erdos_paware
1.0.0
该项目由Marcos Ortiz,Sayantan Roy,Karthik Prabhu,Kristina Knowles和Diptanil Roy完成,这是ErdösInstitute Deep Leach Boot Camp的一部分(2024年春季)。
我们的项目在下面详细介绍,您可以按照PAW_DEMO/ Directory中提供的演示笔记本和数据的主要步骤进行操作。
前四个笔记本电脑使用一小部分数据进行了演示。最后一个笔记本电脑在整个数据集上提供了我们的结果摘要。
给定任意用户查询和人类生成内容的数据集,构建算法以识别和对数据集中的相关内容进行排名,以便可以快速准确地检索匹配集合
我们知道,我们项目结果的最终应用是在检索型发电(RAG)管道中使用。这份最近描述了大语模型(LLMS)的抹布现状的调查文件有助于了解哪种工具可能非常适合我们的特定任务和数据。
抹布的主要步骤是:
提供给我们的原始数据包括来自Reddit的5,528,298个帖子,来自34个子列表。这些数据是在镶木quet文件中提供的,以及数据词典。
对于这个项目,我们专注于抹布过程的前两个步骤:索引和检索。
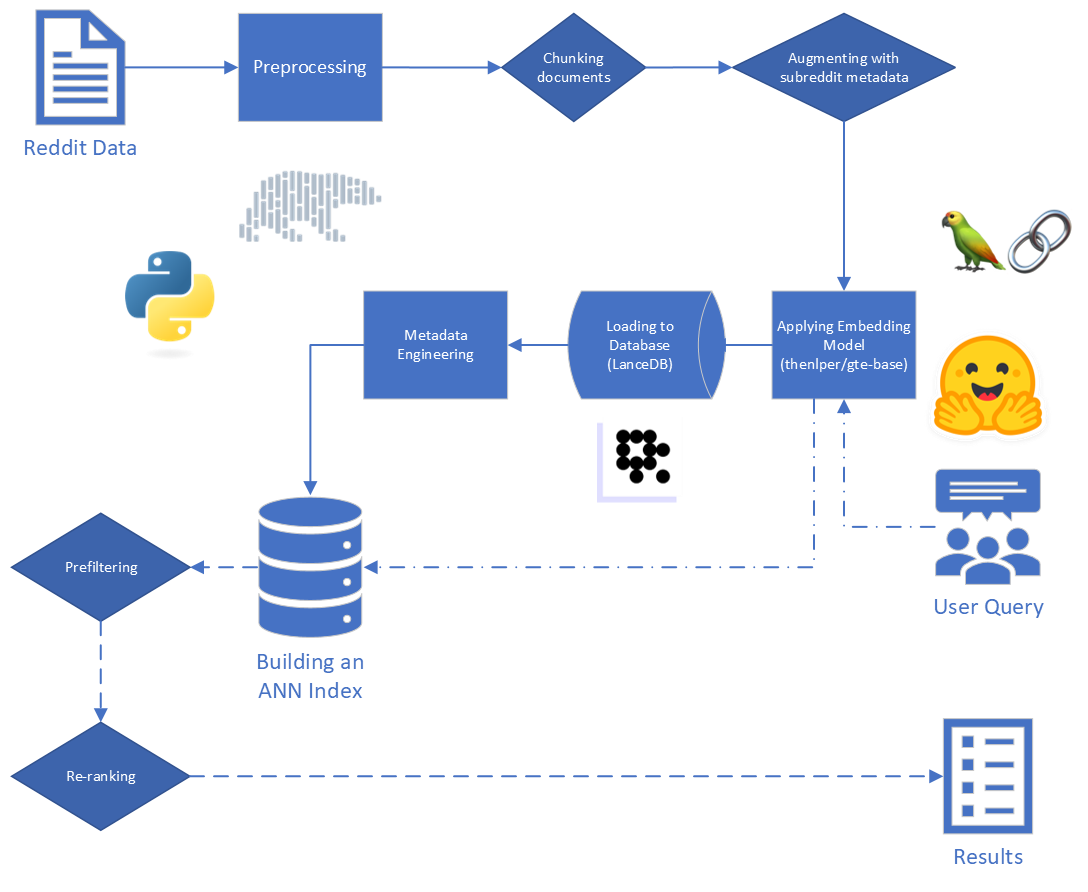
从原始数据开始,我们进行了一些基本清洁:
"[deleted]"或"removed"的reddit_text值掉落的行。reddit_text值的所有行来完成的,并且出现超过7次。如果以后可能有用,我们不想立即删除较短的通用短语(请参阅使用工程元数据)。reddit_text值。reddit_title是reddit_text的代理。因此,在这些情况下,我们用reddit_title替换了空的reddit_text 。 我们使用了基于BERT框架的一般文本嵌入式(GTE)模型的基本版本。拥抱面文档:链接。
我们之所以选择该模型,是因为它似乎是一个合理的尺寸(0.22GB),它是开源的,并且允许嵌入长度高达512个令牌的文本。与其他少于2.50亿参数的开源句子变形金刚相比,它在聚类和检索方面的性能特别出色:链接。
此外,其一部分培训是使用Reddit数据完成的,这增加了其吸引力。
我们考虑了使用其他模型进行的实验,但是由于将数据集与每个新模型嵌入数据集的高计算成本,因此我们为将来的工作保存了这一途径。
我们使用Sbert提供的句子变形金刚框架来实施我们的嵌入模型,以及Langchain提供的拥抱面部嵌入工具
在嵌入过程中,我们考虑了以下参数:
chunk_size :作为文档嵌入的最大文本长度chunk_overlap :每当需要将文档分解成块时,它们应该重叠多少我们还尝试将元数据固定在嵌入之前。为此,我们只需将subreddit标题(或近似值)添加到嵌入文本块的开始即可。例如,如果在FedExers中有评论说“我真的很喜欢在这里工作,因为...”,那么我们将“ FedEx”附加到块的开始,并嵌入“ Fedex n n,我真的很喜欢在这里工作,因为...
我们的直觉是,在帖子不明确包含他们正在讨论的公司名称的情况下,我们可以从SubReddit中推断出这些信息,并且这可能会推动该向量更接近我们的查询。例如,如果我们问“为什么员工喜欢在迪士尼工作?”和“为什么员工喜欢在联邦快递工作?”我们的希望是,元数据的添加使上述评论更有可能在联邦快递查询的结果中显示出更高的表现,而迪士尼查询的结果可能更低。
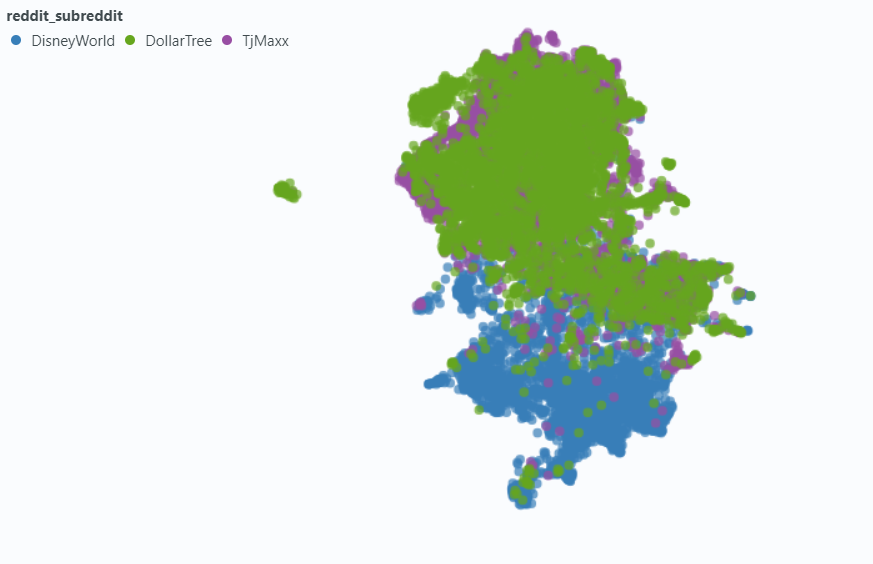
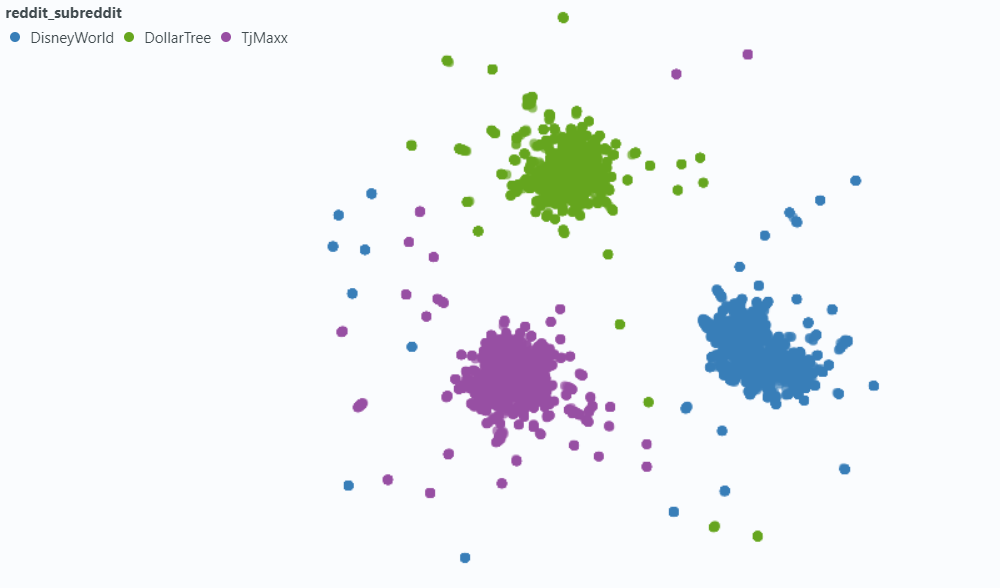
我们使用Spotlight可视化对我们数据的一小部分样本的影响。
没有元数据的嵌入:
与元数据嵌入:
我们选择LancedB(链接)来满足我们的矢量数据库需求。 LancedB是一个开源选项,它提供了与Python和Polars的集成,我们都非常依赖它们。
LancedB提供了倒置文件索引(IVF)和产品量化(PQ)的组合,以构建大约最近的邻居(ANN)索引。
可以通过调整以下参数来微调IVF-PQ索引的两个部分:
我们修复了索引参数,并改变了检索参数。但是,如果允许时间,我们可能会有所不同,以了解检索时间和准确性如何影响。
除了我们的ANN索引中内置的查询参数外,我们还改变了其他反应前和后恢复后变量,以尝试改善我们的整体结果。
在标记数据时,我们注意到一种常见的“相关但无关”结果类型:一个提出与查询本身相似的问题的reddit_text 。
在大多数情况下,这些文本来自submission (而不是评论)。因此,尝试提升更多相关结果的一种方法可能是从向量搜索中省略这些结果。考虑到这些信息包含在我们的原始元数据中,这很容易。
不太频繁,但仍然足以注意到, comment将展示此属性。为了尝试遏制其影响,我们设计了一个元数据列is_short_question以尝试识别所有提出简短问题的reddit_text示例(因此,不太可能为回答这些问题提供有用的信息),以便在搜索之前也可以过滤它们。
为了提高检索后的结果排名,我们设计了一些广泛的元数据,这些元数据可能使我们能够利用答复内容提供的信息。
我们设计了两种类型的元数据:
sentiment和agree_distance措施(和disagree_distance )。对于reply_sentiment ,我们利用了一种预先训练的自然语言处理模型,称为“ MRM8488/Distilroberta-Fineted-Financial-Financial-News-Sentiment-Sentiment-Senalysisiment-analalysiss-sensiment-Senalsisimens-Sensiment-Analysiss”,以衡量文本背后的情感语调。该模型帮助我们将每个答复分为诸如正面,中立或负面的类别。然后汇总了所有答复的情感评分,以反映每个原始文章和以下评论的总体情感。这里的基本假设是,产生主要积极答复的帖子可能具有建设性和信息性,因此可以作为用户认可的代理,类似于Reddit中的upvotes。我们的假设是,具有更积极答复的帖子更有可能包含有用的信息。
在agree_distance的情况下,我们测量了每个reddit_text和一组“同意语句”之间的距离。然后,每当提交或注释回复时,我们都会添加top_reply_agree_distance和avg_reply_agree_distance 。我们的假设是,与“同意”陈述更接近的答复的帖子更有可能包含相关信息。同样,带有更接近“不同意”陈述的答复的帖子不太可能与之相关。
重新排列时,较低的avg_reply_agree_distance的结果更高,较低的avg_reply_disagree_distance的结果降低了。
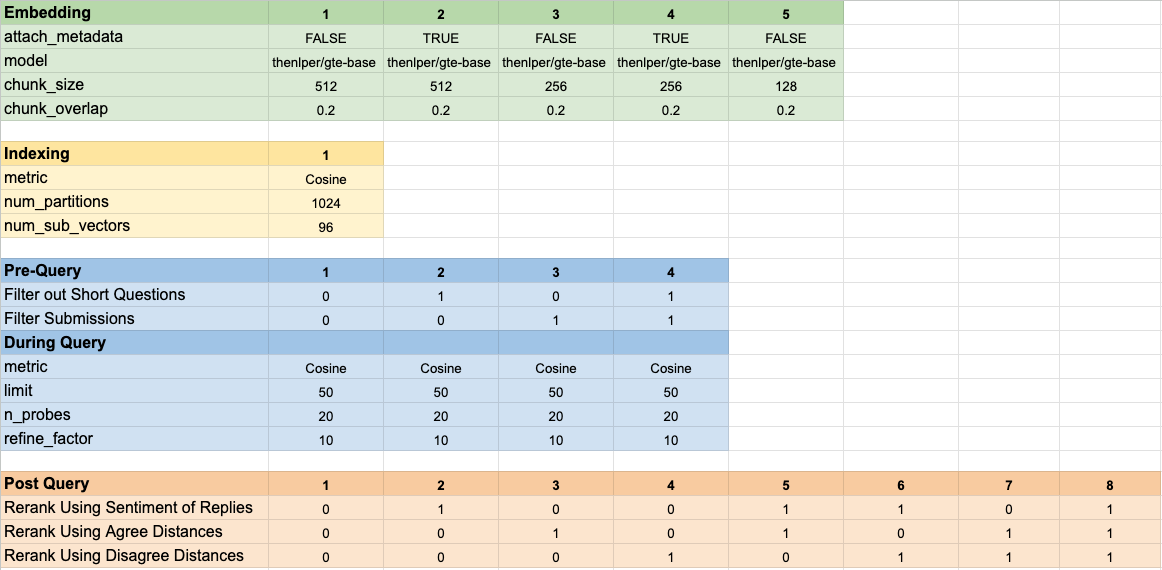
我们测试了160个不同的模型配置。每种配置都包括选择嵌入的选择,在执行矢量搜索之前过滤测试的策略以及重新列入检索结果的策略。
这些超参数总结在下图中:
在评估结果时,我们有两个主要目标:
尽管检索时间很容易衡量,但我们需要开发一些工具来衡量我们在结果排名上的进度。
为了建立评估结果排名的基线,我们手动标记了一部分结果,以建立初始相关性的指标。为此,我们为培训集中的13个数据集中的每个数据集创建了两个查询,并标记了每个查询的前20个结果。结果被标记为:
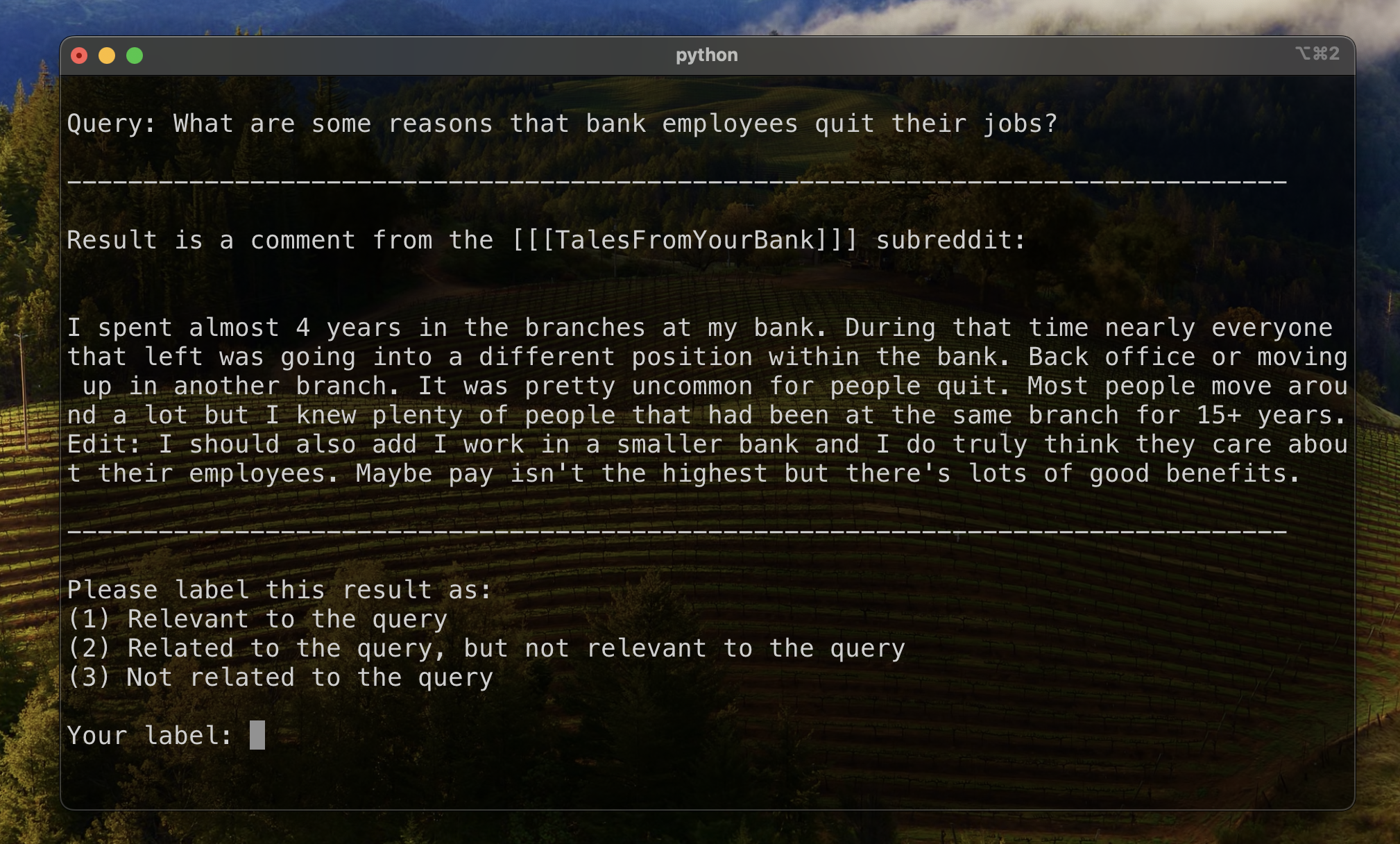
对于每个查询结果,最终标签是由多个投票确定的,并且违约的联系不相关。然后使用此手动标记的数据来量化结果。
我们使用三个指标来对结果进行排名。每个都是推荐系统度量标准的修改版本,适用于我们没有明确地面真相的用例,或者是从最相关到最不相关的相关结果的既定排名。
该指标给出了一个分数,表明出现第一个已知相关结果的顶部。如果每个查询的最高结果是相关的,则可以达到1分的完美分数。
为了计算给定查询的相互等级,我们应用了以下公式:
在标准应用中,有一个已知的“地面真相”结果。在我们修改的应用中,我们接受了任何已知的相关结果作为基础真理。
然后,我们计算了所有标准查询中这些分数的平均值,以达到平均值等级。
该指标给出了一个分数,表明我们已知的相关结果中有多少位在顶部附近出现。如果所有已知的相关结果似乎是所有查询的最高结果(没有未标记的结果似乎高于任何已知的相关结果,则可以达到1分的完美分数。
为了计算给定查询的扩展相互等级,我们应用了以下公式:
在哪里
在哪里
在标准应用程序中,每个相关结果都有其自己的等级,并且对整体得分的贡献考虑到了这一排名是其在结果中的预期位置。在我们修改的应用中,我们为出现在上述位置的任何已知相关结果做出了相同的贡献
然后,我们计算了所有标准查询中这些分数的平均值,以达到平均值等级。
打折累积增益(DCG)通常被用作评估搜索引擎性能的度量,并测量算法在将相关结果放置在检索列表顶部的效率上。对于长度响应列表
在哪里
由于DCG得分很大程度上取决于检索列表的长度,因此我们需要将其归一化,以便在查询检索方案中得分一致,结果数量可变。位置的归一化折扣累积增益(NDCG)得分
在哪里
NDCG可以占据序相关得分(高度相关的1,有点相关的2,依此类推)。我们通过将人类标签(与1相关,2相关但无关的,3-不相关)转换为二进制评分方案来修改案件的评分方案。人类标签= 1的结果给出了相关得分= 1,并且其他所有内容的相关得分为0。这是为了确保NDCG分数所决定的最佳配置只能返回高度相关的结果。然后,我们计算了我们的标准查询的NDCG分数,并将它们平均以获取特定配置的平均NDCG分数。通过设置计算DCG分数和IDCG分数
在哪里
我们使用以下模型参数作为我们的基线进行比较:
基线配置达到了我们指标的以下分数:
| 公制 | 分数 | 排名(160个) |
|---|---|---|
| 平均相互等级 | 0.626031 | 46 |
| 扩展平均互惠等级 | 0.427189 | 84 |
| 标准化折扣累积收益 | 0.714459 | 84 |
| 总体平均排名 | 71.33 |
达到最佳总体结果的配置(跨指标平均排名最高):
这种配置达到我们指标的以下分数:
| 公制 | 分数 | 排名(160个) |
|---|---|---|
| 平均相互等级 | 0.742735 | 7 |
| 扩展平均互惠等级 | 0.599379 | 9 |
| 标准化折扣累积收益 | 0.806476 | 1 |
| 总体平均排名 | 5.67 |
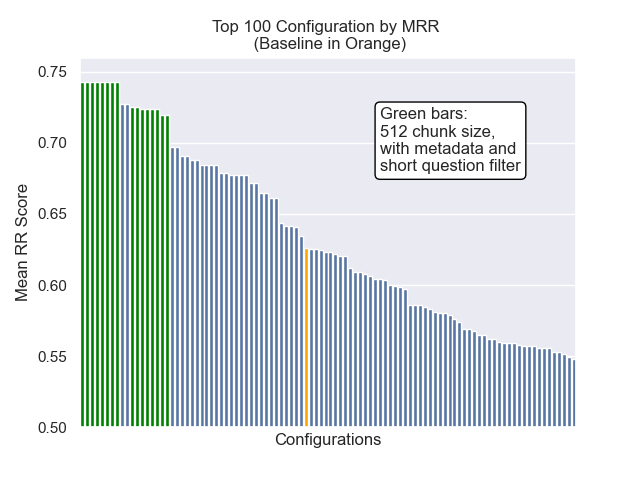
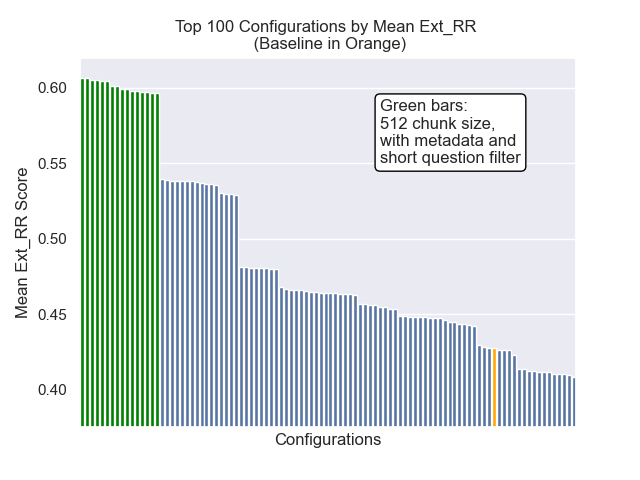
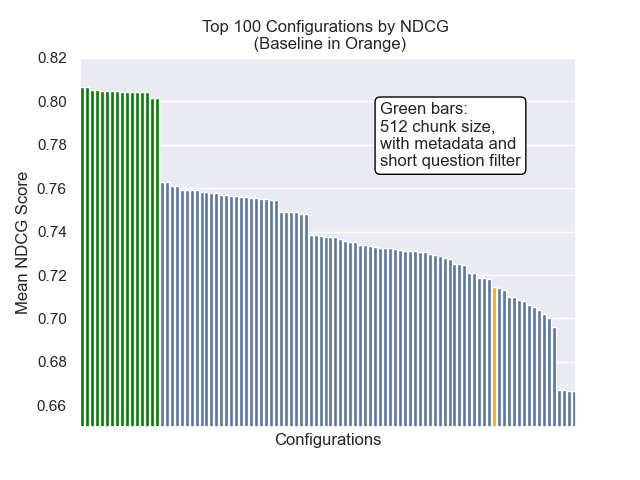
在下面,我们可以看到基线配置与顶部总体的相对位置。
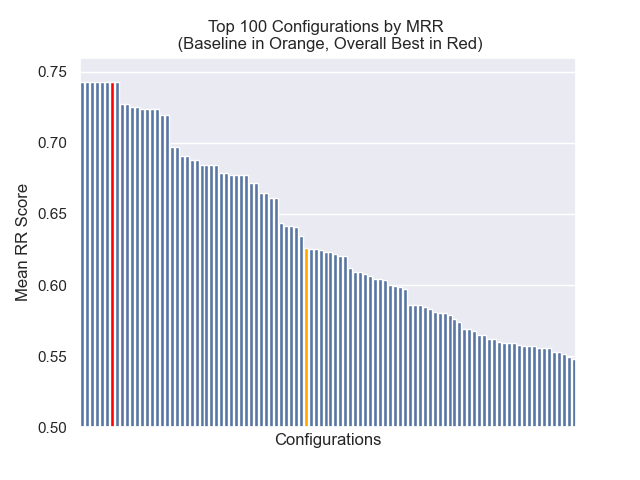
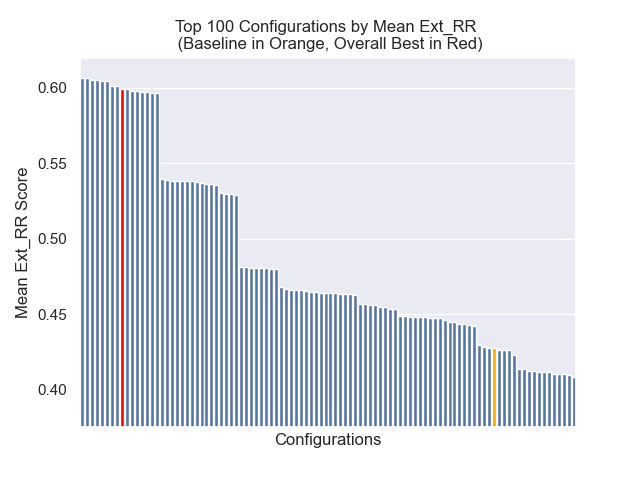
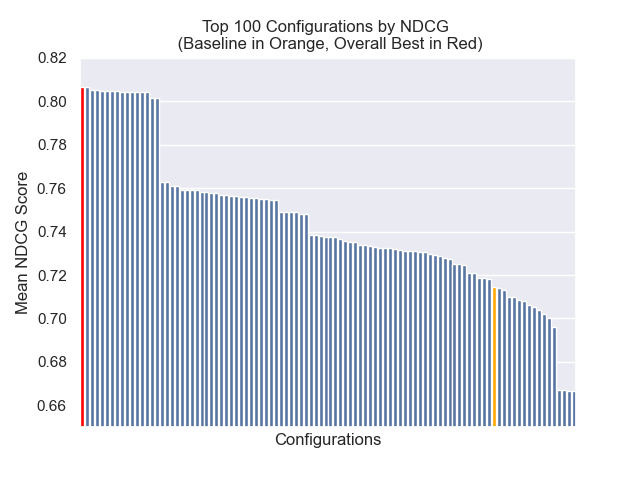
似乎减少的块大小对结果产生了负面影响。
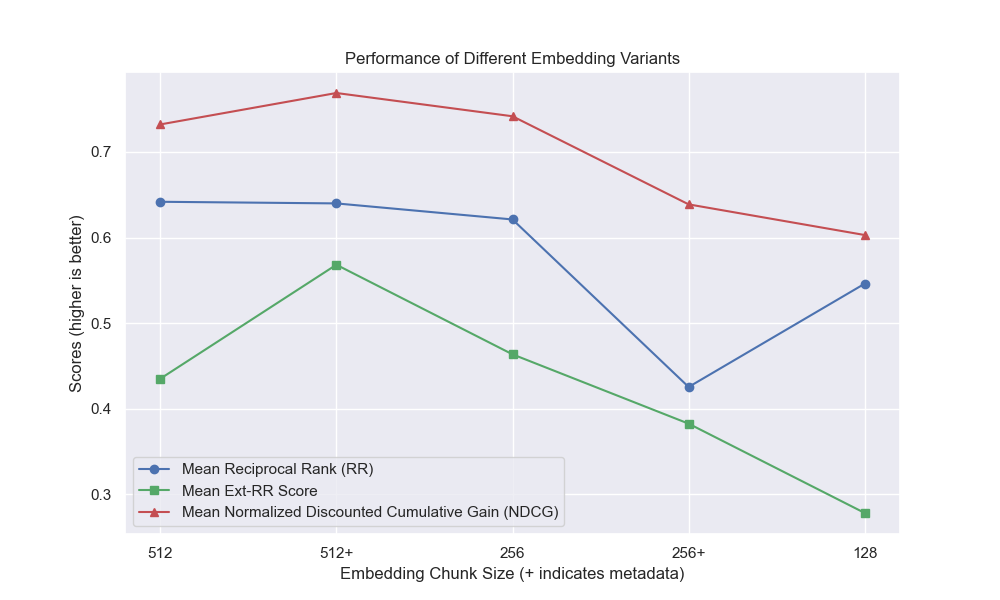
此外,无论其他高参数选择如何,在检索之前滤除简短的问题都会产生积极影响。
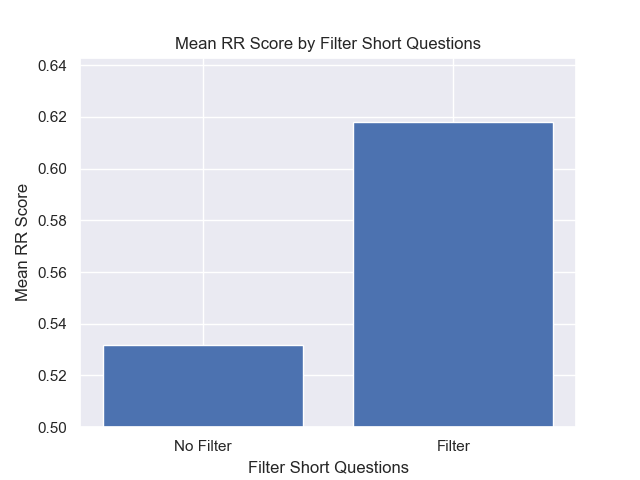
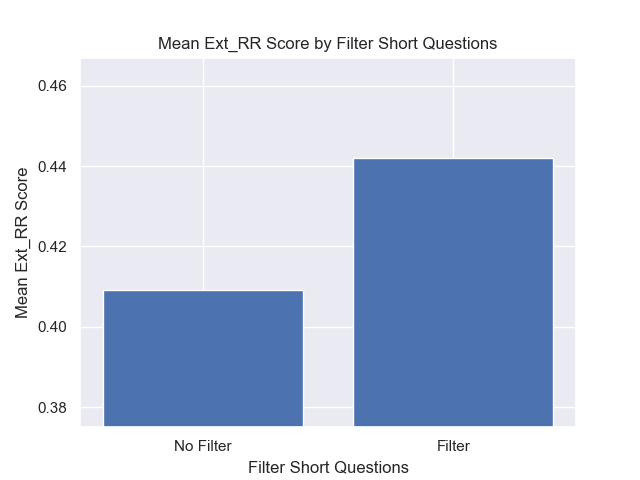
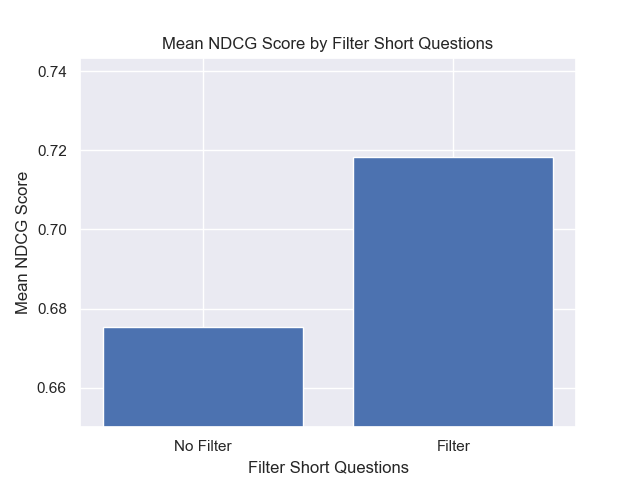
如果我们仅突出显示包含这些变体的那些配置(512个块大小,增加了元数据,并通过简短的问题进行过滤),我们会看到它们相对于其他配置的表现如何。
一些潜在的未来调查领域:


