LLM Minutes of Meeting
1.0.0
| 高级 | 话题 | 关联 |
|---|---|---|
| 0。 | 介绍和项目的“为什么” | 链接将来到这里 |
| 1。 | 设置和安装 | 链接将来到这里 |
| 2。 | 特征 | 另一个链接 |
| 3。 | 演示和应用程序屏幕截图 | 另一个链接 |
| 4。 | 方法和实施* | 另一个链接 |
| 5。 | 最新更新和未来的方向 | 另一个链接 |
| 6。 | 贡献 | 另一个链接 |
| 7。 | 问题/故障排除 | 另一个链接 |

该项目的主要目的是展示NLP&LLM快速总结长会议的能力,并帮助您和您的组织自动化会议记录会议(MOM)电子邮件的任务。它使用高级别2步骤方法,其中步骤1对应于将任何音频/视频文件转换为文本对话。步骤2利用步骤1产生的文本,并生成会议记录和详细的摘要说明。这些会议会议记录将是可编辑的文本。最终确定妈妈后,您可以根据需要进一步使用它。
该存储库的长期目标也是开发一个实时的Python Web应用程序,可以参加会议,并在会议结束时为您提供妈妈。采取婴儿步骤并试图通过短期目标开始长期实现。
有关您的信息:我正在研究微调自定义LLMS和开发。在整个项目完全稳定时,请耐心等待。完成后,我将添加培训和推理代码。如果需要知道最新更新,请执行此存储库。 ?感谢您的时间。
在进行之前,请确保您安装了以下内容:
virtualenv或venv 。让我们立即开始安装步骤。
克隆GitHub存储库
打开终端或命令提示符,然后导航到要克隆存储库的目录。然后运行:
git clone https://github.com/inboxpraveen/LLM-Minutes-of-Meeting
cd LLM-Minutes-of-Meeting安装要求
在安装依赖性之前,最好在安装依赖性之前创建虚拟环境,以避免与其他Python项目的潜在冲突。如果您使用的是virtualenv ,则可以设置一个新环境,如下所示:
# # Create a python virtual environment and activate it.
# Install the required packages after activating:
pip install -r requirements.txt
# # After this, let's install Llama-Cpp-Python binding which will be used to interact with LLMs.
# # Run the following line if you are using it on a CPU.
pip install llama-cpp-python
# # Run the following line if you are using GPU (T4, A100, A10, or H100), or any Nvidia Cuda based GPU Drivers.
CMAKE_ARGS= " -DLLAMA_CUDA=on " pip install llama-cpp-python
# # If you are on Mac or any other GPU types, you can refer the following links and setup the Llama-Cpp-Python
https://llama-cpp-python.readthedocs.io/en/stable/ # installation-configuration
https://llama-cpp-python.readthedocs.io/en/stable/install/macos/设置RabbitMQ和芹菜背景工作处理
使用以下链接以在计算机上设置RabbitMQ。按照指示直到步骤5 ,并保存您的admin-username和password 。
Ubuntu上的设置RabbitMQ 22.04
一旦您成功设置了RabbitMQ,然后设置了Redis服务器和芹菜。使用以下命令进行设置并安装它们。
sudo apt-get update -y
# # Try with apt-get. If it does not install, then run with apt.
sudo apt-get install redis-server -y
# # If the above does not work, try this:
sudo apt install redis-server -y运行应用程序和并行运行芹菜任务
首先,启动烧瓶应用程序:
cd /path/to/project/然后打开代码编辑器内部的app.py文件,然后修改以下行。
Line 18 : broker = 'amqp://<user>:<password>$@localhost:5672//'
## Update <user> with "your-admin-username".
## Update <password> with "your-admin-password"
## Eg: broker='amqp://admin:hello_world$@localhost:5672//'
### IMPORTANT NOTE: If your password contains '@' symbol, you will need to convert it because it is the default delimiter in broker settings. Example if your password has @ symbol inside it would be.
## broker='amqp://admin:hello%40world$@localhost:5672//' -- where the original password was "hello@world", we represent it as 'hello%40world'更新文件后,您将运行setup.py文件到设置目录和模型下载。如果要更改要使用的模型的配置,则可以根据基础架构的大小和系统容量来适当地更改它们。下表显示了我们当前在该项目中支持的模型,但我们将在看到它们合适和开源时添加新的LLMS支持。
支持语音模型
| 模型名称 | 型号大小 | 需要内存(RAM或VRAM) |
|---|---|---|
| 大扭曲/大滴虫-V3 | 3.1 GB | 4GB |
| 扭曲/大滴虫 - 大v2 | 3.1 GB | 4GB |
| 大扭曲/滴虫中的en | 1.6 GB | 2 GB |
| 大呼吸/迪士尔 - small.en | 680 MB | 900 MB |
| Openai/hisper-large-v3 | 6.2 GB | 7.5 GB |
| Openai/hisper-large-v2 | 6.2 GB | 7.5 GB |
| Openai/hisper-large-v1 | 6.2 GB | 7.5 GB |
| Openai/Whisper-Medium | 3.2 GB | 4.5 GB |
| Openai/hisper-small(默认) | 980 MB | 1.7 GB |
LLMS受支持
| 模型名称 | 型号大小 | 需要内存 |
|---|---|---|
| 量化/phi-3-mini-4k-Instruct-gguf(默认) | 1 GB -8 GB | 2 GB -14 GB |
| 量化/phi-3-mini-128k-instruct-gguf | 1 GB -8 GB | 2.5 GB -16 GB |
| Bartowski/Phi-3-Medium-128k-Instruct-Gguf | 3 GB -14 GB | 6 GB -18 GB |
您将需要使用选择的模型名称修改global_varibables.py文件,然后运行setup.py文件,该文件将自动下降您选择的型号。
Line 32 : DEFAULT_SPEECH_MODEL = "openai/whisper-small"
...
Line 46 : DEFAULT_SUMMARY_MODEL = ( "QuantFactory/Phi-3-mini-4k-instruct-GGUF" , "Phi-3-mini-4k-instruct.Q5_0.gguf" )
### After update the above lines as per your need, run the setup.py
python setup . py在新的终端窗口(确保您的虚拟环境也在此处激活),启动应用程序和芹菜工作人员:
python app.py # ensure your environment is activated
# and then in new terminal, run the following.
celery -A app.celery worker --loglevel=info -f celery.logs上传记录以形式
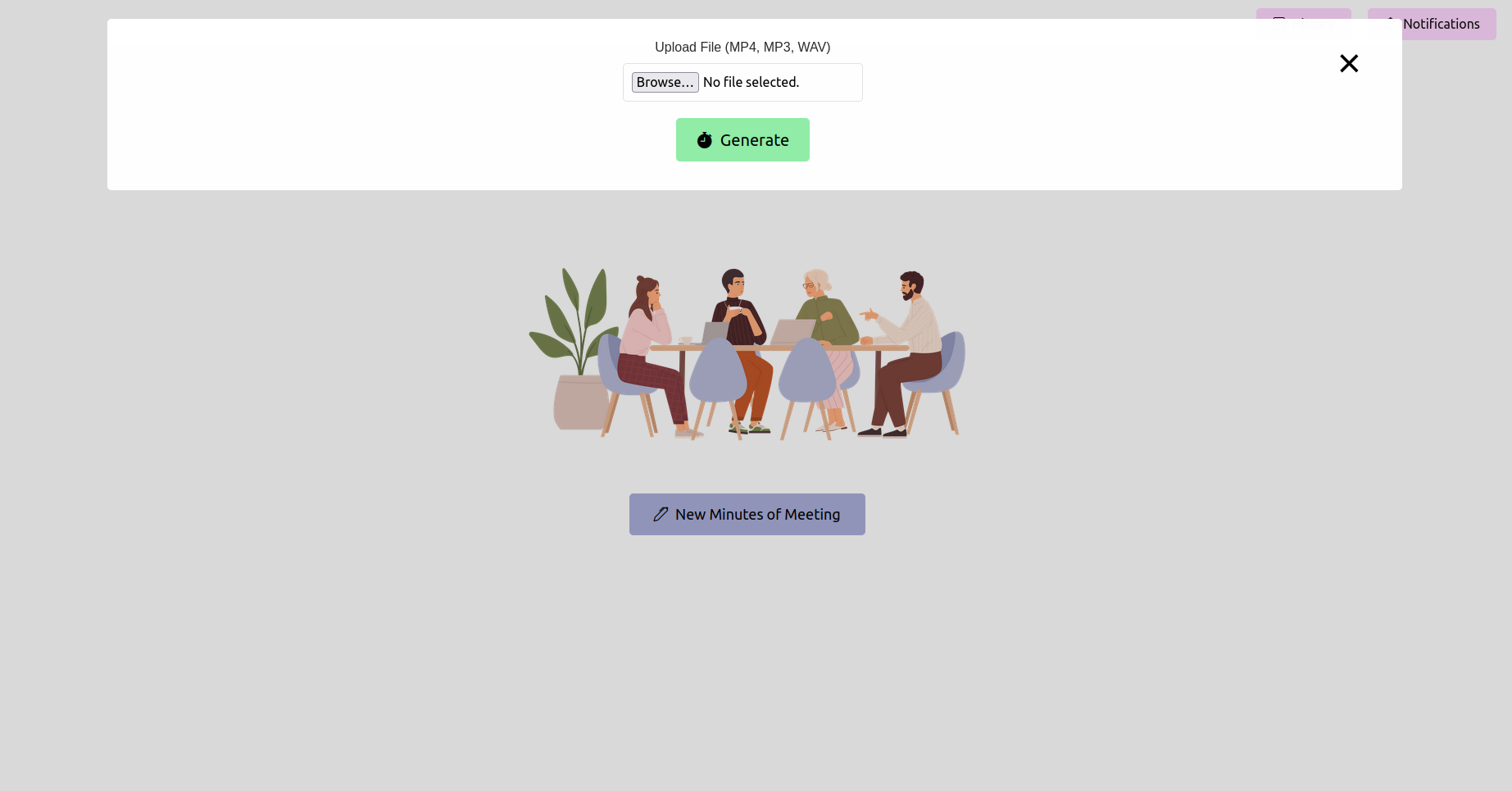
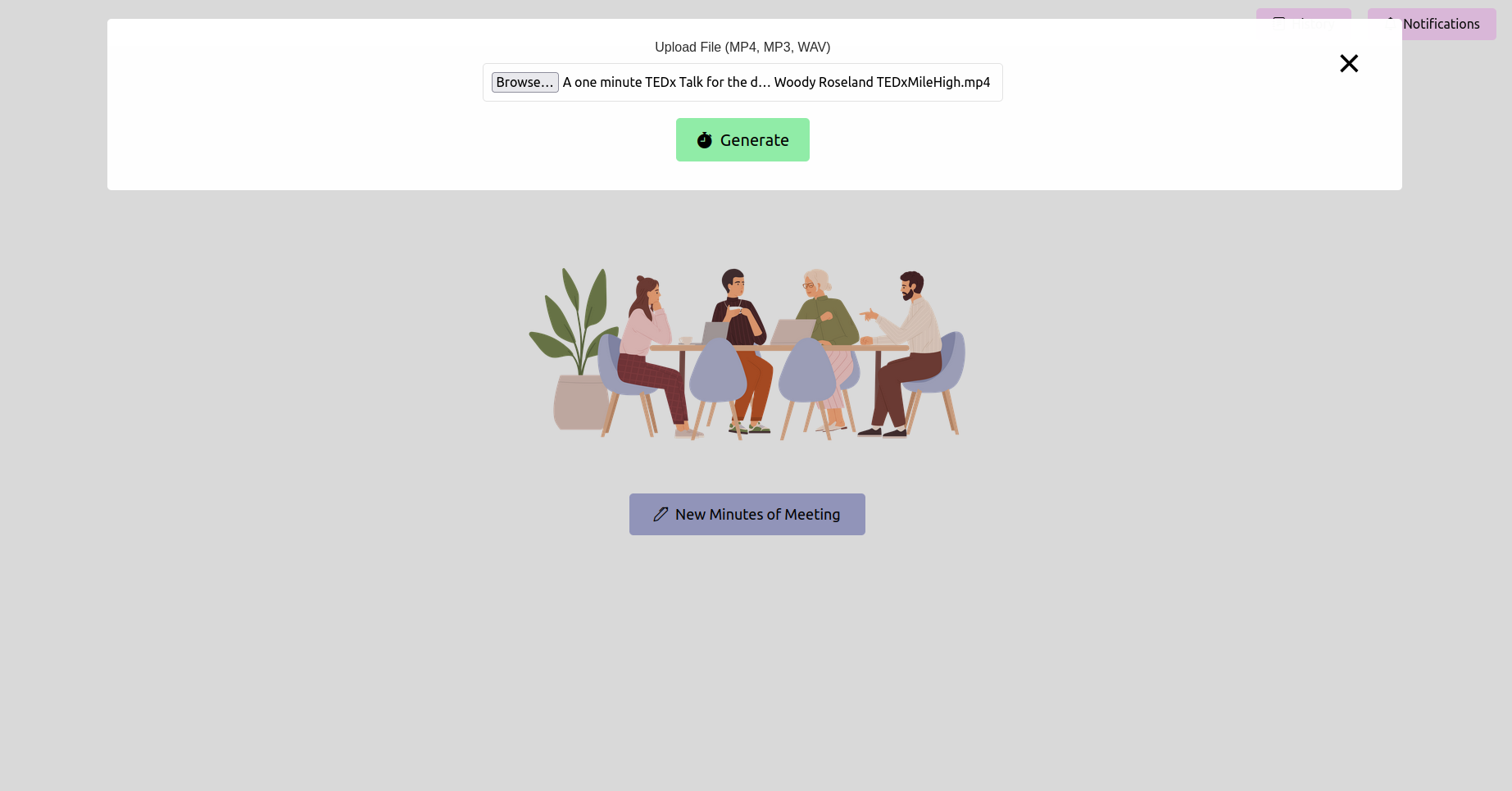
打开Web浏览器并导航到烧瓶应用程序的URL(通常是http://127.0.0.1:5000 )。使用该界面上传您的会议记录。
获得最新状态,等待完成
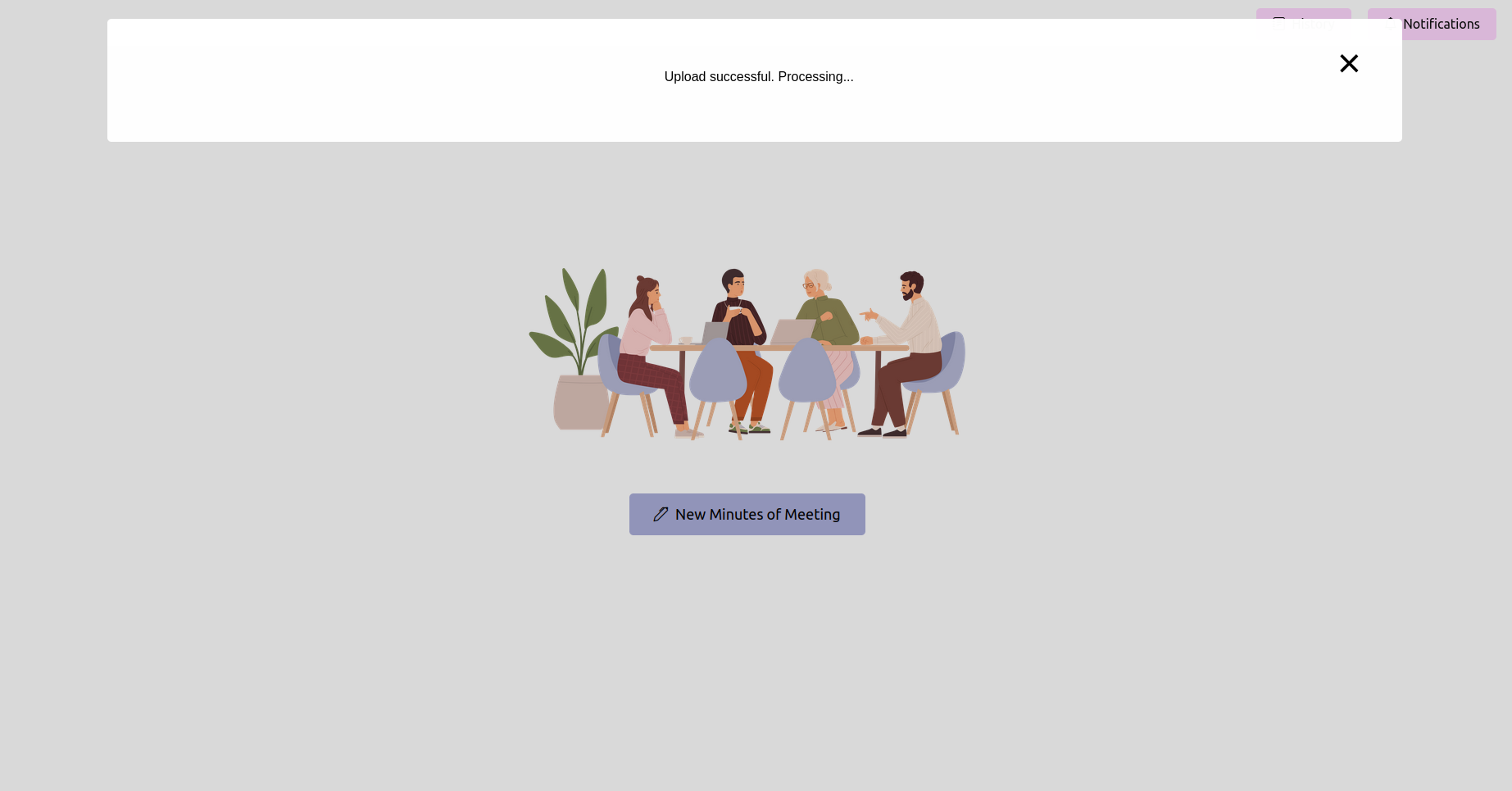
上传记录后,您可以检查处理的状态。这可以作为状态页面或应用程序中的进度栏实现。等到处理完成。
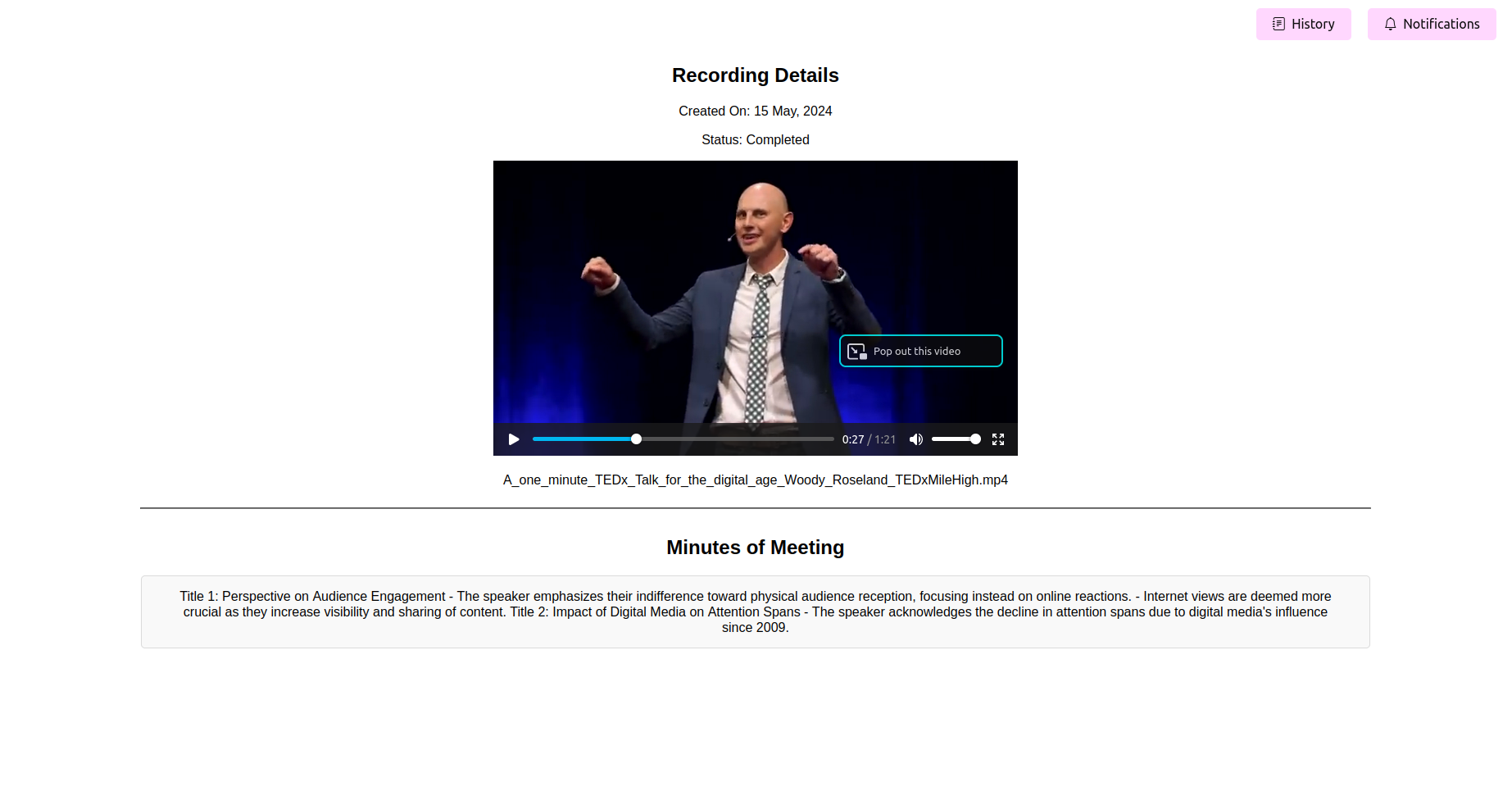
请参阅会议的最后一分钟(妈妈)
处理完成后,申请应显示会议的最后几分钟。您可以查看,编辑(如果功能可用),然后保存妈妈以供参考。
毫不费力地将音频和视频文件转换为准确的文本成绩单:这些也可用于总结,生成操作项目,了解工作流程和资源计划。
关键字突出显示和主题标记以进行快速参考:提取主题并找到相关内容以跳过会议,并仅聆听您感兴趣的特定主题。
以各种格式导出分钟,包括PDF和纯文本:允许您将会议记录,摘要,主题和关键字,操作项等导出到可以在项目计划和管理框架中使用的文档。还消除了您手动编写和生成模板的需求。
用户友好的界面,可轻松自定义和集成:您想选择的开源或封闭源模型易于调整。
核心功能围绕处理通过Web应用程序主页提交的处理会议记录。提交录音后,使用芹菜开始了背景任务,该任务将执行两个主要操作:语音到文本转换,并从转换后的文本中生成会议的会议记录。
您共享的流程图概述了处理和处理媒体文件的详细过程,尤其是专注于音频和视频输入以生成转录和摘要。让我们分解每个步骤,描述此工作流中涉及的高级解决方案:
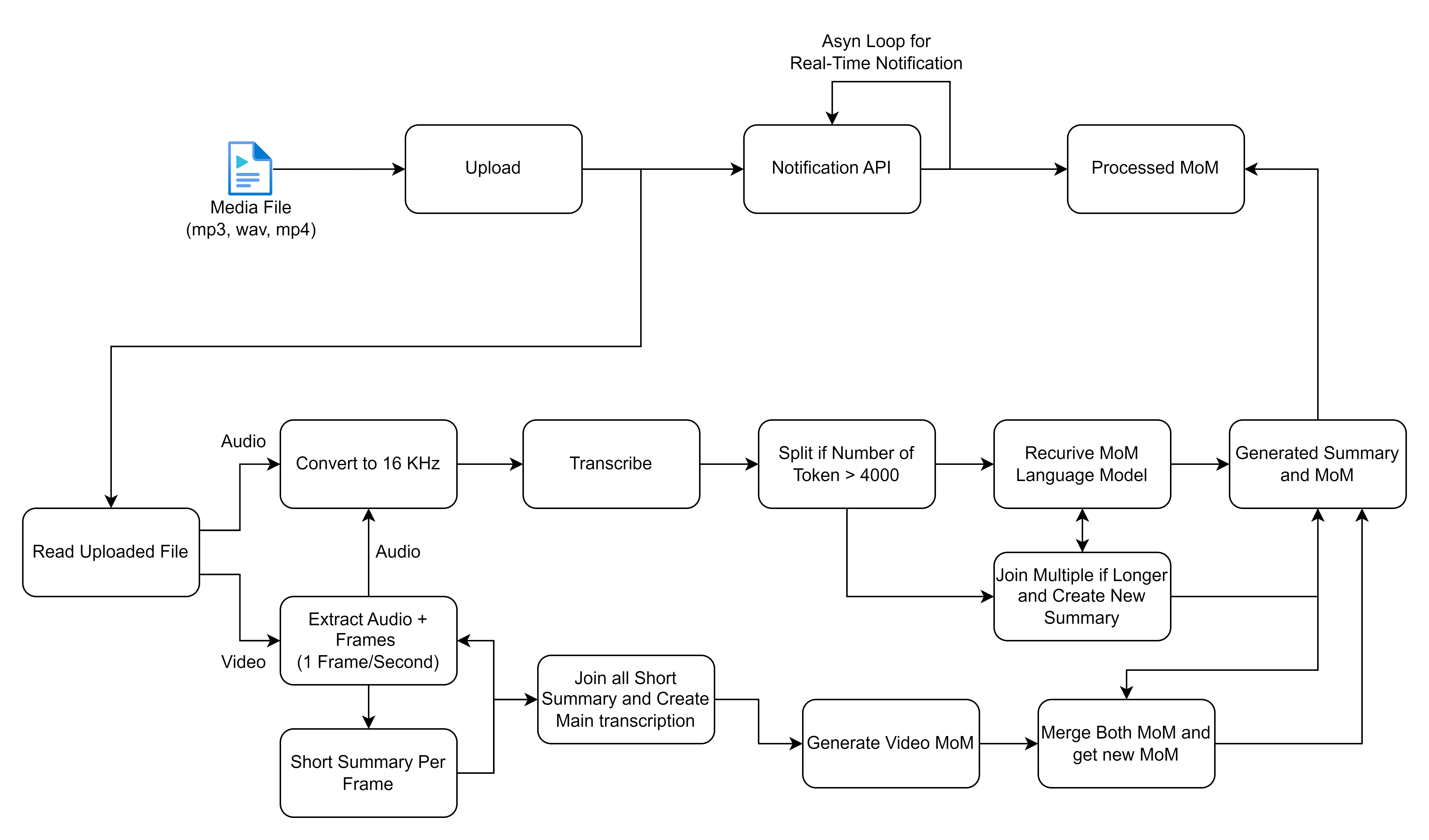




在进行之前,请确保您安装了以下内容:
virtualenv或venv 。requirements.txt 。 在我们项目的第二阶段中,我们计划启用实时会议转录。加入我们,塑造高效和协作会议的未来!
?关注我以获取有关第二阶段开发和其他增强功能的最新信息,以使您的会议更加富有成效。
?鼓励社区的贡献使该工具成为改变各地会议的游戏规则。贡献您的想法和专业知识,以帮助我们实现实时转录!


