LLM Minutes of Meeting
1.0.0
| Старший № | Тема | Связь |
|---|---|---|
| 0 | Введение и «почему» проекта | Ссылка придет сюда |
| 1 | Настройка и установка | Ссылка придет сюда |
| 2 | Функции | Другая ссылка |
| 3 | Демонстрация и скриншоты приложений | Другая ссылка |
| 4 | Подход и реализация* | Другая ссылка |
| 5 | Последние обновления и будущие направления | Другая ссылка |
| 6 | Вклад | Другая ссылка |
| 7 | Проблемы/устранение неполадок | Другая ссылка |

Основная цель этого проекта - продемонстрировать возможность NLP & LLM быстро суммировать долгие встречи и помочь вам и вашей организации автоматизировать задачу делегирования протоколов электронных писем (MOM). Он использует подход высокого уровня 2, где шаг 1 соответствует преобразованию любого аудио/видеофайла в текстовый разговор. Шаг 2 использует текст, созданный на шаге 1, и генерирует протокол встречи и подробные резюме. Эти минуты встречи будут редактируемым кусочком текста. Как только вы завершаете маму, вы можете использовать ее дальше в соответствии с вашим требованием.
Долгосрочная цель для этого репозитория также состоит в том, чтобы разработать веб-применение Python в реальном времени, которое может посещать встречи для вас, а также предоставить вам маму в конце встречи. Принять детские шаги и попытаться добраться до долгосрочной перспективы, начав краткосрочную цель.
Для вашей информации: я работаю над тонкой настройкой Custom LLMS и разработкой. Пожалуйста, будьте терпеливы, пока весь проект полностью стабилен. Я добавлю код обучения и вывода после завершения. Сделайте это хранилище, если вам нужно знать последние обновления. ? Цените ваше время.
Прежде чем продолжить, убедитесь, что у вас установлено следующее:
virtualenv или venv .Давайте начнем шаги установки сейчас.
Клонировать репозиторий GitHub
Откройте свой терминал или командную строку и перейдите в каталог, где вы хотите клонировать репозиторий. Затем беги:
git clone https://github.com/inboxpraveen/LLM-Minutes-of-Meeting
cd LLM-Minutes-of-MeetingУстановить требования
Перед установкой зависимости - это хорошая практика, чтобы создать виртуальную среду, чтобы избежать потенциальных конфликтов с другими проектами Python. Если вы используете virtualenv , вы можете настроить новую среду следующим образом:
# # Create a python virtual environment and activate it.
# Install the required packages after activating:
pip install -r requirements.txt
# # After this, let's install Llama-Cpp-Python binding which will be used to interact with LLMs.
# # Run the following line if you are using it on a CPU.
pip install llama-cpp-python
# # Run the following line if you are using GPU (T4, A100, A10, or H100), or any Nvidia Cuda based GPU Drivers.
CMAKE_ARGS= " -DLLAMA_CUDA=on " pip install llama-cpp-python
# # If you are on Mac or any other GPU types, you can refer the following links and setup the Llama-Cpp-Python
https://llama-cpp-python.readthedocs.io/en/stable/ # installation-configuration
https://llama-cpp-python.readthedocs.io/en/stable/install/macos/Настройка обработка работы Rabbitmq и сельдерея.
Используйте следующую ссылку для настройки Rabbitmq на вашем компьютере. Следуйте инструкциям до шага 5 и сохраните свое admin-username и password .
Настройка Rabbitmq на Ubuntu 22.04
Как только вы успешно настроите Rabbitmq, затем настройте Redis-Server и сельдерей. Используйте следующую команду для настройки и установите их.
sudo apt-get update -y
# # Try with apt-get. If it does not install, then run with apt.
sudo apt-get install redis-server -y
# # If the above does not work, try this:
sudo apt install redis-server -yЗапустить приложение и параллельное выполнение задачи сельдерея
Во -первых, запустите приложение Flask:
cd /path/to/project/а затем откройте файл app.py внутри вашего редактора кода и измените следующую строку.
Line 18 : broker = 'amqp://<user>:<password>$@localhost:5672//'
## Update <user> with "your-admin-username".
## Update <password> with "your-admin-password"
## Eg: broker='amqp://admin:hello_world$@localhost:5672//'
### IMPORTANT NOTE: If your password contains '@' symbol, you will need to convert it because it is the default delimiter in broker settings. Example if your password has @ symbol inside it would be.
## broker='amqp://admin:hello%40world$@localhost:5672//' -- where the original password was "hello@world", we represent it as 'hello%40world' После того, как вы обновили файл, вы запустите файл setup.py для настройки каталогов и загрузки моделей. Если вы хотите изменить конфигурации того, какие модели вы хотите использовать, вы можете изменить их соответствующим образом на основе размера инфраструктуры и системной емкости. В следующей таблице показано, какие модели мы поддерживаем в настоящее время в этом проекте, но мы будем добавлять новую поддержку LLMS, поскольку мы считаем их подходящими и открытым исходным кодом.
Речевые модели поддерживаются
| Название модели | Размер модели | Требуется память (ОЗУ или Врам) |
|---|---|---|
| Distil-Whisper/Distil-Large-V3 | 3,1 ГБ | 4ГБ |
| Distil-Whisper/Distil-Large-V2 | 3,1 ГБ | 4ГБ |
| Distil-Whisper/Distil-Medium.en | 1,6 ГБ | 2 ГБ |
| Distil-Whisper/Distil-Small.en | 680 МБ | 900 МБ |
| Openai/Whisper-Large-V3 | 6,2 ГБ | 7,5 ГБ |
| Openai/Whisper-Large-V2 | 6,2 ГБ | 7,5 ГБ |
| Openai/Whisper-Large-V1 | 6,2 ГБ | 7,5 ГБ |
| Openai/Whisper-Medium | 3,2 ГБ | 4,5 ГБ |
| Openai/Whisper-Small (по умолчанию) | 980 МБ | 1,7 ГБ |
LLMS поддерживается
| Название модели | Размер модели | Память требуется |
|---|---|---|
| QuantFactory/Phi-3-Mini-4K-Instruct-Gguf (по умолчанию) | 1 ГБ - 8 ГБ | 2 ГБ - 14 ГБ |
| QUANTFACTORY/PHI-3-MINI-128K-Instruct-GGUF | 1 ГБ - 8 ГБ | 2,5 ГБ - 16 ГБ |
| Bartowski/Phi-3-Medium-128K-Instruct-Gguf | 3 ГБ - 14 ГБ | 6 ГБ - 18 ГБ |
Вам необходимо будет изменить файл global_varibables.py с помощью имени модели, которое вы выбираете, а затем запустить файл setup.py , который автоматически будет автоматически опустить выбранные вами модели.
Line 32 : DEFAULT_SPEECH_MODEL = "openai/whisper-small"
...
Line 46 : DEFAULT_SUMMARY_MODEL = ( "QuantFactory/Phi-3-mini-4k-instruct-GGUF" , "Phi-3-mini-4k-instruct.Q5_0.gguf" )
### After update the above lines as per your need, run the setup.py
python setup . pyВ новом окне терминала (убедитесь, что ваша виртуальная среда также активирована здесь), запустите приложение и сельдерей:
python app.py # ensure your environment is activated
# and then in new terminal, run the following.
celery -A app.celery worker --loglevel=info -f celery.logsЗагрузить запись для формирования
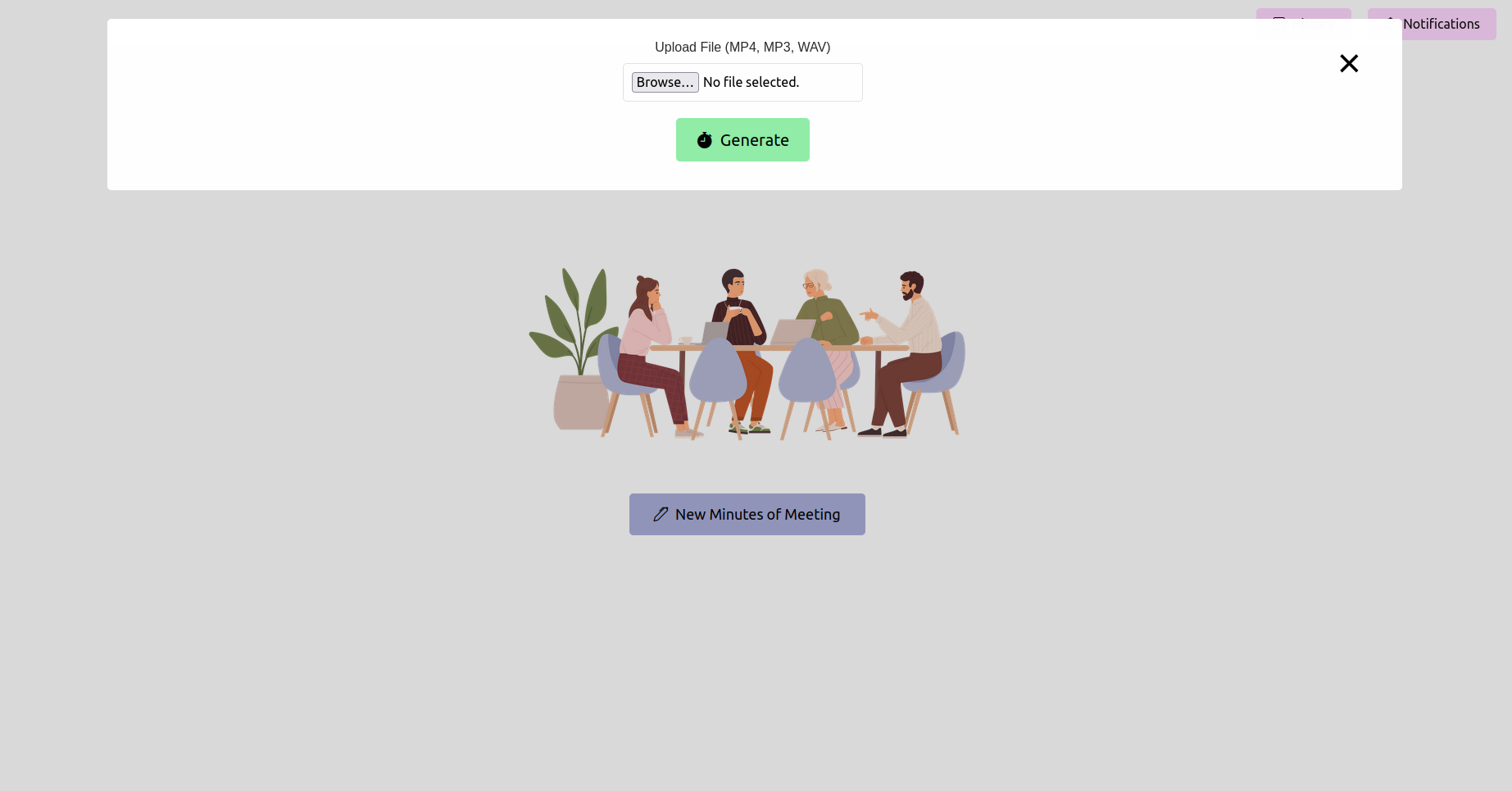
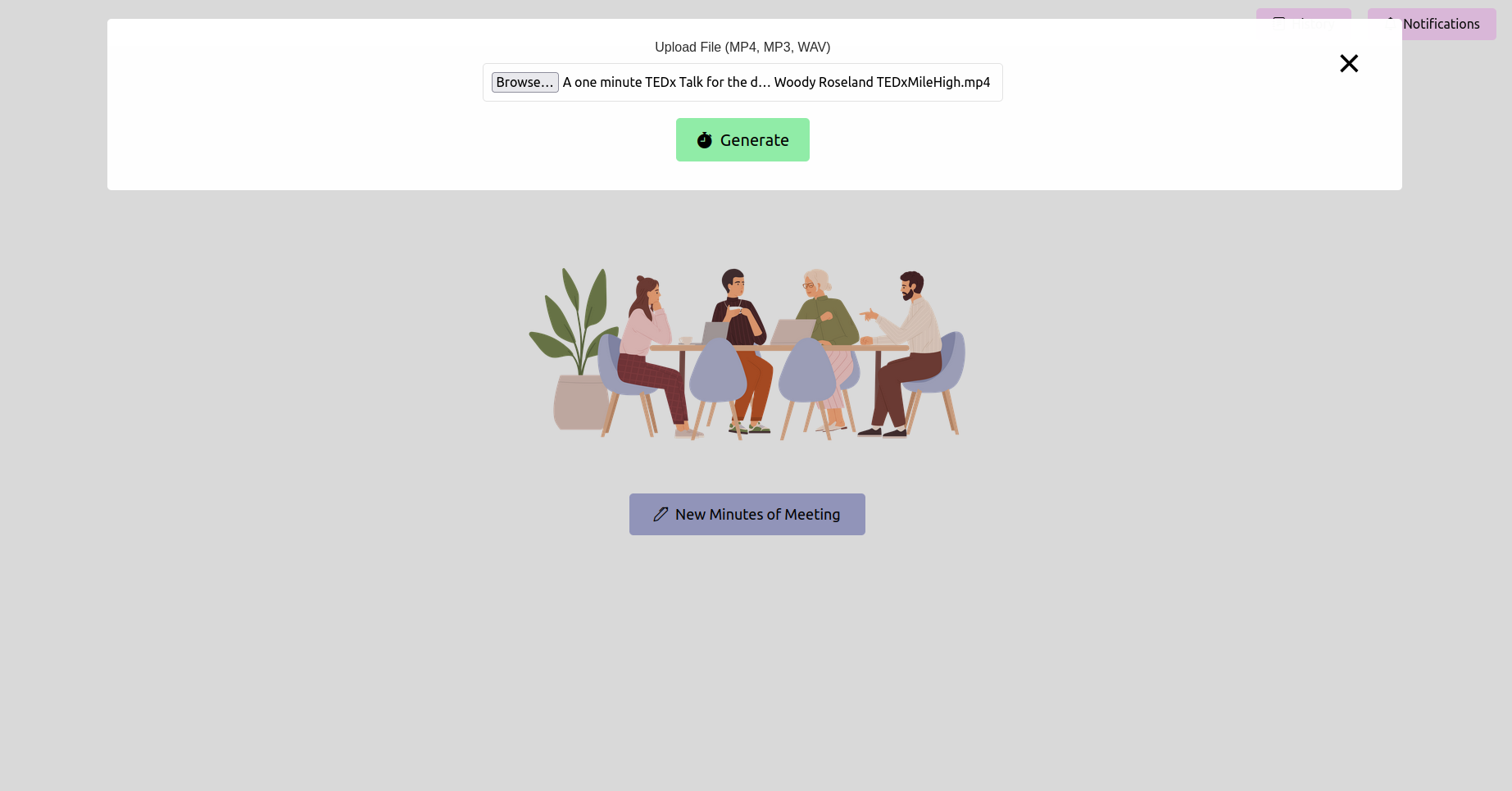
Откройте свой веб -браузер и перейдите к URL -адресу приложения Flask (обычно http://127.0.0.1:5000 ). Используйте интерфейс, чтобы загрузить свою запись встречи.
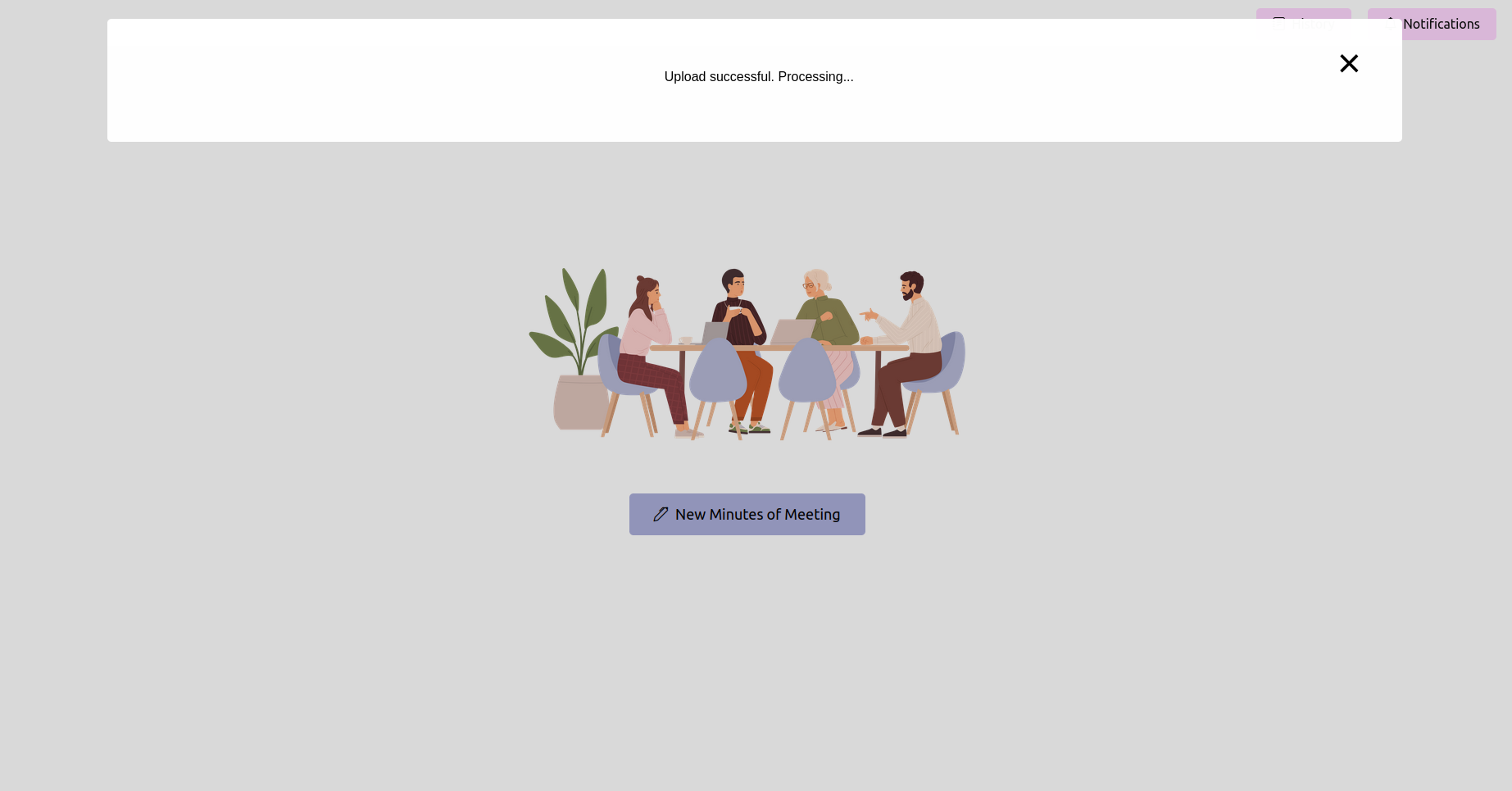
Получите последний статус и подождите, пока он завершит
После загрузки записи вы можете проверить состояние обработки. Это может быть реализовано в качестве страницы статуса или панели прогресса в вашем приложении. Подождите, пока обработка не будет завершена.
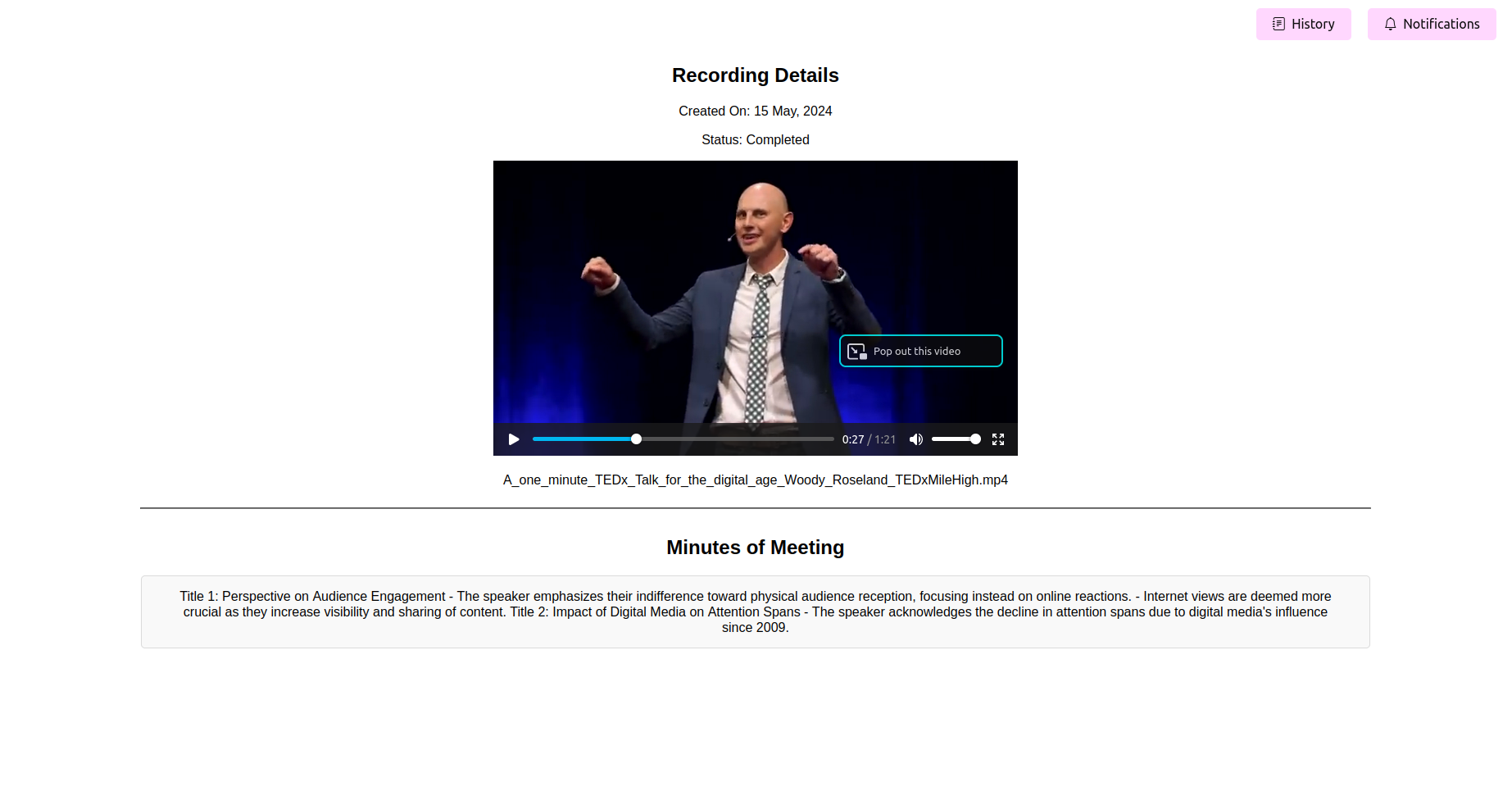
Смотрите окончательные обработанные минуты встречи (мама)
После завершения обработки приложение должно отображать последние минуты встречи. Вы можете просмотреть, редактировать (если функция доступна) и сохранить маму для вашей ссылки.
Без особых усилий конвертируйте аудио и видеофайлы в точные текстовые транскрипты: они также могут использоваться для суммирования, генерации элементов действий, понимания рабочих потоков и планирования ресурсов.
Подсветка ключевых слов и теги для быстрой ссылки: извлечение тем и поиск соответствующего содержимого для прохождения встреч и прослушивания только конкретных тем, которые представляют ваш интерес.
Экспортные минуты в различных форматах, включая PDF и простой текст: позволяет экспортировать транскрипты, резюме, резюме, темы и ключевые слова, элементы действий и т. Д. В документы, которые можно использовать в рамках планирования проекта и управления. Также устраняет вашу необходимость вручную писать и генерировать шаблоны.
Удобный интерфейс для легкой настройки и интеграции: простые в настройке, которая когда-либо открыта модель или модели с закрытым исходным кодом, которую вы хотите выбрать.
Основная функциональность вращается вокруг обработки записей собраний, представленных на домашней странице веб -приложения. После того, как запись будет представлена, фоновая задача инициируется с использованием сельдерея, которая выполняет две основные операции: преобразование речи в текст и генерирование протоколов встречи из конвертированного текста.
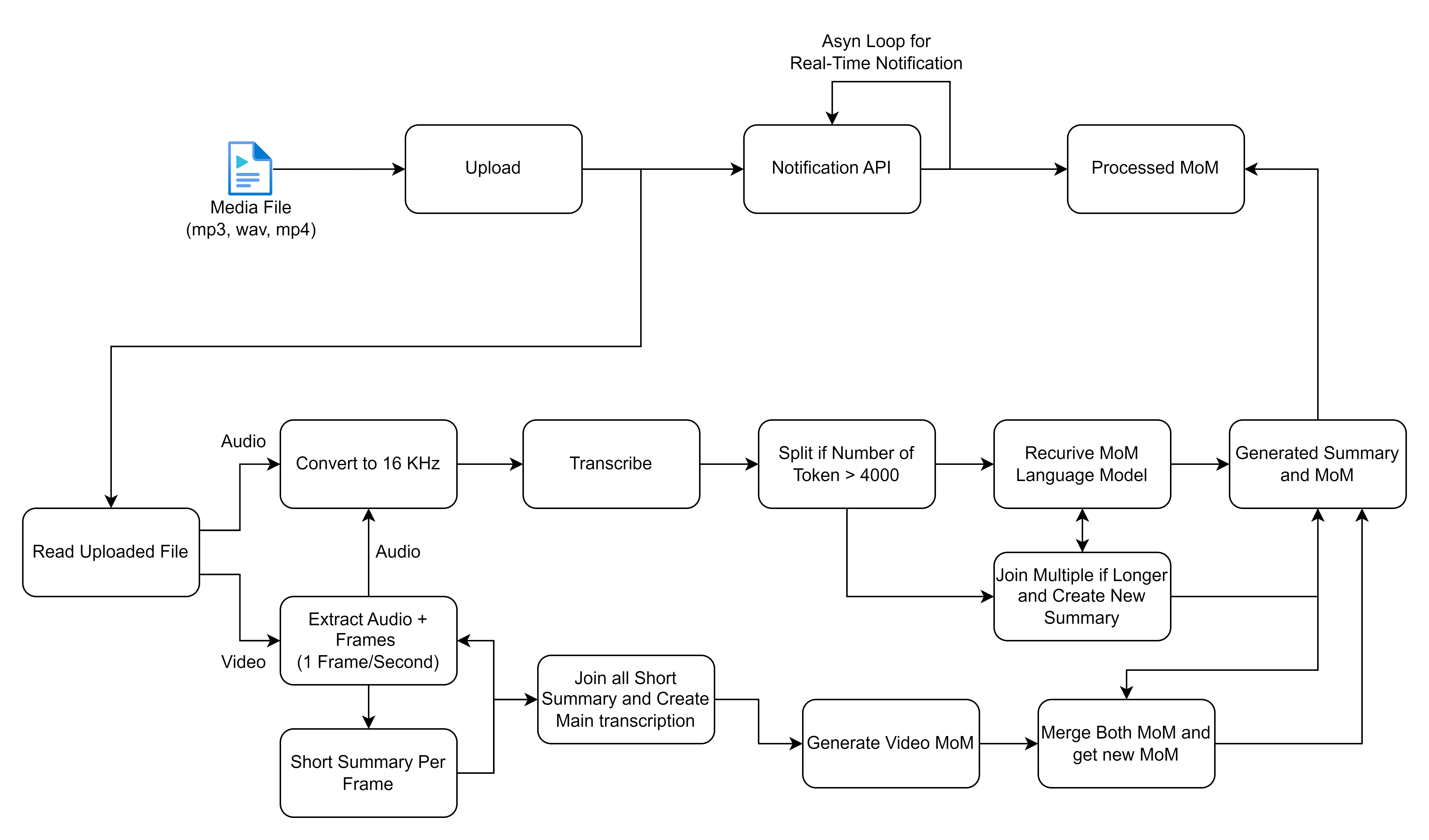
В блок -схеме, которую вы поделились, описывает подробный процесс обработки и обработки медиа -файлов, в частности, фокусируясь на аудио и видео входах для генерации транскрипций и резюме. Давайте разберем каждый шаг и опишем решения высокого уровня, связанные с этим рабочим процессом:




Прежде чем продолжить, убедитесь, что у вас установлено следующее:
virtualenv или venv .requirements.txt совместимы. На этапе 2 нашего проекта мы планируем включить транскрипцию встречи в реальном времени. Присоединяйтесь к нам в формировании будущего эффективных и совместных встреч!
? Следуйте за мной за обновлениями о разработке фазы 2 и других улучшениях, чтобы сделать ваши встречи еще более продуктивными.
Поощрение вклада сообщества, чтобы сделать этот инструмент изменять игру для встреч повсюду. Внесите свои идеи и опыт, чтобы помочь нам достичь транскрипции в реальном времени!


