굉장한 깊이 -R1- 자원
- [? 링크]-DeepSeek-AI/DeepSeek-R1 : 기술 보고서
생식
- [? 링크]-Huggingface/Open-R1 : DeepSeek-R1의 완전히 개방 된 재생산
- [? 링크]-JIAYI-PAN/TINYZERO
- [? 링크]-HKUST-NLP/SIMPLERL-REASY : 이것은 제한된 데이터를 가진 작은 모델에 대한 DeepSeek-R1-Zero 및 DeepSeek-R1 교육의 복제입니다.
관련 리소스
- R1+Sonnet은 14 배 낮은 비용으로 벤치 마크를 산산조각냅니다 . Sonnet 과 쌍을 이루는 DeepSeek R1은 Aider Polyglot 벤치 마크에서 64%를 달성하여 O1을 능가하면서 14 배 낮은 비용을 지불했습니다. 사용자는 최고 대학에서 MIT 라이센스와 채택을 강조했습니다.
- r1 재 디틸화는 Qwen-1.5b를 촉진합니다 : Mobius Labs의 Redistill Ed R1 변형은 원본을 능가했으며 다른 아키텍처로 확장 할 계획입니다.
- R1의 경기장 순위 Spark GPU 할당 이론 : Lmarena의 R1 hit #3 , O1 의 코딩 성과와 20 배 저렴한 NVIDIA H100 사용 및 중국 정부 지원에 대한 소문에 연료를 공급했습니다.
- [? 링크]-Atfortes/awesome-llm-reasoning : LLM의 추론 : 생각의 사슬, Openai O1 및 DeepSeek-R1을 포함한 논문과 자원?
- [? 링크] - Nathan Lambert : O1을 복제하기위한 DeepSeek R1의 레시피 및 LMS 추론의 미래
결과
시작하다
우리가 "R1"이라고 말할 때, 그것은 모호합니다. DeepSeek은 실제로 8 개의 R1 모델 -2 "전체"모델과 개방형 모델의 6 가지 증류를 삭제했습니다.
- Qwen 2.5에서 : 1.5b, 7b, 14b 및 32b에서 DeepSeek-R1로 큐 레이션 된 800K 샘플로 Finetuned
- LLAMA 3.1 8B BASE : DeepSeek-R1-Distill-Llama-8b
- LLAMA3.3-70B-비 구조 : DeepSeek-R1-Distill-Llama-70B
- DeepSeek V3과 유사한 671b MoE 모델 인 Deepseek-R1 및 Deepseek-R1-Zero. 놀랍게도, MIT는 정의 및 증류에 대한 명시 적 OK를 포함하여 맞춤형 라이센스보다는 라이센스가 부여됩니다.
출시에서 다른 주목할만한 점 :
- 가격 (백만 마리의 토큰) : 14 센트 입력 (캐시 적중), 55 센트 입력 (캐시 미스) 및 219 센트 출력. 이는 750 센트 입력 (캐시 적중), 1500 센트 입력 (캐시 미스), 6000 센트 출력의 O1과 비교됩니다. O1보다 27x-50x 저렴합니다.
- O1 블로그 포스트에서 모든 문제를 해결합니다. 모든 사람.
- Ollama에서 증류 모델을 실행할 수 있습니다
- Manim 코드를 정말 잘 작성할 수 있습니다
논문의 놀라움 :

- 그러나 그들은 Depseekmath (DPO 저자에 의해 도전받는)의 GRPO를 "텍스트 내 백 트래킹과 같은 추론 (텍스트 내 백 트래킹과 같은)"이 "수천 개의 RL 단계"를 자연스럽게 나왔지만, 유명한 O1 스케일링 플롯이 아니라 가까운 Cousin이라는 "추론에서 모델 성능을 향상시키기위한 RL 프레임 워크"로 사용합니다.

- "aha moments"를 피벗 토큰으로 사용하여 독자 비 우호적 인 방식으로 언어를 혼합합니다.
- R1은 O1 발표 후 한 달도 채되지 않아 훈련을 시작했습니다.
- R1 증류는 놀랍도록 효과적이어서 우리에게 다음과 같은 미친 인용문을 제공했습니다. "Deepseek-R1-Distill-Qwen- 1.5b는 AIME에서 28.9%, 수학에서 83.9%로 GPT-4O 및 Claude-3.5-Sonnet보다 성능 이 우수합니다.
- 이는 작은 모델을 RL 조정하는 것보다 더 효과적입니다. "더 큰 모델의 추론 패턴은 소규모 모델로 증류 될 수있어 작은 모델에서 RL을 통해 발견 된 추론 패턴에 비해 성능이 향상됩니다." 일명 "총 SFT 승리"
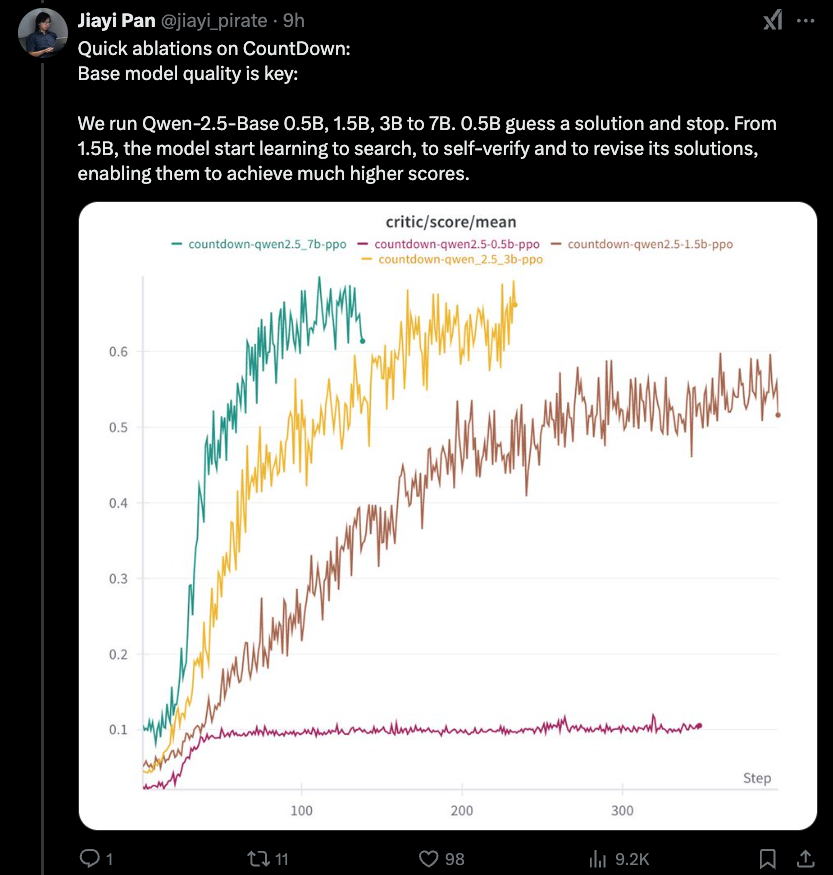
JIAYI-PAN (Tinyzero) :
가장 흥미로운 새로운 발견은 어제 우리가 다루는 증류 효과의 하한이 있다는 것입니다. 1.5B는 당신이가는 것만 큼 낮습니다. RLCOT 추론 자체는 출현 재산입니다.
RL 기술 (PPO, DeepSeek의 GRPO 또는 Prime)은 실제로 중요하지 않습니다.
지시 모델에서 시작하여 더 빠르게 수렴하지만 둘 다 동일하게 끝납니다 (R1 논문 관찰에 따라)