LLM Minutes of Meeting
1.0.0
| Sr. No. | 주제 | 링크 |
|---|---|---|
| 0. | 프로젝트의 소개 및 "왜" | 링크가 여기에 올 것입니다 |
| 1. | 설정 및 설치 | 링크가 여기에 올 것입니다 |
| 2. | 특징 | 다른 링크 |
| 3. | 데모 및 응용 프로그램 스크린 샷 | 다른 링크 |
| 4. | 접근 및 구현* | 다른 링크 |
| 5. | 최근 업데이트 및 향후 방향 | 다른 링크 |
| 6. | 기여 | 다른 링크 |
| 7. | 문제/문제 해결 | 다른 링크 |

이 프로젝트의 주요 목표는 NLP & LLM의 오랜 회의를 신속하게 요약하고 귀하와 귀하의 조직이 회의록 (MOM) 이메일을 위임하는 작업을 자동화하는 데 도움이되는 NLP & LLM의 기능을 보여주는 것입니다. 1 단계가 오디오/비디오 파일을 텍스트 대화로 변환하는 데 해당하는 높은 레벨 2 단계 접근 방식을 사용합니다. 2 단계는 1 단계에서 생성 된 텍스트를 사용하고 회의록 및 자세한 요약 노트를 생성합니다. 이 회의록은 편집 가능한 텍스트가 될 것입니다. 엄마를 마무리하면 요구 사항에 따라 더 사용할 수 있습니다.
이 저장소의 장기 목표는 또한 회의에 참석할 수있는 실시간 파이썬 웹 응용 프로그램을 개발하고 회의가 끝날 때 엄마를 제공하는 것입니다. 아기 발걸음을 내딛고 단기 목표를 시작하여 장기적으로 가려고 노력합니다.
귀하의 정보를 위해 : 저는 맞춤형 LLM 및 개발을 미세 조정하고 있습니다. 전체 프로젝트가 완전히 안정적 인 동안 인내하십시오. 완료되면 교육 및 추론 코드를 추가하겠습니다. 최신 업데이트를 알아야 할 경우이 저장소를 수행하십시오. ? 당신의 시간에 감사드립니다.
진행하기 전에 다음과 같은 설치를했는지 확인하십시오.
virtualenv 또는 venv 와 같은 가상 환경 도구.지금 설치 단계를 시작합시다.
Github 저장소를 복제하십시오
터미널 또는 명령 프롬프트를 열고 저장소를 복제하려는 디렉토리로 이동하십시오. 그런 다음 실행 :
git clone https://github.com/inboxpraveen/LLM-Minutes-of-Meeting
cd LLM-Minutes-of-Meeting요구 사항을 설치하십시오
다른 Python 프로젝트와의 잠재적 충돌을 피하기 위해 종속성을 설치하기 전에 가상 환경을 조성하는 것이 좋습니다. virtualenv 사용하는 경우 다음과 같이 새로운 환경을 설정할 수 있습니다.
# # Create a python virtual environment and activate it.
# Install the required packages after activating:
pip install -r requirements.txt
# # After this, let's install Llama-Cpp-Python binding which will be used to interact with LLMs.
# # Run the following line if you are using it on a CPU.
pip install llama-cpp-python
# # Run the following line if you are using GPU (T4, A100, A10, or H100), or any Nvidia Cuda based GPU Drivers.
CMAKE_ARGS= " -DLLAMA_CUDA=on " pip install llama-cpp-python
# # If you are on Mac or any other GPU types, you can refer the following links and setup the Llama-Cpp-Python
https://llama-cpp-python.readthedocs.io/en/stable/ # installation-configuration
https://llama-cpp-python.readthedocs.io/en/stable/install/macos/설치 Rabbitmq & Celery 배경 작업 처리
다음 링크를 사용하여 컴퓨터에서 RabbitMQ를 설정하십시오. 5 단계 까지 지시를 따르고 admin-username 및 password 저장하십시오.
Ubuntu 22.04의 설치 RabbitMQ
RabbitMQ를 성공적으로 설정 한 다음 Redis-Server 및 Celery를 설정하십시오. 다음 명령을 사용하여 설정하고 설치하십시오.
sudo apt-get update -y
# # Try with apt-get. If it does not install, then run with apt.
sudo apt-get install redis-server -y
# # If the above does not work, try this:
sudo apt install redis-server -y응용 프로그램 실행 및 병렬 실행 셀러리 작업
먼저 플라스크 응용 프로그램을 시작하십시오.
cd /path/to/project/그런 다음 app.py 파일 내부 코드 편집기를 열고 다음 줄을 수정하십시오.
Line 18 : broker = 'amqp://<user>:<password>$@localhost:5672//'
## Update <user> with "your-admin-username".
## Update <password> with "your-admin-password"
## Eg: broker='amqp://admin:hello_world$@localhost:5672//'
### IMPORTANT NOTE: If your password contains '@' symbol, you will need to convert it because it is the default delimiter in broker settings. Example if your password has @ symbol inside it would be.
## broker='amqp://admin:hello%40world$@localhost:5672//' -- where the original password was "hello@world", we represent it as 'hello%40world' 파일을 업데이트 한 후 setup.py 파일을 설정하여 디렉토리를 설정하고 모델의 다운로드합니다. 사용하려는 모델의 구성을 변경하려면 인프라 크기 및 시스템 용량에 따라 모델을 적절하게 변경할 수 있습니다. 다음 표는 현재이 프로젝트에서 어떤 모델을 지원하는지 보여 주지만, 우리는 그들이 적합하고 오픈 소스를 볼 때 새로운 LLMS 지원을 추가 할 것입니다.
스피치 모델이 지원됩니다
| 모델 이름 | 모델 크기 | 메모리 필수 (RAM 또는 VRAM) |
|---|---|---|
| Distil-Whisper/Distil-Large-V3 | 3.1 GB | 4GB |
| Distil-Whisper/Distil-Large-V2 | 3.1 GB | 4GB |
| Distil-Whisper/Distil-Medium.en | 1.6GB | 2GB |
| Distil-Whisper/Distil-Small.en | 680MB | 900MB |
| Openai/Whisper-Large-V3 | 6.2GB | 7.5GB |
| Openai/Whisper-Large-V2 | 6.2GB | 7.5GB |
| Openai/Whisper-Large-V1 | 6.2GB | 7.5GB |
| Openai/Whisper-Medium | 3.2GB | 4.5GB |
| Openai/Whisper-Small (기본값) | 980 MB | 1.7GB |
LLMS 지원
| 모델 이름 | 모델 크기 | 메모리가 필요합니다 |
|---|---|---|
| QuantFactory/PHI-3-MINI-4K-Instruct-Gguf (기본값) | 1GB -8GB | 2GB -14GB |
| QuantFactory/Phi-3-Mini-128k-instruct-gguf | 1GB -8GB | 2.5GB -16GB |
| Bartowski/Phi-3-Medium-128k-instruct-Gguf | 3GB -14GB | 6GB -18GB |
선택한 모델 이름으로 global_varibables.py 파일을 수정 한 다음 선택한 모델을 자동으로 다운하는 setup.py 파일을 실행해야합니다.
Line 32 : DEFAULT_SPEECH_MODEL = "openai/whisper-small"
...
Line 46 : DEFAULT_SUMMARY_MODEL = ( "QuantFactory/Phi-3-mini-4k-instruct-GGUF" , "Phi-3-mini-4k-instruct.Q5_0.gguf" )
### After update the above lines as per your need, run the setup.py
python setup . py새로운 터미널 창에서 (여기에서 가상 환경이 활성화되어 있는지 확인) 앱 및 셀러리 작업자를 시작하십시오.
python app.py # ensure your environment is activated
# and then in new terminal, run the following.
celery -A app.celery worker --loglevel=info -f celery.logs녹음을 형성합니다
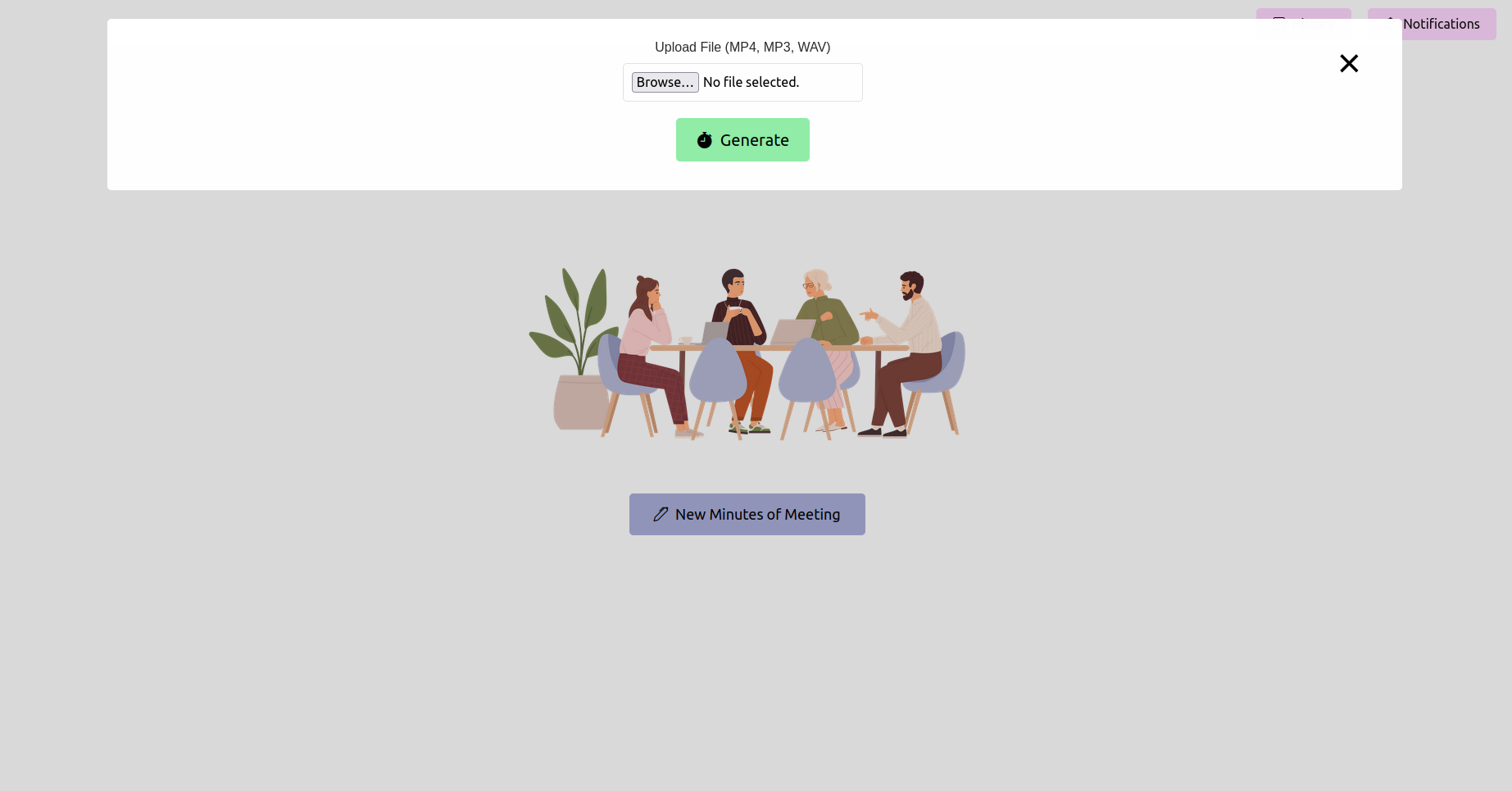
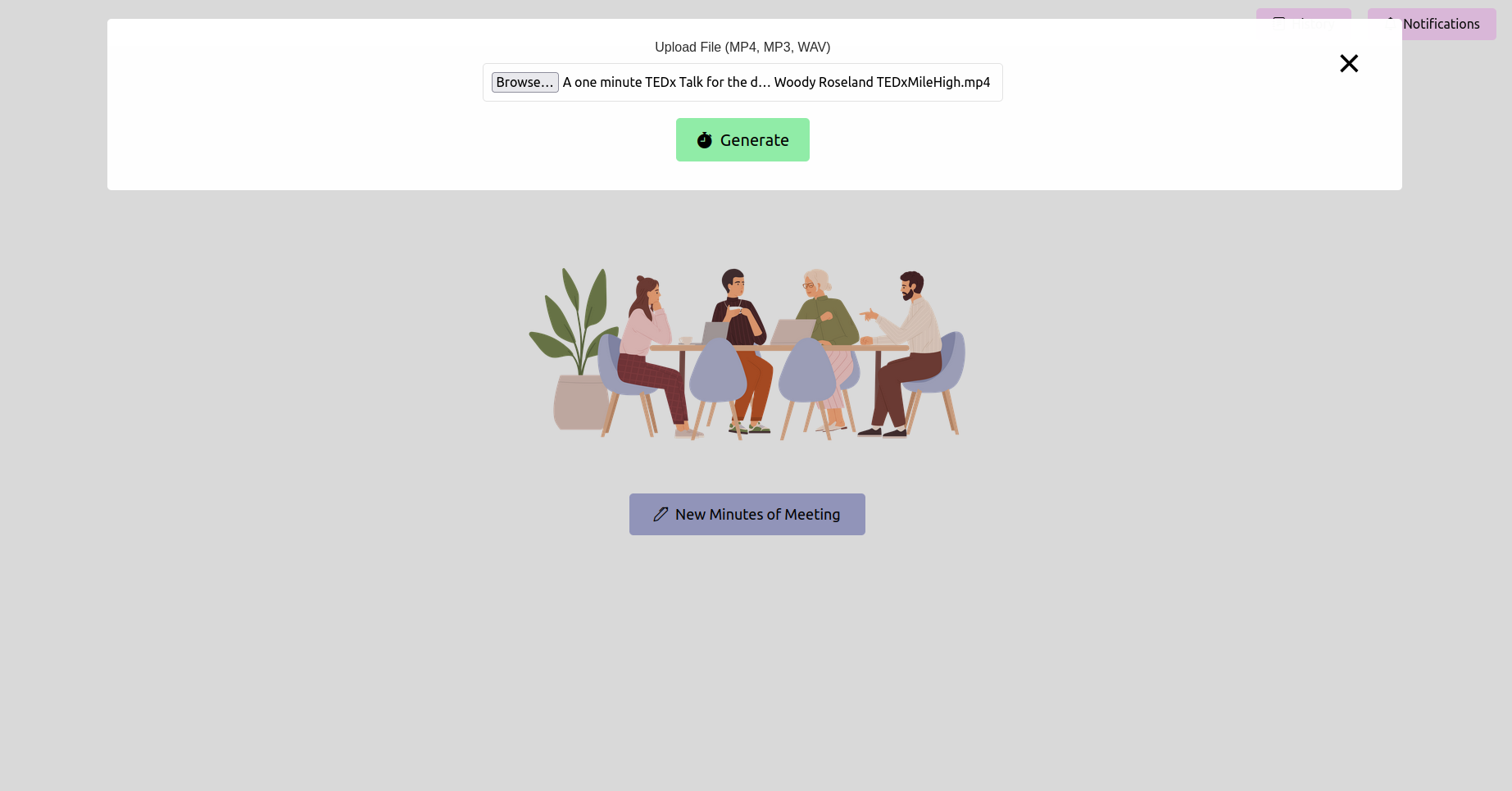
웹 브라우저를 열고 플라스크 애플리케이션의 URL (일반적으로 http://127.0.0.1:5000 )으로 이동하십시오. 인터페이스를 사용하여 회의 기록을 업로드하십시오.
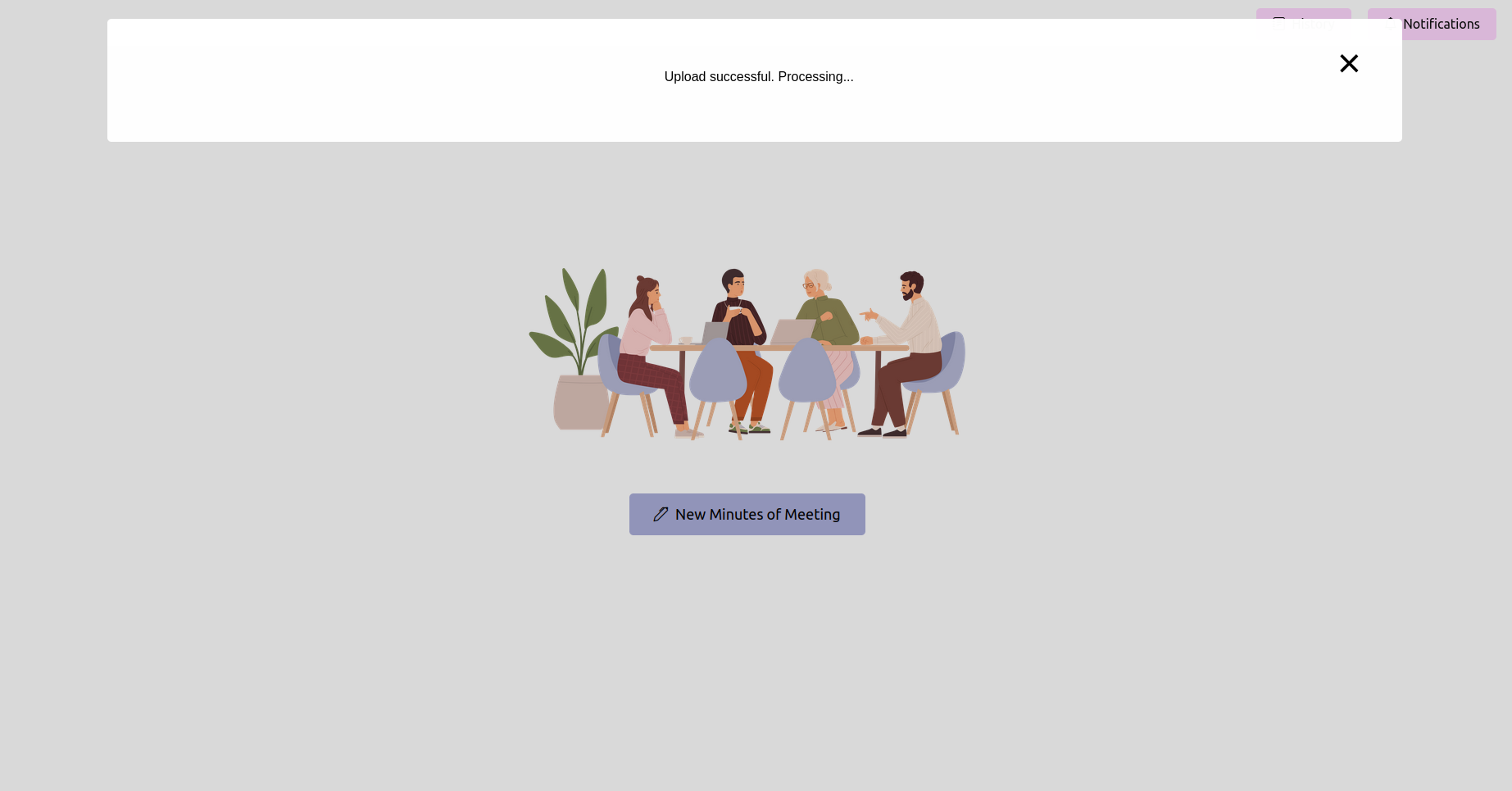
최신 상태를 얻고 완료 될 때까지 기다리십시오
녹음을 업로드 한 후 처리 상태를 확인할 수 있습니다. 응용 프로그램의 상태 페이지 또는 진행률 표시 줄로 구현 될 수 있습니다. 처리가 완료 될 때까지 기다리십시오.
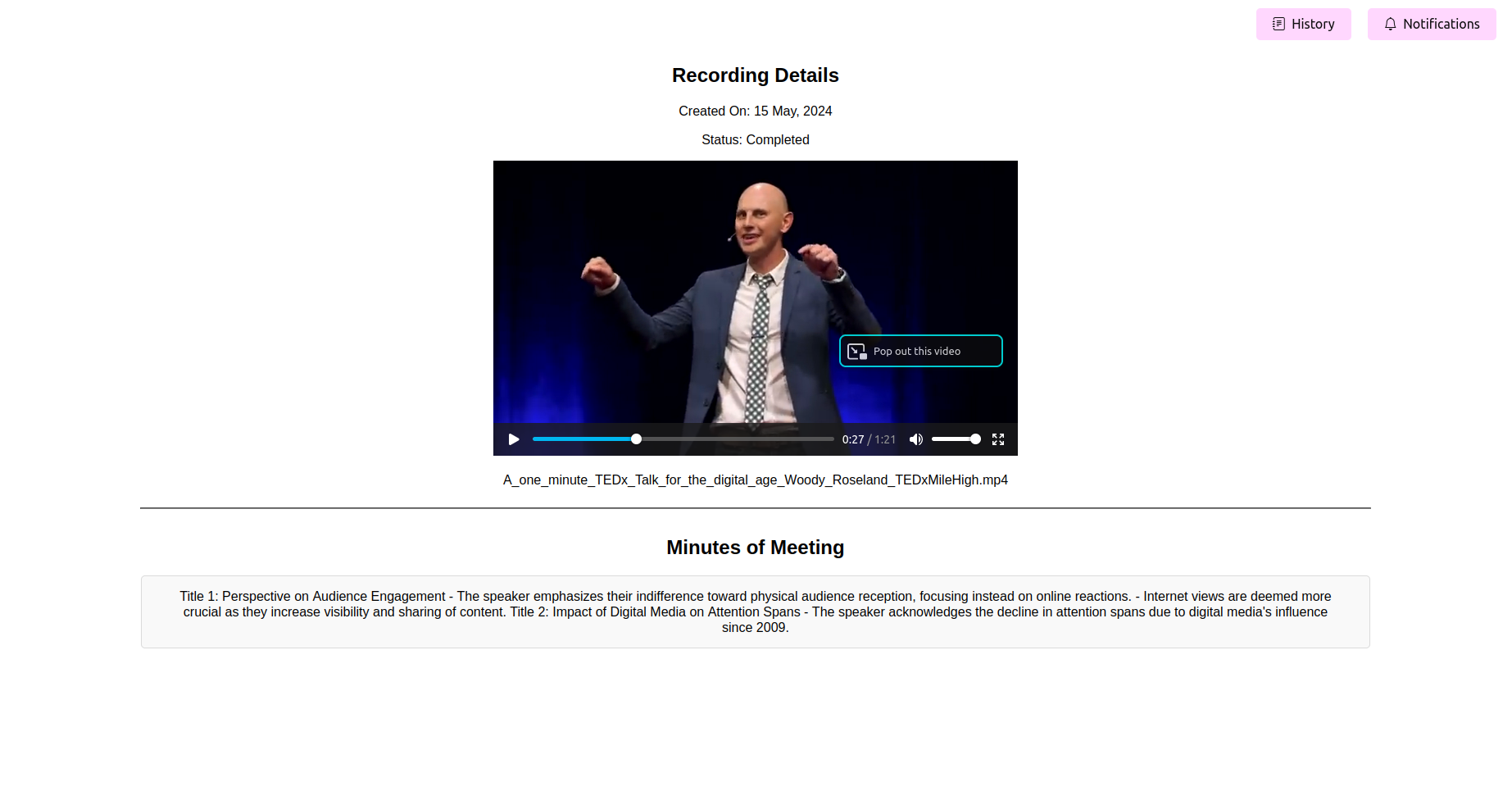
최종 처리 된 회의 회의록 (엄마) 참조
처리가 완료되면 응용 프로그램은 회의의 마지막 시간을 표시해야합니다. 당신은보기, 편집 (기능을 사용할 수있는 경우)을보고, 참조를 위해 엄마를 저장할 수 있습니다.
오디오 및 비디오 파일을 정확한 텍스트 성적표로 쉽게 변환합니다. 또한 요약, 작업 항목을 생성, 작업 흐름 이해 및 리소스 계획에도 사용될 수도 있습니다.
빠른 참조를위한 키워드 하이라이트 및 주제 태그 : 주제를 추출하고 관련 내용을 찾아 회의를 건너 뛰고 관심있는 특정 주제 만 듣습니다.
PDF 및 일반 텍스트를 포함한 다양한 형식의 수출 시간 : 회의 성적표, 요약, 주제 및 키워드, 액션 항목 등을 프로젝트 계획 및 관리 프레임 워크에 활용할 수있는 문서로 내보낼 수 있습니다. 또한 템플릿을 수동으로 작성하고 생성 할 필요가 없습니다.
쉽게 사용자 정의 및 통합을위한 사용자 친화적 인 인터페이스 : 선택하려는 오픈 소스 또는 폐쇄 소스 모델을 쉽게 조정하기 쉽습니다.
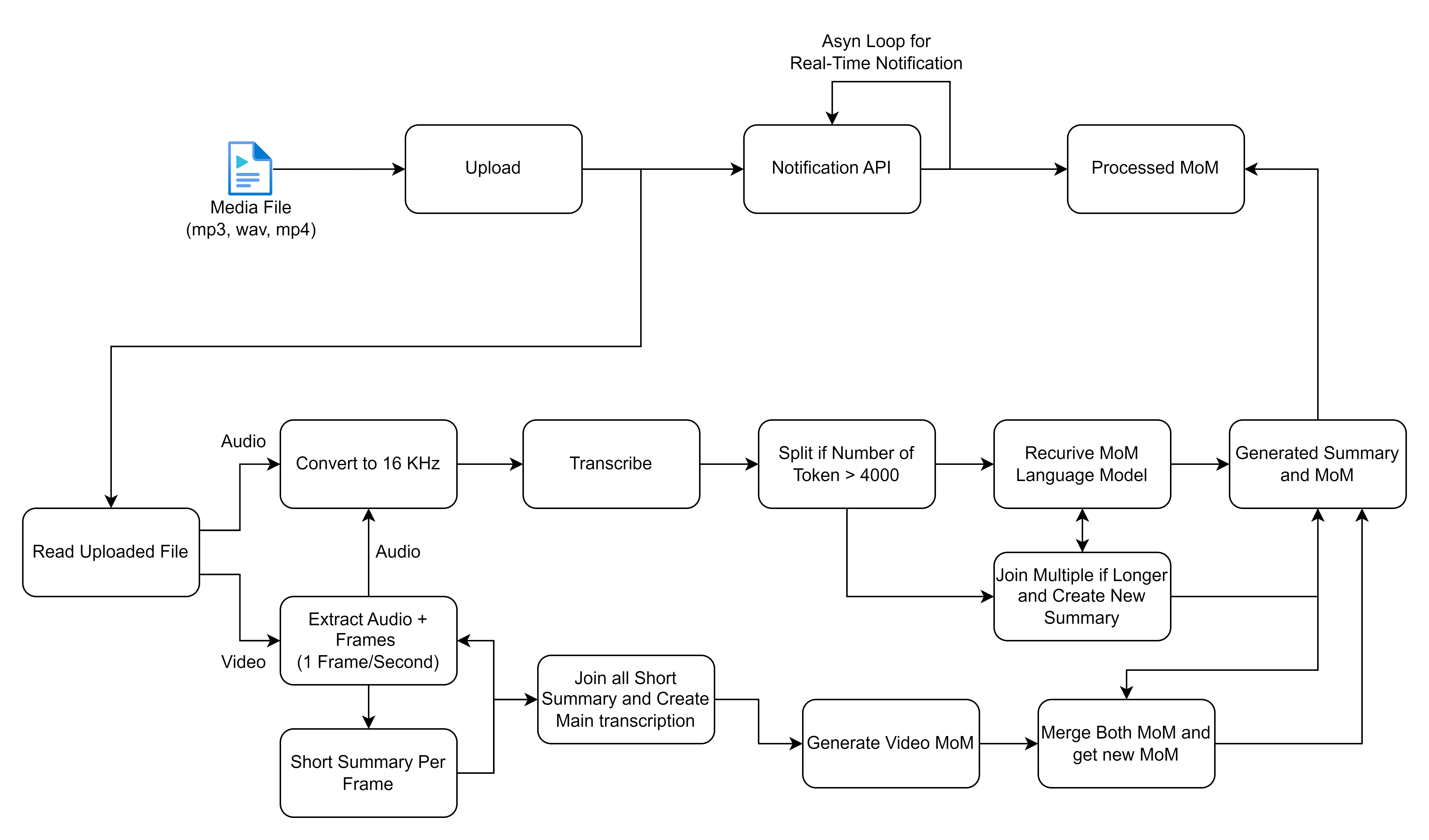
핵심 기능은 웹 응용 프로그램의 홈페이지를 통해 제출 된 회의 기록 처리와 관련이 있습니다. 녹음이 제출되면 셀러리를 사용하여 배경 작업이 시작되며, 이는 두 가지 주요 작업, 즉 음성-텍스트 변환 및 변환 된 텍스트에서 회의 시간을 생성하는 두 가지 주요 작업을 수행합니다.
공유 한 플로우 차트는 미디어 파일을 처리하고 처리하기위한 세부 프로세스, 특히 오디오 및 비디오 입력에 중점을 두어 전사 및 요약을 생성합니다. 각 단계를 세분화 하고이 워크 플로와 관련된 고급 솔루션을 설명해 봅시다.




진행하기 전에 다음과 같은 설치를했는지 확인하십시오.
virtualenv 또는 venv 와 같은 가상 환경 도구.requirements.txt 의 패키지가 호환되는지 확인하십시오. 프로젝트의 2 단계에서는 실시간 회의 전사를 가능하게 할 계획입니다. 효율적이고 협력적인 회의의 미래를 형성하는 데 참여하십시오!
? 2 단계 개발 및 기타 개선 사항에 대한 업데이트를 위해 회의를 더욱 생산적으로 만들 수 있습니다.
? 실시간 전사를 달성하는 데 도움이되는 아이디어와 전문 지식을 제공하십시오!


