Resources impressionnantes
- [? lien] - Deepseek-ai / Deepseek-R1: Rapport technologique
Reproduction
- [? lien] - HuggingFace / Open-R1: reproduction entièrement ouverte de Deepseek-R1
- [? lien] - jiayi-pan / tinyzero
- [? Lien] - HKUST-NLP / Simplerl-REASHE: Ceci est une réplique de la formation Deepseek-R1-Zero et Deepseek-R1 sur les petits modèles avec des données limitées
Ressources connexes
- R1 + Sonnet se brise la référence à 14 fois le coût inférieur : Deepseek R1 associé à Sonnet a atteint 64% sur la référence Aider Polyglot, surpassant l'O1 tout en coûtant 14 fois en moins . Les utilisateurs ont mis en évidence sa licence et son adoption du MIT dans les meilleures universités.
- R1 Restillation stimule Qwen-1.5b : la variante RED R1 de Redistill ED de Mobius Labs a dépassé l'original, avec des plans pour s'étendre à d'autres architectures.
- Les classements de R1 dans les arènes de R1 étimulent les théories de l'allocation du GPU : R1 Hit # 3 en Lmarena, correspondant aux performances de codage d' O1 à 20x moins chères , alimentées par des rumeurs sur l'utilisation de Nvidia H100 de rechange H100 et le soutien du gouvernement chinois.
- [? Lien] - ATFORTES / AMESSION-LLM-RESADERMING: Raisonnement dans LLMS: papiers et ressources, y compris la chaîne de pensées, Openai O1 et Deepseek-R1?
- [? lien] - Nathan Lambert: la recette de Deepseek R1 pour reproduire l'O1 et l'avenir du raisonnement LMS
Résultats
Lancement
Quand nous disons "R1", c'est ambigu. Deepseek a en fait baissé 8 modèles R1 - 2 modèles "complets" et 6 distillations sur les modèles ouverts:
- De Qwen 2.5: Finetuned avec 800k échantillons organisés avec Deepseek-R1, en 1,5b, 7b, 14b et 32b
- De Llama 3.1 8b Base: Deepseek-R1-Distill-Lama-8b
- De Llama3.3-70B-Instruct: Deepseek-R1-Distill-Llama-70b
- et Deepseek-R1 et Deepseek-R1-Zero, les modèles MOE 671B pleine grandeur similaires à Deepseek V3. Étonnamment, le MIT sous licence plutôt que sur personnalité, y compris explicite OK pour la fintuning et la distillation
Autres notables du lancement:
- Prix (par million de jetons): entrée 14 cents (hit de cache), entrée de 55 cents (miss de cache) et sortie de 219 cents. Cela se compare à l'entrée O1 à 750 cents (coup de cache), entrée de 1500 cents (Miss de cache), 6000 cents de sortie. C'est 27x-50x moins cher que O1.
- résout tous les problèmes du blog O1. tout le monde.
- peut exécuter les modèles distillés sur Olllama
- peut vraiment bien écrire du code de manim
Surprises du journal:

- Mais ils utilisent GRPO de Deepseekmath (contesté par l'auteur DPO) comme "le cadre RL pour améliorer les performances du modèle dans le raisonnement" où le raisonnement (comme le retour dans le contexte) "a naturellement émergé" après "des milliers d'étapes RL" - pas tout à fait le célèbre parcelle de mise à l'échelle O1, mais une cousine proche.

- Utiliser "Aha Moments" comme jetons pivot, mélangeant souvent des langues d'une manière hostile à un lecteur
- R1 a commencé à s'entraîner moins d'un mois après l'annonce de l'O1
- Les distillations R1 étaient remarquablement efficaces, nous donnant cette citation folle: "Deepseek-R1-Distill-Qwen- 1.5B surpasse GPT-4O et Claude-3.5-Sonnet sur les références mathématiques avec 28,9% sur AIME et 83,9% sur les mathématiques.", Et cela sans même pousser la distillation à leurs limites.
- Ceci est plus efficace que le simple réglage de RL un petit modèle: "Les modèles de raisonnement de modèles plus grands peuvent être distillés en modèles plus petits, ce qui entraîne de meilleures performances par rapport aux modèles de raisonnement découverts via RL sur de petits modèles." AKA "Total SFT Victory"
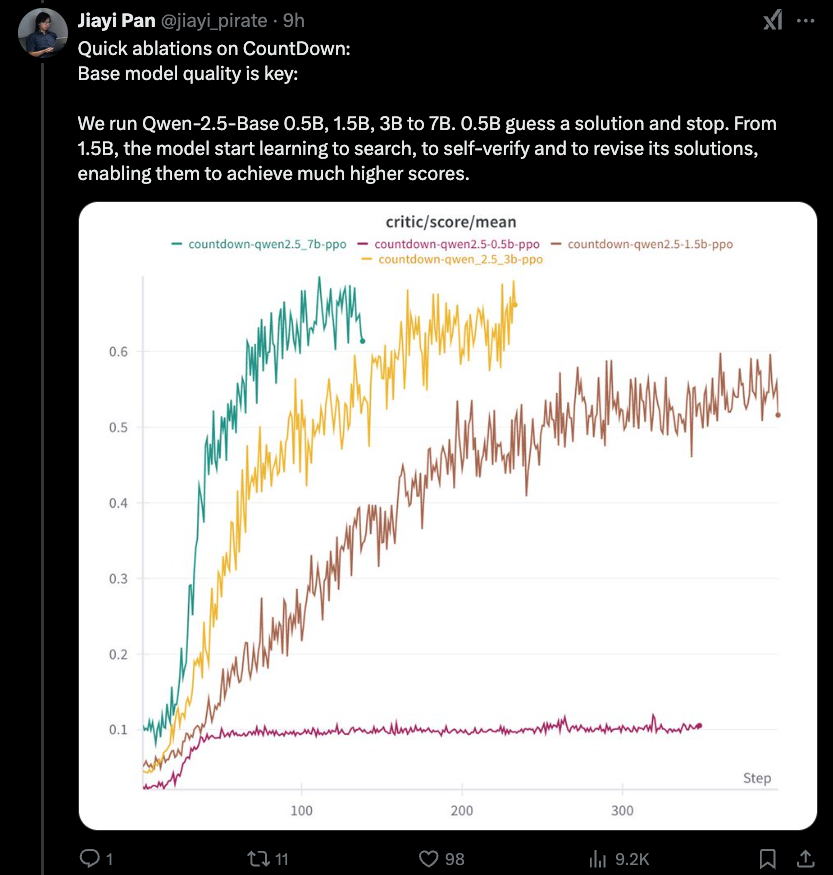
Jiayi-pan (Tinyzero):
La nouvelle découverte la plus intéressante est qu'il y a une limite inférieure à l'effet de distillation que nous avons couvert hier - 1,5b est aussi faible que vous partez. Le raisonnement RLCOT est lui-même une propriété émergente.
La technique RL (PPO, Grpo ou Prime de Deepseek n'a pas vraiment d'importance
À partir de l'instruct, le modèle converge plus rapidement mais sinon les deux se terminent les mêmes (selon l'observation du papier R1)