Sumber daya deepseek-r1 yang mengagumkan
- [? Tautan]-Deepseek-Ai/Deepseek-R1: Laporan Teknologi
Reproduksi
- [? Tautan]-Huggingface/Open-R1: Reproduksi Terbuka Deepseek-R1 Terbuka
- [? Tautan]-Jiayi-Pan/Tinyzero
- [? Tautan]-HKUST-NLP/Simplerl-Reason: Ini adalah replikasi pelatihan Deepseek-R1-Zero dan Deepseek-R1 pada model kecil dengan data terbatas
Sumber daya terkait
- Benchmark R1+Sonnet Shatters dengan biaya 14x lebih rendah : Deepseek R1 dipasangkan dengan soneta mencapai 64% pada tolok ukur poliglot Aider, mengungguli O1 sementara harganya lebih murah . Pengguna menyoroti lisensi dan adopsi MIT di universitas terkemuka.
- R1 Distilasi Meningkatkan Qwen-1.5b : Varian Redistill R1 Mobius Labs 'R1 melampaui aslinya, dengan rencana untuk memperluas ke arsitektur lain.
- Peringkat Arena R1 memicu teori alokasi GPU : R1 hit #3 di Lmarena, mencocokkan kinerja pengkodean O1 di 20X lebih murah , dipicu oleh rumor penggunaan cadangan NVIDIA H100 dan dukungan pemerintah Cina.
- [? Link]-Atfortes/Awesome-Llm-Reasoning: Reasoning in LLMS: Makalah dan Sumber Daya, termasuk rantai-dipikirkan, Openai O1, dan Deepseek-R1?
- [? Link] - Nathan Lambert: Resep Deepseek R1 untuk mereplikasi O1 dan masa depan penalaran LMS
Temuan
Meluncurkan
Ketika kita mengatakan "R1", itu ambigu. Deepseek sebenarnya menjatuhkan 8 model R1 - 2 model "penuh", dan 6 distilasi pada model terbuka:
- Dari Qwen 2.5: Finetuned dengan 800K sampel yang dikuratori dengan Deepseek-R1, dalam 1.5b, 7b, 14b, dan 32b
- Dari Llama 3.1 8b Base: Deepseek-R1-Distill-Llama-8B
- dari llama3.3-70b-instruct: Deepseek-R1-Distill-llama-70b
- dan Deepseek-R1 dan Deepseek-R1-Zero, model MOE 671b ukuran penuh yang mirip dengan Deepseek V3. Anehnya, MIT berlisensi daripada lisensi khusus, termasuk OK eksplisit untuk finetuning dan distilasi
Tokoh terkenal lainnya dari peluncuran:
- Harga (per juta token): Input 14 sen (cache hit), 55 sen input (cache miss), dan output 219 sen. Ini dibandingkan dengan O1 pada input 750 sen (cache hit), input 1500 sen (cache miss), 6000 sen output. Itu 27x-50x lebih murah dari O1.
- memecahkan setiap masalah dari blogpost O1. setiap orang.
- dapat menjalankan model suling di ollama
- bisa menulis kode manim dengan sangat baik
Kejutan dari kertas:

- Tetapi mereka menggunakan GRPO dari Deepseekmath (ditantang oleh penulis DPO) sebagai "kerangka kerja RL untuk meningkatkan kinerja model dalam penalaran" di mana penalaran (seperti pelacakan belakang dalam konteks) "secara alami muncul" setelah "ribuan langkah RL"-bukan plot penskalaan O1 yang terkenal, tetapi cousin yang dekat.

- Menggunakan "AHA Moments" sebagai token pivot, sering mencampur bahasa dengan cara yang tidak ramah pembaca
- R1 mulai berlatih kurang dari sebulan setelah pengumuman O1
- Distilasi R1 sangat efektif, memberi kami kutipan gila ini: "Deepseek-R1-Distill-Qwen- 1.5b mengungguli GPT-4O dan Claude-3.5-Sonnet pada tolok ukur matematika dengan 28,9% pada AIME dan 83,9% pada matematika.", Dan ini bahkan tanpa mendorong distilasi ke dasar mereka.
- Ini lebih efektif dari sekadar RL-tuning model kecil: "Pola penalaran model yang lebih besar dapat disuling menjadi model yang lebih kecil, menghasilkan kinerja yang lebih baik dibandingkan dengan pola penalaran yang ditemukan melalui RL pada model kecil." alias "Total SFT Victory"
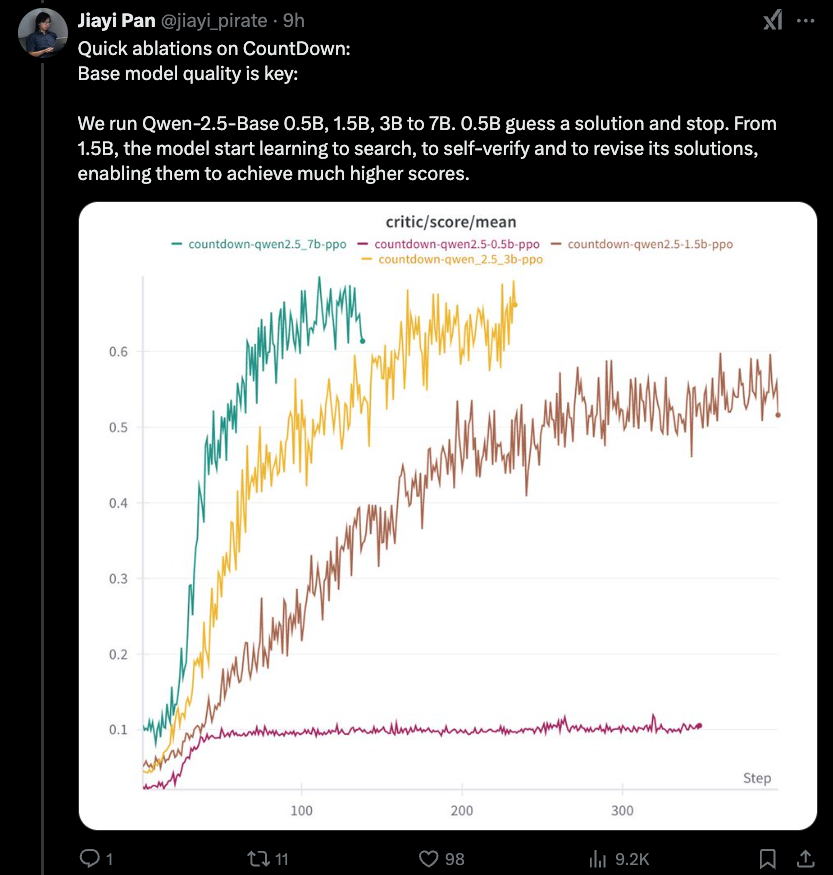
Jiayi-Pan (Tinyzero):
Temuan baru yang paling menarik adalah bahwa ada batas bawah ke efek distilasi yang kami bahas kemarin - 1.5b serendah Anda. Penalaran RLCOT sendiri merupakan properti yang muncul.
Teknik RL (PPO, GRPO Deepseek, atau Prime) tidak terlalu penting
Mulai dari model instruksi konvergen lebih cepat tetapi keduanya berakhir sama (sesuai dengan pengamatan kertas R1)