很棒的深色R1资源
- [?链接] - DeepSeek-ai/deepseek-r1:技术报告
生殖
- [?链接] - huggingface/open-r1:DeepSeek-R1的完全开放繁殖
- [?链接] - jiayi-pan/tinyzero
- [?链接] - hkust-nlp/simplerl-resason:这是对小型模型的DeepSeek-R1-Zero和DeepSeek-R1培训的复制品,数据有限
相关资源
- R1+十四行诗以低成本的成本粉碎基准: DeepSeek R1与十四行诗配对的Aider Polyglot基准测试的基准为64% ,表现优于O1 ,而成本降低了14倍。用户强调了其在顶级大学的MIT许可证和收养。
- R1重新延伸提升QWEN-1.5B :Mobius Labs的Redistill Ed R1变体超过原始,并计划扩展到其他架构。
- R1的竞技场排名SPARD GPU分配理论:R1在LMARENA中排名第3 ,与O1的编码性能相匹配,价格便宜20倍,这是由于备用NVIDIA H100使用和中国政府支持的谣言所推动。
- [?链接] - Atfortes/Awesome-llm - 理论:LLMS中的推理:论文和资源,包括思考链,OpenAi O1和DeepSeek-R1?
- [?链接] - 内森·兰伯特(Nathan Lambert):DeepSeek R1复制O1的食谱和推理LMS的未来
发现
发射
当我们说“ R1”时,这是模棱两可的。 DeepSeek实际上丢弃了8种R1型号-2个“完整”型号,并在开放型号上进行了6种蒸馏:
- 从QWEN 2.5:用DeepSeek-R1策划的800K样品进行填充,以1.5b,7b,14b和32b
- 来自Llama 3.1 8b基础:DeepSeek-R1-Distill-Lalama-8B
- 来自Llama3.3-70B-Instruct:DeepSeek-R1-Distill-Lalama-70b
- 以及DeepSeek-R1和DeepSeek-R1-Zero,类似于DeepSeek V3的全尺寸的671B MOE型号。令人惊讶的是,麻省理工学院已获得许可而不是自定义许可,包括明确的鉴定和蒸馏
发射中的其他知名人士:
- 定价(每百万个令牌):14美分输入(缓存命中率),55美分输入(缓存失误)和219美分的输出。相比之下,在750美分的输入(缓存命中),1500美分输入(缓存失误),6000美分的输出相比。比O1便宜27倍。
- 解决O1 Blogpost中的每个问题。每个人。
- 可以在Ollama上运行蒸馏型
- 可以很好地编写Manim代码
纸上的惊喜:
该过程是:
- V3基础→R1零(使用GRPO-又称正确性和样式结果的奖励 - 无花哨的PRM/MCT/RMS)
- R1零→R1燃烧冷启动(从R1零的Distil长床样品)
- R1冷启动→带有RL的R1推理器(专注于语言一致性 - 产生可读的推理)
- R1推理→R1 Finetuned-Reasoner(生成600K:多响应采样,仅保留正确的样本(使用Prev规则),然后使用V3作为法官:过滤掉混合语言,长段落和代码)
- R1指导者→R1对准(使用GRPO的有益和无害的平衡推理)
可视化:

监督数据,流程奖励模型和MCT进行了 - 不工作

- 但是,他们确实使用了DeepSeekmath(由DPO作者挑战)的GRPO作为“ RL框架,以提高推理中的模型性能”,“在“成千上万的RL步骤”之后,推理(例如在上下文中的背面跟踪)“自然而然地出现” - 不是很有名的O1缩放图,而是一个紧密的表情。

- 使用“ aha moments”作为枢轴令牌,通常以读者不友好的方式混合语言
- R1在O1公告后不到一个月就开始培训
- R1蒸馏非常有效,这给了我们这一疯狂的报价:“ DeepSeek-R1-Distill-Qwen- 1.5b的表现优于GPT-4O和Claude-3.5-sonnet在数学基准上,AIME的28.9%,而数学上的83.9%,这甚至不推动蒸馏蒸馏到其限制上。
- 这不仅是对一个小型模型的RL调整更有效:“与小型模型上通过RL发现的推理模式相比,较大模型的推理模式可以蒸馏成较小的模型。”又名“ SFT胜利”
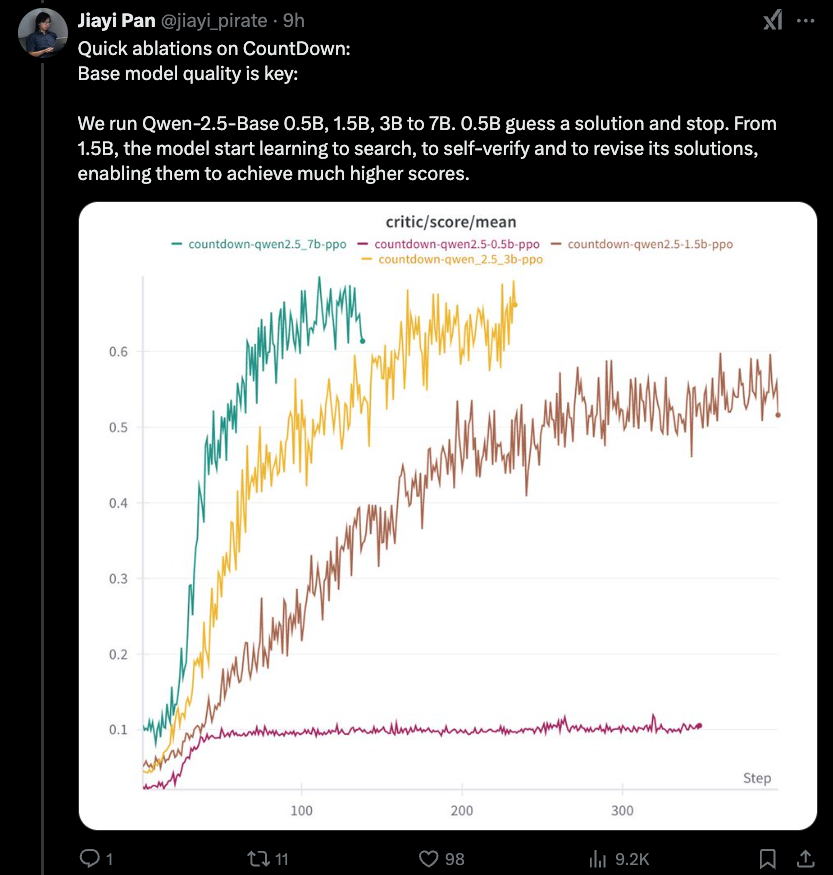
Jiayi-Pan(TinyZero):
最有趣的新发现是,我们昨天涵盖的蒸馏效果的下限-1.5B与您一样低。 rlcot推理本身就是新兴的财产。
RL技术(PPO,DeepSeek的grpo或Prime)并不重要
从指示模型开始收敛的速度更快,但两者都结束相同(根据R1纸观测)