exhaustive de toutes les classes possibles. Lorsqu'il est déployé, le modèle serait très probablement confronté à des classes invisibles. Par exemple, il y a plus de 1000 appels API Windows possibles et l'ensemble de données collecté jusqu'à présent n'en contient qu'environ 250 d'entre eux. Faire face à ce problème nous obligera à explorer plusieurs stratégies pour gérer les classes invisibles pour obtenir les meilleures performances. Une option supplémentaire serait le recyclage des modèles en production avec de nouvelles données via des techniques d'apprentissage incrémentielles.
Veuillez télécharger notre code depuis GitHub et suivre les instructions ci-dessous
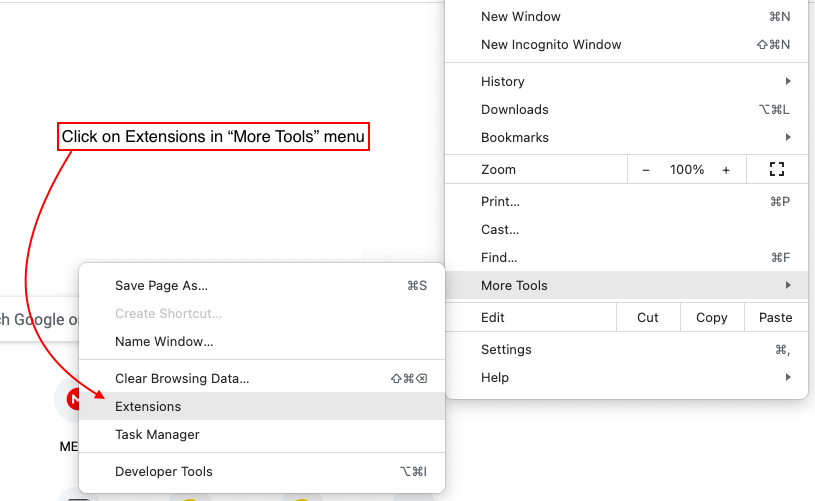
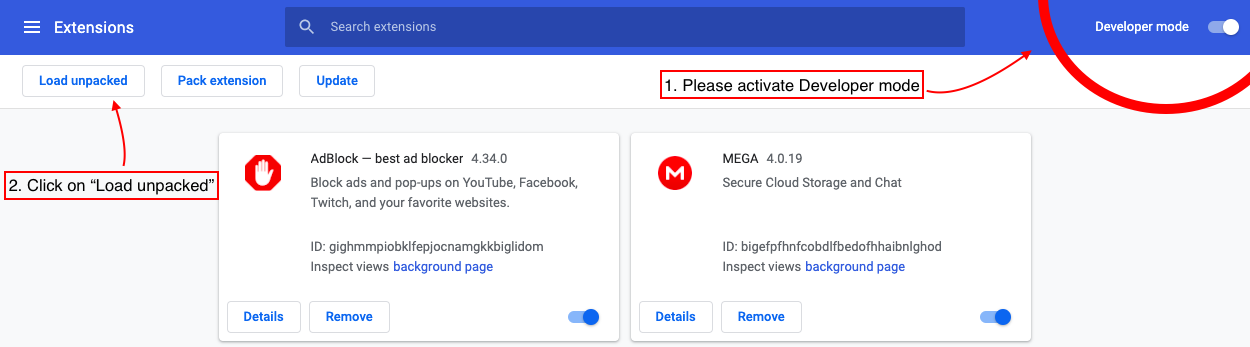
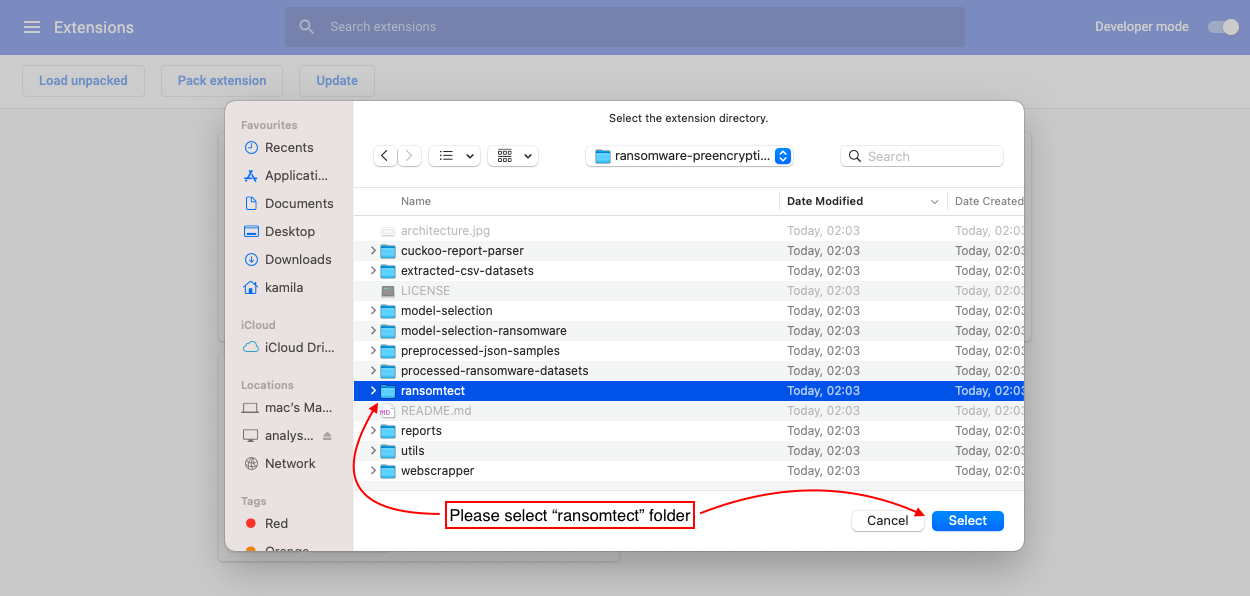
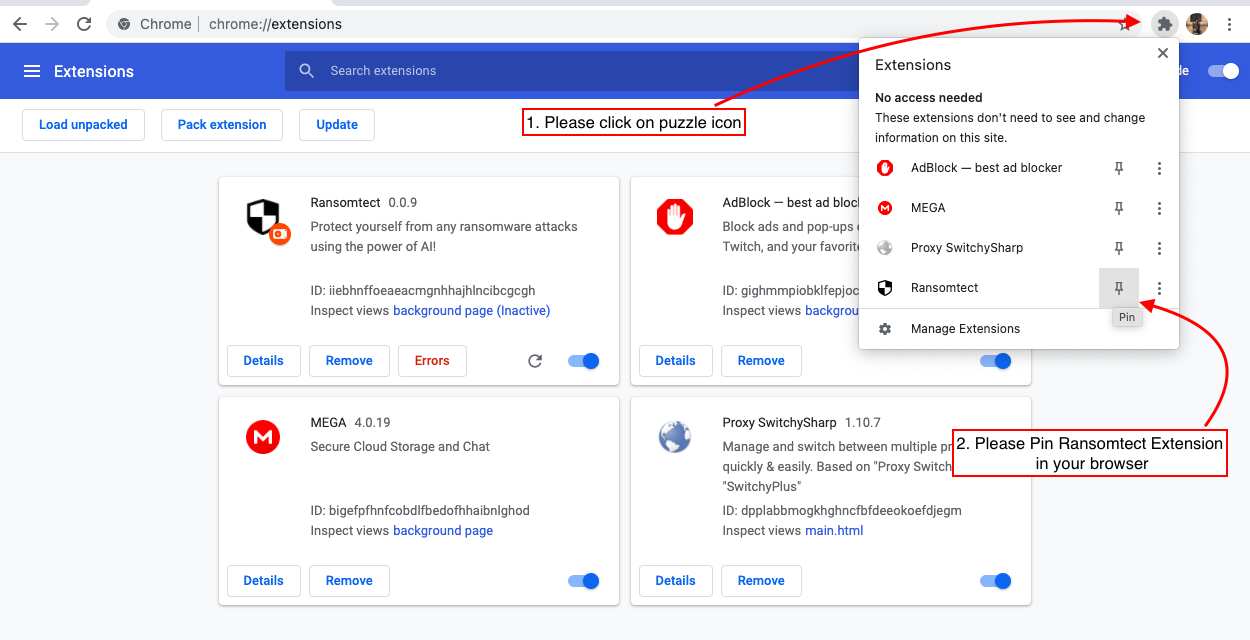 6.
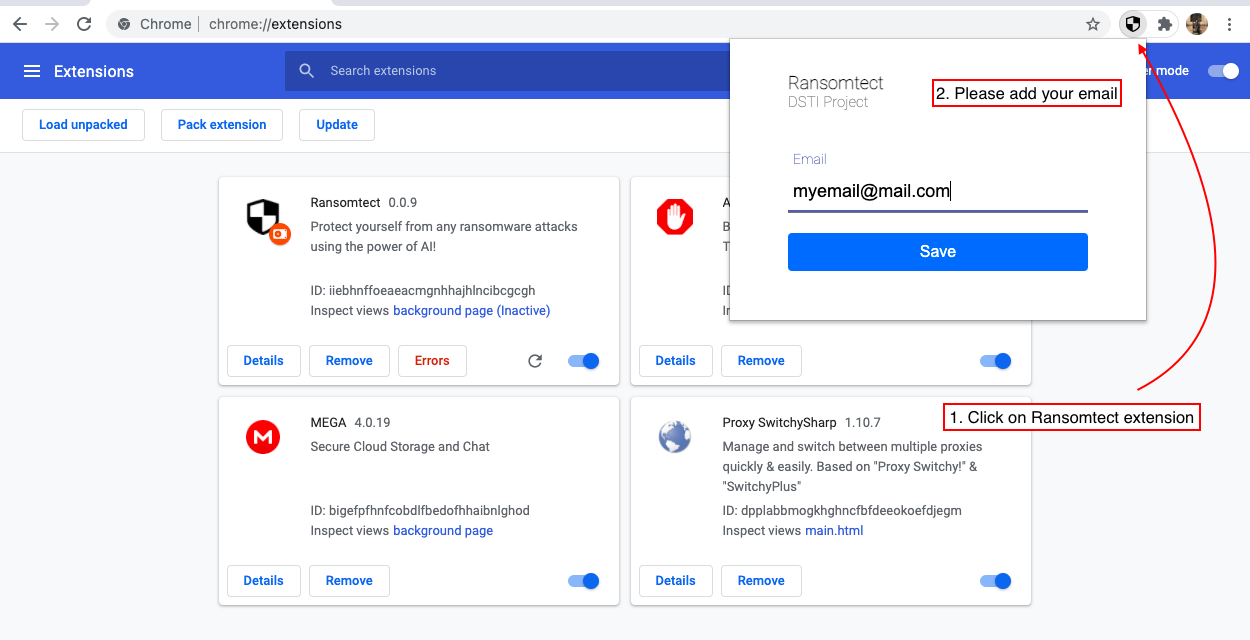
6. 
Vous êtes prêt à partir! Profitez de votre navigation en toute sécurité! 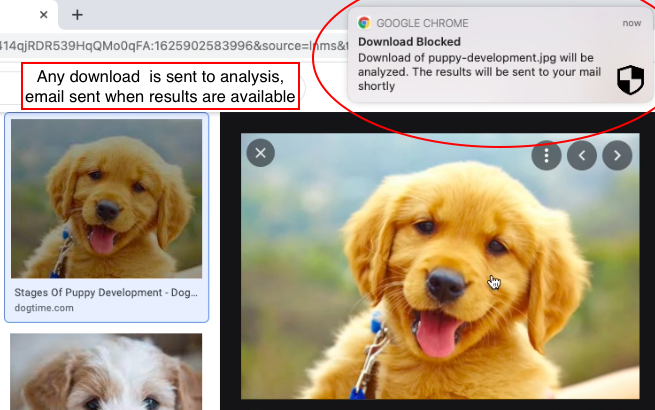
Notez que vous recevrez des e-mails dans ce format: 


