LLM Minutes of Meeting
1.0.0
| الأب رقم | عنوان | وصلة |
|---|---|---|
| 0. | مقدمة و "لماذا" المشروع | الرابط سيأتي إلى هنا |
| 1. | الإعداد والتركيب | الرابط سيأتي إلى هنا |
| 2. | سمات | رابط آخر |
| 3. | تجريبي وقطات شاشة للتطبيق | رابط آخر |
| 4. | النهج والتنفيذ* | رابط آخر |
| 5. | التحديثات الحديثة والاتجاهات المستقبلية | رابط آخر |
| 6. | مساهمات | رابط آخر |
| 7. | القضايا/استكشاف الأخطاء وإصلاحها | رابط آخر |

الهدف الأساسي من هذا المشروع هو عرض إمكانية NLP & LLM لتلخيص الاجتماعات الطويلة ومساعدتك ومؤسستك على أتمتة مهمة تفويض رسائل البريد الإلكتروني (MOM). يستخدم نهج الخطوة عالية المستوى 2 حيث يتوافق الخطوة 1 مع تحويل أي ملف صوتي/فيديو إلى محادثة نصية. تستخدم الخطوة 2 النص الناتج عن الخطوة 1 وإنشاء دقائق من الاجتماع وملاحظات موجزة مفصلة. ستكون محضر الاجتماع هذه نصًا قابلاً للتحرير. بمجرد الانتهاء من الأم ، يمكنك استخدامها أكثر وفقًا لمتطلباتك.
الهدف طويل الأجل لهذا المستودع هو أيضًا تطوير تطبيق ويب Python في الوقت الفعلي والذي يمكنه حضور الاجتماعات لك وأيضًا يوفر لك أمي في نهاية الاجتماع. اتخاذ خطوات الطفل ومحاولة الوصول إلى المدى الطويل من خلال بدء هدف قصير الأجل.
لمعلوماتك: أنا أعمل على صقل LLMs المخصص والتطوير. يرجى التحلي بالصبر بينما المشروع بأكمله مستقر تمامًا. سأضيف رمز التدريب والاستدلال بمجرد الانتهاء. قم بهذا المستودع إذا كنت بحاجة إلى معرفة آخر التحديثات. ؟ نقدر وقتك.
قبل المتابعة ، تأكد من تثبيت ما يلي:
virtualenv أو venv .لنبدأ خطوات التثبيت الآن.
استنساخ مستودع جيثب
افتح محطة الطرفية أو الأوامر وانتقل إلى الدليل حيث تريد استنساخ المستودع. ثم قم بالتشغيل:
git clone https://github.com/inboxpraveen/LLM-Minutes-of-Meeting
cd LLM-Minutes-of-Meetingتثبيت المتطلبات
إنها ممارسة جيدة لإنشاء بيئة افتراضية قبل تثبيت التبعيات لتجنب النزاعات المحتملة مع مشاريع بيثون الأخرى. إذا كنت تستخدم virtualenv ، فيمكنك إعداد بيئة جديدة على النحو التالي:
# # Create a python virtual environment and activate it.
# Install the required packages after activating:
pip install -r requirements.txt
# # After this, let's install Llama-Cpp-Python binding which will be used to interact with LLMs.
# # Run the following line if you are using it on a CPU.
pip install llama-cpp-python
# # Run the following line if you are using GPU (T4, A100, A10, or H100), or any Nvidia Cuda based GPU Drivers.
CMAKE_ARGS= " -DLLAMA_CUDA=on " pip install llama-cpp-python
# # If you are on Mac or any other GPU types, you can refer the following links and setup the Llama-Cpp-Python
https://llama-cpp-python.readthedocs.io/en/stable/ # installation-configuration
https://llama-cpp-python.readthedocs.io/en/stable/install/macos/إعداد RabbitMQ & Celery الخلفية معالجة الوظائف
استخدم الرابط التالي لإعداد RabbitMQ على جهازك. اتبع الإرشادات حتى الخطوة 5 وحفظ admin-username وكلمة password .
إعداد RabbitMQ على Ubuntu 22.04
بمجرد أن تنجح في إعداد RabbitMQ ، ثم قم بإعادة الإعداد لخادم وكرفس. استخدم الأمر التالي لإعدادها وتثبيتها.
sudo apt-get update -y
# # Try with apt-get. If it does not install, then run with apt.
sudo apt-get install redis-server -y
# # If the above does not work, try this:
sudo apt install redis-server -yتشغيل التطبيق ومهمة Run Run Celery
أولاً ، ابدأ تطبيق القارورة:
cd /path/to/project/ثم افتح ملف app.py بداخل محرر الرمز وقم بتعديل السطر التالي.
Line 18 : broker = 'amqp://<user>:<password>$@localhost:5672//'
## Update <user> with "your-admin-username".
## Update <password> with "your-admin-password"
## Eg: broker='amqp://admin:hello_world$@localhost:5672//'
### IMPORTANT NOTE: If your password contains '@' symbol, you will need to convert it because it is the default delimiter in broker settings. Example if your password has @ symbol inside it would be.
## broker='amqp://admin:hello%40world$@localhost:5672//' -- where the original password was "hello@world", we represent it as 'hello%40world' بعد تحديث الملف ، ستقوم بتشغيل ملف setup.py لإعداد الدلائل وتنزيل النماذج. إذا كنت ترغب في تغيير تكوينات النماذج التي ترغب في استخدامها ، فيمكنك تغييرها بشكل مناسب بناءً على حجم البنية التحتية وقدرة النظام. يوضح الجدول التالي النماذج التي ندعمها حاليًا في هذا المشروع ، لكننا سنضيف دعم LLMS جديد كما نراها مناسبة ومصدر مفتوح.
نماذج الكلام المدعومة
| اسم النموذج | حجم النموذج | الذاكرة مطلوبة (ذاكرة الوصول العشوائي أو VRAM) |
|---|---|---|
| distil-whisper/distil-large-v3 | 3.1 غيغابايت | 4 غيغابايت |
| distil-whisper/distil-large-v2 | 3.1 غيغابايت | 4 غيغابايت |
| distil-whisper/distil-medium.en | 1.6 جيجابايت | 2 غيغابايت |
| distil-whisper/distil-small.en | 680 ميغابايت | 900 ميغابايت |
| Openai/Whisper-Large-V3 | 6.2 غيغابايت | 7.5 جيجابايت |
| Openai/Whisper-Large-V2 | 6.2 غيغابايت | 7.5 جيجابايت |
| Openai/Whisper-Large-V1 | 6.2 غيغابايت | 7.5 جيجابايت |
| Openai/Whisper-Medium | 3.2 غيغابايت | 4.5 غيغابايت |
| Openai/Whisper-Small (افتراضي) | 980 ميغابايت | 1.7 غيغابايت |
LLMS المدعومة
| اسم النموذج | حجم النموذج | الذاكرة المطلوبة |
|---|---|---|
| QuantFactory/PHI-3-MINI-4K-instruct-GGUF (افتراضي) | 1 غيغابايت - 8 جيجابايت | 2 غيغابايت - 14 جيجابايت |
| QuantFactory/PHI-3-MINI-128K-instruct-gguf | 1 غيغابايت - 8 جيجابايت | 2.5 غيغابايت - 16 جيجابايت |
| Bartowski/PHI-3-Medium-128k-instruct-gguf | 3 غيغابايت - 14 جيجابايت | 6 غيغابايت - 18 جيجابايت |
ستحتاج إلى تعديل ملف global_varibables.py باسم النموذج الذي تختاره ثم تشغيل ملف setup.py الذي سيؤدي تلقائيًا إلى أسفل النماذج التي تختارها.
Line 32 : DEFAULT_SPEECH_MODEL = "openai/whisper-small"
...
Line 46 : DEFAULT_SUMMARY_MODEL = ( "QuantFactory/Phi-3-mini-4k-instruct-GGUF" , "Phi-3-mini-4k-instruct.Q5_0.gguf" )
### After update the above lines as per your need, run the setup.py
python setup . pyفي نافذة طرفية جديدة (تأكد من تنشيط بيئتك الافتراضية هنا أيضًا) ، ابدأ تطبيق التطبيق والكرفس:
python app.py # ensure your environment is activated
# and then in new terminal, run the following.
celery -A app.celery worker --loglevel=info -f celery.logsتحميل التسجيل لتشكيل
افتح متصفح الويب الخاص بك وانتقل إلى عنوان URL لتطبيق Flask (عادةً ما يكون http://127.0.0.1:5000 ). استخدم الواجهة لتحميل تسجيل الاجتماع الخاص بك.
احصل على أحدث حالة وانتظر حتى يكتمل
بعد تحميل التسجيل ، يمكنك التحقق من حالة المعالجة. يمكن تنفيذ ذلك كصفحة حالة أو شريط تقدم في التطبيق الخاص بك. انتظر حتى تكتمل المعالجة.
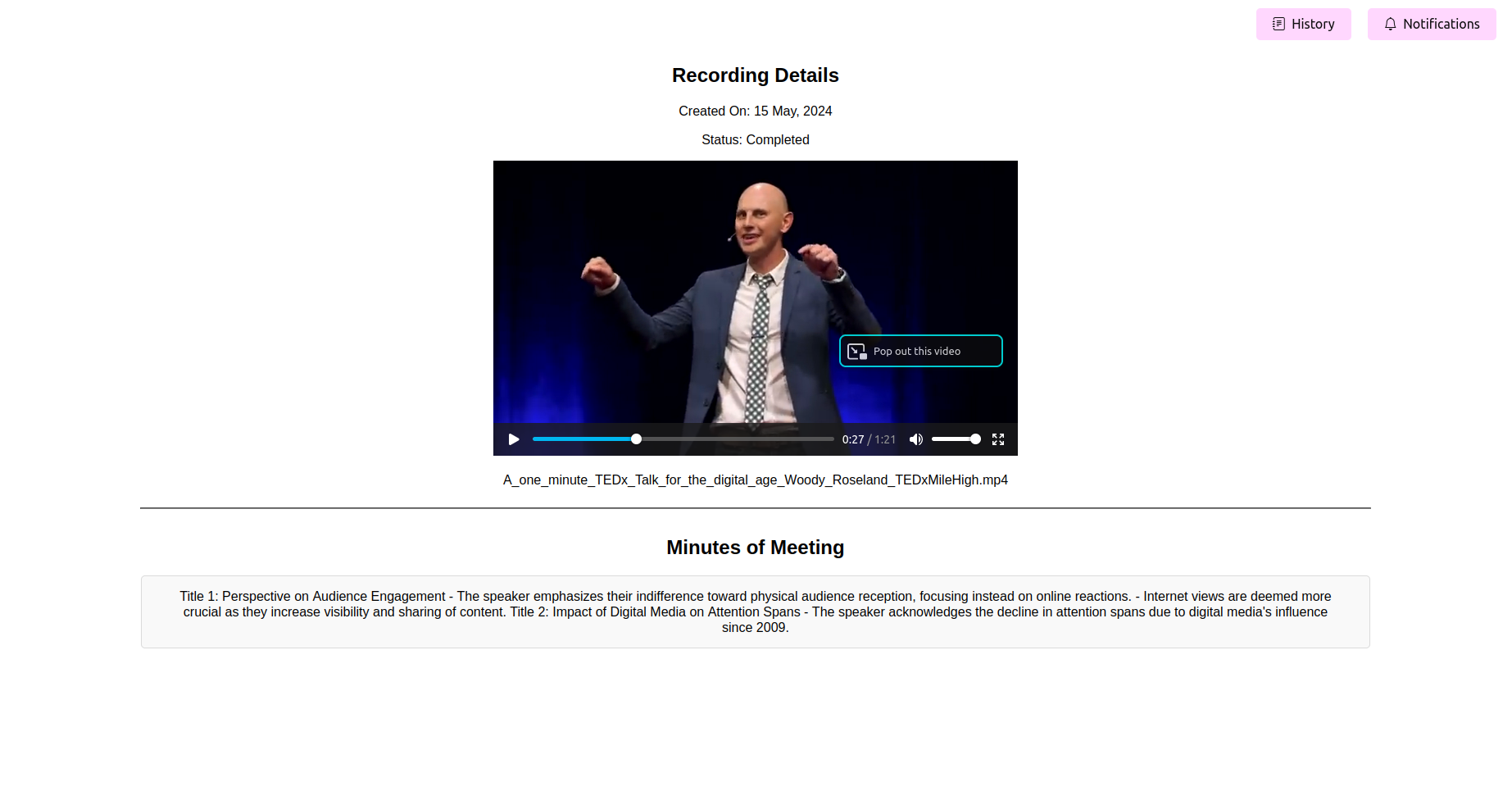
انظر الدقائق النهائية المعالجة للاجتماع (أمي)
بمجرد اكتمال المعالجة ، يجب أن يعرض التطبيق الدقائق الأخيرة من الاجتماع. يمكنك عرض ، تحرير (إذا كانت الميزة متوفرة) ، وحفظ أمي للرجوع إليها.
تحويل ملفات الصوت والفيديو دون عناء إلى نصوص نصية دقيقة: يمكن أيضًا استخدامها لتلخيص وإنشاء عناصر الإجراءات وفهم التدفقات والتخطيط للموارد.
تسليط الضوء على الكلمات الرئيسية ووضع العلامات للموضوع للمرجع السريع: استخراج الموضوعات وإيجاد المحتويات ذات الصلة للتخطي من خلال الاجتماعات والاستماع إلى مواضيع محددة فقط هي اهتمامك.
دقائق التصدير بتنسيقات مختلفة ، بما في ذلك PDF والنص العادي: يسمح لك بتصدير نصوص اجتماعات وملخصات وموضوع وكلمات رئيسية وعناصر الإجراء ، وما إلى ذلك في المستندات التي يمكن استخدامها في أطراف تخطيط وإدارة المشروع. يلغي أيضًا حاجتك إلى الكتابة وإنشاء قوالب يدويًا.
واجهة سهلة الاستخدام لسهولة التخصيص والتكامل: من السهل تعديل أي نموذج مفتوح المصدر أو مصدر مغلق تريد اختياره.
تدور الوظيفة الأساسية حول معالجة تسجيلات الاجتماعات المقدمة عبر الصفحة الرئيسية لتطبيق الويب. بمجرد إرسال التسجيل ، يتم بدء مهمة خلفية باستخدام Celery ، والتي تؤدي عمليتين أساسيتين: تحويل الكلام إلى النص وتوليد دقائق من الاجتماع من النص المحول.
يحدد المخطط الانسيابي الذي قمت بمشاركته عملية مفصلة للتعامل مع ملفات الوسائط ومعالجتها ، مع التركيز بشكل خاص على مدخلات الصوت والفيديو لإنشاء نسخ وملخصات. دعنا نقوم بتفكيك كل خطوة ونصف الحلول عالية المستوى المشاركة في سير العمل هذا:
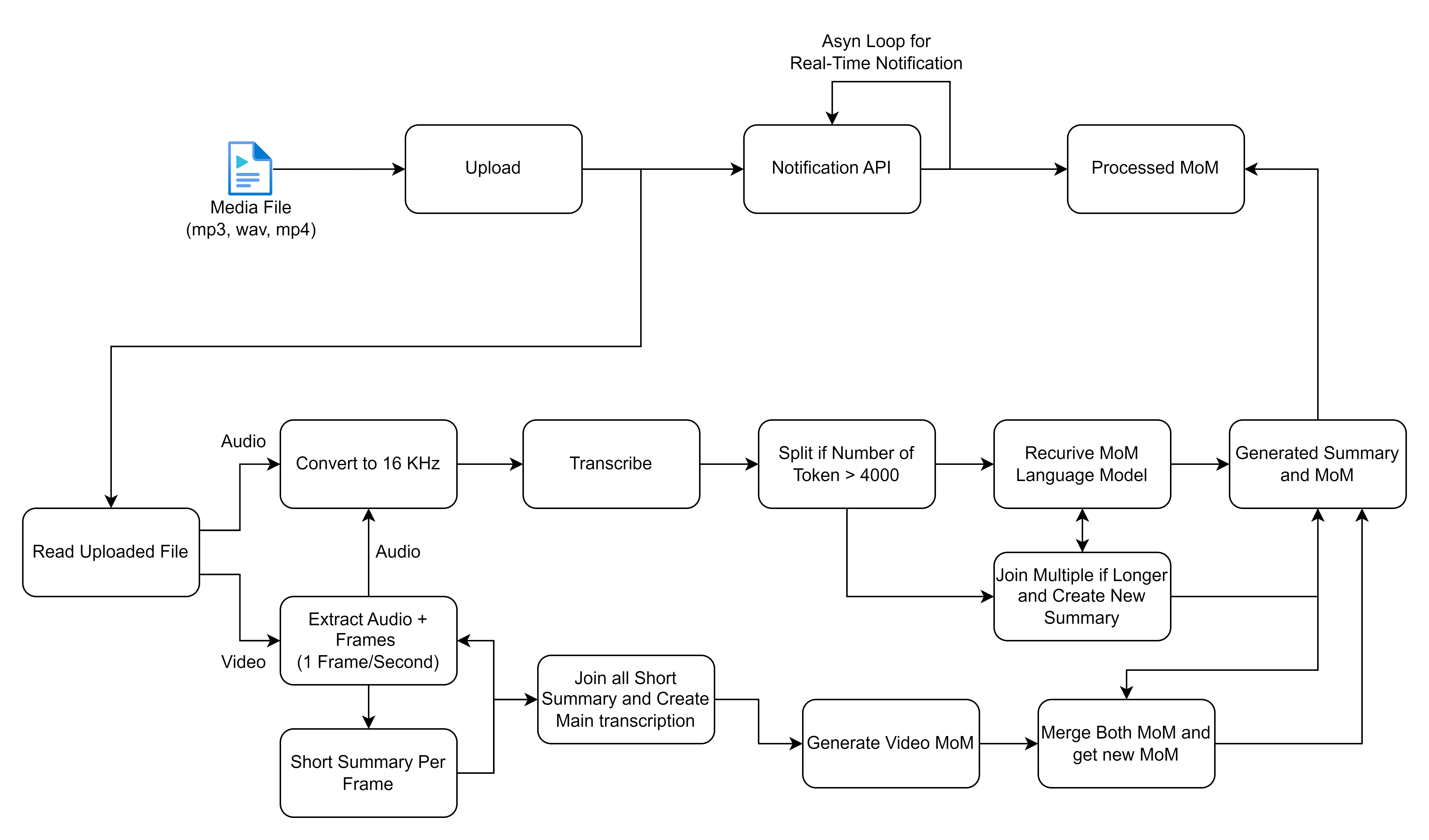

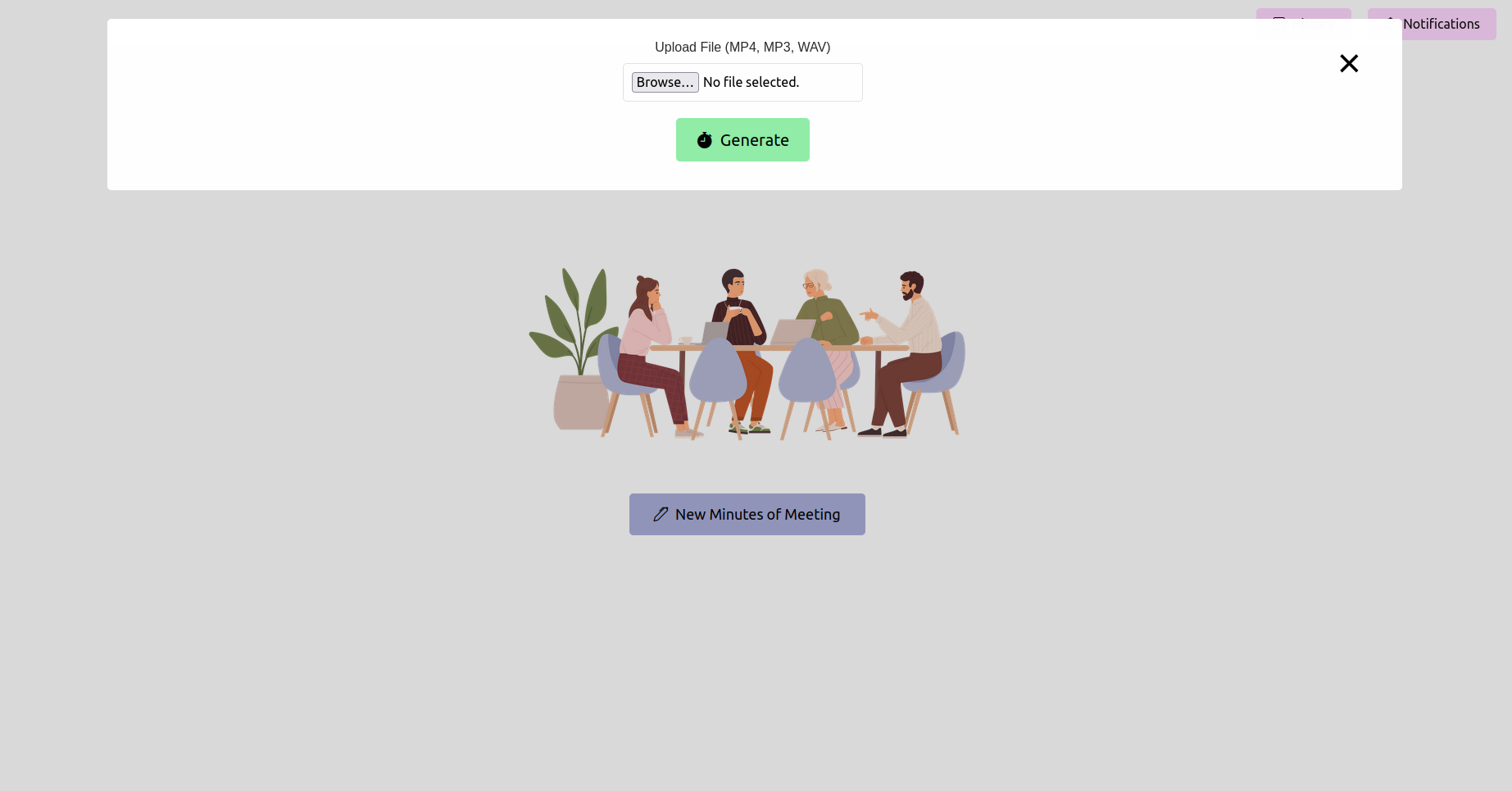
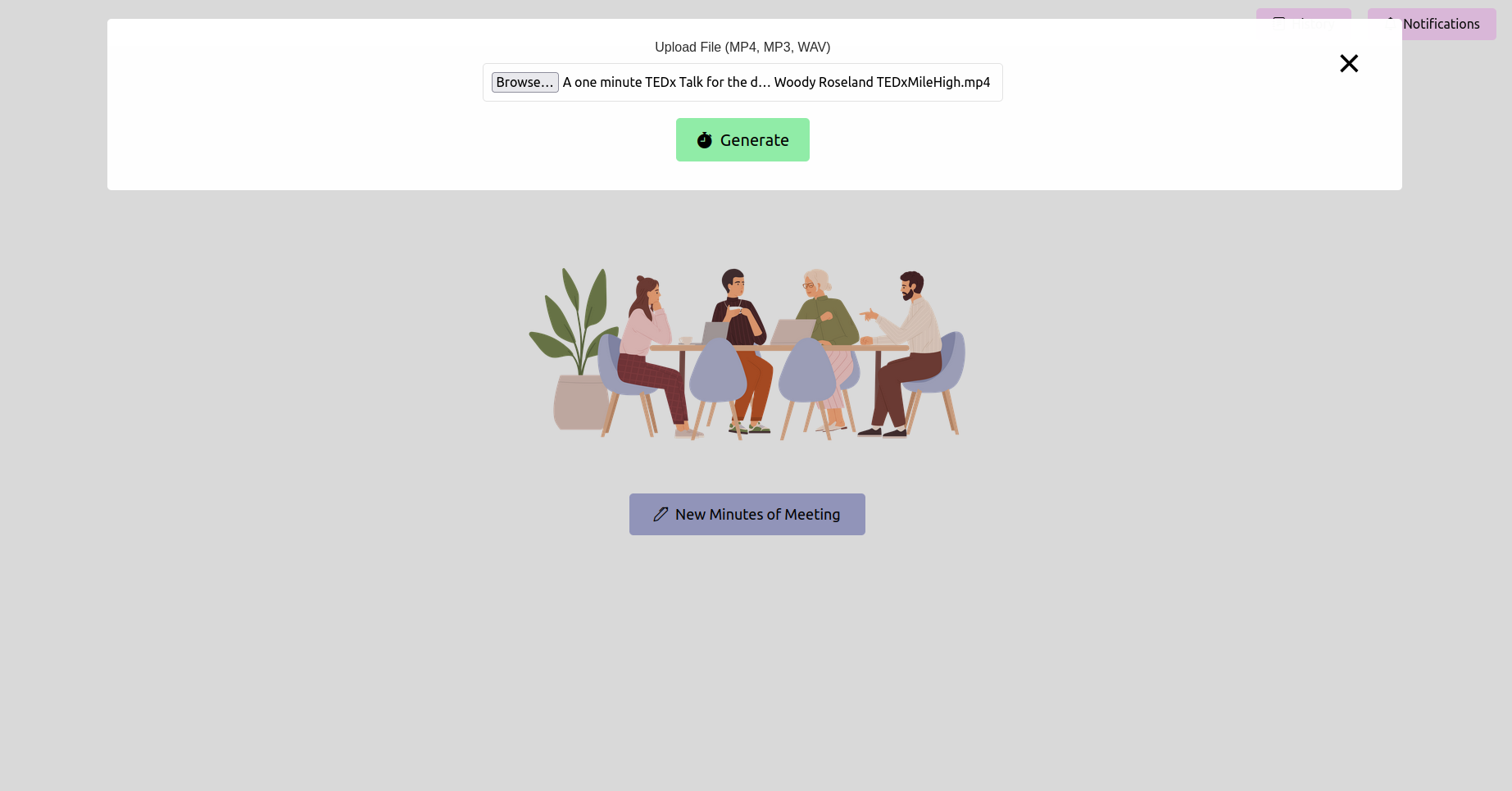
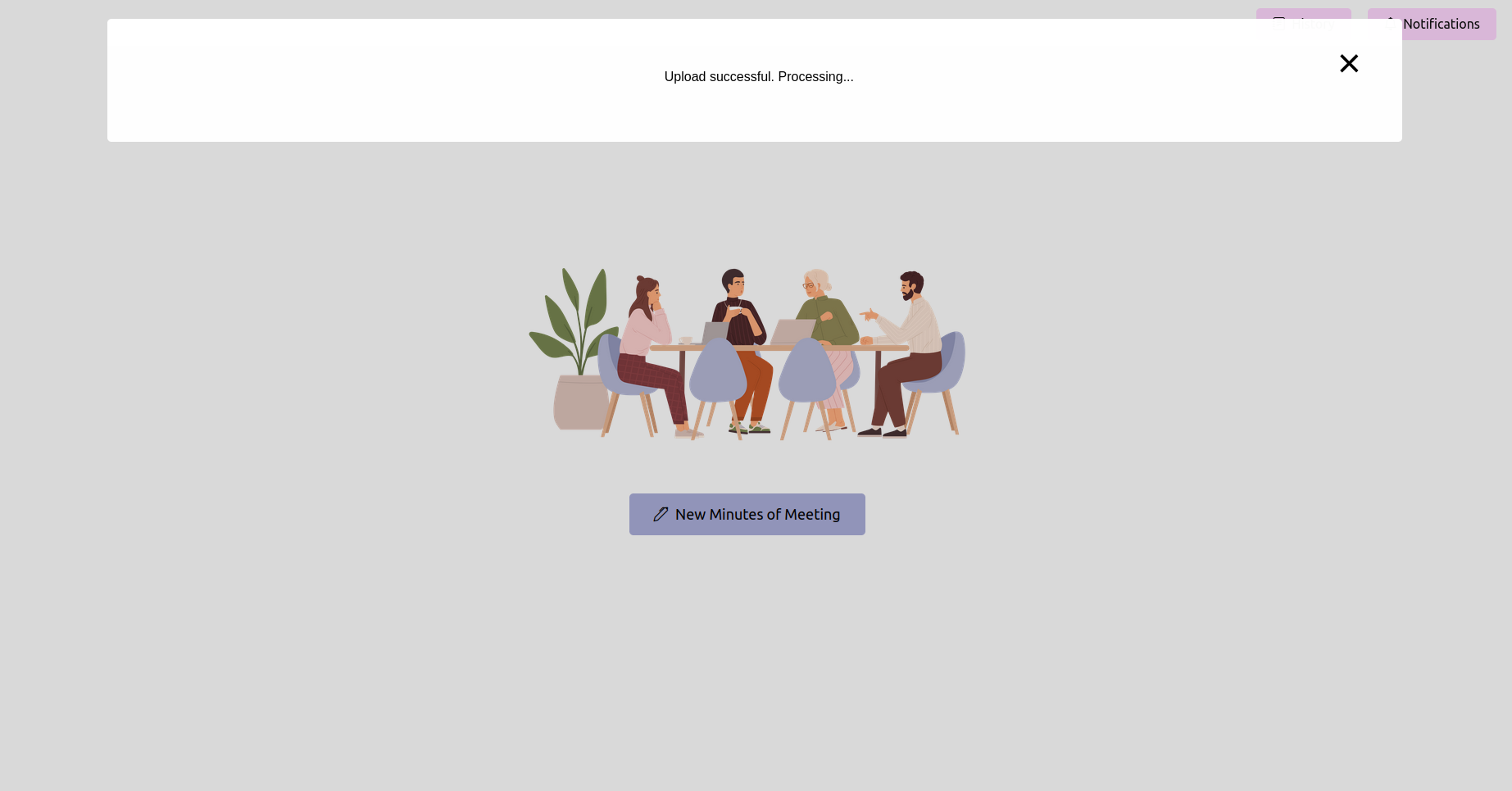



قبل المتابعة ، تأكد من تثبيت ما يلي:
virtualenv أو venv .requirements.txt متوافقة. في المرحلة الثانية من مشروعنا ، نخطط لتمكين النسخ في الوقت الفعلي. انضم إلينا في تشكيل مستقبل الاجتماعات الفعالة والتعاونية!
؟ اتبعني للحصول على تحديثات حول تطوير المرحلة الثانية والتحسينات الأخرى لجعل اجتماعاتك أكثر إنتاجية.
تشجيع المساهمات من المجتمع لجعل هذه الأداة تغيير اللعبة للاجتماعات في كل مكان. المساهمة بأفكارك وخبراتك لمساعدتنا على تحقيق النسخ في الوقت الفعلي!


