LLM Minutes of Meeting
1.0.0
| Sr. Nr. | Thema | Link |
|---|---|---|
| 0. | Einführung und "Warum" des Projekts | Link wird hierher kommen |
| 1. | Einrichtung und Installation | Link wird hierher kommen |
| 2. | Merkmale | Ein weiterer Link |
| 3. | Demo- und Anwendungssindrusshots | Ein weiterer Link |
| 4. | Ansatz und Implementierung* | Ein weiterer Link |
| 5. | Aktuelle Updates und zukünftige Anweisungen | Ein weiterer Link |
| 6. | Beiträge | Ein weiterer Link |
| 7. | Probleme/Fehlerbehebung | Ein weiterer Link |

Das Hauptziel dieses Projekts ist es, die Fähigkeit von NLP & LLM zu demonstrieren, lange Besprechungen schnell zusammenzufassen und Ihnen und Ihrer Organisation zu helfen, die Aufgabe der Delegierung von MOM -E -Mails (MOM) zu automatisieren. Es verwendet einen Stufe 2 -Schritt -Ansatz, bei dem Schritt 1 der Konvertierung einer Audio-/Videodatei in eine Textgespräch entspricht. In Schritt 2 wird Text verwendet, der in Schritt 1 erstellt wurde, und generieren Sie Protokolle der Besprechung und detaillierte Zusammenfassungsnotizen. Diese Minuten des Treffens sind ein edierbares Textstück. Sobald Sie die Mutter fertiggestellt haben, können Sie sie nach Ihren Wünschen weiter verwenden.
Das langfristige Ziel für dieses Repository ist es auch, eine Echtzeit-Python-Webanwendung zu entwickeln, mit der Sie am Ende des Meetings an Besprechungen für Sie teilnehmen und Ihnen auch Mama zur Verfügung stellen können. Machen Sie Babyschritte und versuchen Sie, durch ein kurzfristiges Ziel zu erreichen.
Zu Ihren Informationen: Ich arbeite an feinstimmigen kundenspezifischen LLMs und Entwicklung. Bitte seien Sie geduldig, während das gesamte Projekt völlig stabil ist. Ich werde nach Abschluss der Schulungen und Inferenzcode hinzufügen. Machen Sie dieses Repository, wenn Sie die neuesten Updates kennen müssen. ? Schätzen Sie Ihre Zeit.
Stellen Sie vor dem Fahren sicher, dass Sie die folgenden Installation haben:
virtualenv oder venv .Beginnen wir jetzt mit den Installationsschritten.
Klonen Sie das Github -Repository
Öffnen Sie Ihr Terminal oder die Eingabeaufforderung und navigieren Sie zum Verzeichnis, in dem Sie das Repository klonen möchten. Dann rennen:
git clone https://github.com/inboxpraveen/LLM-Minutes-of-Meeting
cd LLM-Minutes-of-MeetingAnforderungen installieren
Es ist eine gute Praxis, eine virtuelle Umgebung zu schaffen, bevor Abhängigkeiten installiert werden, um potenzielle Konflikte mit anderen Python -Projekten zu vermeiden. Wenn Sie virtualenv verwenden, können Sie wie folgt eine neue Umgebung einrichten:
# # Create a python virtual environment and activate it.
# Install the required packages after activating:
pip install -r requirements.txt
# # After this, let's install Llama-Cpp-Python binding which will be used to interact with LLMs.
# # Run the following line if you are using it on a CPU.
pip install llama-cpp-python
# # Run the following line if you are using GPU (T4, A100, A10, or H100), or any Nvidia Cuda based GPU Drivers.
CMAKE_ARGS= " -DLLAMA_CUDA=on " pip install llama-cpp-python
# # If you are on Mac or any other GPU types, you can refer the following links and setup the Llama-Cpp-Python
https://llama-cpp-python.readthedocs.io/en/stable/ # installation-configuration
https://llama-cpp-python.readthedocs.io/en/stable/install/macos/Setup Rabbitmq & Sellerie -Hintergrund -Jobverarbeitung einrichten
Verwenden Sie den folgenden Link zum Setup Rabbitmq auf Ihrer Maschine. Befolgen Sie die Anweisungen bis Schritt 5 und speichern Sie Ihren admin-username und password .
Setup Rabbitmq auf Ubuntu 22.04 einrichten
Sobald Sie Rabbitmq erfolgreich eingerichtet haben, dann setzten Sie Redis-Server und Sellerie ein. Verwenden Sie den folgenden Befehl, um sie einzurichten und zu installieren.
sudo apt-get update -y
# # Try with apt-get. If it does not install, then run with apt.
sudo apt-get install redis-server -y
# # If the above does not work, try this:
sudo apt install redis-server -yFühren Sie die Anwendung und parallel ausgeführte Sellerie -Aufgabe aus
Starten Sie zunächst die Flask -Anwendung:
cd /path/to/project/Öffnen Sie die Datei App.py in Ihrem Code -Editor und ändern Sie die folgende Zeile.
Line 18 : broker = 'amqp://<user>:<password>$@localhost:5672//'
## Update <user> with "your-admin-username".
## Update <password> with "your-admin-password"
## Eg: broker='amqp://admin:hello_world$@localhost:5672//'
### IMPORTANT NOTE: If your password contains '@' symbol, you will need to convert it because it is the default delimiter in broker settings. Example if your password has @ symbol inside it would be.
## broker='amqp://admin:hello%40world$@localhost:5672//' -- where the original password was "hello@world", we represent it as 'hello%40world' Nachdem Sie die Datei aktualisiert haben, führen Sie die Datei setup.py auf Setup -Verzeichnisse und Herunterladen von Modellen aus. Wenn Sie die Konfigurationen, welche Modelle Sie verwenden möchten, ändern möchten, können Sie sie basierend auf Ihrer Infrastrukturgröße und Systemkapazität ordnungsgemäß ändern. Die folgende Tabelle zeigt, welche Modelle wir derzeit in diesem Projekt unterstützen, aber wir werden neue LLMS-Unterstützung hinzufügen, da wir sie sehen und Open-Source.
Sprachmodelle unterstützt
| Modellname | Modellgröße | Speicher erforderlich (RAM oder VRAM) |
|---|---|---|
| Distil-Whisper/Distil-Large-V3 | 3.1 GB | 4 GB |
| Distil-Whisper/Distil-Large-V2 | 3.1 GB | 4 GB |
| Distil-Whisper/Distil-Medium | 1,6 GB | 2 GB |
| Distil-Whisper/Distil-Small.en | 680 MB | 900 MB |
| OpenAI/Whisper-Large-V3 | 6,2 GB | 7,5 GB |
| OpenAI/Whisper-Large-V2 | 6,2 GB | 7,5 GB |
| OpenAI/Whisper-Large-V1 | 6,2 GB | 7,5 GB |
| Openai/Flüstermedium | 3,2 GB | 4,5 GB |
| OpenAI/Whisper-Small (Standard) | 980 MB | 1,7 GB |
LLMs unterstützt
| Modellname | Modellgröße | Speicher erforderlich |
|---|---|---|
| QuantFactory/Phi-3-Mini-4K-Instruct-GGUF (Standard) | 1 GB - 8 GB | 2 GB - 14 GB |
| Quantfaktorisch/phi-3-mini-128K-Instruct-gguf | 1 GB - 8 GB | 2,5 GB - 16 GB |
| Bartowski/Phi-3-Medium-128K-Instruct-Gguf | 3 GB - 14 GB | 6 GB - 18 GB |
Sie müssen die Datei global_varibables.py mit dem von Ihnen ausgewählten Modellnamen ändern und dann die Datei setup.py ausführen, die automatisch die von Ihnen ausgewählten Modelle herunterfindet.
Line 32 : DEFAULT_SPEECH_MODEL = "openai/whisper-small"
...
Line 46 : DEFAULT_SUMMARY_MODEL = ( "QuantFactory/Phi-3-mini-4k-instruct-GGUF" , "Phi-3-mini-4k-instruct.Q5_0.gguf" )
### After update the above lines as per your need, run the setup.py
python setup . pyStarten Sie in einem neuen Terminalfenster (stellen Sie sicher, dass Ihre virtuelle Umgebung auch hier aktiviert ist) die App- und Sellerie -Arbeiterin:
python app.py # ensure your environment is activated
# and then in new terminal, run the following.
celery -A app.celery worker --loglevel=info -f celery.logsLaden Sie die Aufnahme hoch, um sie zu formen
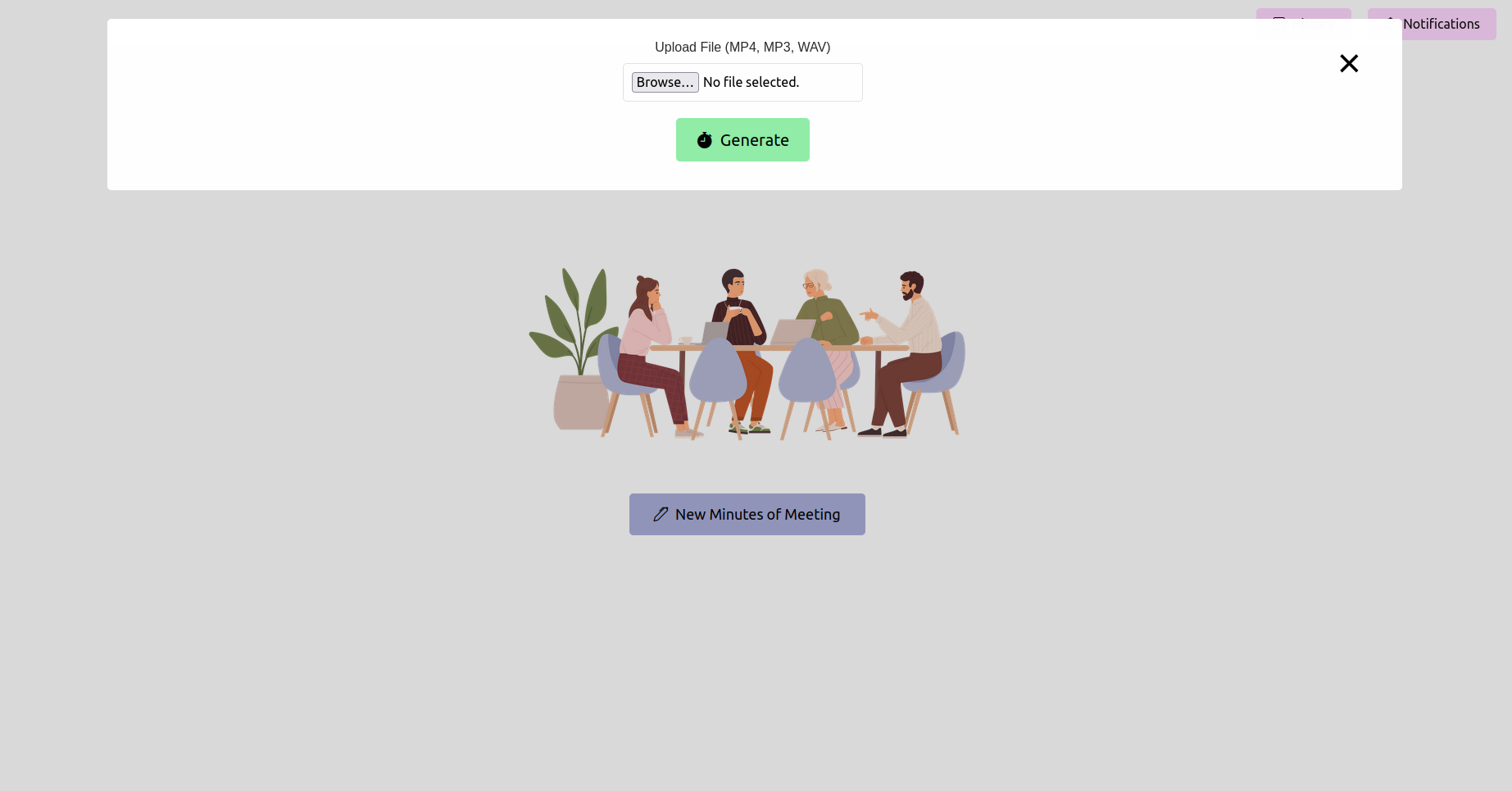
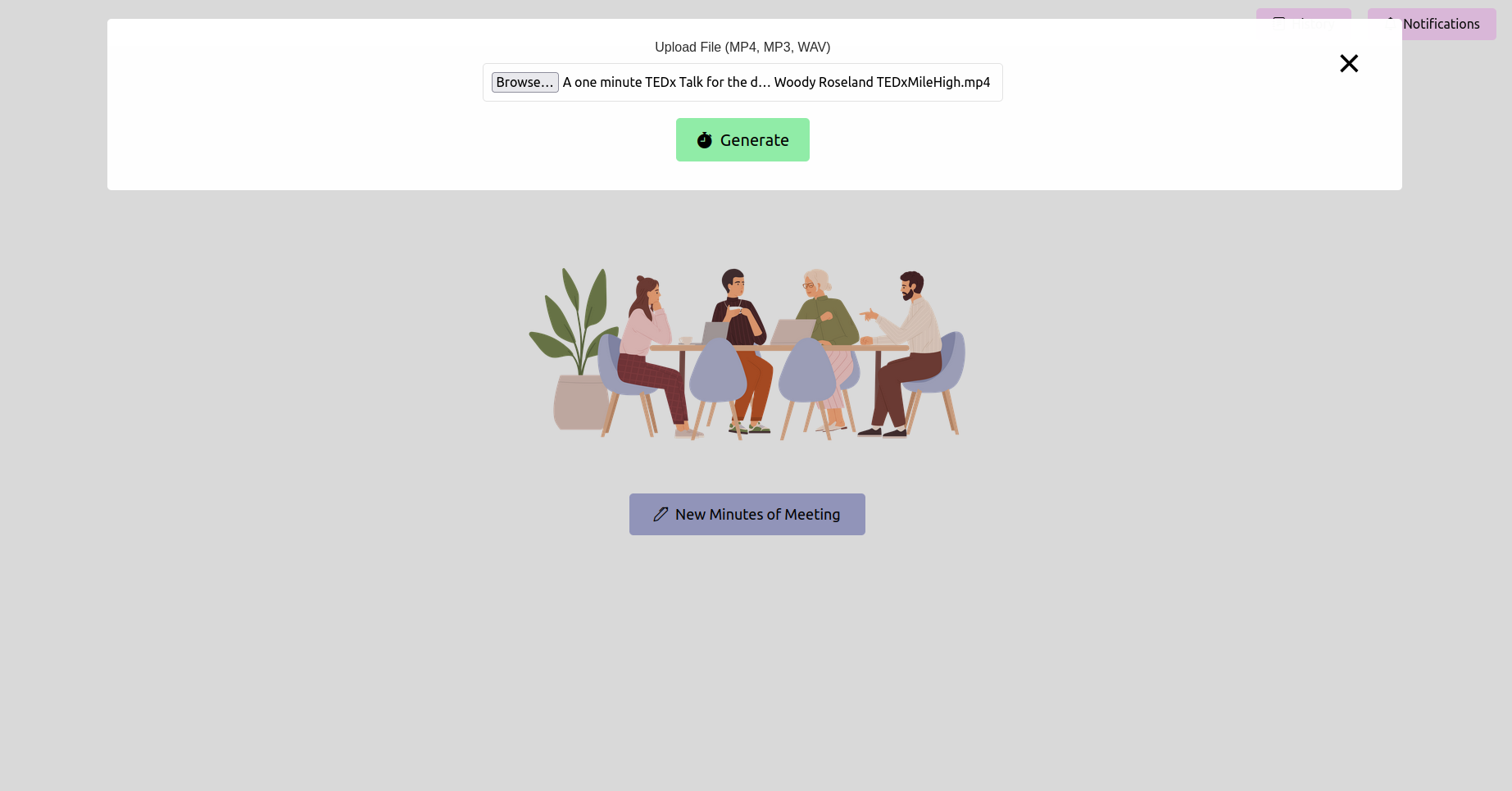
Öffnen Sie Ihren Webbrowser und navigieren Sie zur URL der Flash -Anwendung (normalerweise http://127.0.0.1:5000 ). Verwenden Sie die Schnittstelle, um Ihre Besprechungsaufzeichnung hochzuladen.
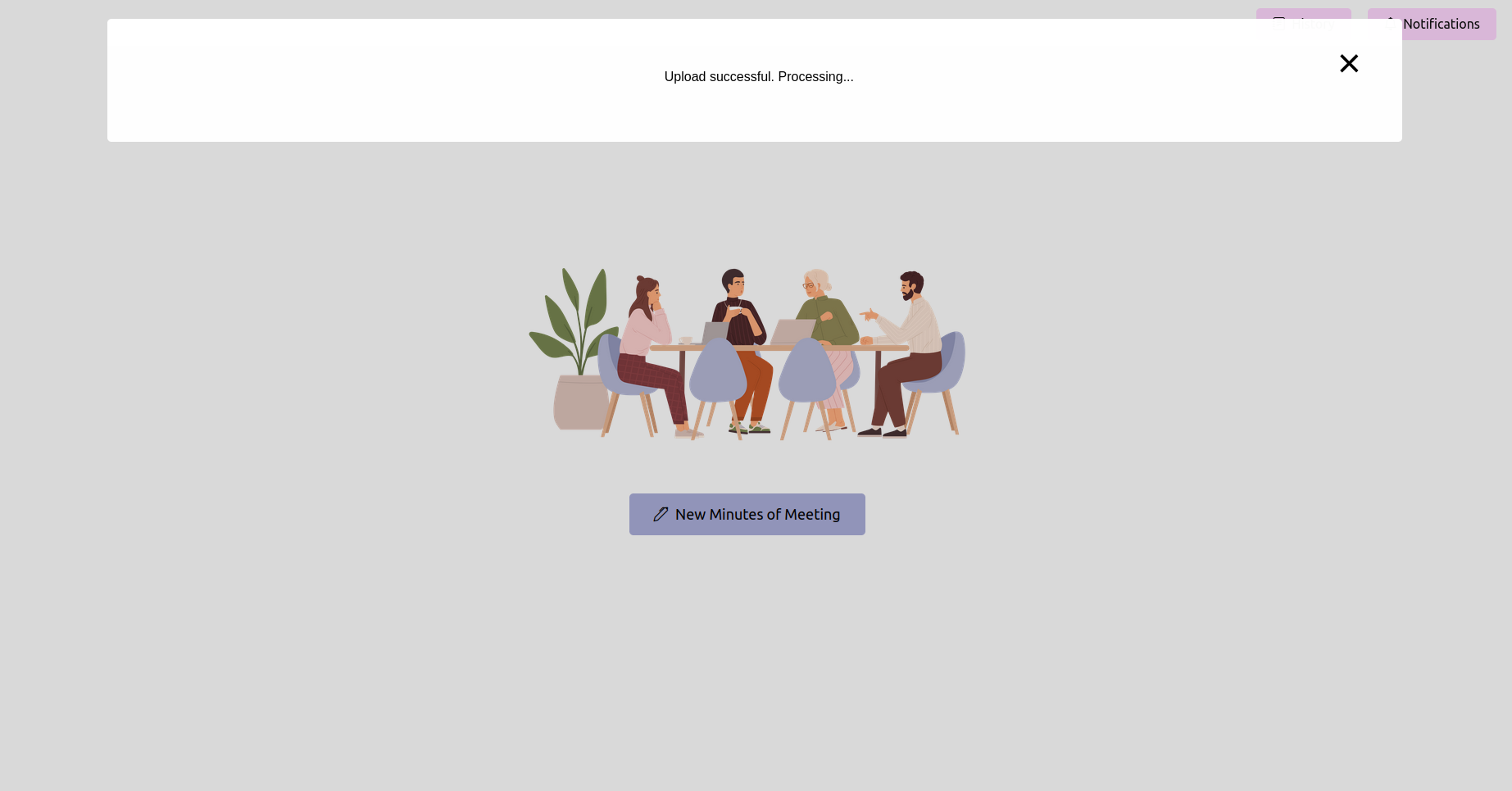
Erhalten Sie den neuesten Status und warten Sie, bis er abgeschlossen ist
Nach dem Hochladen der Aufzeichnung können Sie den Status der Verarbeitung überprüfen. Dies kann als Statusseite oder eine Fortschrittsleiste in Ihrer Anwendung implementiert werden. Warten Sie, bis die Verarbeitung abgeschlossen ist.
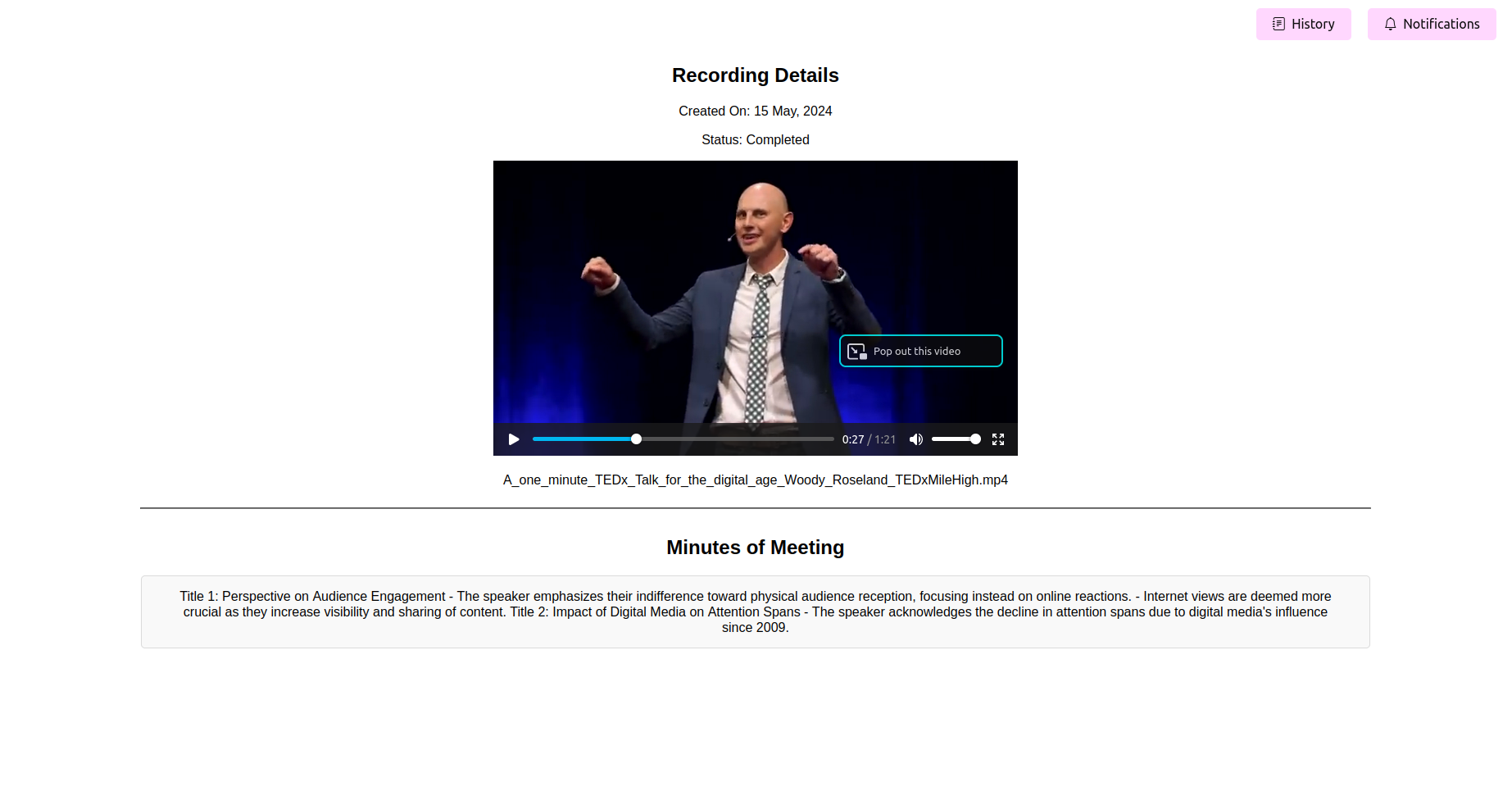
Siehe die endgültigen verarbeiteten Minuten des Meetings (Mama)
Sobald die Verarbeitung abgeschlossen ist, sollte die Anwendung die letzten Protokolle des Meetings anzeigen. Sie können anzeigen, bearbeiten (wenn die Funktion verfügbar ist) und die Mutter für Ihre Referenz speichern.
Mühelos Audio- und Videodateien in genaue Text-Transkripte konvertieren: Diese können auch zum Zusammenfassen, Generieren von Aktionselementen, Verständnis von Arbeitsflüssen und Ressourcenplanung verwendet werden.
Keyword -Hervorhebung und Themen -Tagging für schnelle Referenz: Extrahieren von Themen und fundierte Inhalte, um Besprechungen zu überspringen und nur bestimmte Themen anzuhören, die von Ihrem Interesse sind.
Exportieren Sie die Minuten in verschiedenen Formaten, einschließlich PDF und einfachem Text: Ermöglicht Ihnen die Einfuhr von Transkripten, Zusammenfassungen, Themen und Keywords, Aktionselementen usw. in Dokumente, die in Rahmenbedingungen für Projektplanungs- und Verwaltungsrahmen verwendet werden können. Beseitigt auch Ihre Notwendigkeit, Vorlagen manuell zu schreiben und zu generieren.
Benutzerfreundliche Schnittstelle zur einfachen Anpassung und Integration: Einfach zu optimieren, das jemals Open-Source- oder geschlossene Quellmodell auswählen.
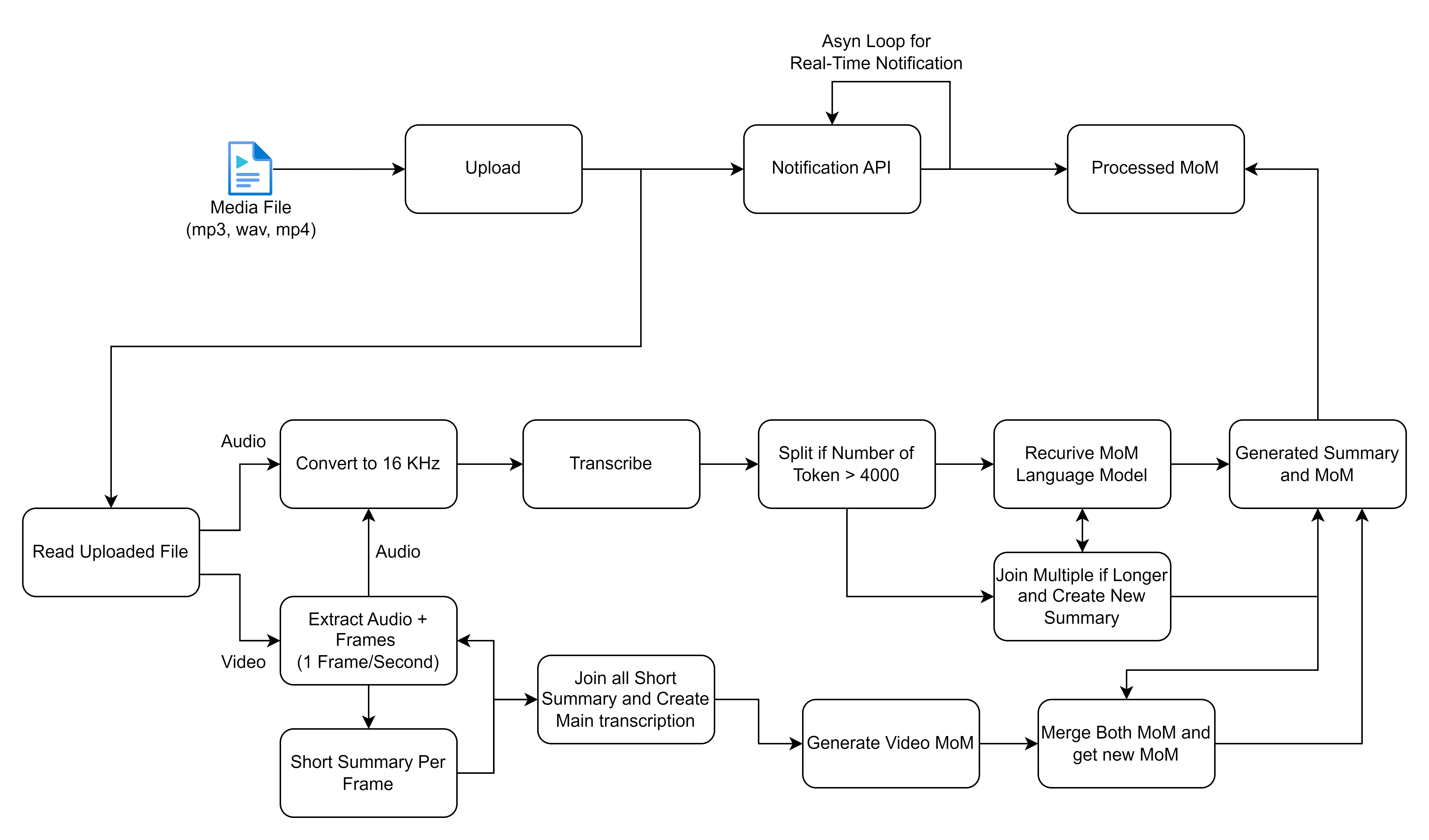
Die Kernfunktionalität dreht sich um die über die Startseite der Webanwendung eingereichten Verarbeitung von Besprechungsaufzeichnungen. Sobald eine Aufzeichnung eingereicht wurde, wird eine Hintergrundaufgabe unter Verwendung von Sellerie initiiert, die zwei primäre Vorgänge ausführt: Rede-zu-Text-Konvertierung und Generierung von Minuten des Meetings aus dem konvertierten Text.
Das von Ihnen geteilte Flowdiagramm beschreibt einen detaillierten Prozess für die Handhabung und Verarbeitung von Mediendateien, insbesondere auf Audio- und Videoeingänge, um Transkriptionen und Zusammenfassungen zu generieren. Lassen Sie uns jeden Schritt aufschlüsseln und die hochrangigen Lösungen für diesen Workflow beschreiben:




Stellen Sie vor dem Fahren sicher, dass Sie die folgenden Installation haben:
virtualenv oder venv .requirements.txt kompatibel sind. In Phase 2 unseres Projekts planen wir, die Transkription in Echtzeit zu ermöglichen. Gestalten Sie mit uns die Zukunft effizienter und kollaborativer Meetings!
? Folgen Sie mir, um Aktualisierungen der Entwicklung von Phase 2 und anderen Verbesserungen zu aktualisieren, um Ihre Besprechungen noch produktiver zu gestalten.
? Ermutigen Sie Beiträge der Community, dieses Tool zu einem Spielveränderer für Besprechungen überall zu machen. Tragen Sie Ihre Ideen und Ihre Fachkenntnisse bei, um uns in Echtzeit-Transkription zu unterstützen!


