Awesome-deepseek-r1-resources
- [?リンク] - deepseek-ai/deepseek-r1:技術レポート
再生
- [?リンク] - Huggingface/Open-R1:DeepSeek-R1の完全に開いた複製
- [?リンク] - jiayi-pan/tinyzero
- [?リンク] - hkust-nlp/simplerl-reason:これは、データが限られている小さなモデルでのdeepseek-r1-zeroとdeepseek-r1トレーニングの複製です
関連リソース
- R1+Sonnetは14倍低コストでベンチマークを粉砕します: Deepseek R1とSonnetのペアリングは、Aider PolyGlotベンチマークで64%を達成し、 O1を上回り、14倍のコストを削減しました。ユーザーは、MITライセンスとトップ大学での採用を強調しました。
- R1の再浸透により、QWEN-1.5B :Mobius LabsのRedistill ED R1バリアントがオリジナルを上回り、他のアーキテクチャに拡張する計画を立てました。
- R1のアリーナランキングスパークGPU割り当て理論:R1はLMARENAで#3をヒットし、 20倍安いO1のコーディングパフォーマンスを一致させ、予備のNVIDIA H100使用と中国政府の支援の噂に拍車をかけました。
- [?リンク] - Atfortes/Awesome-llm-Reasoning:LLMSの推論:考え方、Openai O1、Deepseek-R1を含む論文とリソース?
- [?リンク] - ネイサンランバート:O1と推論の未来を複製するためのDeepseek R1のレシピ
調査結果
打ち上げ
「R1」と言うとき、それは曖昧です。 DeepSeekは実際に8つのR1モデル-2つの「フル」モデル、およびオープンモデルで6つの蒸留をドロップしました。
- Qwen 2.5から:1.5b、7b、14b、および32bで、deepseek-r1でキュレーションされた800kのサンプルで微調ューされました
- Llama 3.1 8bベースから:Deepseek-R1-Distill-llama-8b
- llama3.3-70b-instructから:deepseek-r1-distill-llama-70b
- DeepSeek-R1およびDeepSeek-R1-Zero、Full-Size、671B MOEモデル、DeepSeek V3に似ています。驚くべきことに、Finetuningと蒸留用の明示的なOKを含む、カスタムライセンスではなくライセンスを取得したMIT
打ち上げからのその他の著名人:
- 価格(100万トークンあたり):14セントの入力(キャッシュヒット)、55セント入力(キャッシュミス)、219セントの出力。これは、750セントの入力(キャッシュヒット)、1500セントの入力(キャッシュミス)、6000セントの出力でのO1と比較されます。これはO1よりも27倍から50倍安いです。
- O1 BlogPostからすべての問題を解決します。みんな。
- オラマで蒸留モデルを実行できます
- マニムコードを本当によく書くことができます
紙からの驚き:

- しかし、彼らは、Deepseekmath(DPO著者に挑戦する)のGRPOを「RLフレームワークに挑戦して、推論のモデルパフォーマンスを改善する」(コンテキスト内のバックトラッキングなど)「数千のRLステップ」の後に「自然に出現した」 - O1スケーリングプロットではなく、近いCousinです。

- 「Aha Moments」をピボットトークンとして使用し、多くの場合、読者の友好的な方法で言語を混ぜます
- R1はO1の発表の1か月以内にトレーニングを開始しました
- R1蒸留は非常に効果的で、この非常識な引用を与えてくれました。
- これは、小さなモデルを単に調整するよりも効果的です。「より大きなモデルの推論パターンは、小さなモデルに蒸留することができ、小さなモデルでRLで発見された推論パターンと比較してパフォーマンスが向上します。」別名「合計SFT勝利」
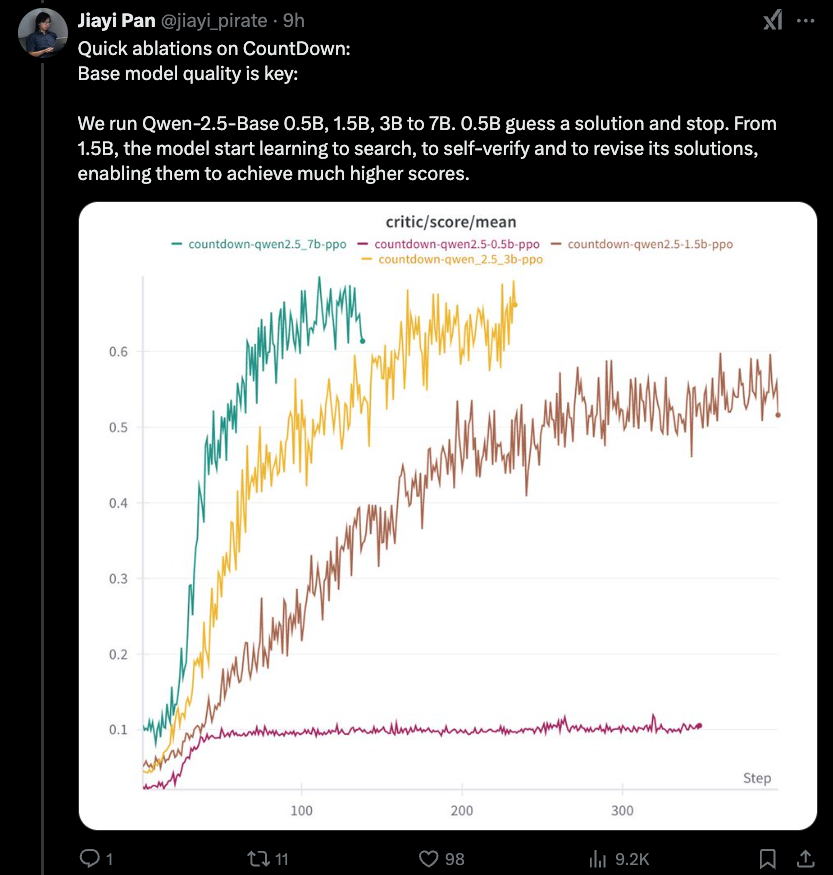
Jiayi-Pan(Tinyzero):
最も興味深い新しい発見は、昨日カバーした蒸留効果の下限があるということです-1.5Bはあなたが行くのと同じくらい低いことです。 rlcotの推論自体は緊急のプロパティです。
RLテクニック(PPO、DeepseekのGRPO、またはPRIME)は本当に重要ではありません
指示モデルから始めることはより速く収束しますが、それ以外は両方が同じで終わります(R1紙の観察に従って)