LLM Minutes of Meeting
1.0.0
| Sr. No. | Tópico | Link |
|---|---|---|
| 0. | Introdução e "porquê" do projeto | Link virá aqui |
| 1. | Configuração e instalação | Link virá aqui |
| 2. | Características | Outro link |
| 3. | Capturas de demonstração e aplicação | Outro link |
| 4. | Abordagem e implementação* | Outro link |
| 5. | Atualizações recentes e direções futuras | Outro link |
| 6. | Contribuições | Outro link |
| 7. | Questões/solução de problemas | Outro link |

O objetivo principal deste projeto é mostrar a capacidade da NLP & LLM de resumir rapidamente reuniões longas e ajudar você e sua organização a automatizar a tarefa de delegar atas de e -mails de reunião (MOM). Ele usa uma abordagem de alto nível 2, onde a etapa 1 corresponde à conversão de qualquer arquivo de áudio/vídeo em uma conversa de texto. A etapa 2 utiliza o texto produzido pela etapa 1 e gera minutos de reunião e notas de resumo detalhadas. Essas minutos de reunião serão editáveis em texto. Depois de finalizar a mãe, você pode usá -lo ainda mais conforme sua exigência.
O objetivo de longo prazo para este repositório também é desenvolver uma aplicação na web em tempo real do Python, que pode participar de reuniões para você e também fornecer a você mãe no final da reunião. Dando passos do bebê e tentando chegar a longo prazo, iniciando um objetivo de curto prazo.
Para sua informação: estou trabalhando em LLMs e desenvolvimento personalizados de ajuste fino. Por favor, seja paciente enquanto todo o projeto estiver completamente estável. Vou adicionar código de treinamento e inferência depois de concluído. Faça este repositório se precisar saber as últimas atualizações. ? Agradeço seu tempo.
Antes de prosseguir, verifique se você tem o seguinte instalado:
virtualenv ou venv .Vamos começar as etapas de instalação agora.
Clone o repositório do GitHub
Abra seu terminal ou prompt de comando e navegue até o diretório, onde deseja clonar o repositório. Em seguida, corra:
git clone https://github.com/inboxpraveen/LLM-Minutes-of-Meeting
cd LLM-Minutes-of-MeetingInstale requisitos
É uma boa prática criar um ambiente virtual antes de instalar dependências para evitar possíveis conflitos com outros projetos Python. Se você estiver usando virtualenv , pode configurar um novo ambiente da seguinte maneira:
# # Create a python virtual environment and activate it.
# Install the required packages after activating:
pip install -r requirements.txt
# # After this, let's install Llama-Cpp-Python binding which will be used to interact with LLMs.
# # Run the following line if you are using it on a CPU.
pip install llama-cpp-python
# # Run the following line if you are using GPU (T4, A100, A10, or H100), or any Nvidia Cuda based GPU Drivers.
CMAKE_ARGS= " -DLLAMA_CUDA=on " pip install llama-cpp-python
# # If you are on Mac or any other GPU types, you can refer the following links and setup the Llama-Cpp-Python
https://llama-cpp-python.readthedocs.io/en/stable/ # installation-configuration
https://llama-cpp-python.readthedocs.io/en/stable/install/macos/Configurar RabbitMQ & Celery Background Job Processing
Use o link a seguir para configurar o RabbitMQ em sua máquina. Siga as instruções até a etapa 5 e salve seu admin-username e password .
Configure o rabbitMQ no Ubuntu 22.04
Depois de configurar com sucesso o RabbitMQ, configure o Redis-Server e o aipo. Use o seguinte comando para configurá -los e instalá -los.
sudo apt-get update -y
# # Try with apt-get. If it does not install, then run with apt.
sudo apt-get install redis-server -y
# # If the above does not work, try this:
sudo apt install redis-server -yExecutar a Tarefa de Aplicativo e Execução Paralela
Primeiro, inicie o aplicativo Flask:
cd /path/to/project/e depois abra o arquivo app.py dentro do seu editor de código e modifique a seguinte linha.
Line 18 : broker = 'amqp://<user>:<password>$@localhost:5672//'
## Update <user> with "your-admin-username".
## Update <password> with "your-admin-password"
## Eg: broker='amqp://admin:hello_world$@localhost:5672//'
### IMPORTANT NOTE: If your password contains '@' symbol, you will need to convert it because it is the default delimiter in broker settings. Example if your password has @ symbol inside it would be.
## broker='amqp://admin:hello%40world$@localhost:5672//' -- where the original password was "hello@world", we represent it as 'hello%40world' Depois de atualizar o arquivo, você executará o arquivo setup.py para configurar diretórios e download de modelos. Se você deseja alterar as configurações de quais modelos deseja usar, pode alterá -los adequadamente com base no tamanho da sua infraestrutura e na capacidade do sistema. A tabela a seguir mostra quais modelos suportamos atualmente neste projeto, mas adicionaremos um novo suporte ao LLMS, pois os vemos adequados e de código aberto.
Modelos de fala suportados
| Nome do modelo | Tamanho do modelo | Memória necessária (RAM ou VRAM) |
|---|---|---|
| Whisper/Distil-Large-V3 destilo | 3,1 GB | 4GB |
| Whisper/Distil-Large-V2 destilo | 3,1 GB | 4GB |
| Whisper/Distil-Medium | 1,6 GB | 2 GB |
| Whisper/Distil-small.en | 680 MB | 900 MB |
| OpenAI/Whisper-Large-V3 | 6.2 GB | 7,5 GB |
| OpenAI/Whisper-Large-V2 | 6.2 GB | 7,5 GB |
| OpenAI/Whisper-Large-V1 | 6.2 GB | 7,5 GB |
| OpenAI/Whisper-Medium | 3,2 GB | 4,5 GB |
| Openai/Whisper-small (padrão) | 980 MB | 1,7 GB |
LLMS suportado
| Nome do modelo | Tamanho do modelo | Memória necessária |
|---|---|---|
| QuantFactory/Phi-3-Mini-4K-Instruct-GGUF (padrão) | 1 GB - 8 GB | 2 GB - 14 GB |
| QuantFactory/PHI-3-MINI-128K-Instruct-GGUF | 1 GB - 8 GB | 2,5 GB - 16 GB |
| Bartowski/Phi-3-Medium-128K-Instruct-GGUF | 3 GB - 14 GB | 6 GB - 18 GB |
Você precisará modificar o arquivo global_varibables.py com o nome do modelo escolhido e executar o arquivo setup.py , que automaticamente reduzirá os modelos que você escolher.
Line 32 : DEFAULT_SPEECH_MODEL = "openai/whisper-small"
...
Line 46 : DEFAULT_SUMMARY_MODEL = ( "QuantFactory/Phi-3-mini-4k-instruct-GGUF" , "Phi-3-mini-4k-instruct.Q5_0.gguf" )
### After update the above lines as per your need, run the setup.py
python setup . pyEm uma nova janela do terminal (verifique se seu ambiente virtual também está ativado aqui), inicie o aplicativo e o trabalhador de aipo:
python app.py # ensure your environment is activated
# and then in new terminal, run the following.
celery -A app.celery worker --loglevel=info -f celery.logsEnvie a gravação para formar
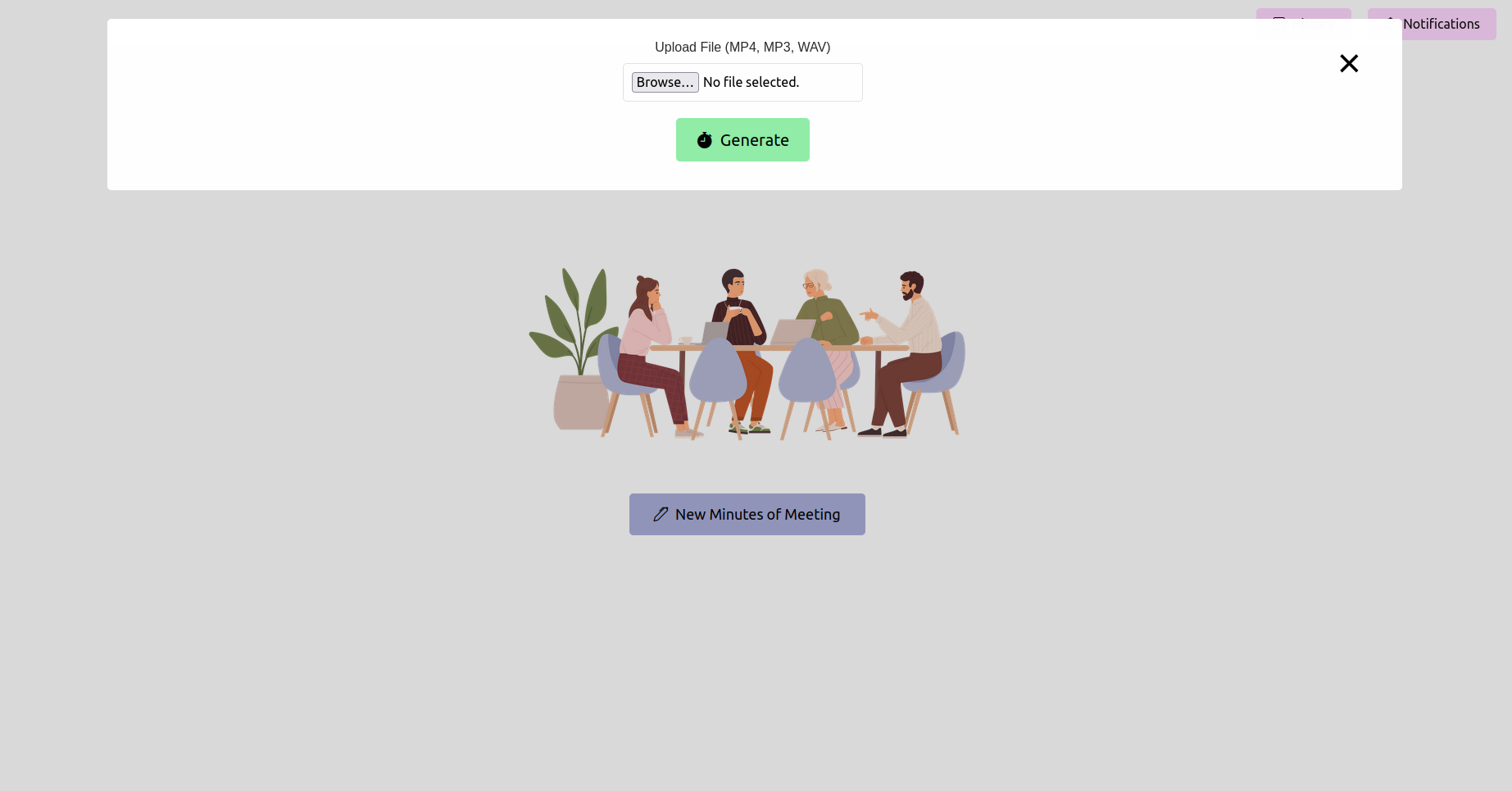
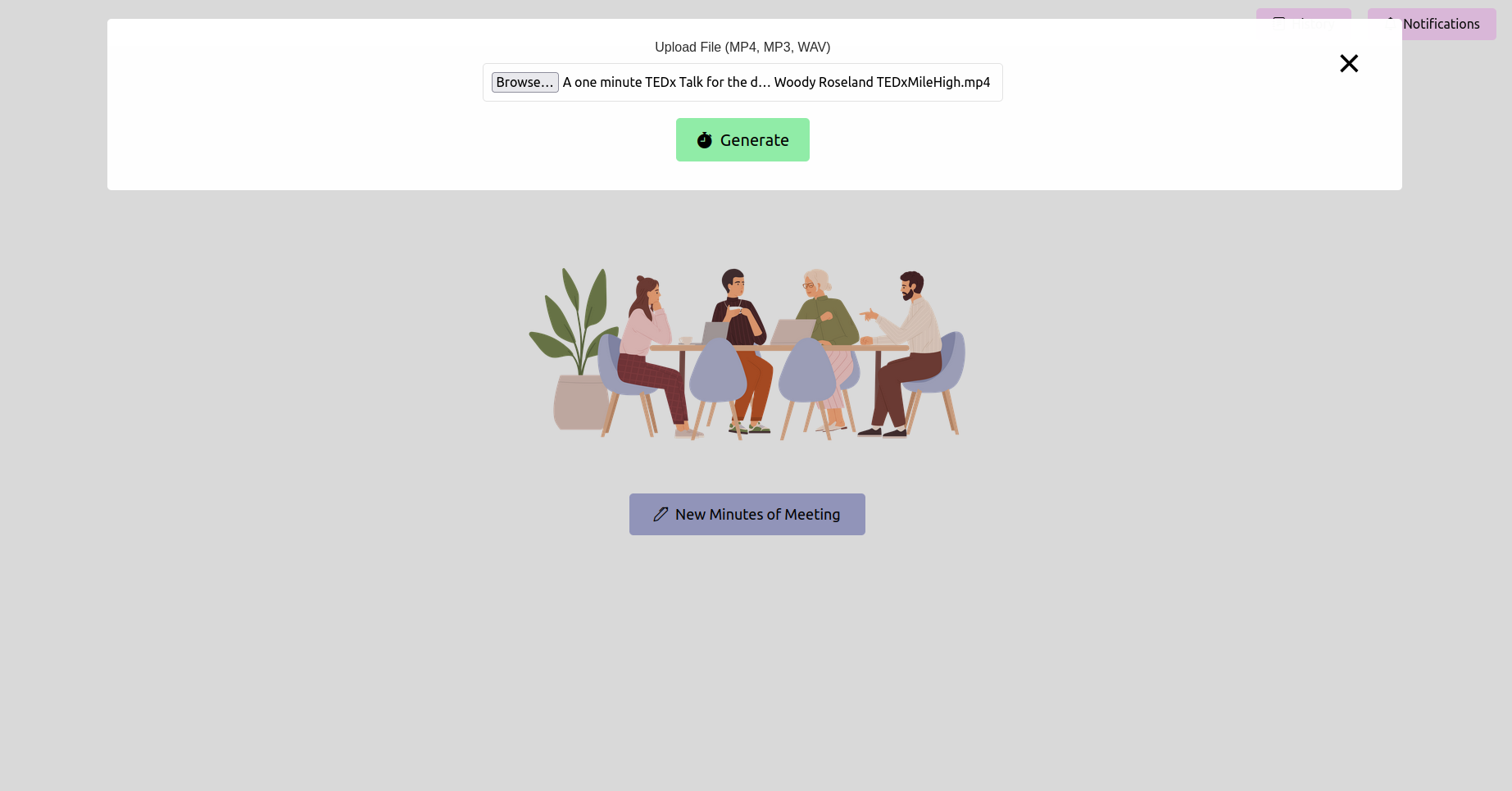
Abra o navegador da web e navegue até o URL do aplicativo de frasco (geralmente http://127.0.0.1:5000 ). Use a interface para fazer upload de sua gravação de reunião.
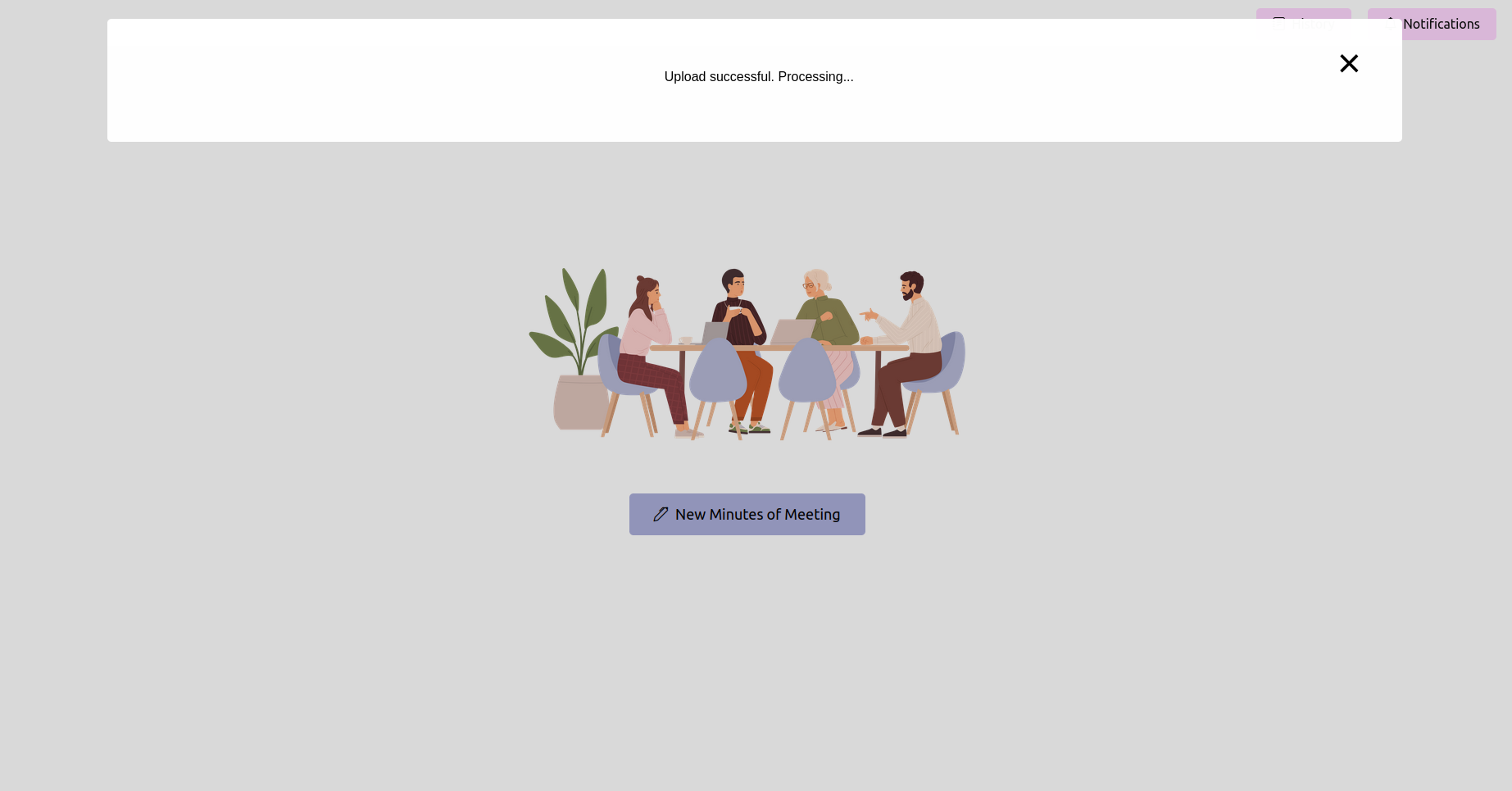
Obtenha o status mais recente e aguarde a conclusão
Depois de enviar a gravação, você pode verificar o status do processamento. Isso pode ser implementado como uma página de status ou uma barra de progresso em seu aplicativo. Aguarde até que o processamento seja concluído.
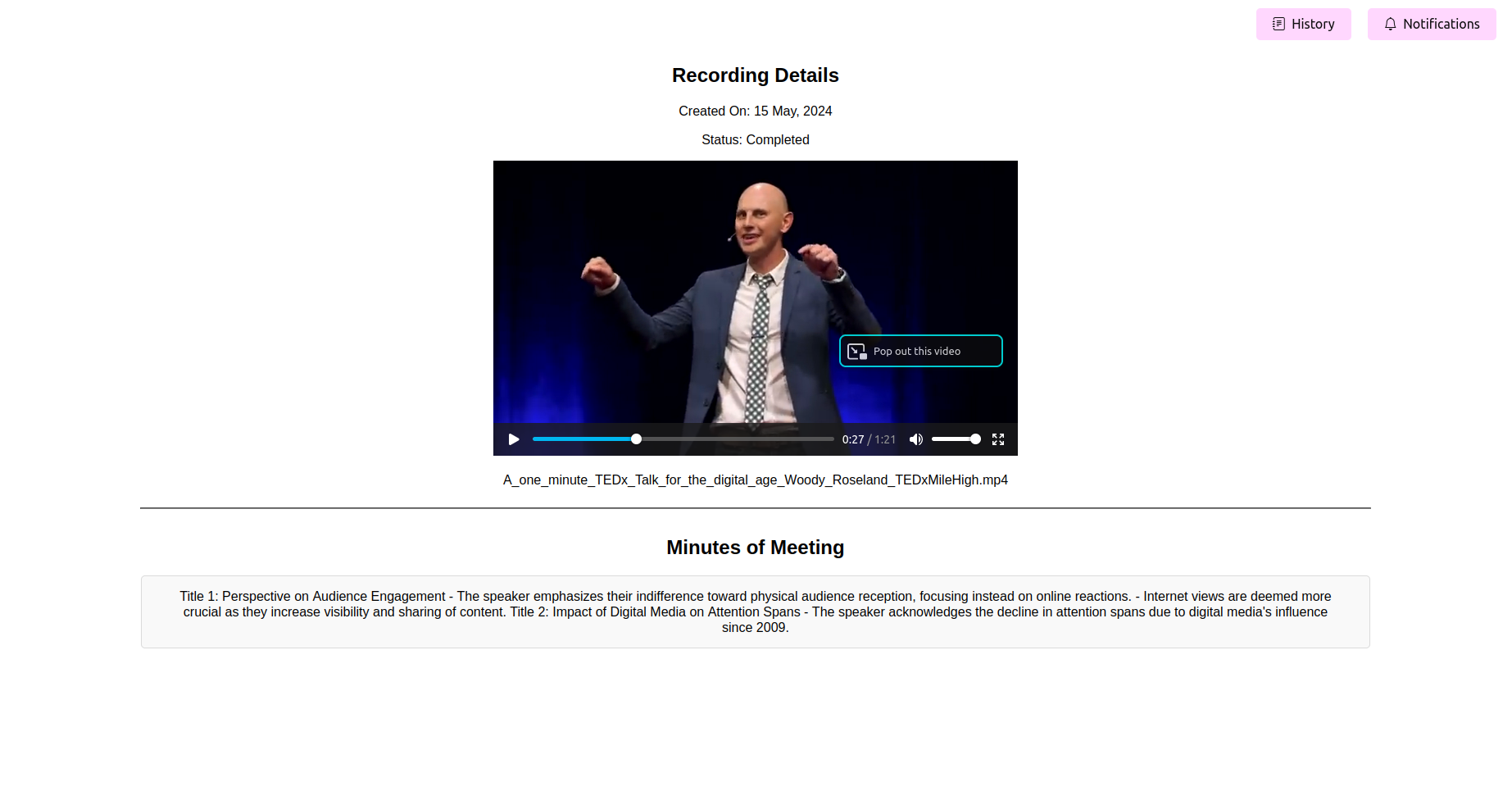
Veja as minutos finais processadas da reunião (mãe)
Depois que o processamento estiver concluído, o aplicativo deve exibir os minutos finais da reunião. Você pode visualizar, editar (se o recurso estiver disponível) e salve a mãe para sua referência.
Converter sem esforço arquivos de áudio e vídeo em transcrições de texto precisas: elas também podem ser usadas para resumir, gerar itens de ação, entender os fluxos de trabalho e o planejamento de recursos.
Destaque de palavras -chave e marcação de tópicos para referência rápida: Extraindo tópicos e encontrando conteúdos relevantes para pular através de reuniões e ouvir apenas tópicos específicos que são do seu interesse.
Exportar minutos em vários formatos, incluindo PDF e texto simples: permite exportar transcrições de reuniões, resumos, tópicos e palavras -chave, itens de ação, etc. em documentos que podem ser utilizados nas estruturas de planejamento e gerenciamento de projetos. Também elimina sua necessidade de escrever e gerar modelos manualmente.
Interface amigável para fácil personalização e integração: fácil ajustar o modelo de código aberto ou de código fechado que você deseja escolher.
A funcionalidade principal gira em torno do processamento de gravações de reunião enviadas pela página inicial do aplicativo da web. Depois que uma gravação é enviada, uma tarefa em segundo plano é iniciada usando o aipo, que executa duas operações primárias: conversão de fala em texto e geração de minutos da reunião a partir do texto convertido.
O FlowChart que você compartilhou descreve um processo detalhado para lidar e processamento de arquivos de mídia, focando particularmente nas entradas de áudio e vídeo para gerar transcrições e resumos. Vamos quebrar cada etapa e descrever as soluções de alto nível envolvidas neste fluxo de trabalho:
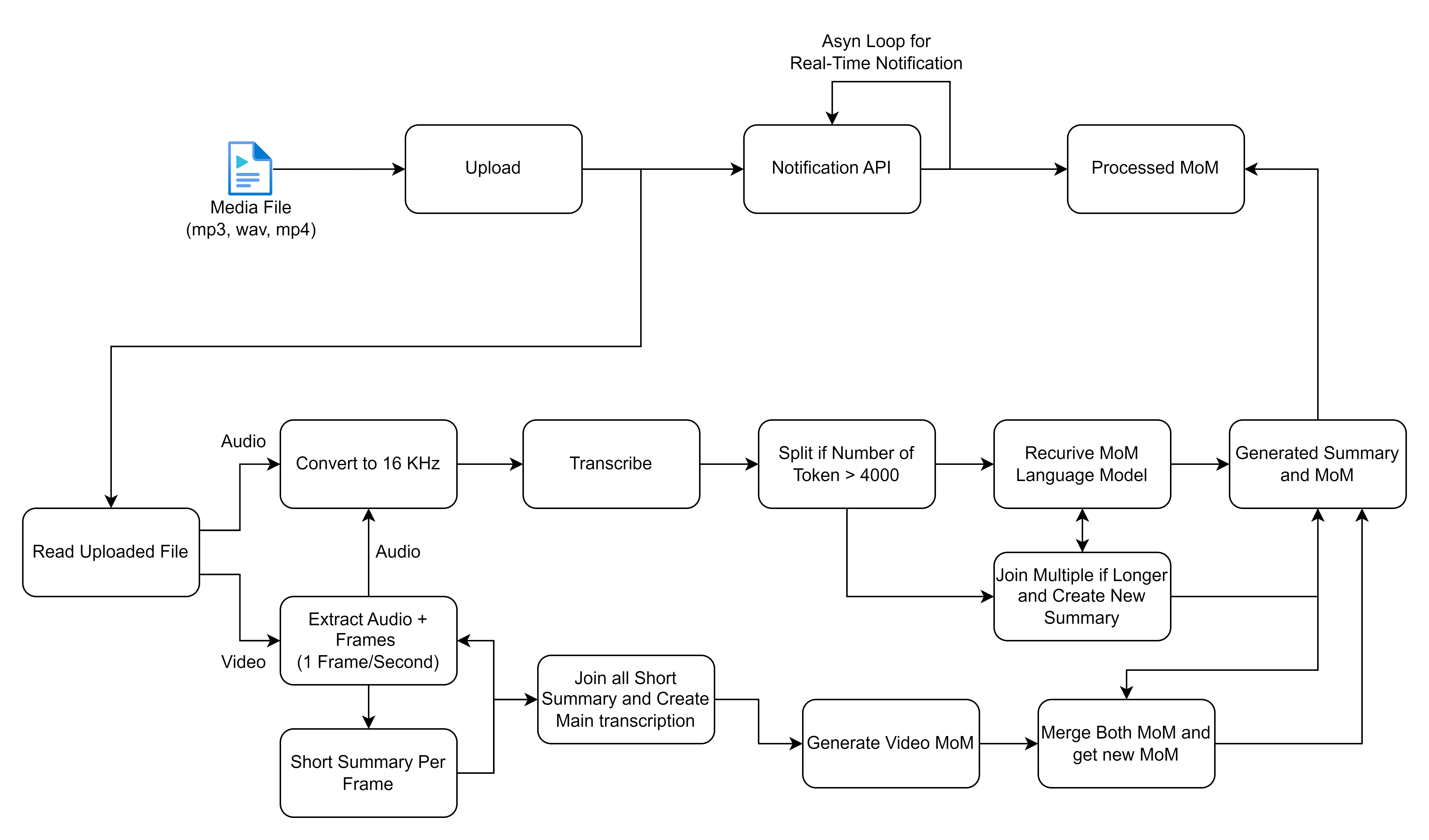




Antes de prosseguir, verifique se você tem o seguinte instalado:
virtualenv ou venv .requirements.txt são compatíveis. Na fase 2 do nosso projeto, planejamos permitir a transcrição em tempo real. Junte -se a nós na formação do futuro das reuniões eficientes e colaborativas!
? Siga -me para obter atualizações sobre o desenvolvimento da Fase 2 e outros aprimoramentos para tornar suas reuniões ainda mais produtivas.
Incentivar as contribuições da comunidade a tornar essa ferramenta uma mudança de jogo para reuniões em todos os lugares. Contribua com suas idéias e experiência para nos ajudar a alcançar a transcrição em tempo real!


