Awesome-Deepseek-R1-Ressourcen
- [? Link]-Deepseek-AI/Deepseek-R1: Tech-Bericht
Reproduktion
- [? Link]-Huggingface/Open-R1: vollständig offene Reproduktion von Deepseek-R1
- [? Link]-Jiayi-Pan/Tinyzero
- [? Link]-HKUST-NLP/SimpleerL-Rate: Dies ist ein Replikat von Deepseek-R1-Zero und Deekseek-R1-Training für kleine Modelle mit begrenzten Daten
Verwandte Ressourcen
- R1+Sonnet zerbricht den Benchmark zu 14 -fachen niedrigeren Kosten : Deepseek R1 gepaart mit Sonnet erreichte 64% am Aider Polyglot -Benchmark und übertraf O1 und kostete den 14 -fachen weniger . Die Benutzer haben ihre MIT -Lizenz und -Anführung an Top -Universitäten hervorgehoben.
- R1 Redistillation steigert Qwen-1.5b : Die redistillierte R1-Variante von Mobius Labs übertraf das Original mit den Plänen, auf andere Architekturen zu expandieren.
- R1's Arena Rankings Spark GPU -Allokationstheorien : R1 traf #3 in Larena, die die Codierungsleistung von O1 bei 20X Billiger entspricht, die von Gerüchten über Nvidia H100 -Nutzung und Unterstützung der chinesischen Regierung angetrieben wird.
- [? Link]-Atfortes/Awesome-Llm-Erfindung: Argumentation in LLMs: Papiere und Ressourcen, einschließlich der Gedankenkette, Openai O1 und Deepseek-R1?
- [? Link] - Nathan Lambert: Deepseek R1s Rezept zur Replikation von O1 und die Zukunft des Argumentierens LMS
Ergebnisse
Start
Wenn wir "R1" sagen, ist es mehrdeutig. Deepseek hat tatsächlich 8 R1 -Modelle fallen - 2 "vollständige" Modelle und 6 Destillationen auf offenen Modellen:
- Von Qwen 2.5: Finetuned mit 800K-Proben mit Deepseek-R1, in 1,5b, 7b, 14b und 32b zusammengestellt
- Aus Lama 3.1 8b Basis: Deepseek-R1-Distill-Llama-8b
- Aus LLAMA3.3-70B-Instruct: Deepseek-R1-Distill-Llama-70b
- und Deepseek-R1 und Deepseek-R1-Null, The Full Size, 671B Moe-Modelle ähnlich wie Deekseek V3. Überraschenderweise lizenziert MIT eher lizenziert als benutzerdefinierte Lizenzen, einschließlich explizit OK für Finetuning und Destillation
Andere Auszeichnungen aus dem Start:
- Preisgestaltung (pro Million Token): 14 Cent -Eingang (Cache -Hit), 55 Cent -Eingang (Cache -Fehlschlag) und 219 Cent -Ausgabe. Dies ist im Vergleich zu O1 bei 750 Cent -Eingang (Cache -Hit), 1500 Cent -Eingang (Cache -Fehlschlag), 6000 Cent Ausgabe. Das sind 27x-50x billiger als O1.
- Löst jedes Problem aus dem O1 -Blogpost. alle.
- kann die destillierten Modelle auf Ollama ausführen
- kann Manim Code wirklich gut schreiben
Überraschungen von der Zeitung:

- Aber sie verwenden Grpo von Deepseekmath (herausgefordert vom DPO-Autor) als "RL-Framework zur Verbesserung der Modellleistung in der Argumentation", bei der die Argumentation (wie die Rücksperrung in Kontext) "natürlich nach" Tausenden von RL-Schritten "entstanden ist-nicht ganz die berühmte O1-Skalierung, aber eine enge Cousine.

- Verwenden Sie "Aha Momente" als Pivot -Token, die oft unfreundliche Sprachen mischen
- R1 begann weniger als einen Monat nach der O1 -Ankündigung mit dem Training
- R1-Destillationen waren bemerkenswert effektiv und gab uns dieses verrückte Zitat: "Deepseek-r1-Distill-Qwen- 1,5B übertrifft GPT-4O und Claude-3,5-SONNET auf Mathematik-Benchmarks mit 28,9% und 83,9% in Mathe."
- Dies ist effektiver als nur RL-Tuning ein kleines Modell: "Argumentationsmuster größerer Modelle können in kleinere Modelle destilliert werden, was zu einer besseren Leistung im Vergleich zu den Argumentationsmustern führt, die durch RL auf kleinen Modellen entdeckt werden." AKA "Total SFT Victory"
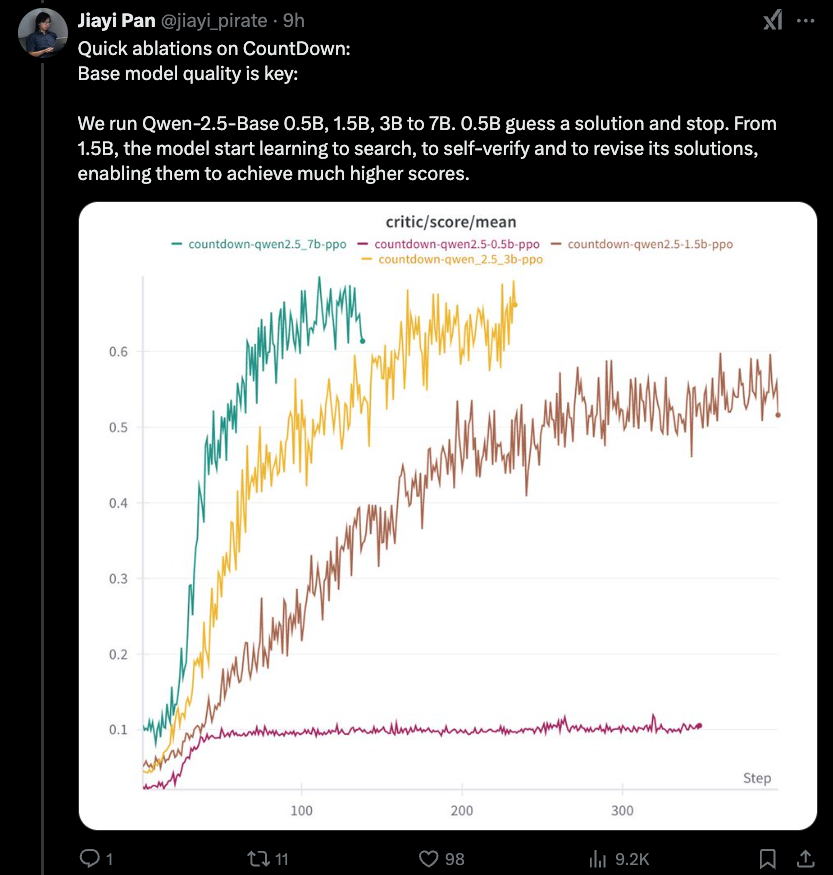
Jiayi-Pan (Tinyzero):
Das interessanteste neue Erkenntnis ist, dass es eine untere Grenze für den Destillationseffekt gibt, den wir gestern abgedeckt haben - 1,5B ist so niedrig wie Sie. RLCOT -Argumentation ist selbst eine aufstrebende Eigenschaft.
RL -Technik (PPO, Deepseeks Grpo oder Prime) ist nicht wirklich wichtig
Ausgehend von dem Anweisungsmodell konvergiert schneller, aber ansonsten beenden beide gleich (gemäß der R1 -Papierbeobachtung)