LLM Minutes of Meeting
1.0.0
| Sr. No. | Tema | Enlace |
|---|---|---|
| 0. | Introducción y "por qué" del proyecto | El enlace vendrá aquí |
| 1. | Configuración e instalación | El enlace vendrá aquí |
| 2. | Características | Otro enlace |
| 3. | Capturas de pantalla de demostración y aplicación | Otro enlace |
| 4. | Enfoque e implementación* | Otro enlace |
| 5. | Actualizaciones recientes y direcciones futuras | Otro enlace |
| 6. | Contribuciones | Otro enlace |
| 7. | Problemas/Solución de problemas | Otro enlace |

El objetivo principal de este proyecto es mostrar la capacidad de NLP & LLM para resumir rápidamente las largas reuniones y ayudarlo a usted y su organización automatizar la tarea de delegar minutos de correos electrónicos de reuniones (MOM). Utiliza un enfoque de alto nivel de nivel 2 donde el paso 1 corresponde a la conversión de cualquier archivo de audio/video en una conversación de texto. El paso 2 utiliza el texto producido por el Paso 1 y genera minutos de reunión y notas de resumen detalladas. Estas actas de reunión serán un texto editable. Una vez que finalice a la madre, puede usarla más según sus requisitos.
El objetivo a largo plazo para este repositorio también es desarrollar una aplicación web de Python en tiempo real que pueda asistir a reuniones para usted y también proporcionarle a su madre al final de la reunión. Tomar pasos para bebés y tratando de llegar a largo plazo comenzando un objetivo a corto plazo.
Para su información: estoy trabajando en el ajuste de LLMS y el desarrollo personalizados. Tenga paciencia mientras todo el proyecto sea completamente estable. Agregaré código de entrenamiento e inferencia una vez completado. Haga este repositorio si necesita saber las últimas actualizaciones. ? Aprecia tu tiempo.
Antes de continuar, asegúrese de tener lo siguiente instalado:
virtualenv o venv .Comencemos los pasos de instalación ahora.
Clon el repositorio de Github
Abra su terminal o símbolo del sistema y navegue al directorio donde desea clonar el repositorio. Luego corre:
git clone https://github.com/inboxpraveen/LLM-Minutes-of-Meeting
cd LLM-Minutes-of-MeetingRequisitos de instalación
Es una buena práctica crear un entorno virtual antes de instalar dependencias para evitar posibles conflictos con otros proyectos de Python. Si está utilizando virtualenv , puede configurar un nuevo entorno de la siguiente manera:
# # Create a python virtual environment and activate it.
# Install the required packages after activating:
pip install -r requirements.txt
# # After this, let's install Llama-Cpp-Python binding which will be used to interact with LLMs.
# # Run the following line if you are using it on a CPU.
pip install llama-cpp-python
# # Run the following line if you are using GPU (T4, A100, A10, or H100), or any Nvidia Cuda based GPU Drivers.
CMAKE_ARGS= " -DLLAMA_CUDA=on " pip install llama-cpp-python
# # If you are on Mac or any other GPU types, you can refer the following links and setup the Llama-Cpp-Python
https://llama-cpp-python.readthedocs.io/en/stable/ # installation-configuration
https://llama-cpp-python.readthedocs.io/en/stable/install/macos/Configurar el procesamiento de trabajo de antecedentes de RabbitMQ & Ceyery
Use el siguiente enlace para configurar RabbitMQ en su máquina. Siga las instrucciones hasta el paso 5 y guarde su nombre de usuario y password admin-username .
Configurar conejos en Ubuntu 22.04
Una vez que haya configurado con éxito RabbitMQ, configure Redis-Server y Celery. Use el siguiente comando para configurarlos e instalarlos.
sudo apt-get update -y
# # Try with apt-get. If it does not install, then run with apt.
sudo apt-get install redis-server -y
# # If the above does not work, try this:
sudo apt install redis-server -yEjecutar la aplicación y la tarea de apio en ejecución paralela
Primero, inicie la aplicación Flask:
cd /path/to/project/y luego abra el archivo App.py dentro de su editor de códigos y modifique la siguiente línea.
Line 18 : broker = 'amqp://<user>:<password>$@localhost:5672//'
## Update <user> with "your-admin-username".
## Update <password> with "your-admin-password"
## Eg: broker='amqp://admin:hello_world$@localhost:5672//'
### IMPORTANT NOTE: If your password contains '@' symbol, you will need to convert it because it is the default delimiter in broker settings. Example if your password has @ symbol inside it would be.
## broker='amqp://admin:hello%40world$@localhost:5672//' -- where the original password was "hello@world", we represent it as 'hello%40world' Después de haber actualizado el archivo, ejecutará el archivo setup.py para configurar directorios y descargar modelos. Si desea cambiar las configuraciones de los modelos que desea usar, puede cambiarlos adecuadamente en función de su tamaño de infraestructura y capacidad del sistema. La siguiente tabla muestra qué modelos admitimos actualmente en este proyecto, pero agregaremos un nuevo soporte de LLMS a medida que los vemos en forma y de código abierto.
Modelos de habla apoyados
| Nombre del modelo | Tamaño del modelo | Memoria requerida (RAM o VRAM) |
|---|---|---|
| destilado | 3.1 GB | 4 GB |
| destilado | 3.1 GB | 4 GB |
| DISTIL-WHISPER/DISTIL-MIDIUM.EN | 1.6 GB | 2 GB |
| destilado | 680 MB | 900 MB |
| OpenAI/Whisper-Large-V3 | 6.2 GB | 7.5 GB |
| OpenAI/Whisper-Large-V2 | 6.2 GB | 7.5 GB |
| OpenAI/Whisper-Large-V1 | 6.2 GB | 7.5 GB |
| OPERAI/Whisper-Medio | 3.2 GB | 4.5 GB |
| OpenAI/Whisper-Small (predeterminado) | 980 MB | 1.7 GB |
LLMS admitido
| Nombre del modelo | Tamaño del modelo | Se requiere memoria |
|---|---|---|
| QuantFactory/Phi-3-Mini-4K-InStruct-GGUF (predeterminado) | 1 GB - 8 GB | 2 GB - 14 GB |
| QuantFactory/Phi-3-Mini-128K-Instructo-GGUF | 1 GB - 8 GB | 2.5 GB - 16 GB |
| Bartowski/Phi-3-Medium-128K-Instructo-GGUF | 3 GB - 14 GB | 6 GB - 18 GB |
Deberá modificar el archivo global_varibables.py con el nombre del modelo que elija y luego ejecute el archivo setup.py que depositará automáticamente los modelos que elija.
Line 32 : DEFAULT_SPEECH_MODEL = "openai/whisper-small"
...
Line 46 : DEFAULT_SUMMARY_MODEL = ( "QuantFactory/Phi-3-mini-4k-instruct-GGUF" , "Phi-3-mini-4k-instruct.Q5_0.gguf" )
### After update the above lines as per your need, run the setup.py
python setup . pyEn una nueva ventana de terminal (asegúrese de que su entorno virtual se active aquí también), inicie la aplicación y el trabajador de apio:
python app.py # ensure your environment is activated
# and then in new terminal, run the following.
celery -A app.celery worker --loglevel=info -f celery.logsSubir la grabación para formar
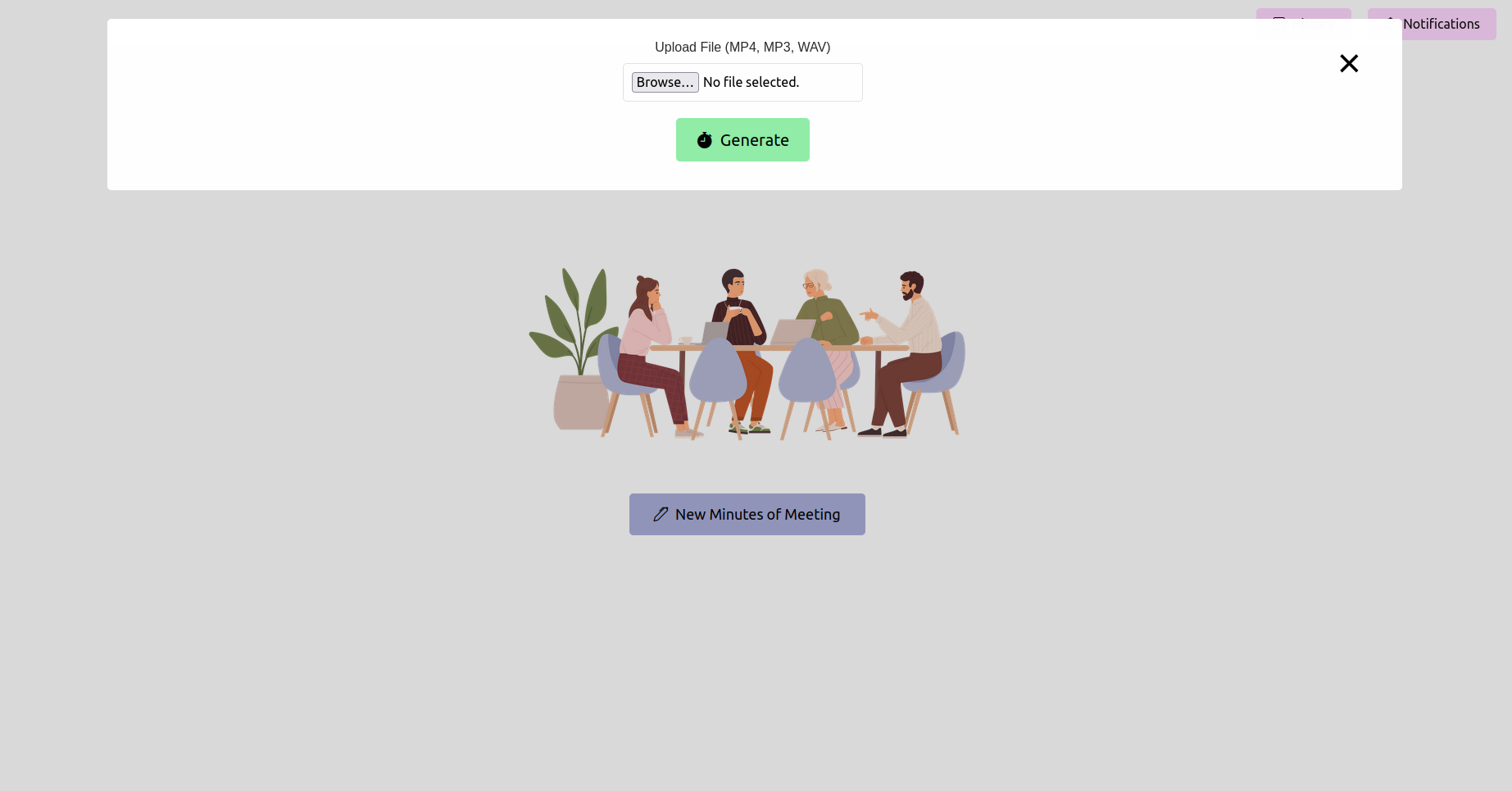
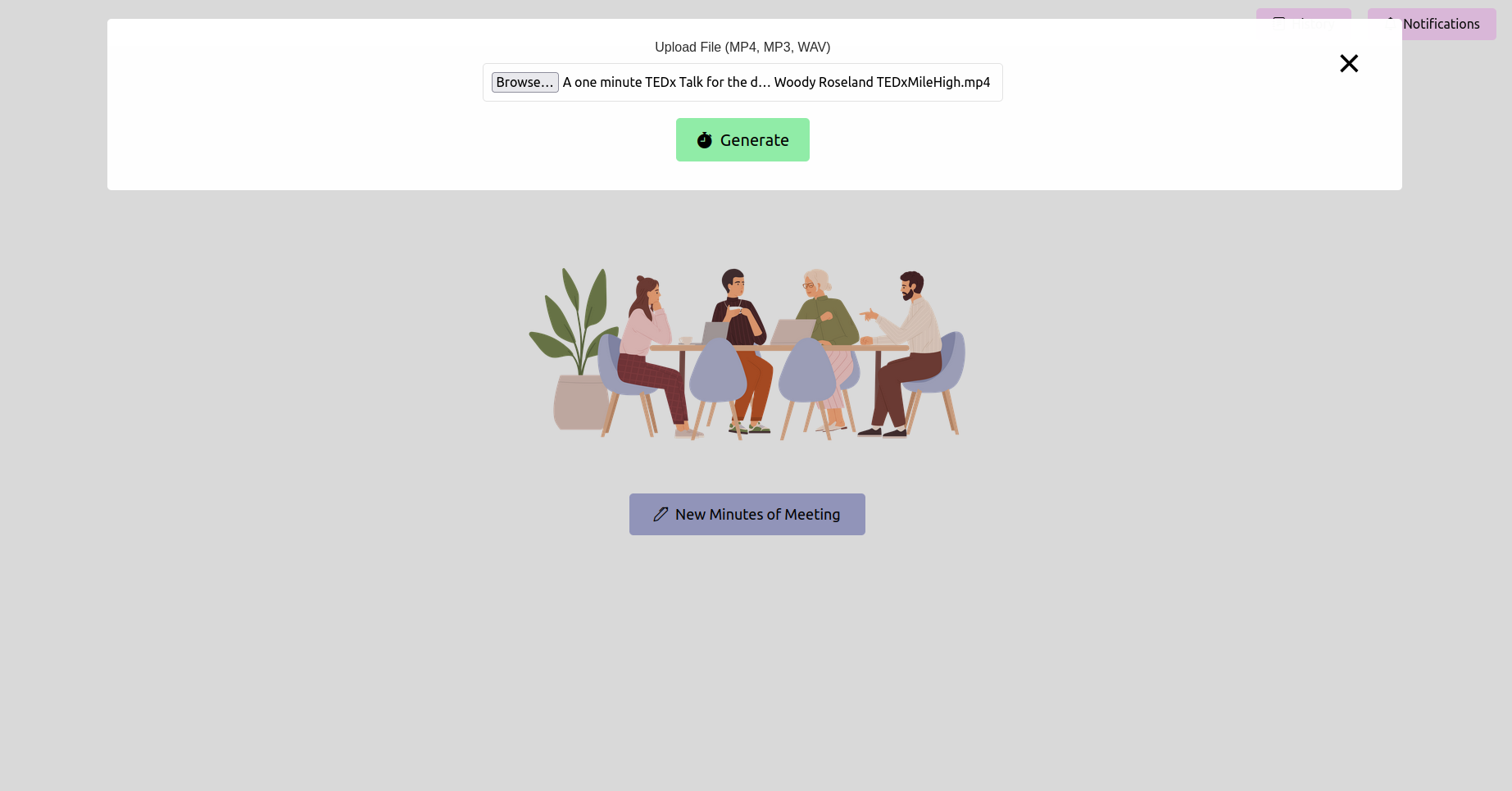
Abra su navegador web y navegue a la URL de la aplicación Flask (generalmente http://127.0.0.1:5000 ). Use la interfaz para cargar la grabación de su reunión.
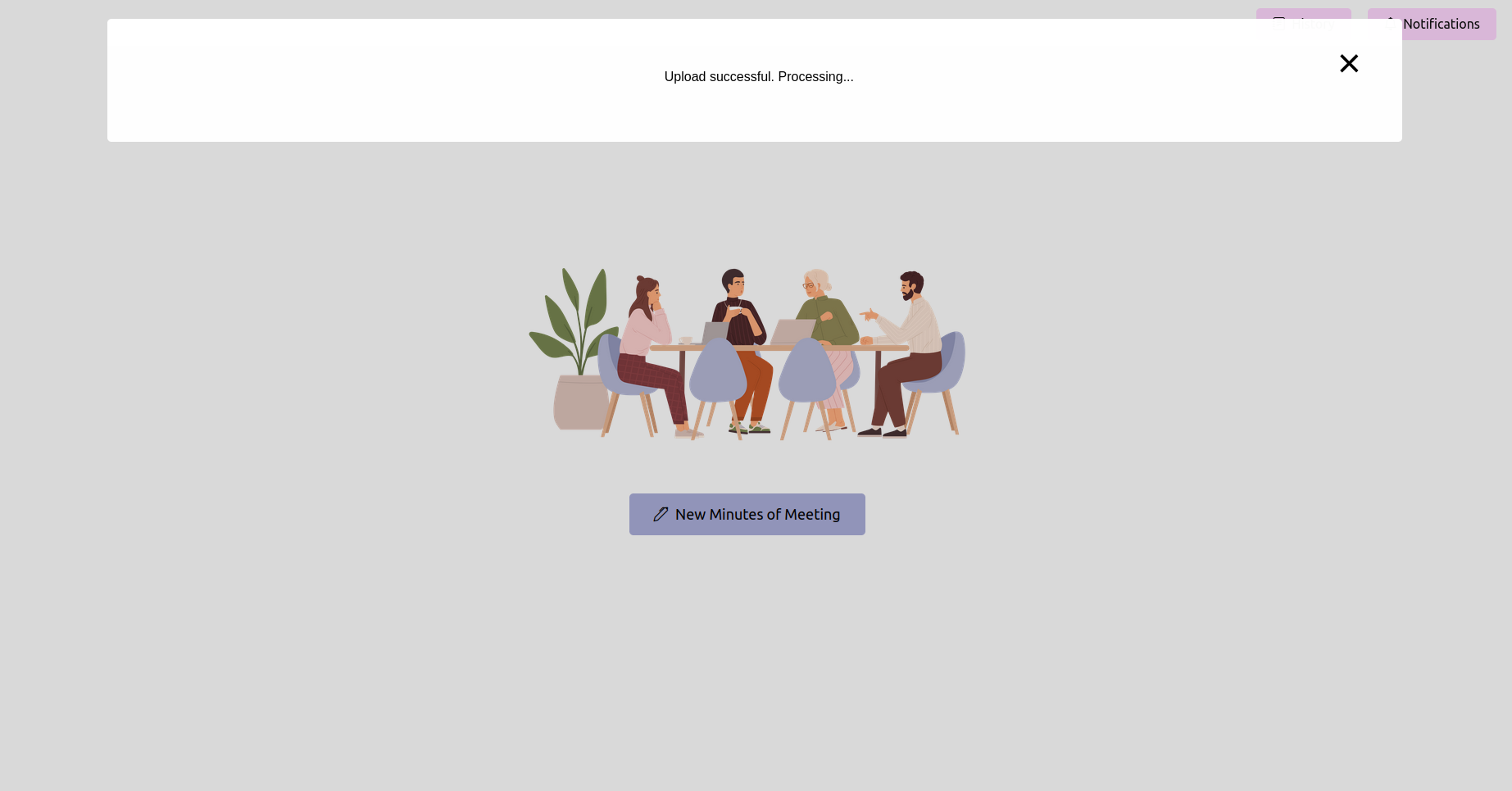
Obtenga el último estado y espere a que se complete
Después de cargar la grabación, puede verificar el estado del procesamiento. Esto podría implementarse como una página de estado o una barra de progreso en su aplicación. Espere hasta que se complete el procesamiento.
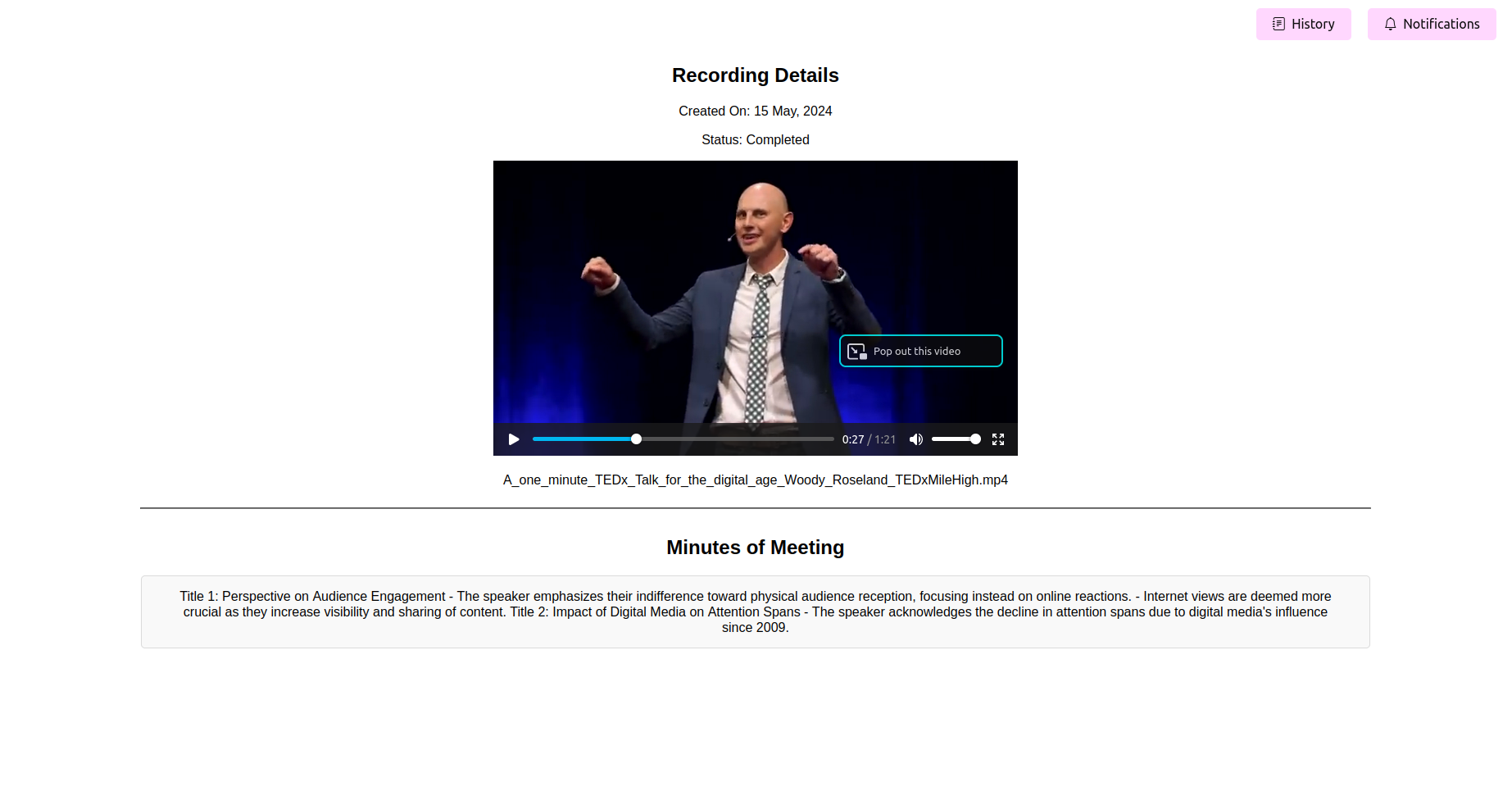
Vea las actas finales procesadas de la reunión (mamá)
Una vez que se completa el procesamiento, la solicitud debe mostrar las actas finales de la reunión. Puede ver, editar (si la función está disponible) y guardar la madre para su referencia.
Convierta sin esfuerzo archivos de audio y video a transcripciones precisas de texto: también se pueden usar para resumir, generar elementos de acción, comprender las flujos de trabajo y la planificación de recursos.
Destacación de palabras clave y etiquetado de temas para referencia rápida: extraer temas y encontrar contenido relevante para saltar a través de reuniones y escuchar solo temas específicos que son de su interés.
Minutes de exportación en varios formatos, incluidos PDF y texto sin formato: le permite exportar transcripciones de reuniones, resúmenes, temas y palabras clave, elementos de acción, etc. en documentos que pueden utilizarse en los marcos de planificación y gestión de proyectos. También elimina su necesidad de escribir y generar plantillas manualmente.
Interfaz fácil de usar para una fácil personalización e integración: fácil de ajustar el modelo de código abierto o de código cerrado que desea elegir.
La funcionalidad central gira en torno a las grabaciones de reuniones de procesamiento enviadas a través de la página de inicio de la aplicación web. Una vez que se envía una grabación, se inicia una tarea de fondo utilizando el apio, que realiza dos operaciones principales: conversión del habla a texto y las actas de generación de la reunión del texto convertido.
El diagrama de flujo que ha compartido contornos un proceso detallado para manejar y procesar archivos multimedia, particularmente centrado en las entradas de audio y video para generar transcripciones y resúmenes. Desglosemos cada paso y describamos las soluciones de alto nivel involucradas en este flujo de trabajo:
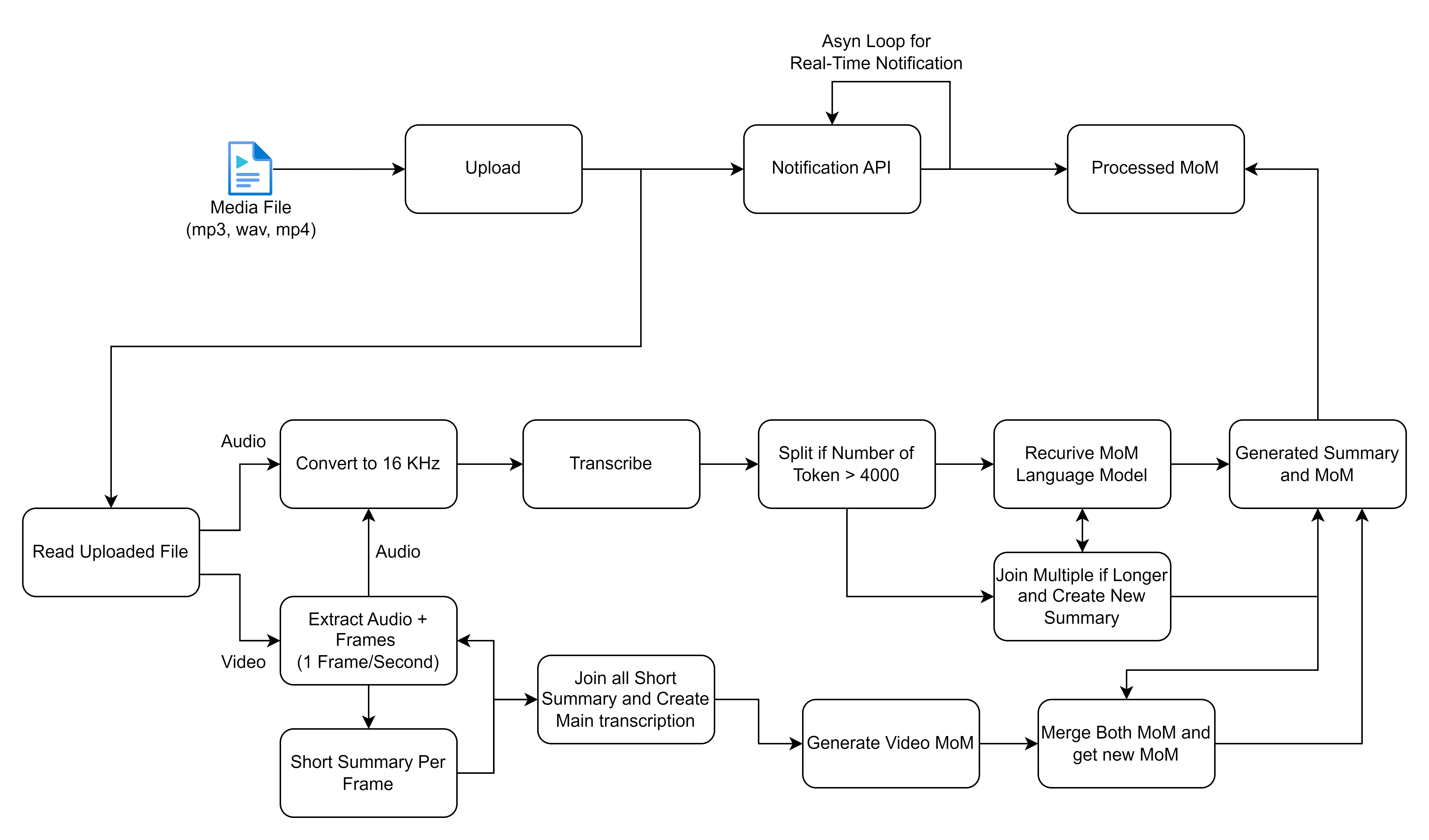




Antes de continuar, asegúrese de tener lo siguiente instalado:
virtualenv o venv .requirements.txt sean compatibles. En la fase 2 de nuestro proyecto, planeamos habilitar la transcripción de reuniones en tiempo real. ¡Únase a nosotros para dar forma al futuro de las reuniones eficientes y colaborativas!
? Sígueme para obtener actualizaciones sobre el desarrollo de la Fase 2 y otras mejoras para que sus reuniones sean aún más productivas.
? Alentando las contribuciones de la comunidad a hacer de esta herramienta un cambio de juego para las reuniones en todas partes. ¡Contribuya sus ideas y experiencia para ayudarnos a lograr la transcripción en tiempo real!


