رهيبة Deepseek-R1 موارد
- [؟ Link]-Deepseek-Ai/Deepseek-R1: تقرير تقني
التكاثر
- [؟ Link]-Huggingface/Open-R1: التكاثر المفتوح بالكامل لـ DeepSeek-R1
- [؟ Link]-Jiayi-Pan/Tinyzero
- [؟ LINK]-HKUST-NLP/Simplerl-Reason: هذا هو تكرار لتدريب Deepseek-R1-Zero و Deepseek-R1 على نماذج صغيرة مع بيانات محدودة
الموارد ذات الصلة
- R1+Sonnet يحطم المعيار بتكلفة أقل من 14x : حقق Deepseek R1 مقترنًا بونيت 64 ٪ على معيار Polyglot Aider ، يتفوق على O1 بينما يكلف 14x أقل . أبرز المستخدمون ترخيص معهد ماساتشوستس للتكنولوجيا وتبنيه في أفضل الجامعات.
- R1 يعزز إعادة التصميم Qwen-1.5b : متغير Mobius Labs ' Redistill ed R1 تجاوز الأصل ، مع خطط للتوسع في بنيات أخرى.
- تصنيفات Arena's Arena's Parch نظريات تخصيص GPU : R1 Hit #3 في Lmarena ، مطابقة أداء الترميز في O1 على ارتفاع 20X ، تغذيه شائعات عن استخدام Nvidia H100 ودعم الحكومة الصينية.
- [؟ Link]-atoveres/Awesome-Llm-Roxer: التفكير في LLMS: الأوراق والموارد ، بما في ذلك سلسلة الفكرة ، Openai O1 ، و Deepseek-R1؟
- [؟ Link] - Nathan Lambert: Deepseek R1 وصفة لتكرار O1 ومستقبل LMS
النتائج
يطلق
عندما نقول "R1" ، إنه غامض. أسقطت Deepseek فعليًا 8 نماذج R1 - 2 نماذج "كاملة" ، و 6 تقطير في النماذج المفتوحة:
- من QWEN 2.5: تم تحريكه مع 800 ألف عينة برعاية مع Deepseek-R1 ، في 1.5B ، 7B ، 14B ، و 32B
- من LLAMA 3.1 8B قاعدة: DEEPSEEK-R1-Distill-Llama-8B
- من llama3.3-70b-instruct: Deepseek-R1-Distill-llama-70b
- و Deepseek-R1 و Deepseek-R1-Zero ، نماذج Moe ذات الحجم الكامل ، 671 ب تشبه Deepseek V3. من المثير للدهشة أن معهد ماساتشوستس للتكنولوجيا مرخصة بدلاً من التراخيص المخصصة ، بما في ذلك OK الصريح للتكوين المحدود والتقطير
شخصيات بارزة أخرى من الإطلاق:
- التسعير (لكل مليون رمز): مدخلات 14 سنتًا (ضربات ذاكرة التخزين المؤقت) ، إدخال 55 سنتًا (MISS MISS) ، وإخراج 219 سنتًا. يقارن هذا بـ O1 عند مدخلات 750 سنتًا (HIT Cache) ، إدخال 1500 سنت (MISS MISS) ، 6000 سنت. هذا هو 27x-50x أرخص من O1.
- يحل كل مشكلة من O1 blogpost. الجميع.
- يمكن تشغيل النماذج المقطرة على Ollama
- يمكن أن تكتب رمز مانيم جيدا حقا
مفاجآت من الورقة:

- لكنهم يستخدمون GRPO من DeepSeekmath (الذي يواجهه مؤلف DPO) باعتباره "إطار عمل RL لتحسين أداء النموذج في التفكير" حيث يظهر التفكير (مثل التتبع الخلفي في السياق) "ظهر بشكل طبيعي" بعد "آلاف خطوات RL"-ليس تمامًا مؤامرة Scaling الشهيرة ، ولكن بجلس وثيق.

- باستخدام "لحظات آها" كرموز محورية ، وغالبًا ما تمزج اللغات بطريقة غير ودية
- بدأ R1 التدريب بعد أقل من شهر من إعلان O1
- كانت عمليات التقطير R1 فعالة بشكل ملحوظ ، مما يمنحنا هذا الاقتباس المجنون: "Deepseek-R1-Distill-Qwen- 1.5b يتفوق على GPT-4O و Claude-3.5-Sonnet على معايير الرياضيات مع 28.9 ٪ على AIME و 83.9 ٪ على الرياضيات." ، وهذا دون أن يدفع التقطير إلى حدودها.
- هذا أكثر فعالية من مجرد صياغة RL نموذج صغير: "يمكن تقطير أنماط التفكير في النماذج الأكبر في نماذج أصغر ، مما يؤدي إلى أداء أفضل مقارنة بأنماط التفكير التي تم اكتشافها من خلال RL على النماذج الصغيرة." AKA "إجمالي SFT Victory"
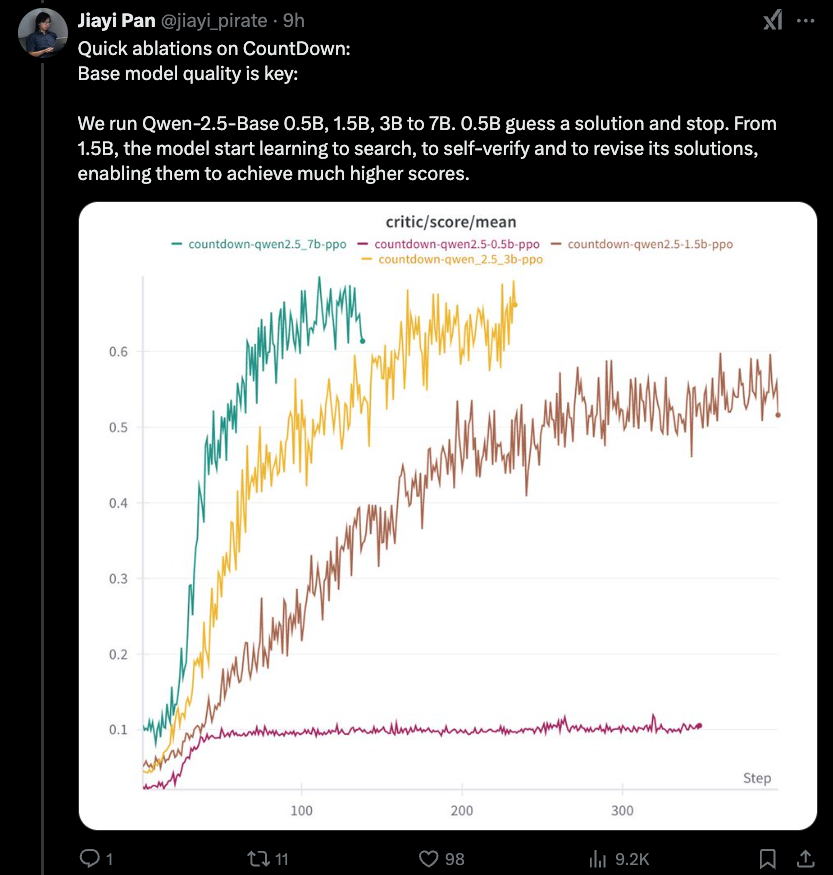
Jiayi-Pan (Tinyzero):
النتيجة الجديدة الأكثر إثارة للاهتمام هي أن هناك حد أدنى لتأثير التقطير الذي قمنا بتغطيته بالأمس - 1.5B منخفض بقدر ما تذهب. التفكير RLCOT هو في حد ذاته خاصية ناشئة.
تقنية RL (PPO ، Deepseek's GRPO ، أو Prime) لا يهم حقًا
بدءًا من نموذج الإرشاد يتقارب بشكل أسرع ولكن على خلاف ذلك ينتهي كلاهما (كما في مراقبة ورقة R1)