Awesome-Sueek-R1-R1-RESOURCES
- [? Link]-Deepseek-AI/Deepseek-R1: Relatório de Tecnologia
Reprodução
- [? Link]-Huggingface/Open-R1: Reprodução totalmente aberta de Deepseek-R1
- [? Link]-Jiayi-pan/tinyzero
- [? link]-hkust-nlp/simples-roason: esta é uma replicação do treinamento Deepseek-R1-Zero e Deepseek-R1 em modelos pequenos com dados limitados
Recursos relacionados
- O soneto R1+quebra o benchmark a 14x de menor custo : o Deepseek R1 emparelhado com o soneto alcançado 64% na referência de poliglota da AIDER, superando O1 enquanto custa 14x menos . Os usuários destacaram sua licença e adoção do MIT nas principais universidades.
- O R1 Re-Distilação aumenta QWEN-1.5B : A variante Redistill Ed R1 da Mobius Labs superou o original, com planos de expandir para outras arquiteturas.
- Rankings de arena de R1 Teorias de alocação de GPU Spark : R1 atingiu o 3º lugar em Lmarena, combinando o desempenho de codificação de O1 em 20x mais barato , alimentado por rumores de uso sobressalente da NVIDIA H100 e apoio do governo chinês.
- [? Link]-Atfortes/Awesome-llm-Remuneing: Raciocínio no LLMS: Documentos e Recursos, incluindo cadeia de pensamento, Openai O1 e Deepseek-R1?
- [? Link] - Nathan Lambert: Receita de Deepseek R1 para replicar O1 e o futuro do raciocínio LMS
Descobertas
Lançar
Quando dizemos "R1", é ambíguo. Deepseek realmente soltou 8 modelos R1 - modelos "completos" e 6 destilações em modelos abertos:
- De Qwen 2.5: FinetUned com 800 mil amostras com curadoria de Deepseek-R1, em 1,5b, 7b, 14b e 32b
- De Llama 3.1 8b Base: Deepseek-R1-Distill-llama-8b
- de LLAMA3.3-70B-INSTRUTA: Deepseek-R1-Distill-llama-70b
- e Deepseek-R1 e Deepseek-R1-Zero, os modelos MOE de 671b em tamanho real semelhante ao Deepseek V3. Surpreendentemente, o MIT licenciado em vez de licenças personalizadas, incluindo OK explícito para finetuning e destilação
Outros notáveis do lançamento:
- Preços (por milhão de tokens): 14 centavos de entrada (acerto de cache), entrada de 55 centavos (miss cache) e saída de 219 centavos. Isso se compara ao O1 a 750 centavos de entrada (acerto de cache), entrada de 1500 centavos (cache miss), 6000 centavos de saída. Isso é 27x-50x mais barato que O1.
- Resolve todos os problemas do O1 BlogPost. todos.
- pode executar os modelos destilados no ollama
- pode escrever o código de manim muito bem
Surpresas do artigo:

- Mas eles usam o GRPO do DeepSeekmath (desafiado pelo autor do DPO) como "a estrutura do RL para melhorar o desempenho do modelo no raciocínio" onde o raciocínio (como o rastreamento de fundo do contexto) "naturalmente emergiu" depois de "milhares de etapas de RL"-não é o famoso ploto de escala O1, mas um prato próximo.

- Usando "AHA Moments" como fichas dinâmicas, muitas vezes misturando idiomas de uma maneira hostil
- R1 começou a treinar menos de um mês após o anúncio da O1
- As destilações R1 foram notavelmente eficazes, dando-nos esta cotação insana: "Deepseek-R1-Distill-Qwen- 1,5b supera GPT-4O e Claude-3,5 em referências matemáticas com 28,9% em AIMe e 83,9% em matemática", e isso é sem a destacação da distinção às limites.
- Isso é mais eficaz do que apenas RL ajustando um modelo pequeno: "Os padrões de raciocínio de modelos maiores podem ser destilados em modelos menores, resultando em melhor desempenho em comparação com os padrões de raciocínio descobertos através da RL em modelos pequenos". aka "Total SFT Victory"
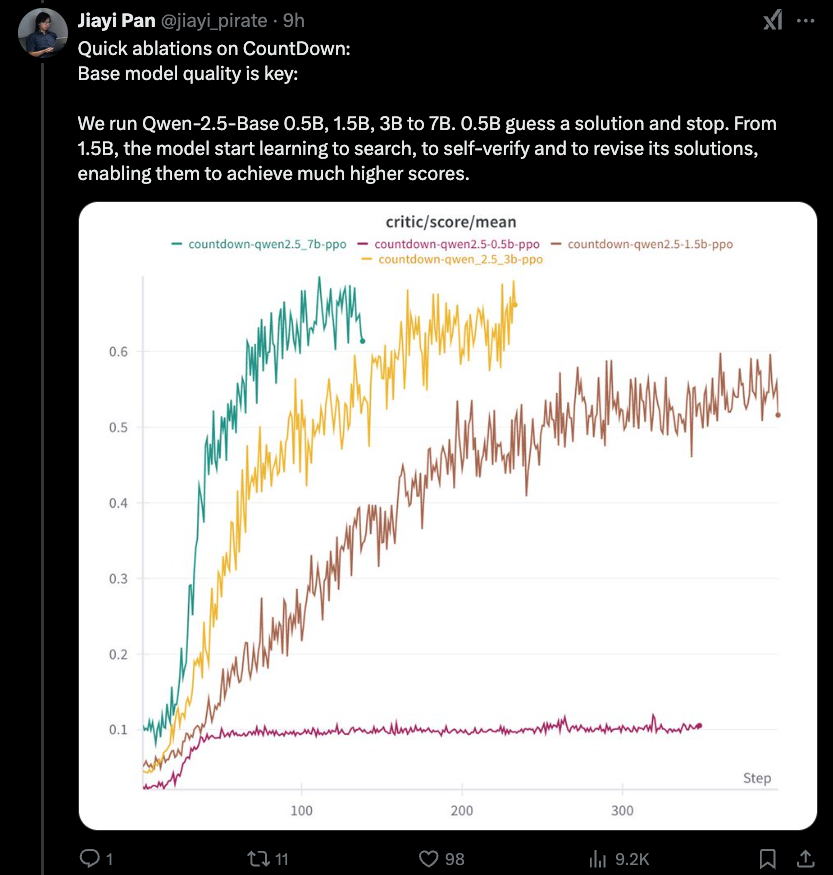
Jiayi-pan (tinyzero):
A nova descoberta mais interessante é que há um limite inferior ao efeito de destilação que abordamos ontem - 1,5b é tão baixo quanto você vai. O raciocínio rlCot é em si uma propriedade emergente.
Técnica RL (PPO, GRPO de Deepseek, ou Prime) não importa realmente
A partir do modelo de instrução, converge mais rápido, mas ambos terminam o mesmo (conforme a observação de papel R1)