LLM Minutes of Meeting
1.0.0
| シニアいいえ | トピック | リンク |
|---|---|---|
| 0。 | プロジェクトの紹介と「なぜ」 | リンクはここに来ます |
| 1。 | セットアップとインストール | リンクはここに来ます |
| 2。 | 特徴 | 別のリンク |
| 3。 | デモとアプリケーションのスクリーンショット | 別のリンク |
| 4。 | アプローチと実装* | 別のリンク |
| 5。 | 最近の更新と将来の方向 | 別のリンク |
| 6。 | 貢献 | 別のリンク |
| 7。 | 問題/トラブルシューティング | 別のリンク |

このプロジェクトの主な目的は、NLP&LLMの能力を紹介し、長い会議を迅速に要約し、あなたとあなたの組織が会議の議事録(MOM)メールを委任するタスクを自動化するのを支援することです。ステップ1がオーディオ/ビデオファイルのテキスト会話への変換に対応するハイレベル2ステップアプローチを使用します。ステップ2ステップ1で作成されたテキストを使用し、会議の議事録と詳細な要約ノートを生成します。これらの会議の議事録は、編集可能なテキストになります。お母さんを完成させたら、要件に従ってさらに使用できます。
このリポジトリの長期的な目的は、リアルタイムのPython Webアプリケーションを開発し、会議に出席し、会議の最後にお母さんを提供できることです。赤ちゃんの一歩を踏み出し、短期的な目標を開始することで長期的に到達しようとします。
あなたの情報については、私は微調整カスタムLLMと開発に取り組んでいます。プロジェクト全体が完全に安定している間、我慢してください。完了したら、トレーニングと推論コードを追加します。最新の更新を知る必要がある場合は、このリポジトリを実行してください。 ?あなたの時間に感謝します。
先に進む前に、次のインストールを確認してください。
virtualenvやvenvなどの仮想環境ツール。今すぐインストール手順を始めましょう。
GitHubリポジトリをクローンします
ターミナルまたはコマンドプロンプトを開き、リポジトリをクローンするディレクトリに移動します。その後、実行:
git clone https://github.com/inboxpraveen/LLM-Minutes-of-Meeting
cd LLM-Minutes-of-Meeting要件をインストールします
他のPythonプロジェクトとの潜在的な競合を回避するために、依存関係をインストールする前に仮想環境を作成することをお勧めします。 virtualenvを使用している場合は、次のように新しい環境を設定できます。
# # Create a python virtual environment and activate it.
# Install the required packages after activating:
pip install -r requirements.txt
# # After this, let's install Llama-Cpp-Python binding which will be used to interact with LLMs.
# # Run the following line if you are using it on a CPU.
pip install llama-cpp-python
# # Run the following line if you are using GPU (T4, A100, A10, or H100), or any Nvidia Cuda based GPU Drivers.
CMAKE_ARGS= " -DLLAMA_CUDA=on " pip install llama-cpp-python
# # If you are on Mac or any other GPU types, you can refer the following links and setup the Llama-Cpp-Python
https://llama-cpp-python.readthedocs.io/en/stable/ # installation-configuration
https://llama-cpp-python.readthedocs.io/en/stable/install/macos/rabbitmqとセロリの背景ジョブ処理のセットアップ
次のリンクを使用して、マシンにRabbitMQをセットアップします。ステップ5までの指示に従って、 admin-usernameとpasswordを保存します。
ubuntu 22.04にrabbitmqをセットアップします
RabbitMQを正常にセットアップしたら、Redis-ServerとCelryをセットアップします。次のコマンドを使用して、それらをセットアップしてインストールします。
sudo apt-get update -y
# # Try with apt-get. If it does not install, then run with apt.
sudo apt-get install redis-server -y
# # If the above does not work, try this:
sudo apt install redis-server -yアプリケーションとパラレル実行セロリタスクを実行します
まず、フラスコのアプリケーションを開始します。
cd /path/to/project/次に、app.pyファイルを開きます。エディターをコードし、次の行を変更します。
Line 18 : broker = 'amqp://<user>:<password>$@localhost:5672//'
## Update <user> with "your-admin-username".
## Update <password> with "your-admin-password"
## Eg: broker='amqp://admin:hello_world$@localhost:5672//'
### IMPORTANT NOTE: If your password contains '@' symbol, you will need to convert it because it is the default delimiter in broker settings. Example if your password has @ symbol inside it would be.
## broker='amqp://admin:hello%40world$@localhost:5672//' -- where the original password was "hello@world", we represent it as 'hello%40world'ファイルを更新した後、 setup.pyファイルを[ディレクトリ]をセットアップしてモデルのダウンロードに実行します。使用するモデルの構成を変更する場合は、インフラストラクチャのサイズとシステム容量に基づいて適切に変更できます。次の表は、現在このプロジェクトでサポートしているモデルを示していますが、それらが適合し、オープンソースが見られるように、新しいLLMSサポートを追加します。
サポートされている音声モデル
| モデル名 | モデルサイズ | 必要なメモリ(RAMまたはVRAM) |
|---|---|---|
| 蒸留/蒸留-v3 | 3.1 GB | 4ギガバイト |
| 蒸留/蒸留-large-v2 | 3.1 GB | 4ギガバイト |
| 蒸留 - 蒸留/med.en | 1.6 GB | 2 GB |
| distil-whisper/distil-small.en | 680 MB | 900 MB |
| Openai/Whisper-Large-V3 | 6.2 GB | 7.5 GB |
| Openai/Whisper-Large-V2 | 6.2 GB | 7.5 GB |
| Openai/Whisper-Large-V1 | 6.2 GB | 7.5 GB |
| Openai/Whisper-Medium | 3.2 GB | 4.5 GB |
| Openai/Whisper-Small(デフォルト) | 980 MB | 1.7 GB |
LLMSサポート
| モデル名 | モデルサイズ | メモリが必要です |
|---|---|---|
| QuantFactory/PHI-3-MINI-4K-INSTRUCT-GGUF(デフォルト) | 1 GB -8 GB | 2 GB -14 GB |
| QuantFactory/PHI-3-MINI-128K-INSTRUCT-GGUF | 1 GB -8 GB | 2.5 GB -16 GB |
| bartowski/phi-3-med-128k-instruct-gguf | 3 GB -14 GB | 6 GB -18 GB |
選択したモデル名を使用してglobal_varibables.pyファイルを変更し、選択したモデルを自動的にダウンするsetup.pyファイルを実行する必要があります。
Line 32 : DEFAULT_SPEECH_MODEL = "openai/whisper-small"
...
Line 46 : DEFAULT_SUMMARY_MODEL = ( "QuantFactory/Phi-3-mini-4k-instruct-GGUF" , "Phi-3-mini-4k-instruct.Q5_0.gguf" )
### After update the above lines as per your need, run the setup.py
python setup . py新しいターミナルウィンドウ(ここでも仮想環境がアクティブ化されていることを確認)で、アプリとセロリワーカーを開始します。
python app.py # ensure your environment is activated
# and then in new terminal, run the following.
celery -A app.celery worker --loglevel=info -f celery.logs録音をアップロードして形成します
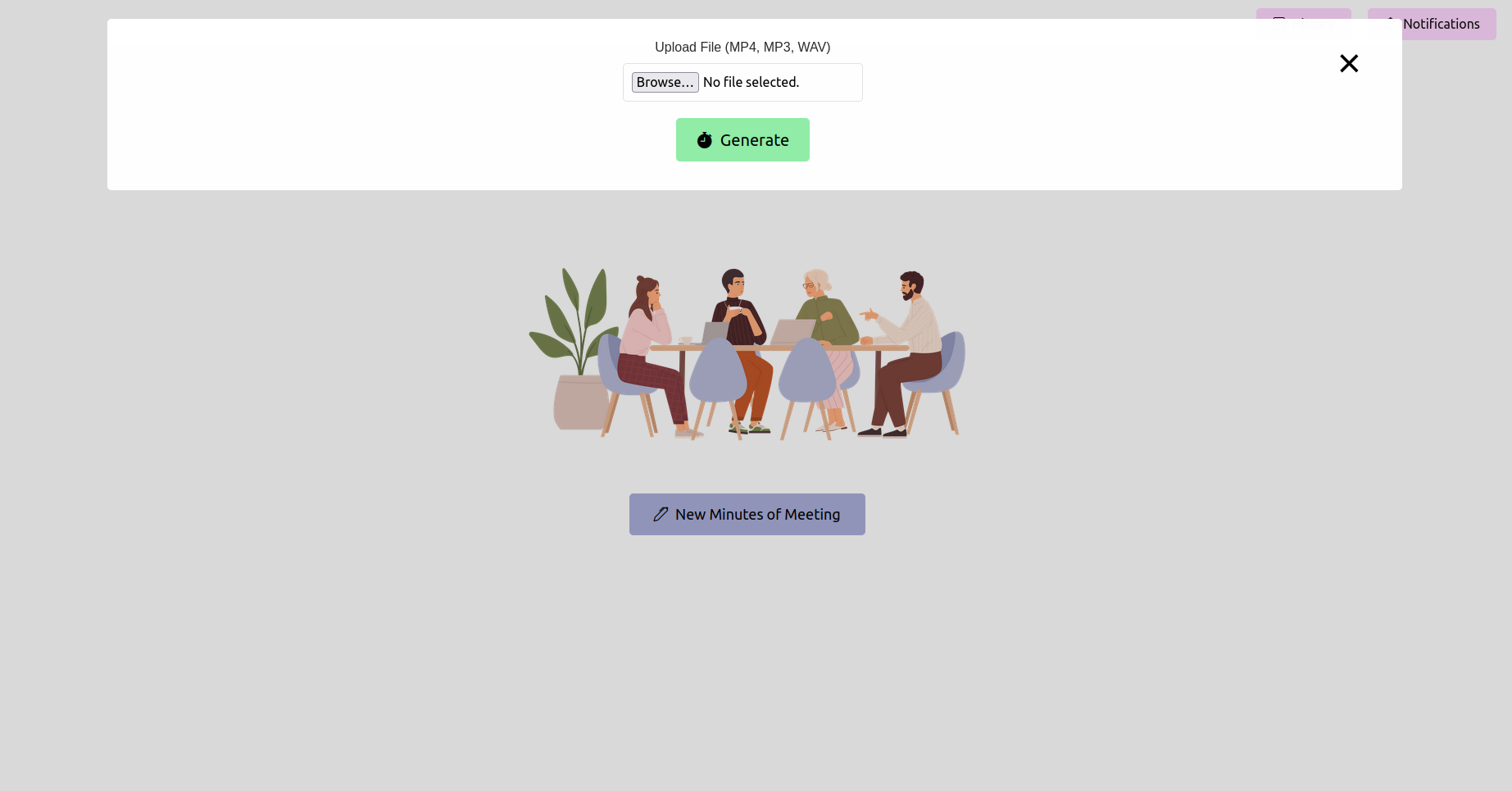
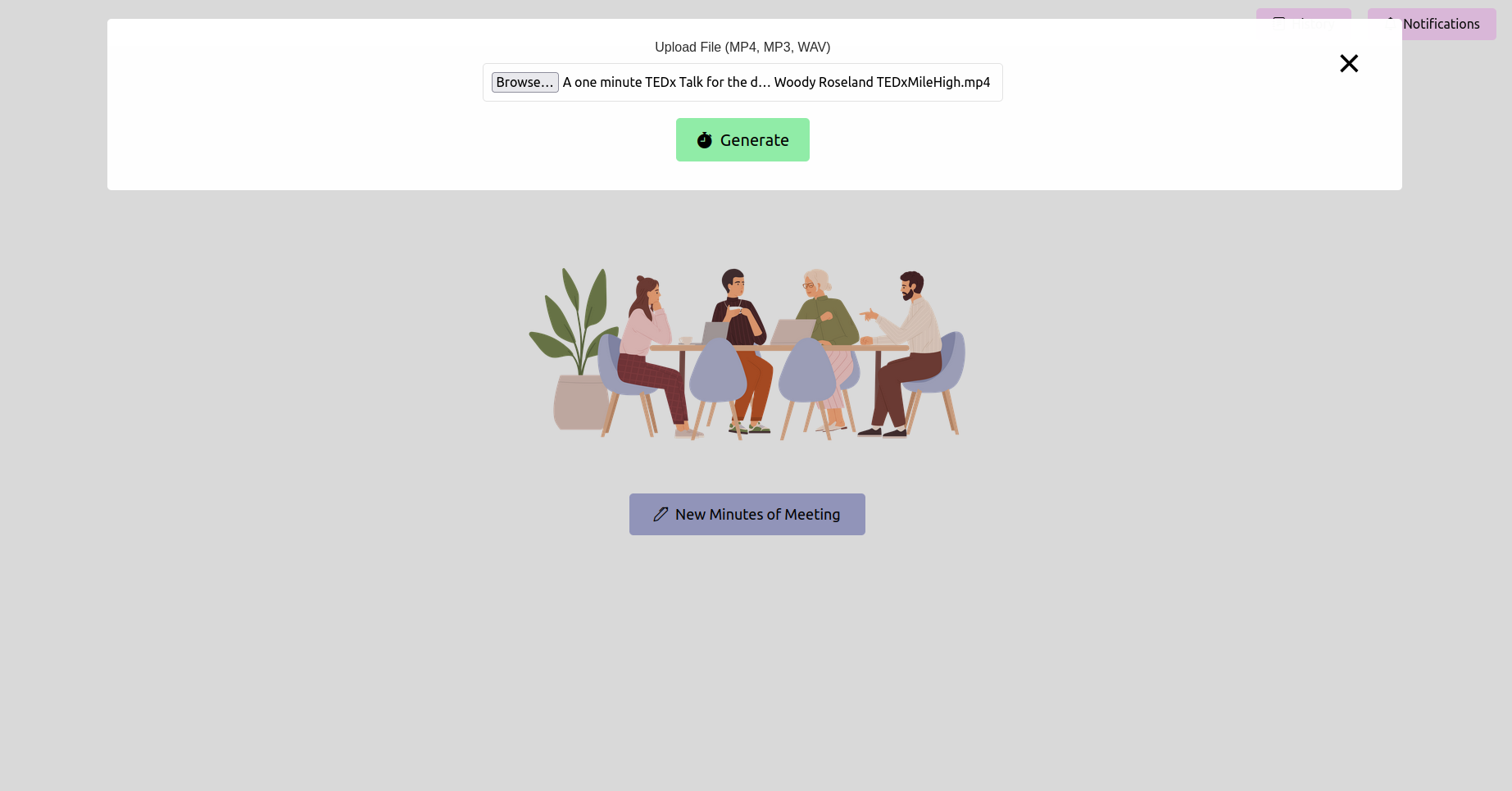
Webブラウザを開き、FlaskアプリケーションのURL(通常http://127.0.0.1:5000 )に移動します。インターフェイスを使用して、会議の録音をアップロードします。
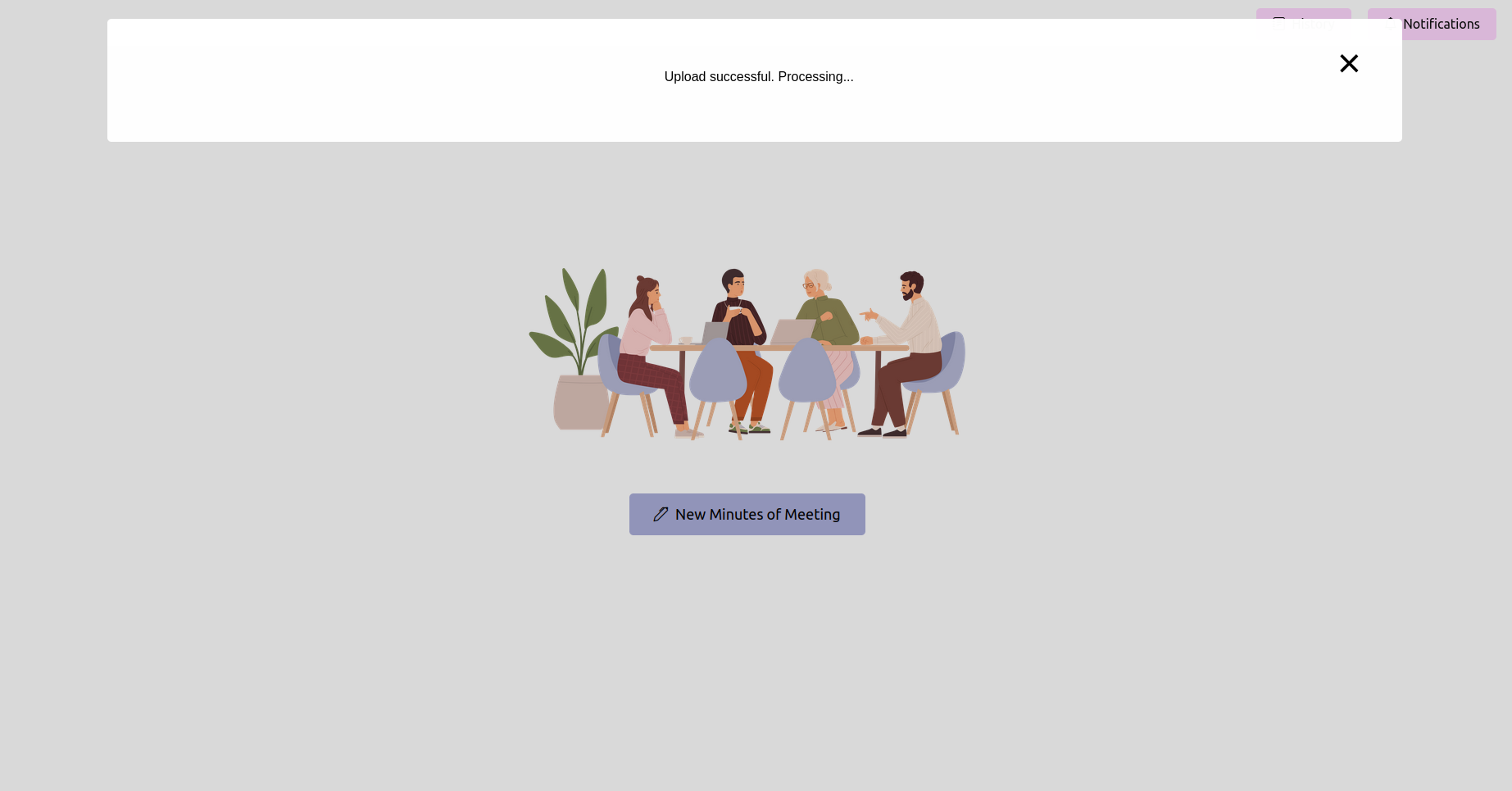
最新のステータスを取得し、完了するのを待ちます
録音をアップロードした後、処理のステータスを確認できます。これは、アプリケーションのステータスページまたは進行状況バーとして実装できます。処理が完了するまで待ちます。
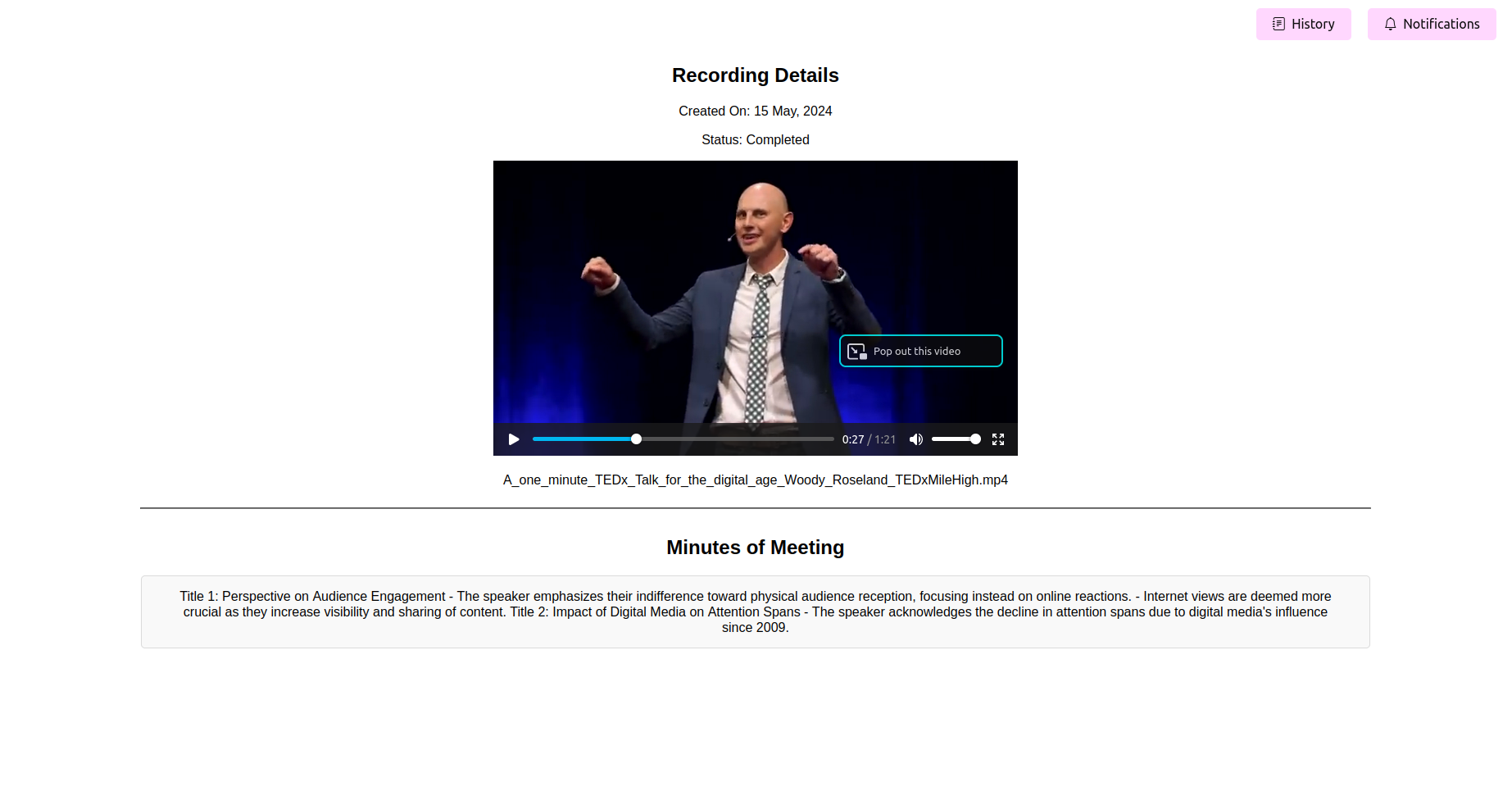
会議の最終処理分を参照してください(ママ)
処理が完了したら、アプリケーションは会議の最後の議事録を表示する必要があります。表示、編集(機能が利用可能な場合)、および参照のためにママを保存することができます。
オーディオおよびビデオファイルを正確なテキストトランスクリプトに簡単に変換します。これらを使用して、アクションアイテムを要約、生成、ワークフローの理解、リソース計画を使用することもできます。
迅速な参照のためのキーワードのハイライトとトピックタグ:トピックを抽出し、会議をスキップし、あなたの興味のある特定のトピックのみを聴くための関連するコンテンツを見つける。
PDFやプレーンテキストを含むさまざまな形式でのエクスポート:トランスクリプト、概要、トピックとキーワード、アクションアイテムなどをプロジェクト計画と管理フレームワークで利用できるドキュメントにエクスポートできます。また、テンプレートを手動で書き込んで生成する必要性を排除します。
簡単にカスタマイズと統合のためのユーザーフレンドリーなインターフェイス:選択したいオープンソースまたはクローズドソースモデルを簡単に調整できます。
コア機能は、Webアプリケーションのホームページを介して送信された会議の記録の処理を中心に展開します。録音が提出されると、セロリを使用してバックグラウンドタスクが開始され、2つの主要な操作が実行されます。音声からテキストへの変換と、変換されたテキストから会議の議事録を生成します。
共有したフローチャートは、メディアファイルを処理および処理するための詳細なプロセスの概要を示しています。特に、音声入力とビデオ入力に焦点を当てて、転写と要約を生成します。各ステップを分解し、このワークフローに関連する高レベルのソリューションについて説明しましょう。
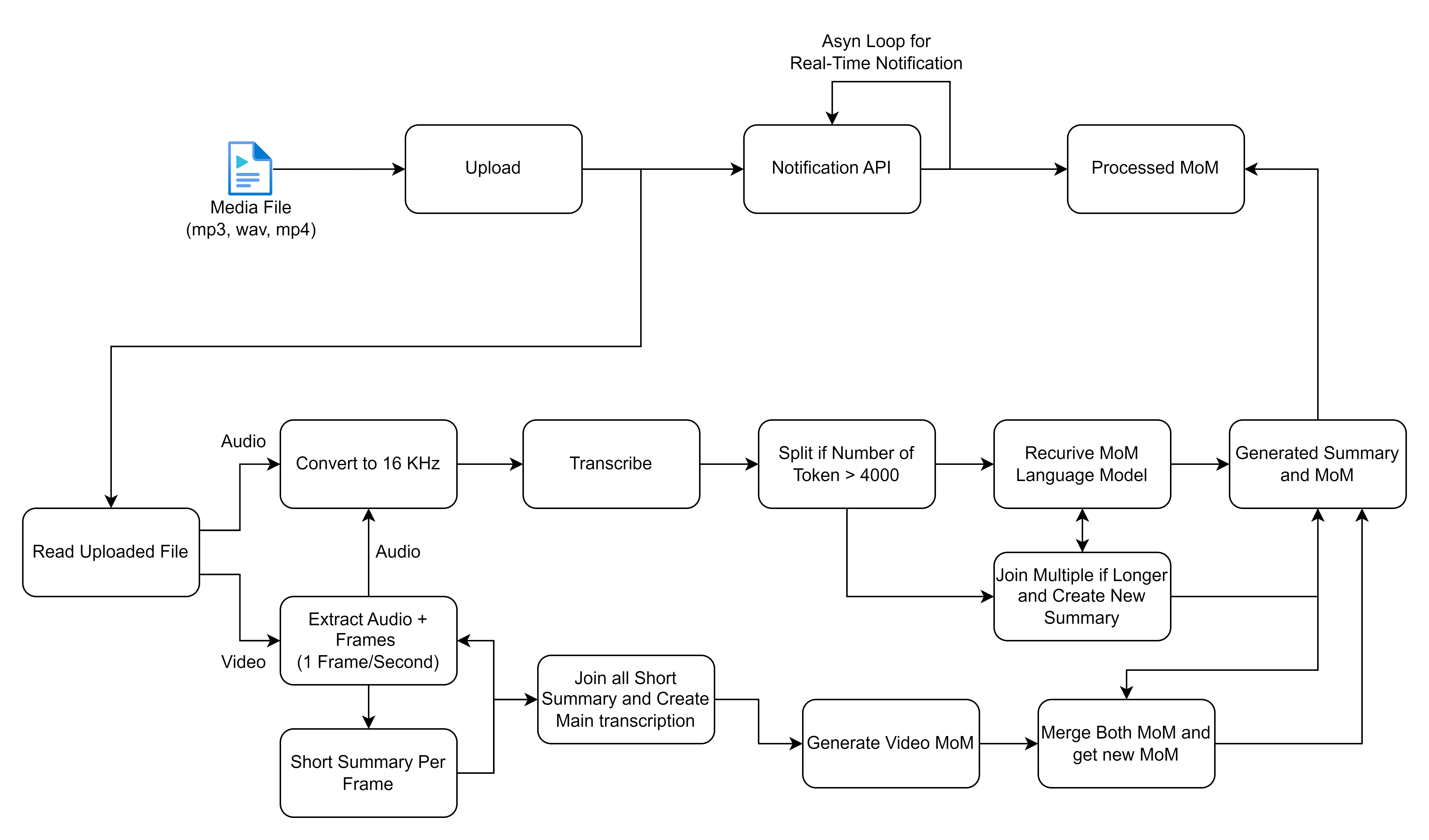




先に進む前に、次のインストールを確認してください。
virtualenvやvenvなどの仮想環境ツール。requirements.txtのパッケージが互換性があることを確認してください。 プロジェクトのフェーズ2では、リアルタイムの会議転写を有効にすることを計画しています。効率的で協力的な会議の未来を形作ることにご参加ください!
?フェーズ2の開発とその他の強化に関する最新情報については、会議をさらに生産的にしてください。
?は、コミュニティからの貢献を奨励して、このツールをどこでも会議のためのゲームチェンジャーにします。リアルタイムの転写を達成するのに役立つアイデアと専門知識を提供してください!


