แหล่งข้อมูลที่ยอดเยี่ยมมาก-R1
- - ลิงค์]-DeepSeek-AI/DEEPSEEK-R1: รายงานเทคโนโลยี
การสืบพันธุ์
- - ลิงค์]-HuggingFace/Open-R1: การทำซ้ำแบบเปิดอย่างเต็มที่ของ Deepseek-R1
- - ลิงค์]-Jiayi-Pan/Tinyzero
- - ลิงค์]-HKUST-NLP/Simplerl-Reason: นี่คือการทำซ้ำของการฝึกอบรม Deepseek-R1-Zero และ Deepseek-R1 ในรุ่นเล็กที่มีข้อมูล จำกัด
ทรัพยากรที่เกี่ยวข้อง
- R1+Sonnet Shatters มาตรฐานที่ราคาต่ำกว่า 14x : Deepseek R1 จับคู่กับ Sonnet ประสบความสำเร็จ 64% ตามเกณฑ์มาตรฐาน Polyglot Aider ซึ่งสูงกว่า O1 ในขณะที่ราคา น้อยกว่า 14 เท่า ผู้ใช้เน้นใบอนุญาต MIT และการนำไปใช้ในมหาวิทยาลัยชั้นนำ
- R1 การปรับเปลี่ยนใหม่ช่วยเพิ่ม QWEN-1.5B : Redistill Ed R1 ของ Mobius Labs ของ Mobius Labs เหนือกว่าต้นฉบับโดยมีแผนที่จะขยายไปยังสถาปัตยกรรมอื่น ๆ
- การจัดอันดับสนามกีฬาของ R1 จุดประกายการจัดสรร GPU : R1 HIT #3 ใน Lmarena, การจับคู่การเข้ารหัสของ O1 ที่ 20X ราคาถูกกว่า โดยมีข่าวลือเกี่ยวกับการใช้ Nvidia H100 สำรองและการสนับสนุนจากรัฐบาลจีน
- - ลิงค์]-Atfortes/Awesome-llm-reining: การใช้เหตุผลใน LLMS: เอกสารและทรัพยากรรวมถึง Chain-of-Though, Openai O1 และ Deepseek-R1?
- - ลิงค์] - นาธานแลมเบิร์ต: สูตรของ Deepseek R1 เพื่อทำซ้ำ O1 และอนาคตของการให้เหตุผล LMS
ผลการวิจัย
ปล่อย
เมื่อเราพูดว่า "R1" มันคลุมเครือ Deepseek ลดลงจริง 8 รุ่น R1 - 2 รุ่น "เต็ม" และ 6 การกลั่นในรุ่นเปิด:
- จาก Qwen 2.5: finetuned ด้วยตัวอย่าง 800k ที่รวบรวมด้วย Deepseek-R1 ใน 1.5B, 7B, 14B และ 32B
- จาก LLAMA 3.1 8B BASE: DEEPSEEK-R1-DISTILL-LLAMA-8B
- จาก LLAMA3.3-70B-Instruct: DEEPSEEK-R1-DISTILL-LLAMA-70B
- และ Deepseek-R1 และ Deepseek-R1-Zero รุ่นเต็มขนาด 671B MOE คล้ายกับ Deepseek V3 น่าแปลกที่ MIT ได้รับใบอนุญาตมากกว่าใบอนุญาตที่กำหนดเองรวมถึง OK ที่ชัดเจนสำหรับ finetuning และการกลั่น
สิ่งที่น่าสนใจอื่น ๆ จากการเปิดตัว:
- การกำหนดราคา (ต่อล้านโทเค็น): อินพุต 14 เซ็นต์ (แคชตี) อินพุต 55 เซ็นต์ (แคชพลาด) และเอาต์พุต 219 เซนต์ สิ่งนี้เปรียบเทียบกับ O1 ที่อินพุต 750 เซ็นต์ (แคชตี), อินพุต 1,500 เซ็นต์ (Cache Miss), เอาต์พุต 6000 เซนต์ นั่นคือ 27x-50x ถูกกว่า O1
- แก้ปัญหาทุกอย่างจาก O1 BlogPost ทุกคน.
- สามารถเรียกใช้โมเดลกลั่นบน Ollama
- เขียนรหัส Manim ได้ดีจริงๆ
เซอร์ไพรส์จากกระดาษ:

- แต่พวกเขาใช้ GRPO จาก DeepseekMath (ท้าทายโดยผู้เขียน DPO) เป็น "กรอบ RL เพื่อปรับปรุงประสิทธิภาพของแบบจำลองในการให้เหตุผล" ที่การใช้เหตุผล (เช่นการติดตามย้อนกลับในบริบท) "เกิดขึ้นตามธรรมชาติ" หลังจาก "ขั้นตอน RL หลายพัน"

- การใช้ "aha moments" เป็นโทเค็นหมุน
- R1 เริ่มฝึกน้อยกว่าหนึ่งเดือนหลังจากประกาศ O1
- การกลั่น R1 นั้นมีประสิทธิภาพอย่างน่าทึ่งทำให้เรามีคำพูดที่บ้าคลั่งนี้: "Deepseek-R1-Distill-Qwen- 1.5B มีประสิทธิภาพสูงกว่า GPT-4O และ Claude-3.5-Sonnet ในการวัดเกณฑ์มาตรฐานทางคณิตศาสตร์ที่มี 28.9% ใน AIME และ 83.9% ในคณิตศาสตร์"
- สิ่งนี้มีประสิทธิภาพมากกว่าการปรับแต่ง RL เป็นรุ่นเล็ก ๆ : "รูปแบบการใช้เหตุผลของรุ่นที่มีขนาดใหญ่กว่าสามารถกลั่นเป็นรุ่นที่เล็กกว่าส่งผลให้ประสิทธิภาพดีขึ้นเมื่อเทียบกับรูปแบบการใช้เหตุผลที่ค้นพบผ่าน RL ในรุ่นเล็ก" aka "Total SFT Victory"
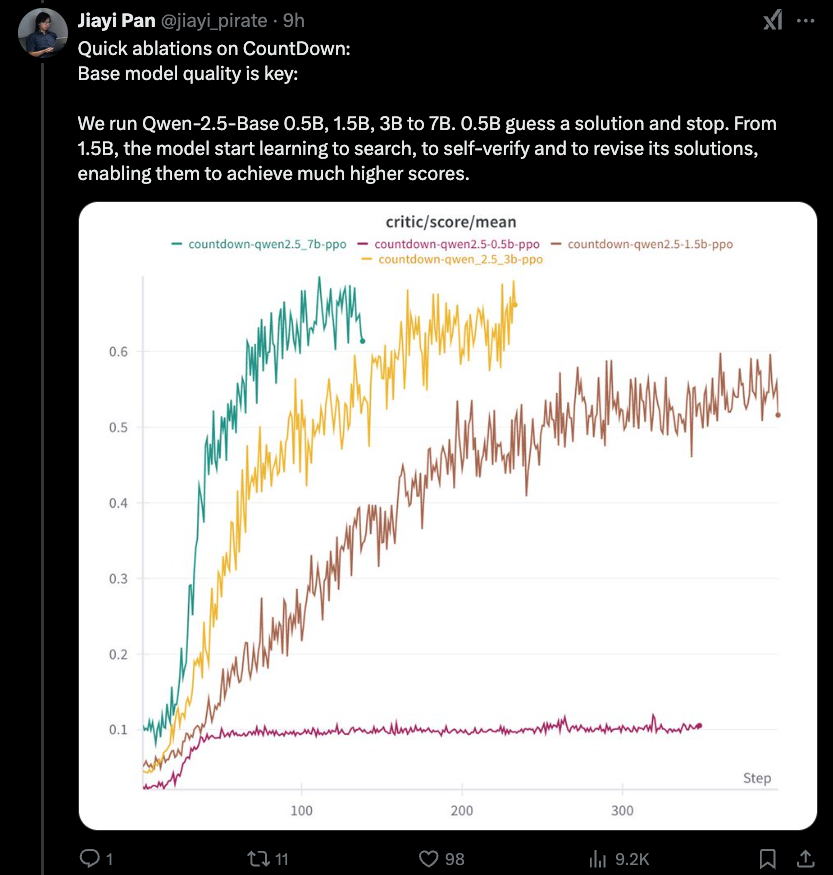
Jiayi-Pan (Tinyzero):
การค้นพบใหม่ที่น่าสนใจที่สุดคือมีผลกระทบที่ต่ำกว่าของเอฟเฟกต์การกลั่นที่เราครอบคลุมเมื่อวานนี้ - 1.5B ต่ำที่สุดเท่าที่คุณไป การให้เหตุผล RLCOT เป็นทรัพย์สินที่เกิดขึ้นใหม่
เทคนิค RL (PPO, GRPO ของ Deepseek หรือ Prime) ไม่สำคัญจริงๆ
เริ่มต้นจากแบบจำลองคำสั่งมาบรรจบกันเร็วขึ้น แต่อย่างอื่นทั้งสองจะจบลง (ตามการสังเกตกระดาษ R1)