Потрясающий Deepseek-R1-Resources
- [? Ссылка]-DeepSeek-AI/DeepSeek-R1: Технический отчет
Размножение
- [? Ссылка]-Hurgingface/Open-R1: Полностью открытое воспроизведение DeepSeek-R1
- [? Ссылка]-Jiayi-Pan/Tinyzero
- [? Ссылка]-HKUST-NLP/SIMPLERL-RESONESS: Это повторение обучения DeepSeek-R1-Zero и Deepseek-R1 на небольших моделях с ограниченными данными
Связанные ресурсы
- R1+Sonnet Shatters Clarkmark при 14 -кратной более низкой стоимости : DeepSeek R1 в паре с сонетом достиг 64% на эталоне PolyGlot, превзойдя O1 , при этом стоил в 14 раз меньше . Пользователи выделили свою лицензию и принятие MIT в лучших университетах.
- R1 Re-Distillation повышает QWEN-1.5B : вариант Mobius Labs ' Redistill ED R1 превзошел оригинал, с планами расширения до других архитектур.
- Рейтинги R1 Arena Spark GPU Теории распределения графических процессоров : R1 Hit #3 в Lmarena, соответствующие результатам кодирования O1 в 20x дешевле , подпитываемые слухами об использовании NVIDIA H100 и поддержке китайского правительства.
- [? Ссылка]-Atfortes/Awesome-LLM-RESEING: Рассуждение в LLMS: документы и ресурсы, включая цепь-размышлений, Openai O1 и Deepseek-R1?
- [? Ссылка] - Натан Ламберт: рецепт Deepseek R1, чтобы повторить O1 и будущее рассуждений LMS
Выводы
Запуск
Когда мы говорим «R1», это неоднозначно. DeepSeek фактически сбросил 8 моделей R1 - 2 «полные» модели и 6 дистилляций на открытых моделях:
- От QWEN 2.5: CeneTuned с 800 тысячами образцов, курируемых с DeepSeek-R1, в 1,5B, 7B, 14B и 32B
- от Llama 3.1 8b Base: DeepSeek-R1-Distill-Llama-8b
- от Llama3.3-70B-Instruct: DeepSeek-R1-Distill-Llama-70b
- и Deepseek-R1 и Deepseek-R1-Zero, полноразмерные модели MoE 671b, похожие на DeepSeek V3. Удивительно, но MIT лицензированы, а не на пользовательские лицензии, в том числе явные ОК для создания и дистилляции
Другие знаменитости с запуска:
- Цены (на миллион токенов): вход 14 центов (хит кэша), вход 55 центов (кэш -пропуск) и 219 центов. Это сравнивается с O1 при входе 750 центов (кэш -хит), 1500 центов вход (кэш -пропуск), 6000 центов. Это 27x-50x дешевле, чем O1.
- Решает каждую проблему из блога O1. каждый.
- может запустить дистиллированные модели на Олламе
- может очень хорошо написать код манима
Сюрпризы из бумаги:

- Но они используют GRPO от DeepSeekmath (оспариваемый автором DPO) в качестве «структуры RL для улучшения производительности модели при рассуждении», где рассуждения (например, в связи с отслеживанием) «естественным образом появились» после «тысяч шагов RL»-не совсем знаменитый сюжет масштабирования O1, а близкий кузин.

- Использование «моментов AHA» в качестве токенов поворота, часто смешивание языков недружественным образом смешивать
- R1 начал обучение менее чем через месяц после объявления O1
- Растилляции R1 были удивительно эффективными, придавая нам эту безумную цитату: «Deepseek-R1-Distill-Qwen- 1,5B превосходит GPT-4O и Claude-3,5-Sonnet на математических показателях с 28,9% на AIME и 83,9% по математике». И это даже не подталкивает перегородку к их ограничениям.
- Это более эффективно, чем только RL-подключение к небольшой модели: «Паттерны рассуждений более крупных моделей могут быть перегоняются в более мелкие модели, что приводит к лучшей производительности по сравнению с шаблонами рассуждений, обнаруженных через RL на небольших моделях». aka "Общая победа SFT"
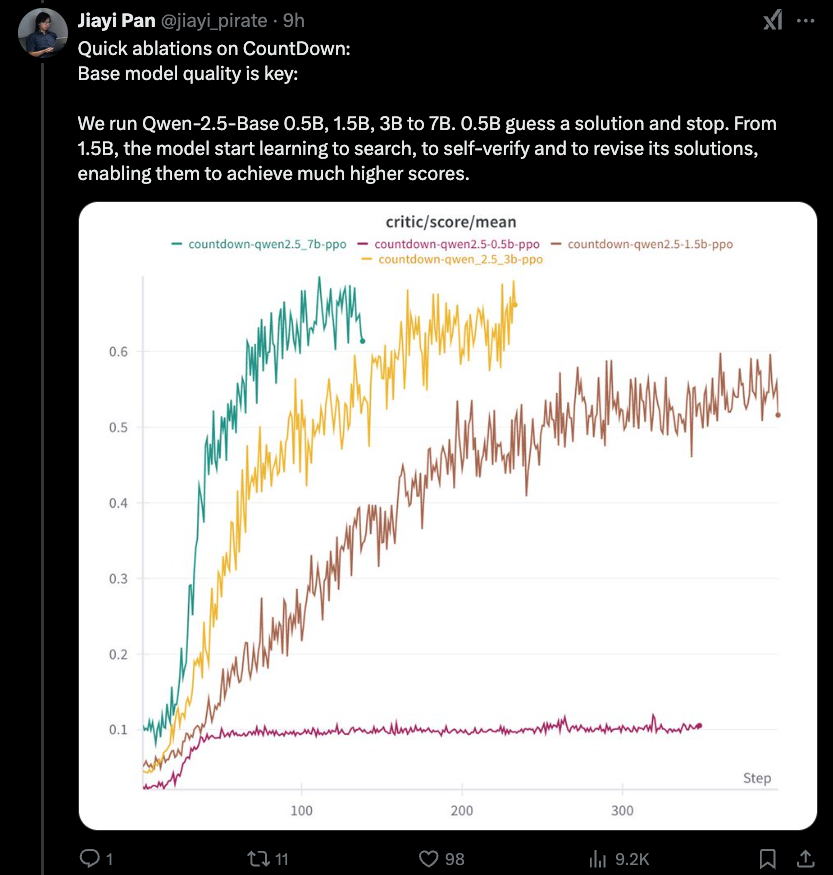
Jiayi-pan (tinyzero):
Наиболее интересным новым выводом является то, что существует более низкая граница с эффектом дистилляции, который мы покрывали вчера - 1,5B настолько низко, как и вы. Рассуждение RLCOT сама по себе является новой собственностью.
Техника RL (PPO, GRPO Deepseek или Prime) не имеет значения
Начиная с инструкта модели сходится быстрее, но в остальном оба заканчиваются одинаковыми (как в случае наблюдения за R1 Paper)