LLM Minutes of Meeting
1.0.0
| Sr. Non | Sujet | Lien |
|---|---|---|
| 0. | Introduction et «pourquoi» du projet | Le lien viendra ici |
| 1 et 1 | Configuration et installation | Le lien viendra ici |
| 2 | Caractéristiques | Un autre lien |
| 3 et 3 | Captures d'écran de démo et d'application | Un autre lien |
| 4 | Approche et mise en œuvre * | Un autre lien |
| 5 | Mises à jour récentes et orientations futures | Un autre lien |
| 6. | Contributions | Un autre lien |
| 7 | Problèmes / dépannage | Un autre lien |

L'objectif principal de ce projet est de présenter la capacité de NLP & LLM à résumer rapidement les longues réunions et à vous aider, ainsi qu'à votre organisation, à automatiser la tâche de déléguer les procès-verbaux de la réunion (MOM). Il utilise une approche de haut niveau 2 où l'étape 1 correspond à la conversion de tout fichier audio / vidéo dans une conversation texte. L'étape 2 utilise le texte produit à l'étape 1 et génére des procès-verbaux de réunion et des notes de résumé détaillées. Ces procès-verbaux seront modifiables. Une fois que vous avez finalisé la maman, vous pouvez l'utiliser davantage selon vos besoins.
L'objectif à long terme de ce référentiel est également de développer une application Web Python en temps réel qui peut assister à des réunions pour vous et également vous fournir maman à la fin de la réunion. Faire des marches de bébé et essayer d'arriver à long terme en commençant un objectif à court terme.
Pour vos informations: je travaille sur les LLM et le développement personnalisés pour affiner. Soyez patient pendant que l'ensemble du projet est complètement stable. J'ajouterai le code de formation et d'inférence une fois terminé. Faites ce référentiel si vous avez besoin de connaître les dernières mises à jour. ? Appréciez votre temps.
Avant de continuer, assurez-vous que vous avez installé les suivants:
virtualenv ou venv .Commençons maintenant les étapes d'installation.
Cloner le référentiel github
Ouvrez votre terminal ou votre invite de commande et accédez au répertoire où vous souhaitez cloner le référentiel. Puis courez:
git clone https://github.com/inboxpraveen/LLM-Minutes-of-Meeting
cd LLM-Minutes-of-MeetingInstaller les exigences
C'est une bonne pratique de créer un environnement virtuel avant d'installer des dépendances pour éviter les conflits potentiels avec d'autres projets Python. Si vous utilisez virtualenv , vous pouvez configurer un nouvel environnement comme suit:
# # Create a python virtual environment and activate it.
# Install the required packages after activating:
pip install -r requirements.txt
# # After this, let's install Llama-Cpp-Python binding which will be used to interact with LLMs.
# # Run the following line if you are using it on a CPU.
pip install llama-cpp-python
# # Run the following line if you are using GPU (T4, A100, A10, or H100), or any Nvidia Cuda based GPU Drivers.
CMAKE_ARGS= " -DLLAMA_CUDA=on " pip install llama-cpp-python
# # If you are on Mac or any other GPU types, you can refer the following links and setup the Llama-Cpp-Python
https://llama-cpp-python.readthedocs.io/en/stable/ # installation-configuration
https://llama-cpp-python.readthedocs.io/en/stable/install/macos/Configurer Rabbitmq et Céleri
Utilisez le lien suivant pour configurer RabbitMQ sur votre machine. Suivez les instructions jusqu'à l'étape 5 et enregistrez votre admin-username et password .
Configuration de Rabbitmq sur Ubuntu 22.04
Une fois que vous avez réussi à configurer RabbitMQ, configurez Redis-Server et Celery. Utilisez la commande suivante pour les configurer et les installer.
sudo apt-get update -y
# # Try with apt-get. If it does not install, then run with apt.
sudo apt-get install redis-server -y
# # If the above does not work, try this:
sudo apt install redis-server -yExécuter l'application et parallèle Exécuter la tâche de céleri
Tout d'abord, démarrez l'application Flask:
cd /path/to/project/puis ouvrez le fichier app.py dans votre éditeur de code et modifiez la ligne suivante.
Line 18 : broker = 'amqp://<user>:<password>$@localhost:5672//'
## Update <user> with "your-admin-username".
## Update <password> with "your-admin-password"
## Eg: broker='amqp://admin:hello_world$@localhost:5672//'
### IMPORTANT NOTE: If your password contains '@' symbol, you will need to convert it because it is the default delimiter in broker settings. Example if your password has @ symbol inside it would be.
## broker='amqp://admin:hello%40world$@localhost:5672//' -- where the original password was "hello@world", we represent it as 'hello%40world' Après avoir mis à jour le fichier, vous exécuterez le fichier setup.py pour configurer les répertoires et télécharger des modèles. Si vous souhaitez modifier les configurations des modèles que vous souhaitez utiliser, vous pouvez les modifier de manière appropriée en fonction de la taille de votre infrastructure et de la capacité du système. Le tableau suivant montre quels modèles que nous prenons actuellement dans ce projet, mais nous ajouterons un nouveau support LLMS tel que nous les voyons en forme et en open source.
Modèles vocaux pris en charge
| Nom du modèle | Taille du modèle | Mémoire requise (RAM ou VRAM) |
|---|---|---|
| distil-whisper / distillag-v3 | 3,1 Go | 4 Go |
| distil-whisper / distillag-v2 | 3,1 Go | 4 Go |
| distil-whisper / distil-medium.en | 1,6 Go | 2 Go |
| distil-whisper / distil-small.en | 680 MB | 900 Mb |
| Openai / Whisper-Large-V3 | 6,2 Go | 7,5 Go |
| Openai / Whisper-Large-V2 | 6,2 Go | 7,5 Go |
| Openai / Whisper-Large-V1 | 6,2 Go | 7,5 Go |
| Openai / Whisper-Medium | 3,2 Go | 4,5 Go |
| openai / whisper-small (par défaut) | 980 MB | 1,7 Go |
LLMS pris en charge
| Nom du modèle | Taille du modèle | Mémoire requise |
|---|---|---|
| Quantfactory / PHI-3-MINI-4K-INSTRUCT-GGUF (par défaut) | 1 Go - 8 Go | 2 Go - 14 Go |
| Quantfactory / phi-3-min-128k-instruct-ganguf | 1 Go - 8 Go | 2,5 Go - 16 Go |
| Bartowski / PHI-3-Medium-128K-Instructe-Ganguf | 3 Go - 14 Go | 6 Go - 18 Go |
Vous devrez modifier le fichier global_varibables.py avec le nom du modèle que vous choisissez, puis exécuter le fichier setup.py qui baissera automatiquement les modèles que vous choisissez.
Line 32 : DEFAULT_SPEECH_MODEL = "openai/whisper-small"
...
Line 46 : DEFAULT_SUMMARY_MODEL = ( "QuantFactory/Phi-3-mini-4k-instruct-GGUF" , "Phi-3-mini-4k-instruct.Q5_0.gguf" )
### After update the above lines as per your need, run the setup.py
python setup . pyDans une nouvelle fenêtre de terminal (assurez-vous que votre environnement virtuel est également activé ici), démarrez l'application et le céleri:
python app.py # ensure your environment is activated
# and then in new terminal, run the following.
celery -A app.celery worker --loglevel=info -f celery.logsTélécharger l'enregistrement pour former
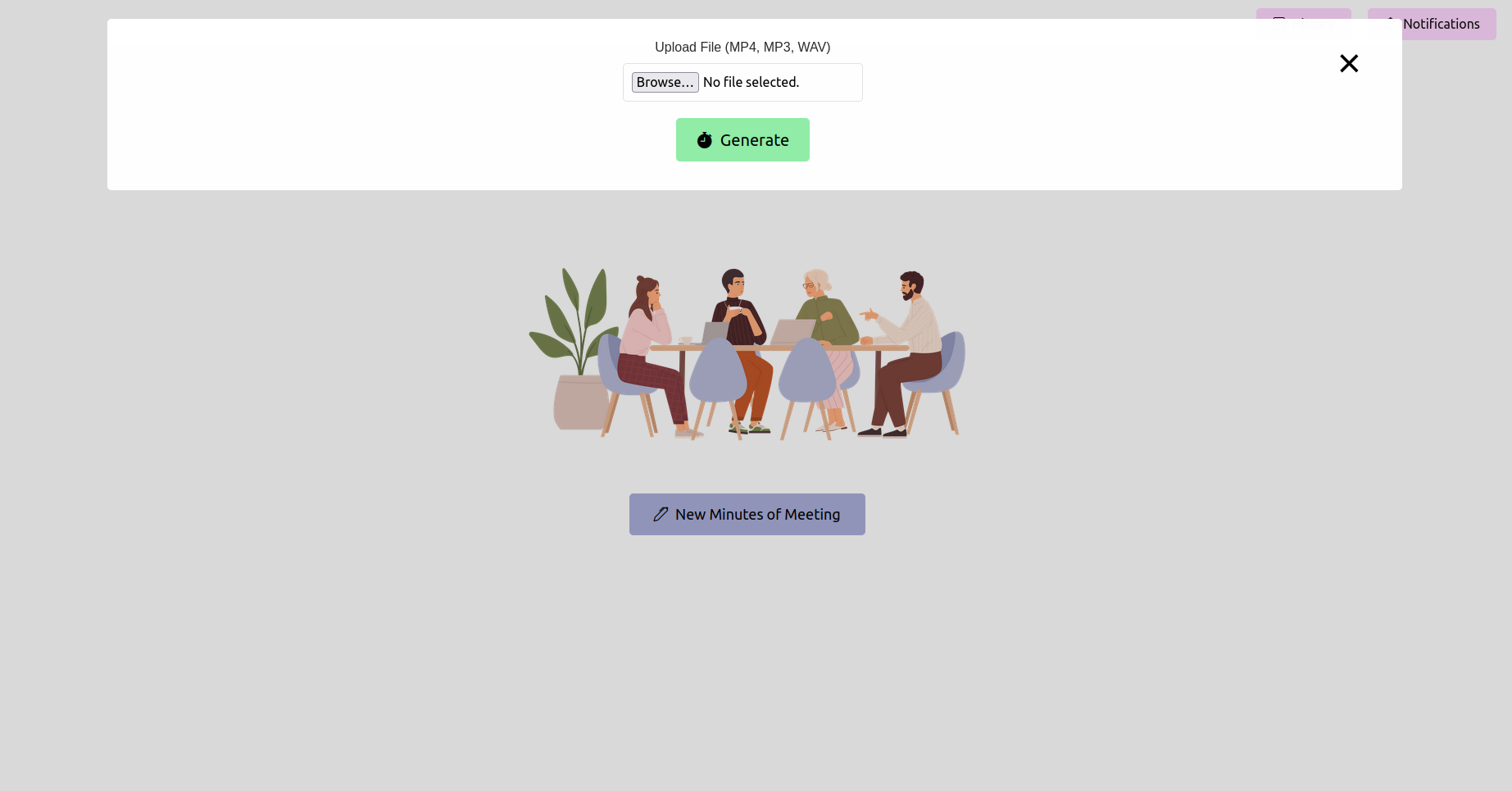
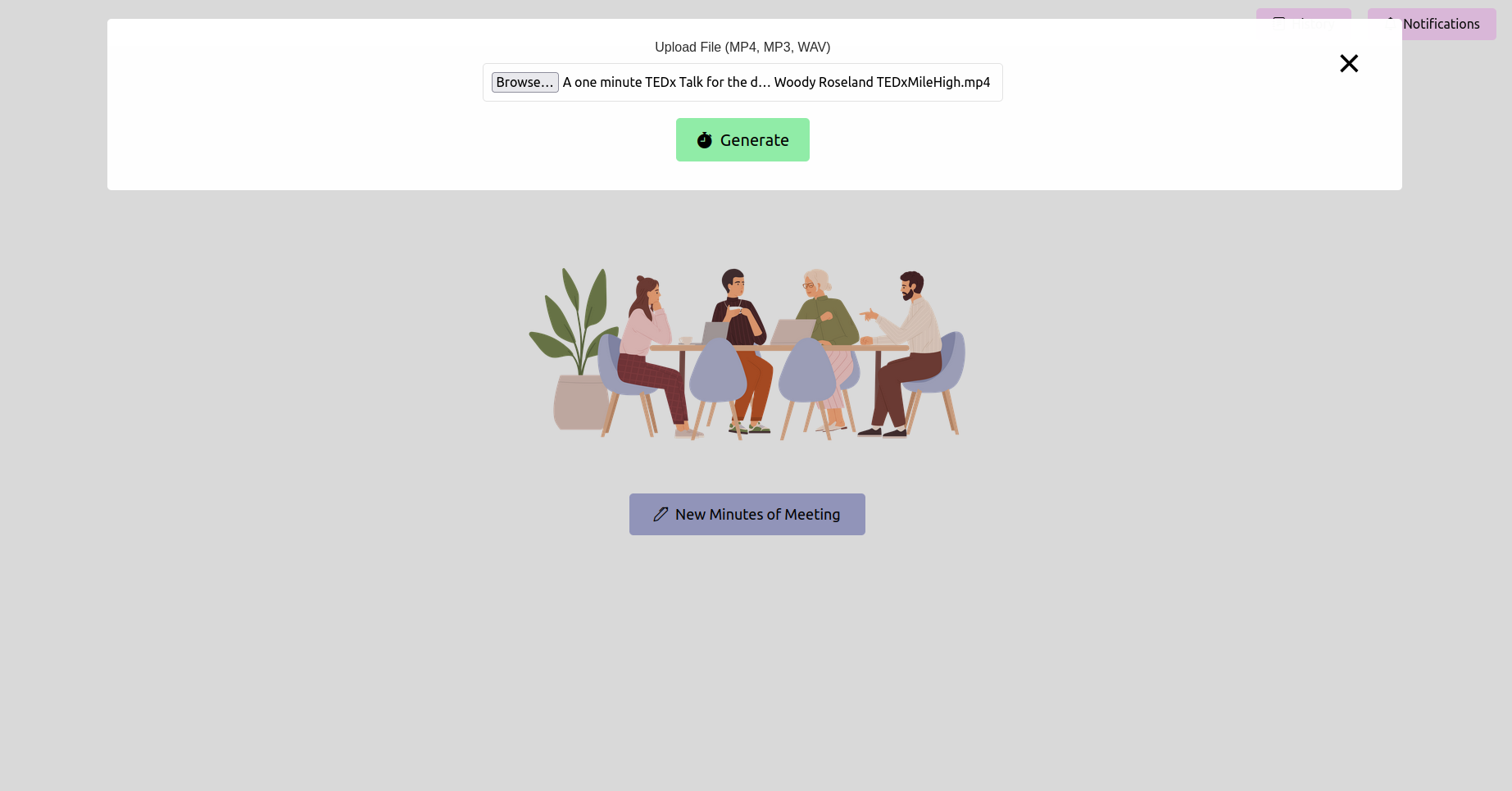
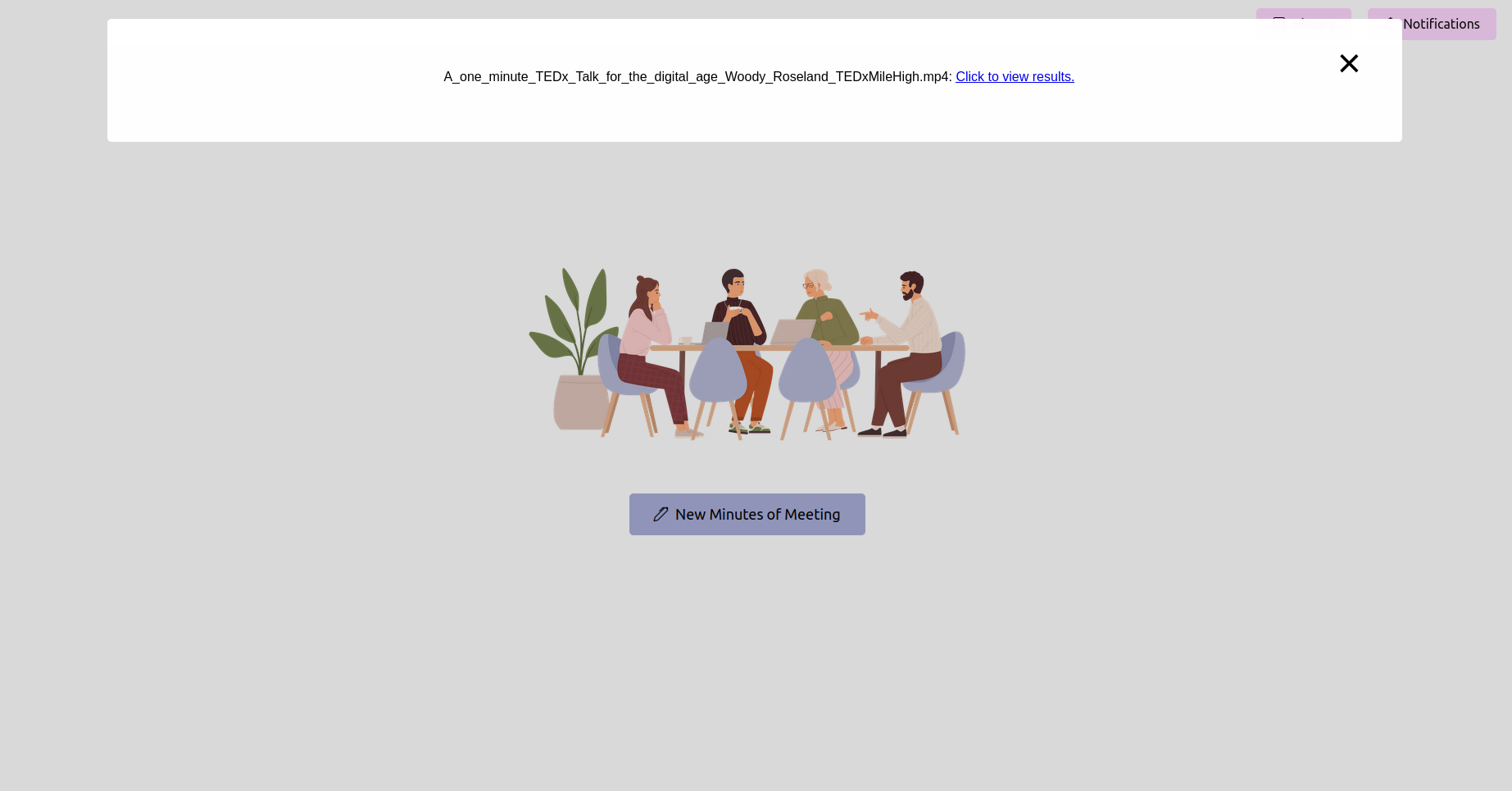
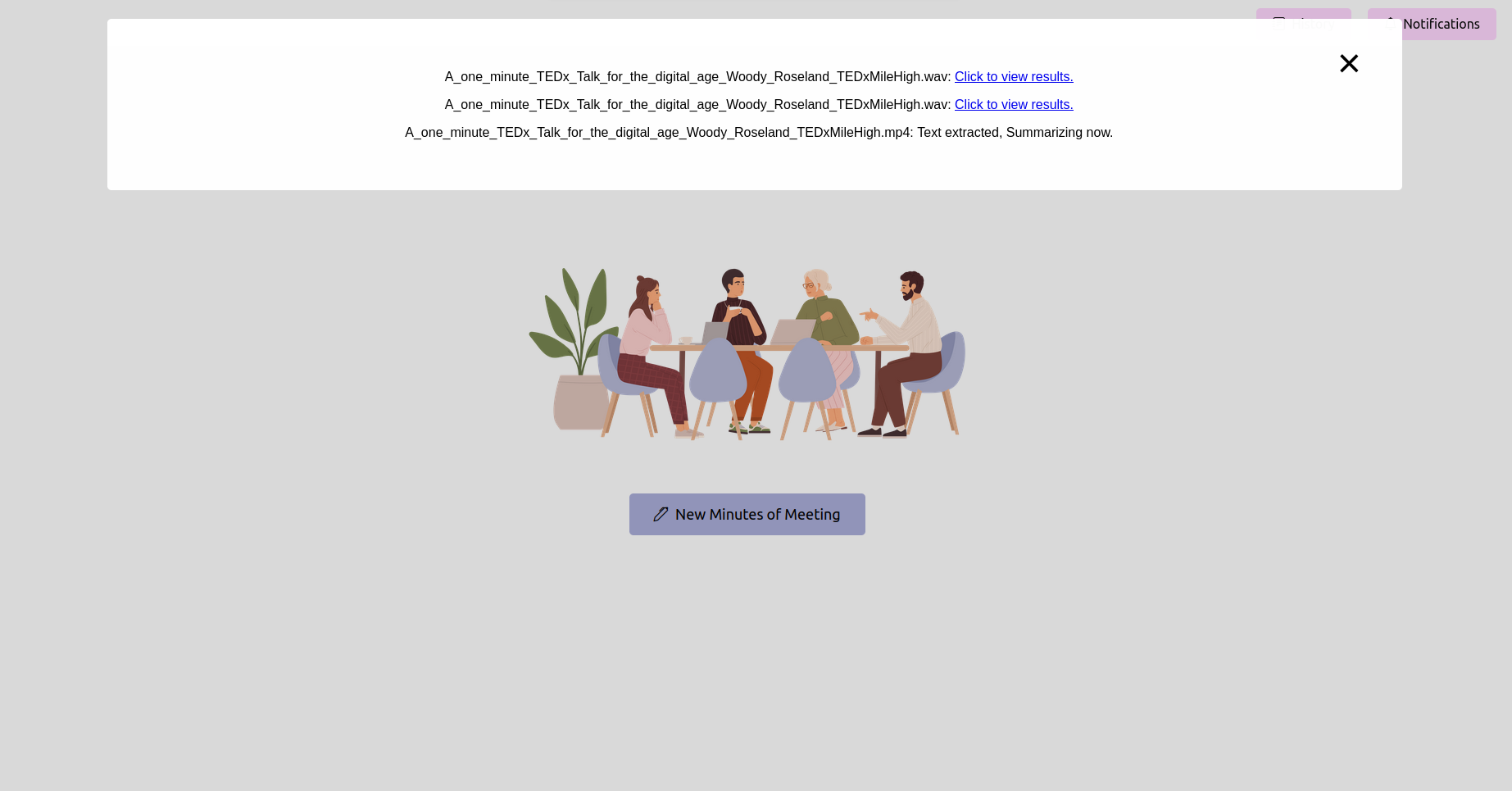
Ouvrez votre navigateur Web et accédez à l'URL de l'application FLASK (généralement http://127.0.0.1:5000 ). Utilisez l'interface pour télécharger votre enregistrement de réunion.
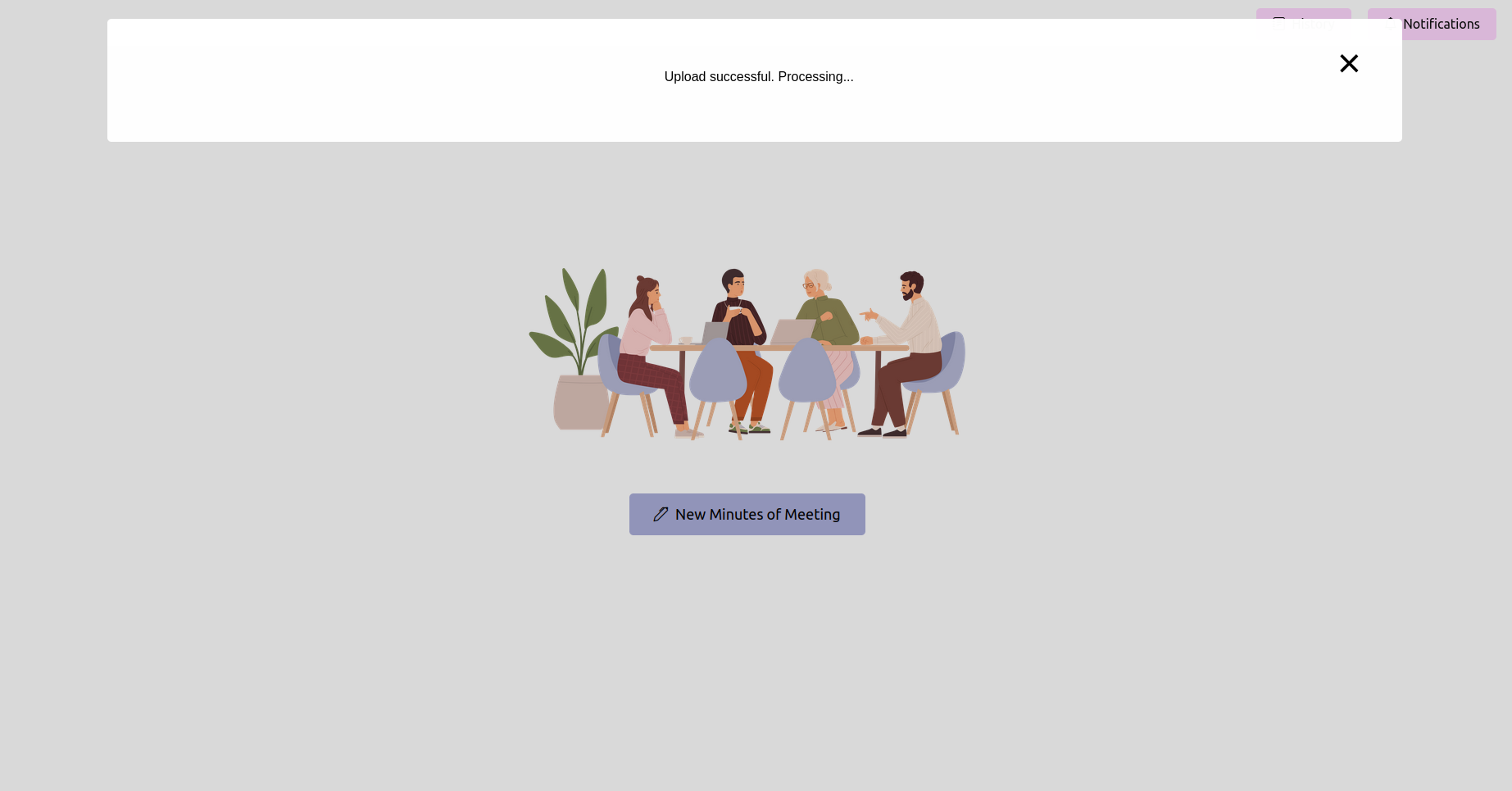
Obtenez le dernier statut et attendez qu'il termine
Après avoir téléchargé l'enregistrement, vous pouvez vérifier l'état du traitement. Cela pourrait être mis en œuvre en tant que page d'état ou barre de progression dans votre application. Attendez que le traitement soit terminé.
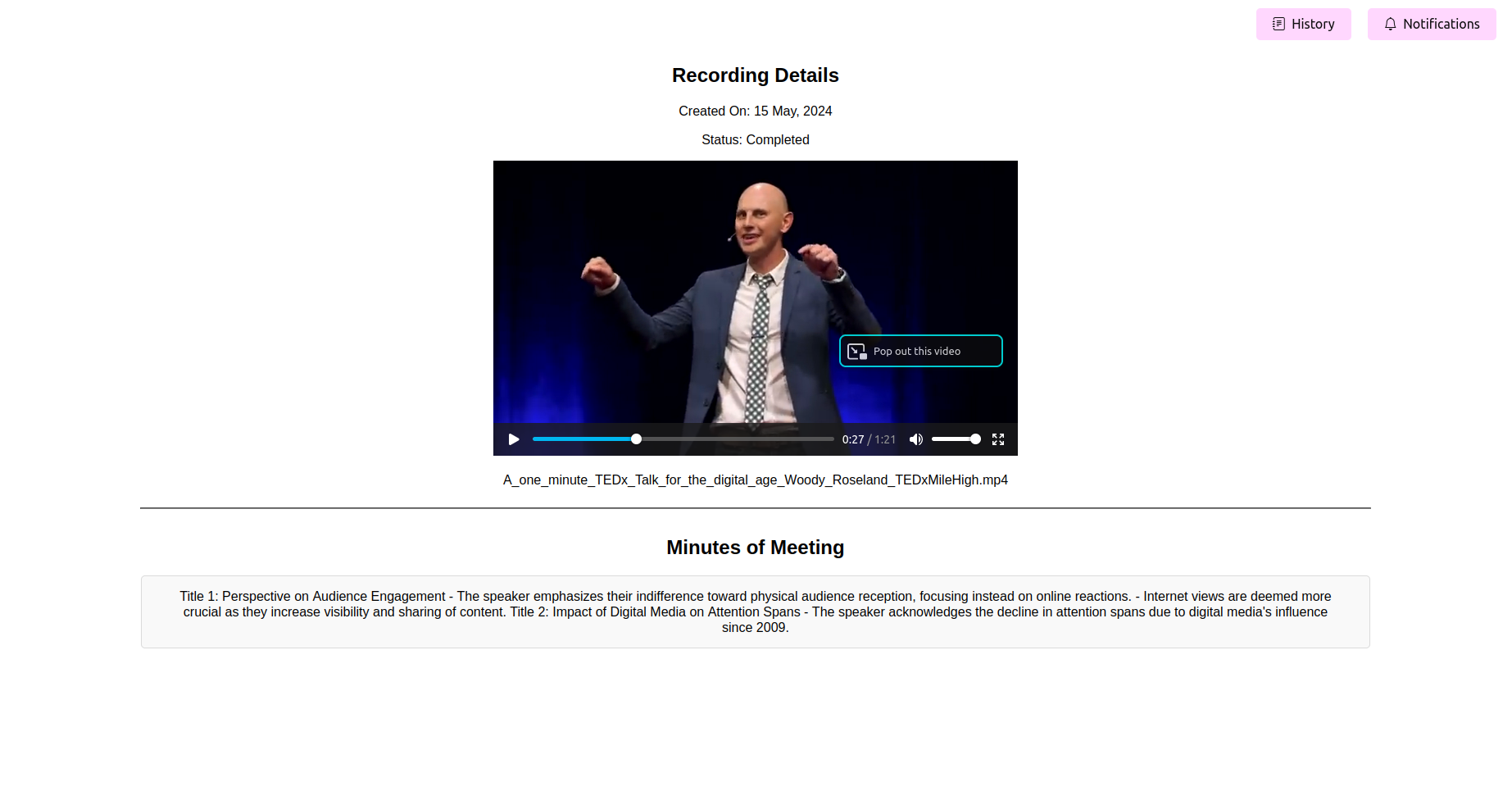
Voir les procès-verbaux de la réunion (maman) finales (maman)
Une fois le traitement terminé, l'application doit afficher les dernières minutes de la réunion. Vous pouvez afficher, modifier (si la fonctionnalité est disponible) et enregistrer la maman pour votre référence.
Convertir sans effort les fichiers audio et vidéo en transcriptions de texte précises: celles-ci peuvent également être utilisées pour résumer, générer des éléments d'action, comprendre les flux de travail et la planification des ressources.
Présentation des mots clés et étiquetage de sujet pour référence rapide: extraire des sujets et trouver des contenus pertinents pour sauter les réunions et écouter uniquement des sujets spécifiques qui présentent votre intérêt.
Les procès-verbaux d'exportation dans divers formats, y compris le PDF et le texte brut: vous permet d'exporter des transcriptions de réunion, des résumés, des mots-clés et des mots clés, des éléments d'action, etc. dans des documents qui peuvent être utilisés dans les cadres de planification de projet et de gestion. Élimine également votre besoin d'écrire et de générer manuellement des modèles.
Interface conviviale pour une personnalisation et une intégration faciles: facile à modifier le modèle de source open-open ou fermé que vous souhaitez choisir.
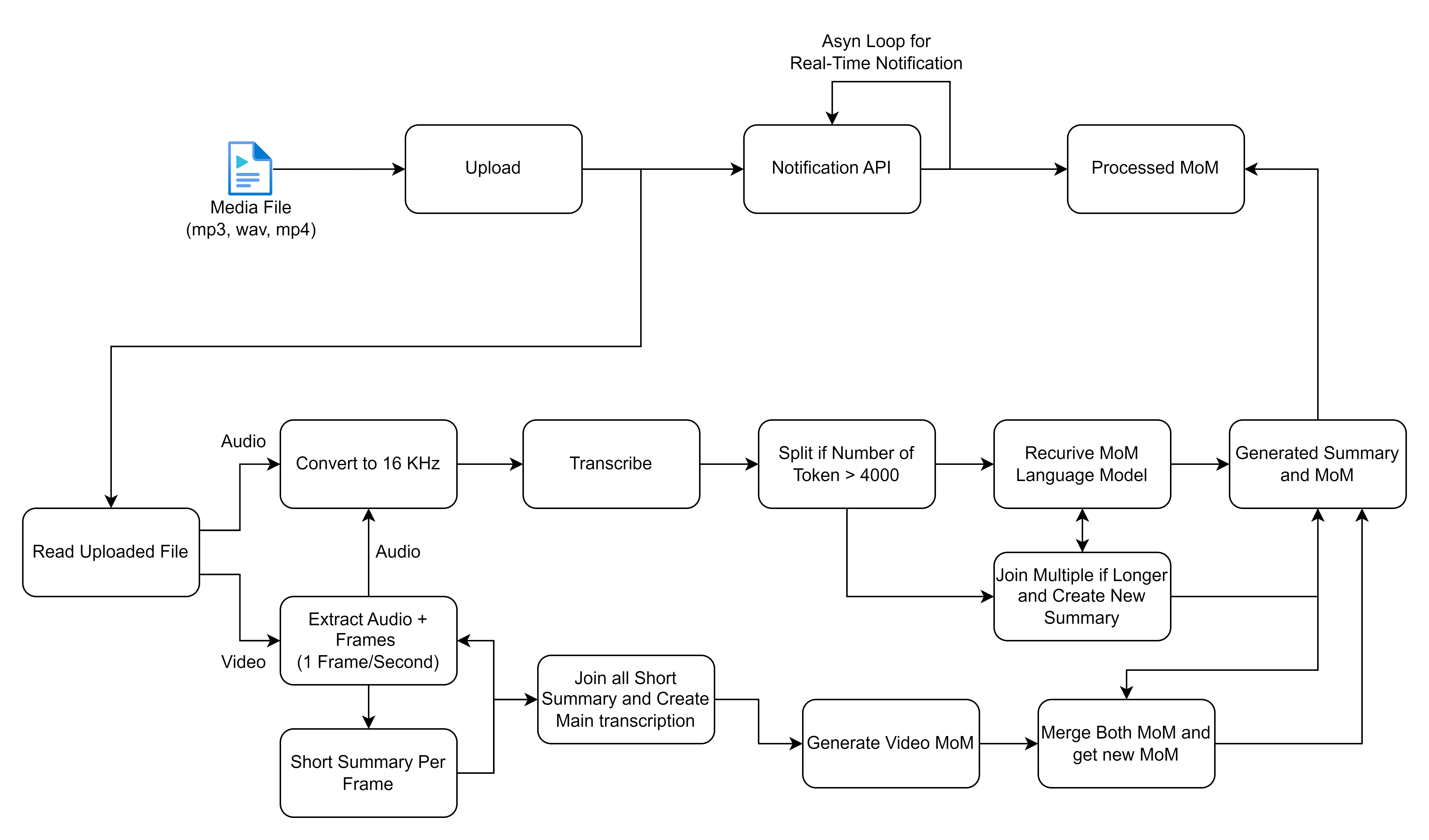
La fonctionnalité de base tourne autour du traitement des enregistrements des réunions de traitement soumis via la page d'accueil de l'application Web. Une fois qu'un enregistrement est soumis, une tâche d'arrière-plan est initiée à l'aide de céleri, qui effectue deux opérations principales: la conversion de la parole et du texte et la génération de minutes de la réunion à partir du texte converti.
L'organigramme que vous avez partagé décrit un processus détaillé de traitement et de traitement des fichiers multimédias, en se concentrant en particulier sur les entrées audio et vidéo pour générer des transcriptions et des résumés. Décomposons chaque étape et décrivons les solutions de haut niveau impliquées dans ce flux de travail:




Avant de continuer, assurez-vous que vous avez installé les suivants:
virtualenv ou venv .requirements.txt sont compatibles. Dans la phase 2 de notre projet, nous prévoyons de permettre la transcription des réunions en temps réel. Rejoignez-nous pour façonner l'avenir des réunions efficaces et collaboratives!
? Suivez-moi pour des mises à jour sur le développement de la phase 2 et d'autres améliorations pour rendre vos réunions encore plus productives.
? Encourageant les contributions de la communauté à faire en sorte que cet outil change la donne pour les réunions partout. Contribuez vos idées et votre expertise pour nous aider à réaliser une transcription en temps réel!


