ransomware preencryption detector
1.0.0
ホストインスタンスに危険を課すことなく、暗号化前の実行ステップでランサムウェアを検出する安全な閲覧施設。
ページの下部にあるビジュアルガイドを参照してください。
2020年にのみ、ランサムウェア「ビジネス」はサイバー犯罪者に200億ドルをもたらしました。この恐ろしい人物は毎年徐々に上昇しており、既存のソリューションはこの脅威と戦うことができません。 Cybercrime Magazineによると、この数字は、現在の傾向を想定して、2031年までに2,650億ドルを超えて上昇し、2,650億ドルを超えています。
Ransomwareの成功の背後にある理由は何ですか?現在、アンチウイルスソフトウェアは最初のプロトタイプとは大きく違いはありません。それらは、既知のマルウェアのライブラリ(ハッシュ)に基づいて動作します。これは、Virustotal Onlineツールのおかげで、研究、ハニーポットなどのために収集するマルウェアのライブラリです。しかし、マルウェア、または特にランサムウェアサンプルが特定のウイルス対策に知られていない場合はどうでしょうか? - その後、アンチウイルスは、その署名がライブラリに存在しないため、悪意のあるプログラムがコンピューターに損害を与えるのを止めません。
すべてのサンプルの署名に依存する代わりに、WindowsシステムAPI呼び出しやその他のシステム情報を使用して、悪意のある動作を検出し、エンドユーザーをマルウェア/ランサムウェアのダウンロードと実行から保護することを提案します。データ収集
データを取得する前に、分析して作業する前に、Goodware、マルウェア、ランサムウェアサンプルを見つける必要がありました。後者を見つけるために、GoogleとGithubから始めて、Darknet Hacking Webサイトまで、すべての可能なオプションを使用しました。合計で、X Goodware、Xマルウェア、Xランサムウェアサンプルを収集しました。
最終的に、Cuckoo Sandbox(https://cuckoosandbox.org)のおかげで、レポートデータセットを作成しました。このサンドボックスソフトウェアは、ファイルの実行中にOSで実行されている内部プロセスに関する詳細かつ貴重な洞察を提供します。
レポートはJSONファイル構造に従います。次のように説明できます。メインファイル構造:

カッコウで取得したデータを深く分析した後、ケースから別のケースまでさまざまである可能性があることを考慮して、記事の後半で説明する特定の値を抽出することに同意しました。
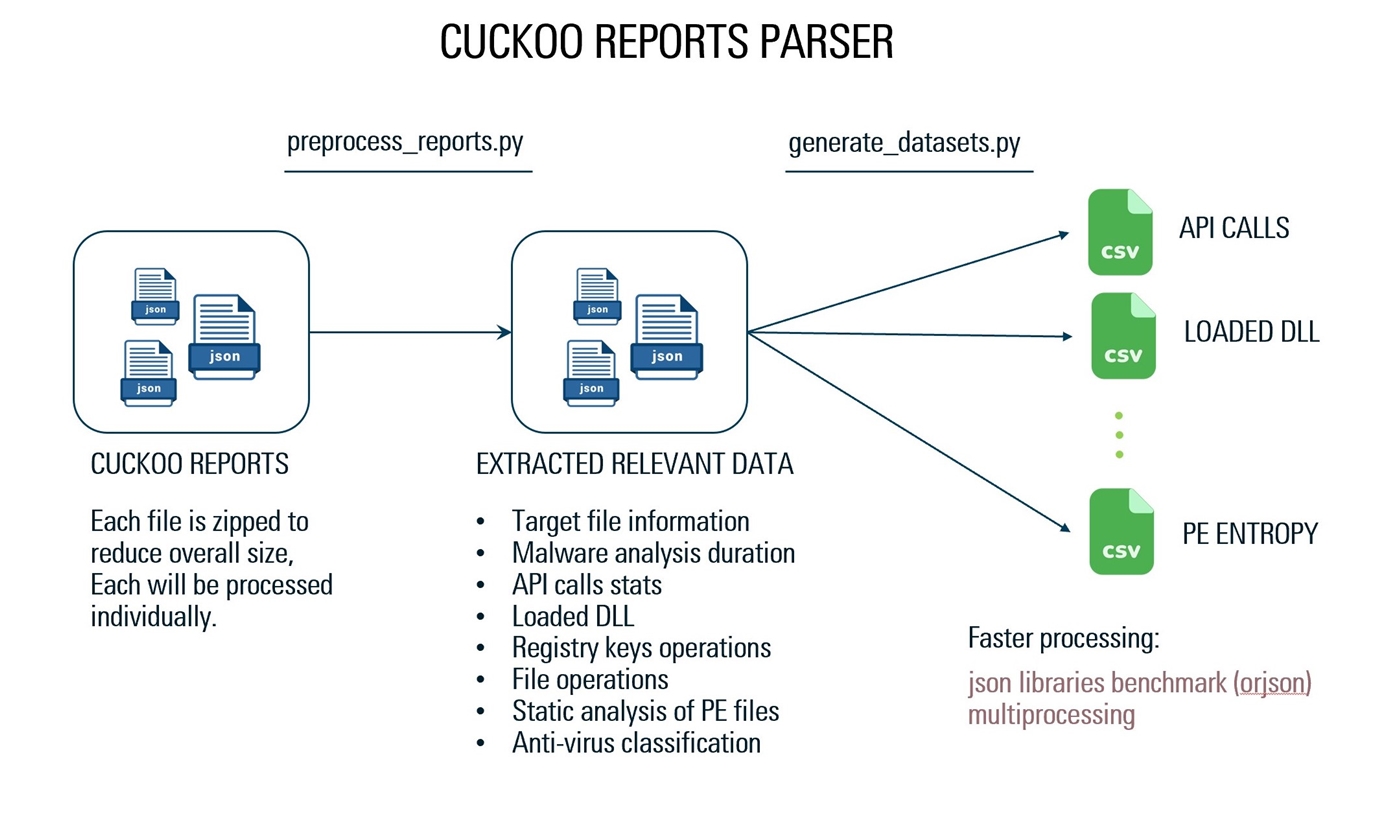
カスタムJSONパーサーを使用して、レポートから必要なデータを取得しました。レポートJSON構造、Orjson Library、およびMultiprocessingを使用して、1000のJSONレポートからデータを抽出する実装であり、合計20ギガバイトのサイズには125秒しかかかりませんでした。 (1つのファイルのサイズが1.1ギガバイトで、処理に39秒かかりました)
妥協案(IOC)の指標は、「システムログエントリやファイルにあるデータなど、システムまたはネットワーク上の潜在的に悪意のあるアクティビティを識別する法医学データの部分」です。妥協の指標は、情報違反、マルウェア感染、またはその他の脅威活動を検出する際の情報セキュリティとIT専門家です。妥協の指標を監視することにより、組織は攻撃を検出し、迅速に行動して、違反が発生しないようにしたり、以前の段階で攻撃を停止したりすることで損害賠償を制限することができます。
APIコールシステムコールは、アプリケーションプログラムインターフェイス(API)を介してオペレーティングシステムのサービスをユーザープログラムに提供します。プロセスとオペレーティングシステムの間のインターフェイスを提供して、ユーザーレベルのプロセスがオペレーティングシステムのサービスを要求できるようにします。システム呼び出しは、カーネルシステムへの唯一のエントリポイントです。
DLLは「Dynamic Link Library」の略です。 DLL(。DLL)ファイルには、Windowsプログラムでアクセスできる機能のライブラリとその他の情報が含まれています。プログラムが起動すると、必要なものへのリンクがあります。いくつかのDLLにはWindowsオペレーティングシステムが付いていますが、新しいプログラムがインストールされているときに追加されるものもあります。
ファイル操作ファイルは抽象データ型です。ファイルを適切に定義するには、ファイルで実行できる操作を考慮する必要があります。 6つの基本ファイル操作。 OSは、ファイルを作成、書き込み、読み取り、再配置、削除、および切り捨てるシステムコールを提供できます。
レジストリキー操作レジストリキーは、フォルダーに似たコンテナオブジェクトです。レジストリ値は、ファイルと同様の非コンテナーオブジェクトです。キーには値とサブキーが含まれる場合があります。キーは、バックスラッシュを使用して階層のレベルを示すものを使用して、Windowsのパス名と同様の構文で参照されます。
PEインポートPEまたはポータブル実行可能ファイルは、Windows実行可能ファイル形式です。 PE形式を調べると、Windowsの内部がどのように機能し、プログラマーが優れているかを理解することができます。しばしば難読化されたバイナリの複雑な詳細を理解したいリバースエンジニアにとって、それはさらに重要です。ファイルを実行するたびに、Windowsローダーは最初にディスクからPEファイルをロードし、メモリにマップします。 PEファイルのメモリマップはモジュールと呼ばれます。ローダーは、コンテンツ全体をディスクからメモリにコピーするだけではないことに注意することが重要です。代わりに、ローダーはヘッダー内のさまざまな値を見て、ファイル内のPEのさまざまな部分を見つけてから、その一部をメモリにマッピングします。 (http://ulsrl.org/pe-portable-xecutable/)
マルウェアエコシステムにおける低エントロピーパッキングスキームの有病率と影響敵のレバレッジ1つの一般的な手法は、バイナリを梱包することです。実行可能ファイルの梱包は、圧縮または暗号化の適用に似ており、詰め込まれたマルウェアを検出するいくつかのテクノロジーの能力を阻害する可能性があります。高いエントロピーは伝統的にパッカーの存在の巧妙な兆候でしたが、多くのマルウェアアナリストはおそらく、低エントロピーパッカーに複数回遭遇した可能性があります。多数の人気のあるツール(例えば、PEID、マナリゼ、簡単に検出)、マルウェア関連のコース、さらにはトピックに関する参考書でさえ、パックされたマルウェアはしばしば高いエントロピーを示していることを確認します。結果として、多くの研究者は、分析ルーチンでこのヒューリスティックを使用しています。また、パッカーを検出するために通常使用されるツールは、署名のマッチングに基づいており、他のヒューリスティックを組み合わせることもあることもよく知られていますが、循環する署名の多くは誤検知を帯びやすいため、結果は完全に忠実ではありません。 Cisco Talos Intelligence Group-包括的な脅威インテリジェンス:新しい研究論文:マルウェアエコシステムにおける低エントロピーパッキングスキームの有病率と影響
分類アルゴリズムに加えて、オンラインで利用可能なランサムウェアサンプルが深刻に不足しているため、Smote(合成マイノリティオーバーサンプリング技術)などの手法を使用して不均衡な分類を扱う必要があります。
また、クラスタリングアルゴリズムを試して、ワーム、トロイの木馬、スパイウェア、ラット、スティーラー、銀行家など、ランサムウェア以外のマルウェアタイプのクラスターを特定できるかどうかを確認する予定です。
Scalabilityの容易さ、需要の高い、さまざまな組み込みツールなど、古典的なサーバー指向のものと比較して多くの利点があるため、アーキテクチャにAWSを使用しました。主なコンポーネントは次のとおりです。
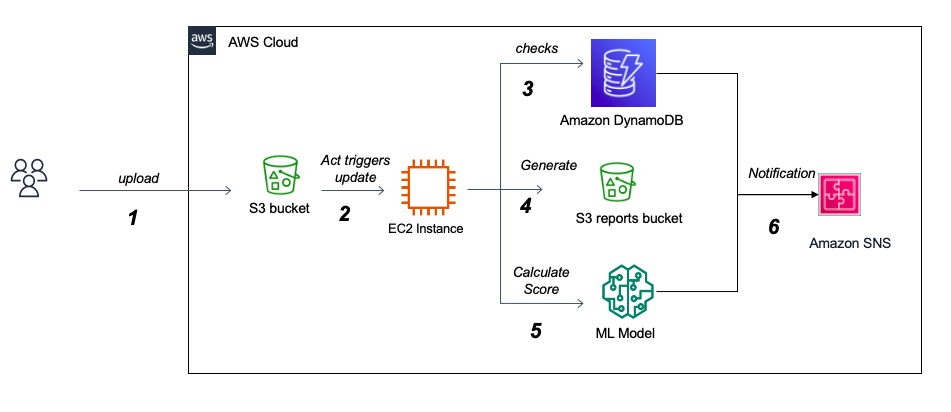
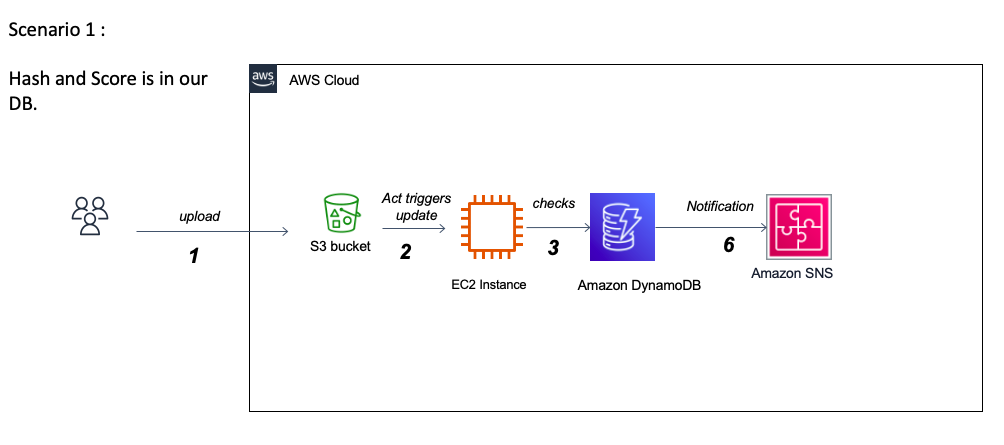
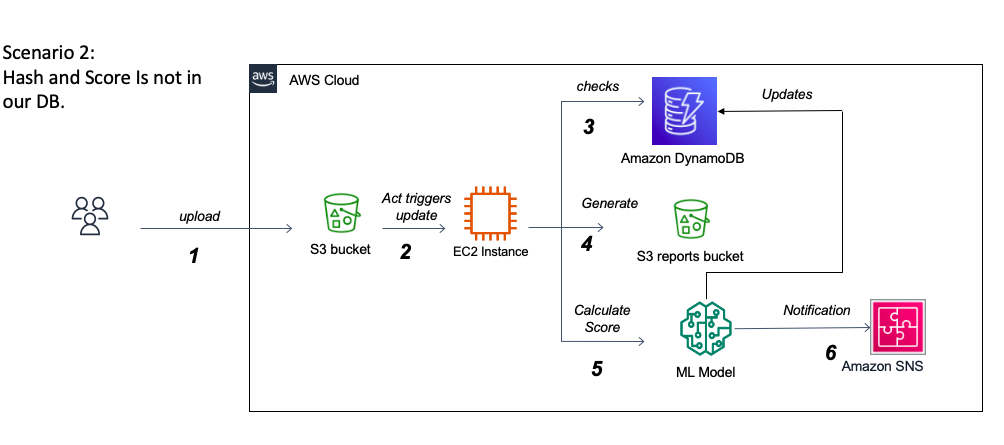
このプロジェクトの大きな課題の1つは、JSONレポートのCuckoo分析に対処することです。一方では、そのサイズは最大500〜700メガバイトに達する可能性があります。これにより、メモリを効率的かつ迅速にロードして処理する方法を把握する必要があります。一方、レポートの広範なネストされた構造を理解し、各セクションの意味を解釈するには、課題をうまく引き起こし、オペレーティングシステムの専門家の助けを必要とする場合があります。実際、Cuckooは、現実的な孤立した環境内で実行されたときにファイルの動作を概説する非常に詳細なレポートを提供します。この詳細な性質と分析のために各サビットされたファイルへのレポートの適応構造により、Cuckooは公式Webサイトにレポートの内容の十分な文書を持っていません。データは主にカテゴリー的であり、Windows環境でのファイルの動作を反映する1000を超える可能な機能があるため、課題は、ランサムウェアとGoodwareを区別できる重要な機能を正常に特定することです。これには、USTOが特徴の重要性を適切に調査し、さまざまな変数選択アルゴリズムを実装する必要があります。また、変数の多重共線性の潜在的な問題に対処し、さまざまな次元削減方法を調査します。この不測の事態における重要な問題は、カテゴリ変数がより大きなカテゴリに属している場合の機能排除の関連性です。マルチクラスのカテゴリ変数を扱う際のもう1つの課題は、トレーニングデータセットがすべての可能なクラスの徹底的なリストを提供しない場合です。展開すると、モデルはおそらく目に見えないクラスに直面するでしょう。たとえば、1000を超える可能なWindows API呼び出しがあり、これまでに収集されたデータセットには約250個しか含まれていません。この問題に対処するには、最高のパフォーマンスを達成するために、目に見えないクラスを処理するための複数の戦略を探求する必要があります。追加のオプションは、インクリメンタル学習技術を介した新しいデータを使用した生産におけるモデル再訓練です。
githubからコードをダウンロードして、以下の手順に従ってください
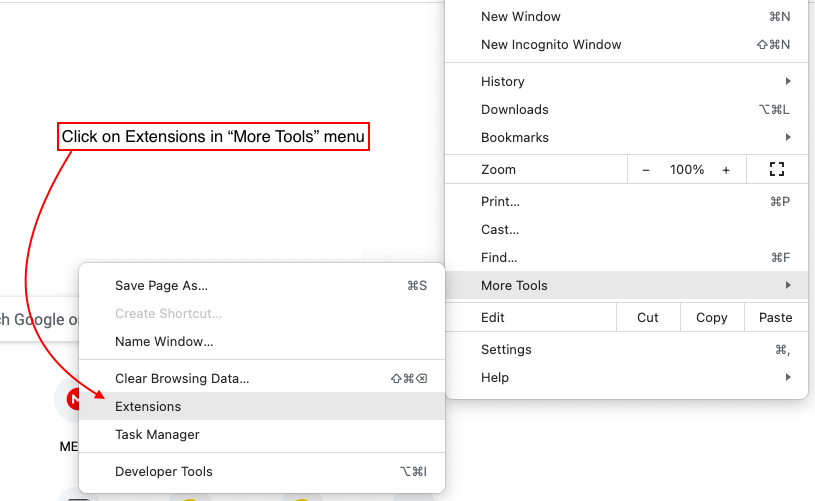
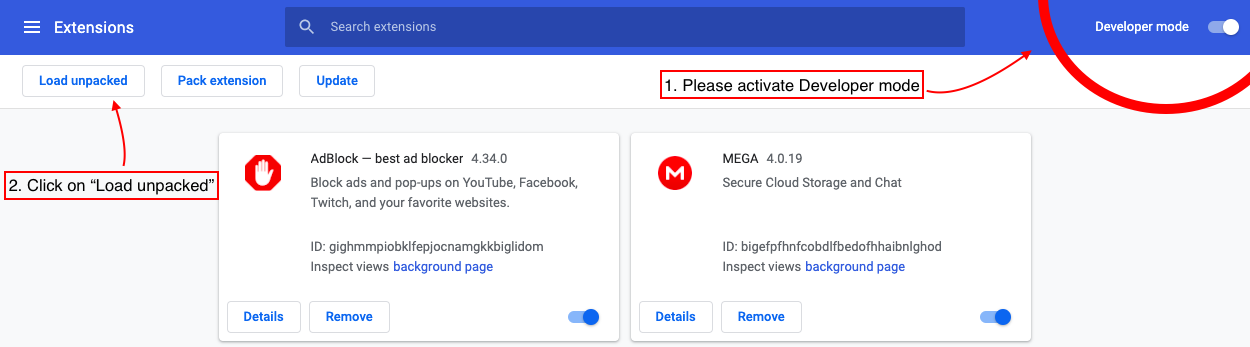
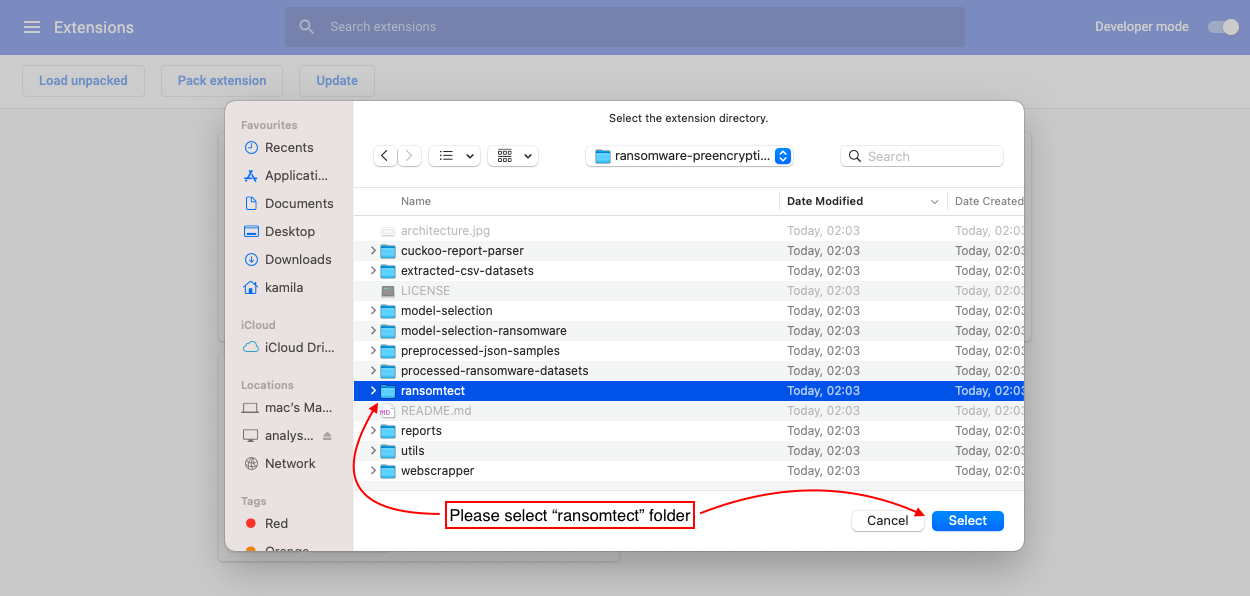
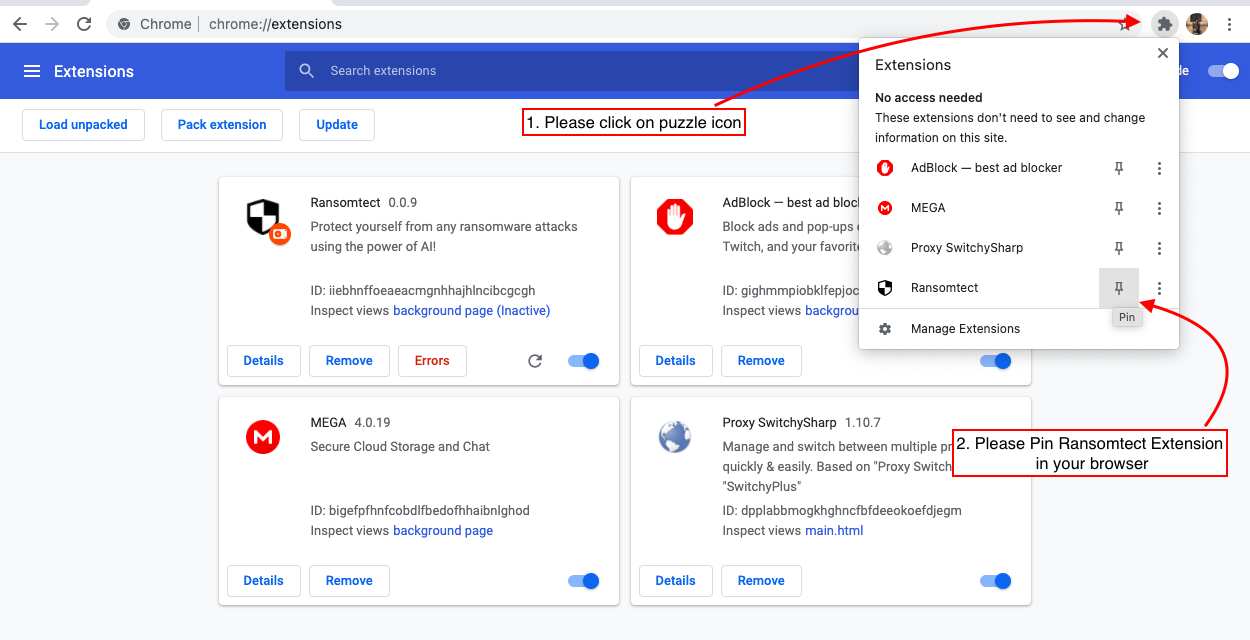 6。
6。 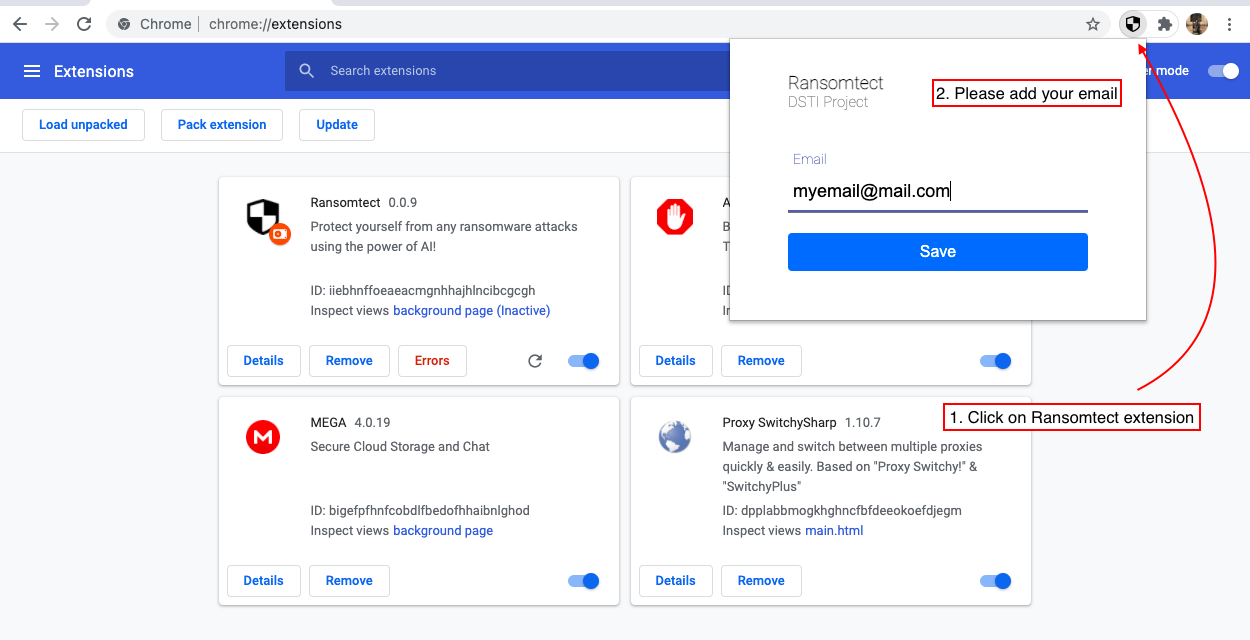
あなたは行ってもいいです!安全なブラウジングをお楽しみください! 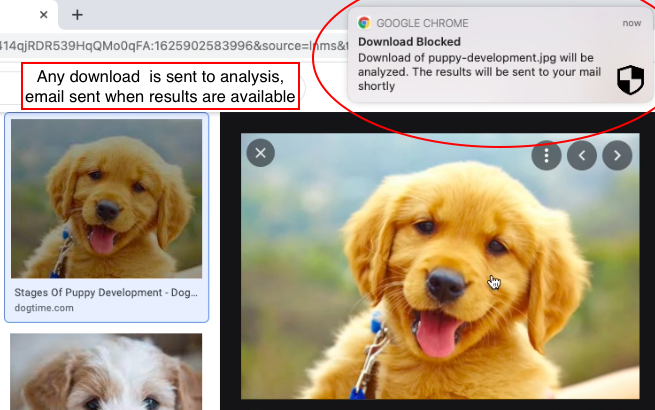
この形式でメールを受信することに注意してください。 


