Impresionante-depende-r1-recursos
- [? Enlace]-Deepseek-ai/Deepseek-R1: Informe tecnológico
Reproducción
- [? Enlace]-Huggingface/Open-R1: reproducción completamente abierta de Deepseek-R1
- [? enlace]-jiayi-pan/tinyzero
- [? Enlace]-HKUST-NLP/SimpleRerl-REAUN
Recursos relacionados
- R1+sonó el soneto de referencia de referencia a 14 veces al costo más bajo : Deepseek R1 emparejado con soneto alcanzado 64% en el punto de referencia de Polyglot de auxilio, superando a O1 al tiempo que costó 14 veces menos . Los usuarios destacaron su licencia y adopción del MIT en las mejores universidades.
- La redistilación de R1 aumenta Qwen-1.5b : la variante R1 R1 de Mobius Labs superó el original, con planes de expandirse a otras arquitecturas.
- Las clasificaciones de la arena de R1 Sparen Teorías de asignación de GPU : R1 Hit #3 en Lmarena, que coincide con el rendimiento de codificación de O1 con 20 veces más barato , impulsado por rumores de uso de NVIDIA H100 de repuesto y respaldo del gobierno chino.
- [? Enlace]-Atfortes/Awesome-LLM-Razing: Razoning in LLMS: ¿Documentos y recursos, incluidos la cadena de pensamiento, OpenAi O1 y Deepseek-R1?
- [? Enlace] - Nathan Lambert: la receta de Deepseek R1 para replicar O1 y el futuro del razonamiento LMS
Recomendaciones
Lanzamiento
Cuando decimos "R1", es ambiguo. Deepseek en realidad cayó 8 modelos R1 - 2 modelos "completos" y 6 destilaciones en modelos abiertos:
- de Qwen 2.5: Fineten con 800k muestras curadas con Deepseek-R1, en 1.5b, 7b, 14b y 32b
- De la Llama 3.1 Base 8B: Deepseek-R1-Distill-Llama-8B
- de Llama3.3-70b-Instructo: Deepseek-R1-Distill-Llama-70b
- y Deepseek-R1 y Deepseek-R1-Zero, los modelos MOE 671B de tamaño completo similares a Deepseek V3. Sorprendentemente, el MIT licenciado en lugar de licencias personalizadas, incluida la OK explícita para la fineta y la destilación
Otros notables del lanzamiento:
- Precios (por millón de tokens): entrada de 14 centavos (HIT de caché), entrada de 55 centavos (Miss de caché) y salida de 219 centavos. Esto se compara con la entrada de O1 a 750 centavos (HIT de caché), entrada de 1500 centavos (Cache Miss), salida de 6000 centavos. Eso es 27x-50x más barato que O1.
- resuelve todos los problemas del O1 BlogPost. todos.
- puede ejecutar los modelos destilados en Ollama
- puede escribir el código Manim muy bien
Sorpresas del papel:

- Pero sí usan GRPO de Deepseekmath (desafiado por el autor de DPO) como "el marco RL para mejorar el rendimiento del modelo en el razonamiento" donde el razonamiento (como el seguimiento posterior de contexto) "surgió naturalmente" después de "miles de pasos RL", no el famoso trama de escalada O1, sino un cuusado cercano.

- Usando "Momentos de AHA" como tokens pivote, a menudo mezclando idiomas de una manera hostil del lector
- R1 comenzó a entrenar menos de un mes después del anuncio de O1
- Las destilaciones R1 fueron notablemente efectivas, lo que nos dio esta cita loca: "Deepseek-r1-Distill-Qwen- 1.5b supera a GPT-4O y Claude-3.5-Sonnet en matemáticas con 28.9% en AIME y 83.9% en matemáticas", y esto es sin incluso llevar la destilación a sus límites.
- Esto es más efectivo que solo el ajuste de RL un modelo pequeño: "Los patrones de razonamiento de modelos más grandes se pueden destilarse en modelos más pequeños, lo que resulta en un mejor rendimiento en comparación con los patrones de razonamiento descubiertos a través de RL en modelos pequeños". también conocido como "victoria total de SFT"
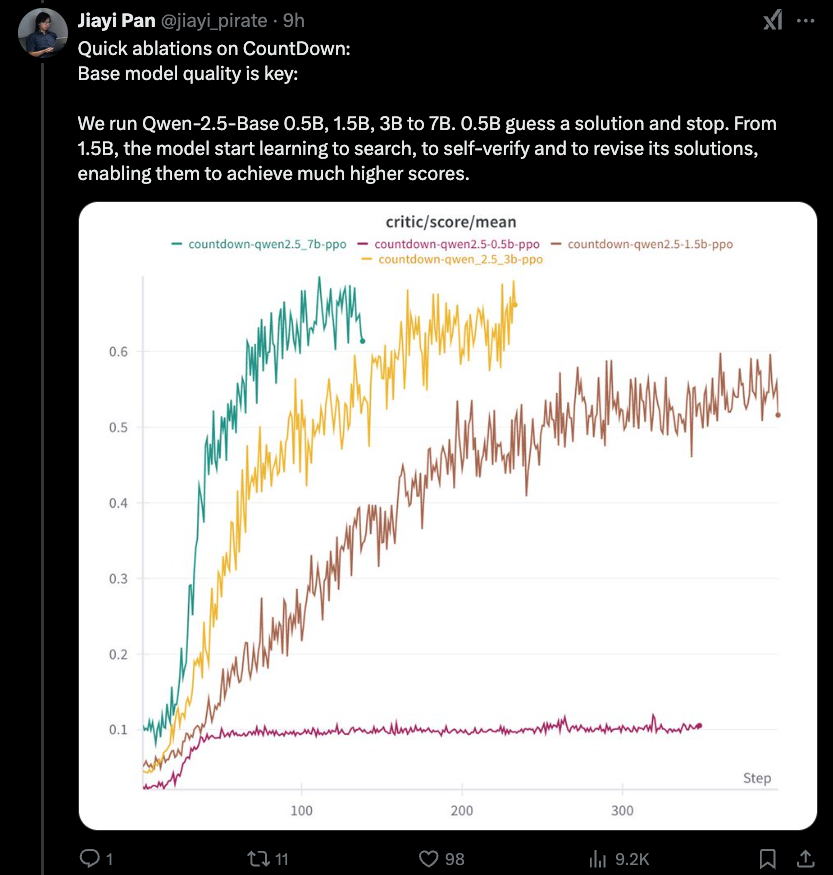
Jiayi-pan (Tinyzero):
El nuevo hallazgo más interesante es que hay un límite inferior al efecto de destilación que cubrimos ayer: 1.5B es tan bajo como usted. El razonamiento RLCOT es en sí mismo una propiedad emergente.
La técnica RL (PPO, GRPO de Deepseek o Prime) realmente no importa
A partir del modelo de instrucción, converge más rápido, pero de lo contrario, ambos terminan lo mismo (según la observación del papel R1)