erdos_paware
1.0.0
Este proyecto fue completado por Marcos Ortiz, Sayantan Roy, Karthik Prabhu, Kristina Knowles y Diptanil Roy, como parte del campamento de entrenamiento de aprendizaje profundo del Instituto Erdös (primavera, 2024).
Nuestro proyecto se detalla a continuación, y puede seguir los pasos principales a través de los cuadernos de demostración y los datos proporcionados en el directorio PAW_DEMO/.
Los primeros cuatro cuadernos caminan a través de una demostración utilizando un pequeño subconjunto de los datos. El último cuaderno proporcionó un resumen de nuestros resultados en todo el conjunto de datos.
Dada una consulta de usuario arbitraria y un conjunto de datos de contenido generado por humanos, cree un algoritmo para identificar y clasificar el contenido relevante en el conjunto de datos, de modo que el conjunto de coincidencias se pueda recuperar de manera rápida y precisa
Sabemos que la aplicación eventual para los resultados de nuestro proyecto es el uso en una tubería de generación acuática (RAG) de recuperación. Este reciente documento de encuesta, que describe el estado actual de RAG para modelos de idiomas grandes (LLM), ayudó a proporcionar una idea de qué herramientas podrían ser una buena opción para nuestra tarea y datos particulares.
Los principales pasos en el trapo son:
Los datos sin procesar que nos proporcionamos constan de 5,528,298 publicaciones de Reddit, de 34 subreddits. Estos datos se proporcionaron en un archivo de parquet, junto con un diccionario de datos.
Para este proyecto, estamos enfocados en los dos primeros pasos del proceso RAG: indexación y recuperación.
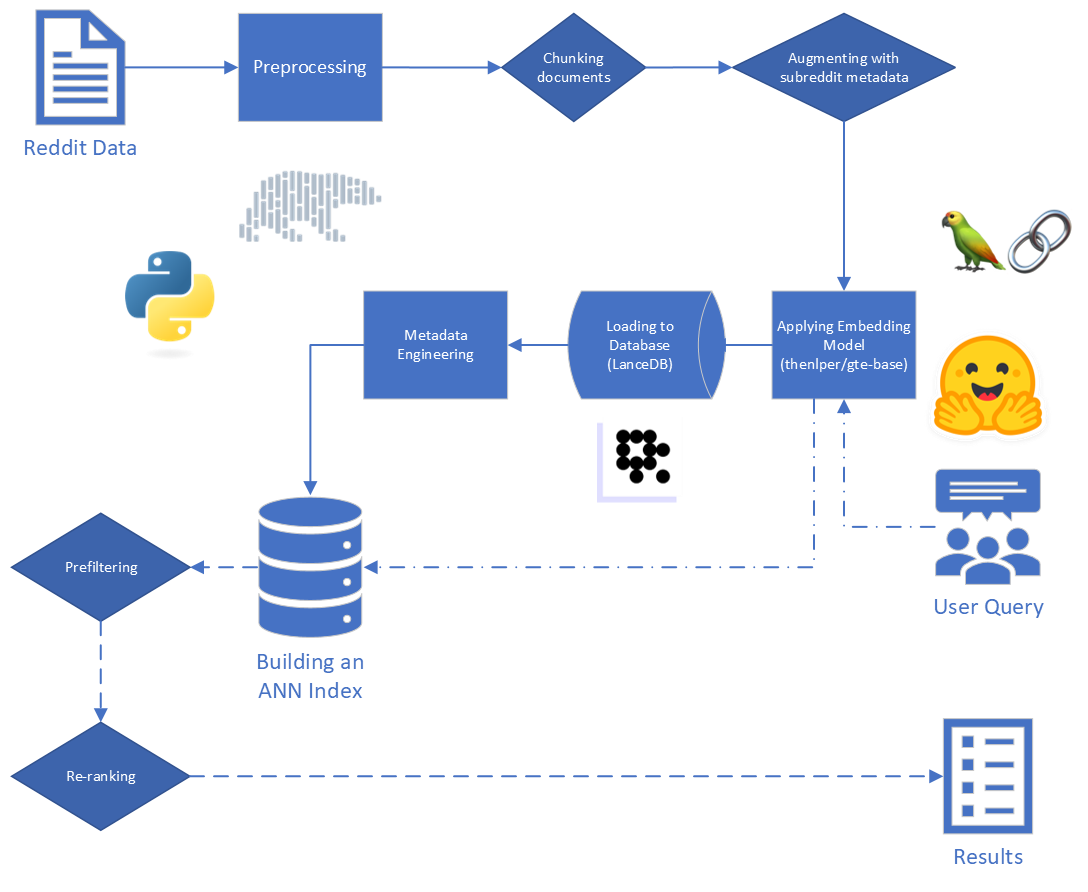
Comenzando con los datos sin procesar, realizamos una limpieza básica:
reddit_text de "[deleted]" o "removed" .reddit_text que tenían al menos 35 caracteres de largo, y aparecieron más de 7 veces. No queríamos dejar caer frases comunes más cortas de inmediato, en caso de que pudieran ser útiles más adelante (ver usando metadatos de ingeniería).reddit_text .reddit_title era un proxy para el reddit_text . Entonces, reemplazamos el vacío reddit_text con el reddit_title en estos casos. Utilizamos la versión base del modelo de incrustaciones de texto general (GTE), que se basa en el marco BERT. Documentación en Huggingface: enlace.
Elegimos este modelo porque parecía ser un tamaño razonable (0.22GB), es de código abierto y permite la incrustación de textos de hasta 512 tokens de longitud. Se desempeña especialmente bien en la agrupación y la recuperación en comparación con otros transformadores de oraciones de código abierto que tienen menos de 250 m parámetros: Link.
Además, parte de su capacitación se realizó utilizando datos Reddit, que se sumaron a su atractivo.
Consideramos la experimentación con otros modelos, pero debido al alto costo computacional de integrar el conjunto de datos con cada nuevo modelo, guardamos esta vía para el trabajo futuro.
Utilizamos el marco de transformadores de oraciones proporcionados por Sbert para implementar nuestro modelo de incrustación, así como para abrazar las herramientas de incrustación de la cara proporcionadas por Langchain
Durante la incrustación consideramos los siguientes parámetros:
chunk_size : la longitud máxima del texto para insertar como documentochunk_overlap : siempre que un documento sea necesario dividir en trozos, cuánto deben superponerseTambién experimentamos con la fijación de metadatos a trozos antes de la incrustación. Para hacer esto, simplemente agregamos el título de subreddit (o una aproximación) al comienzo de un fragmento de texto antes de incrustar. Por ejemplo, si hay un comentario en los FedExers que dice "Realmente me gusta trabajar aquí porque ...", entonces agregaríamos "FedEx" al comienzo de la fragmentación e incrustará "FedEx n n realmente me gusta trabajar aquí porque ..."
Nuestra intuición fue que, en los casos en que una publicación no incluye explícitamente el nombre de la empresa que están discutiendo, podríamos inferir esa información del subreddit y que esto podría empujar a ese vector más cerca de nuestra consulta. Por ejemplo, si preguntamos "¿por qué a los empleados les gusta trabajar en Disney?" y "¿Por qué a los empleados les gusta trabajar en FedEx?" Nuestra esperanza es que la adición de metadatos haga que sea más probable que el comentario anterior aparezca más alto en los resultados de la consulta de FedEx, y tal vez más baja en los resultados de la consulta de Disney.
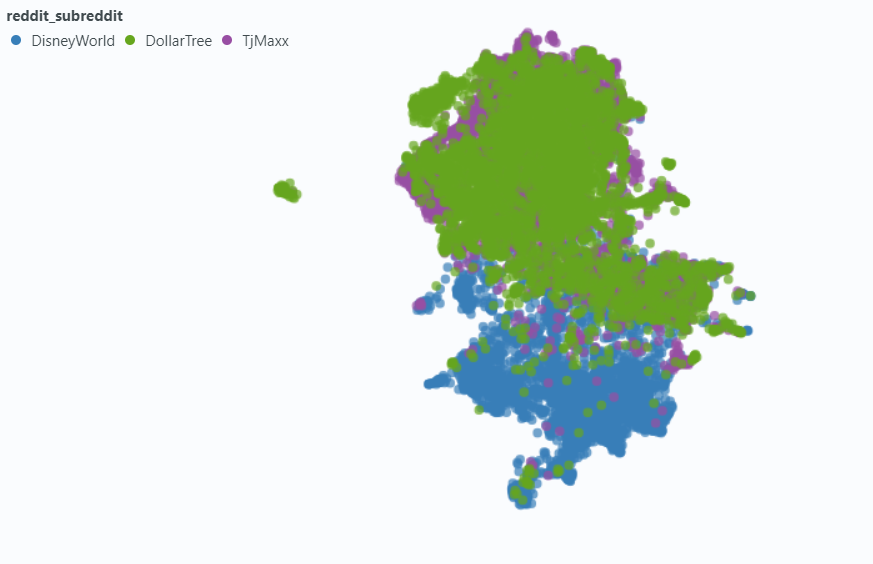
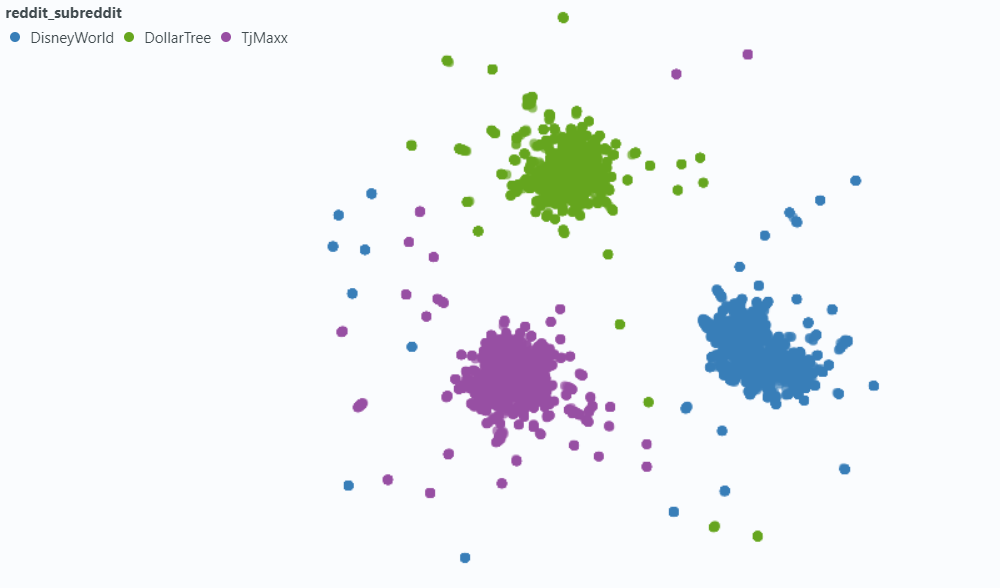
Utilizamos Spotlight para visualizar el efecto en una pequeña muestra de nuestros datos.
Incrustación sin metadatos:
Incrustación con metadatos:
Elegimos LancedB (enlace) para manejar las necesidades de nuestras bases de datos vectoriales. LancedB es una opción de código abierto, y proporciona integración tanto con Python como con los polares, en los cuales dependemos en gran medida.
LancedB proporciona una combinación de índice de archivos e invertido (FIV) y cuantización del producto (PQ) para construir un índice de vecinos más cercanos (ANN) aproximados.
Ambas parte del índice IVF-PQ se pueden ajustar ajustando los siguientes parámetros:
Arreglamos los parámetros de indexación y variamos los parámetros de recuperación. Sin embargo, si el tiempo lo permite, podríamos variar tanto para ver cómo se afectan los tiempos de recuperación y la precisión.
Además de los parámetros de consulta que están integrados en nuestro índice ANN, variamos otras variables pre-retrieves y post-retrievales para tratar de mejorar nuestros resultados generales.
Mientras etiquetamos los datos, notamos un tipo común de resultado "relacionado pero no relevante": un reddit_text que planteaba una pregunta similar a la consulta misma.
La mayoría de las veces, estos textos provienen de una submission (a diferencia de un comentario). Por lo tanto, una forma de intentar elevar los resultados más relevantes podría ser omitirlos de la búsqueda de vectores. Esto es bastante fácil, dado que esta información está contenida en nuestros metadatos originales.
Con menos frecuencia, pero aún lo suficiente como para ser notado, un comment exhibiría esta propiedad. Para tratar de frenar su impacto, diseñamos una columna de metadatos is_short_question para tratar de identificar todos los ejemplos reddit_text que plantearon preguntas cortas (y, por lo tanto, era poco probable que proporcionaran información útil para responder esas preguntas) para que también pudieran filtrarse antes de la búsqueda.
Para mejorar la clasificación de los resultados después de la recuperación, diseñamos algunos metadatos de adición que podrían permitirnos aprovechar la información proporcionada por el contenido de las respuestas.
Diseñamos dos tipos de metadatos:
sentiment de respuestas y,agree_distance (y disagree_distance ) para las respuestas. En el caso de reply_sentiment , utilizamos un modelo de procesamiento de lenguaje natural previamente capacitado llamado "Análisis MRM8488/Distilroberta-Finetuned-Financial-News-Sentiment-Analysis", para medir el tono emocional detrás de los textos. Este modelo nos ayudó a clasificar cada respuesta en categorías como positivo, neutral o negativo. Los puntajes de los sentimientos de todas las respuestas se agregaron para reflejar el sentimiento general hacia cada publicación original y los siguientes comentarios. La suposición subyacente aquí es que las publicaciones que generan respuestas predominantemente positivas probablemente sean constructivas e informativas, sirviendo así como un proxy para los endosos de los usuarios similares a los votos ascendentes en Reddit. Nuestras hipótesis fueron que una publicación con respuestas más positivas sería más probable que contenga información útil.
En el caso de agree_distance medimos la distancia entre cada reddit_text y un conjunto de "declaraciones de acuerdo". Luego, cada vez que una presentación o comentario tenía respuestas, agregamos top_reply_agree_distance y el avg_reply_agree_distance . Nuestra hipótesis fue que las publicaciones con respuestas que estaban más cerca de las declaraciones de "acuerdo" tendrían más probabilidades de contener información relevante. Del mismo modo, las publicaciones con respuestas que estaban más cerca de las declaraciones "en desacuerdo" sería menos probable que fueran relevantes.
Al volver a clasificar, los resultados con avg_reply_agree_distance más bajo se aumentaron más altos, los resultados con avg_reply_disagree_distance más bajos se tocaron más bajos.
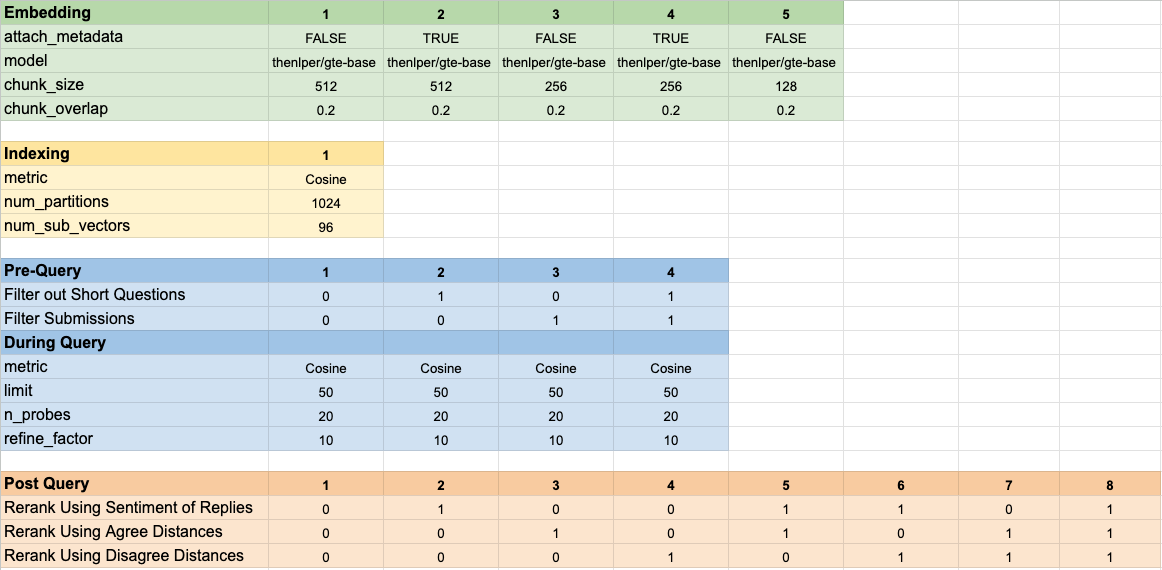
Probamos 160 configuraciones de modelo diferentes. Cada configuración incluía una opción de incrustación, una estrategia para filtrar las pruebas antes de realizar nuestra búsqueda vectorial y una estrategia para volver a clasificar los resultados que se recuperaron.
Estos hiper-parámetros se resumen en la imagen a continuación:
Teníamos dos objetivos principales que teníamos en mente al evaluar nuestros resultados:
Si bien el tiempo de recuperación es bastante fácil de medir, necesitábamos desarrollar algunas herramientas para medir nuestro progreso en la clasificación de resultados.
Para establecer una línea de base para evaluar la clasificación de resultados, etiquetamos manualmente un subconjunto de resultados para establecer una métrica inicial de relevancia. Para hacer esto, creamos dos consultas para cada uno de los trece conjuntos de datos en nuestro conjunto de entrenamiento, y etiquetamos los 20 mejores resultados recuperados para cada consulta. Los resultados fueron etiquetados como:
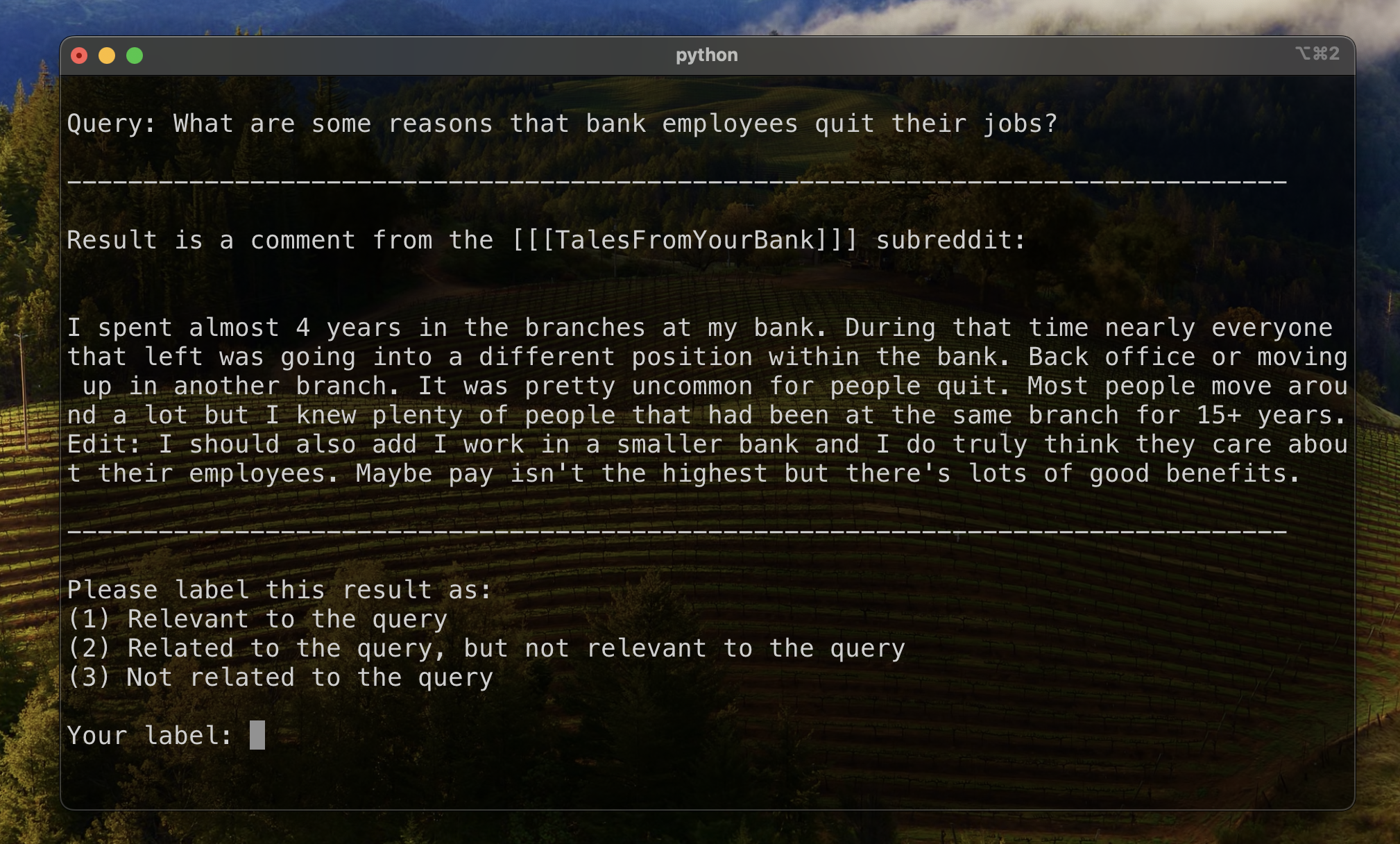
Para cada par de resultados de consulta, la etiqueta final se determinó mediante voto de pluralidad, con los lazos en incumplimiento a menos relevantes. Estos datos etiquetados manualmente se usaron para cuantificar los resultados.
Utilizamos tres métricas para los resultados de clasificación. Cada uno es una versión modificada de una métrica del sistema de recomendación, adaptada a nuestro caso de uso, donde no tenemos una verdad clara de tierra, o una clasificación establecida de resultados relevantes de la más relevante a menos relevante.
Esta métrica ofrece una puntuación que indica qué tan cerca aparece el primer resultado relevante conocido. Se logra un puntaje perfecto de 1 si el resultado principal de cada consulta es relevante.
Para calcular el rango recíproco para una consulta dada, aplicamos la siguiente fórmula:
En las aplicaciones estándar, hay un solo resultado conocido de "verdad terrestre". En nuestra aplicación modificada, aceptamos cualquier resultado relevante conocido como verdad terrestre.
Luego calculamos el promedio de estos puntajes en todas nuestras consultas estándar para llegar al rango recíproco medio.
Esta métrica ofrece una puntuación que indica cuántos de nuestro resultado relevante conocido aparecen cerca de la parte superior. Se logra una puntuación perfecta de 1 si todos los resultados relevantes conocidos aparecen como los principales resultados para todas las consultas (sin un resultado sin etiquetar que aparezca más alto que cualquier resultado relevante conocido).
Para calcular el rango recíproco extendido para una consulta dada, aplicamos la siguiente fórmula:
dónde
dónde
En las aplicaciones estándar, cada resultado relevante tiene su propio rango, y su contribución a la puntuación general tiene en cuenta este rango como su posición esperada en los resultados. En nuestra aplicación modificada, dimos la misma contribución a cualquier resultado relevante conocido que apareció por encima de la posición
Luego calculamos el promedio de estos puntajes en todas nuestras consultas estándar para llegar al rango recíproco medio.
La ganancia acumulada con descuento (DCG) a menudo se emplea como una métrica para evaluar el rendimiento de un motor de búsqueda, y mide la eficiencia del algoritmo para colocar resultados relevantes en la parte superior de la lista de recuperación. Para una lista de respuestas de longitud
dónde
Dado que la puntuación DCG depende en gran medida de la longitud de la lista de recuperación, debemos normalizarlo para que la puntuación sea consistente en todos los escenarios de recuperación de consultas con un número variable de resultados. El puntaje de ganancia acumulada con descuento normalizado (NDCG) en la posición
donde el
NDCG puede tomar el puntaje de relevancia ordinal (1 para altamente relevante, 2 para algo relevante, así). Modificamos el esquema de puntuación para nuestro caso, al convertir nuestras etiquetas humanas (1 relevantes, 2 relacionadas pero no relevantes, 3 no relacionadas) en un esquema de puntuación binario. Los resultados con la etiqueta humana = 1 recibieron una puntuación de relevancia = 1, y todo lo demás recibió un puntaje de relevancia de 0. Esto se hizo para garantizar que la mejor configuración, según lo dictado por el puntaje NDCG, solo debería devolver resultados altamente relevantes. Luego calculamos la puntuación NDCG de nuestras consultas estándar y las promedió para obtener la puntuación NDCG media de una configuración particular. Las puntuaciones DCG y las puntuaciones IDCG se calcularon mediante la configuración
dónde
Utilizamos los siguientes parámetros del modelo como nuestra línea de base para comparación:
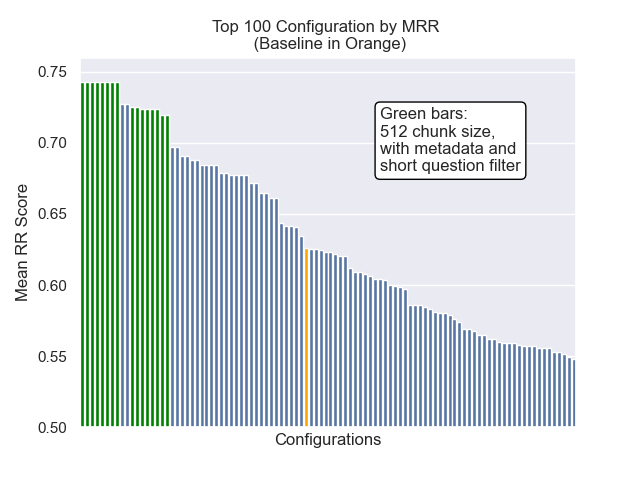
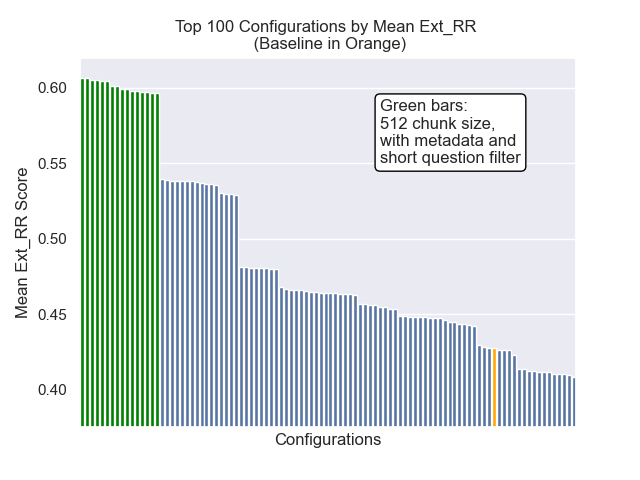
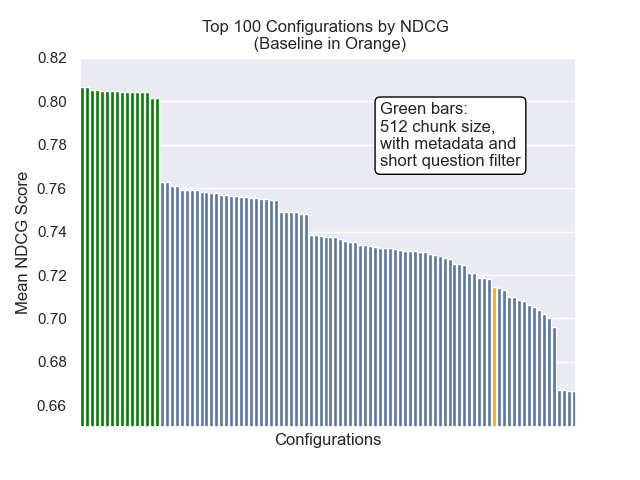
La configuración de línea de base logra los siguientes puntajes en nuestras métricas:
| Métrico | Puntaje | Rango (de 160) |
|---|---|---|
| Rango recíproco medio | 0.626031 | 46 |
| Rango recíproco medio extendido | 0.427189 | 84 |
| Ganancia acumulativa con descuento normalizada | 0.714459 | 84 |
| Rango general promedio | 71.33 |
La configuración que logró el mejor resultado general (rango promedio más alto en métricos):
Esta configuración logra los siguientes puntajes en nuestras métricas:
| Métrico | Puntaje | Rango (de 160) |
|---|---|---|
| Rango recíproco medio | 0.742735 | 7 |
| Rango recíproco medio extendido | 0.599379 | 9 |
| Ganancia acumulativa con descuento normalizada | 0.806476 | 1 |
| Rango general promedio | 5.67 |
A continuación, podemos ver la posición relativa de la configuración de línea de base en la parte superior general.
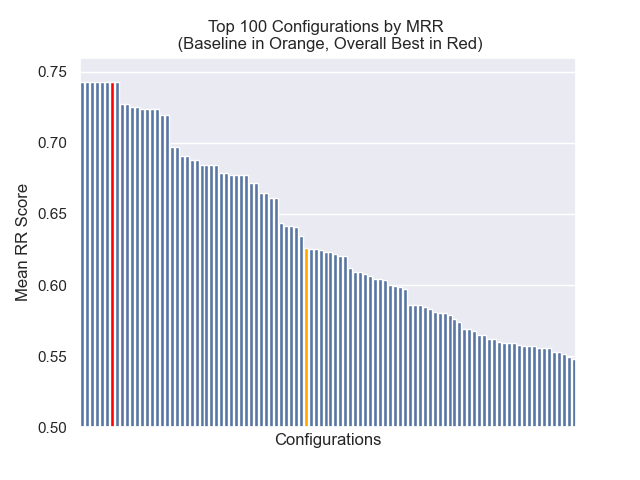
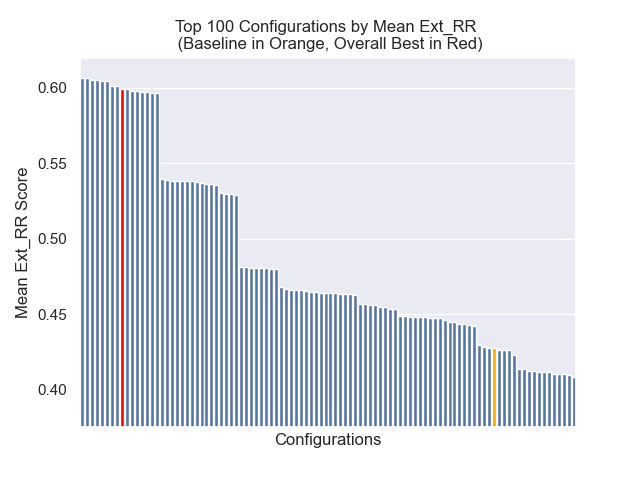
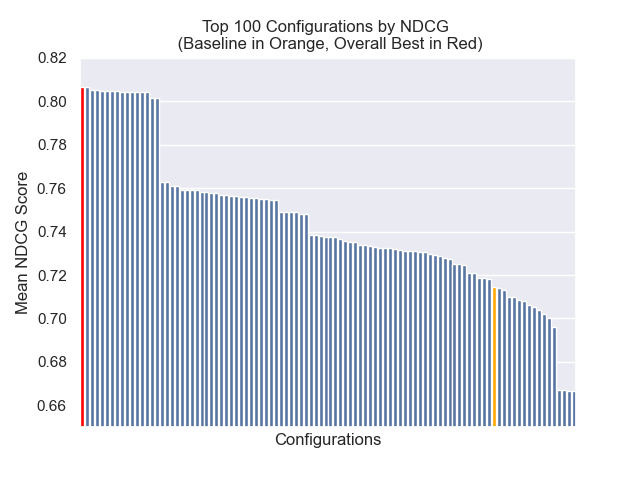
Parecía que la disminución del tamaño del fragmento tuvo un impacto generalmente negativo en los resultados.
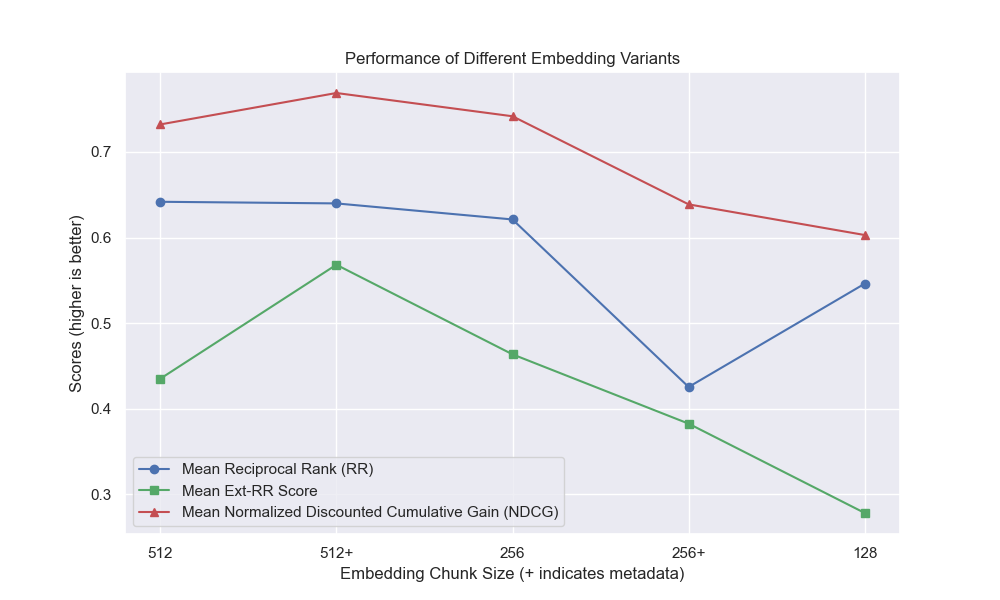
Además, filtrar preguntas breves antes de la recuperación tuvo un impacto positivo independientemente de otras opciones de hiperparameter.
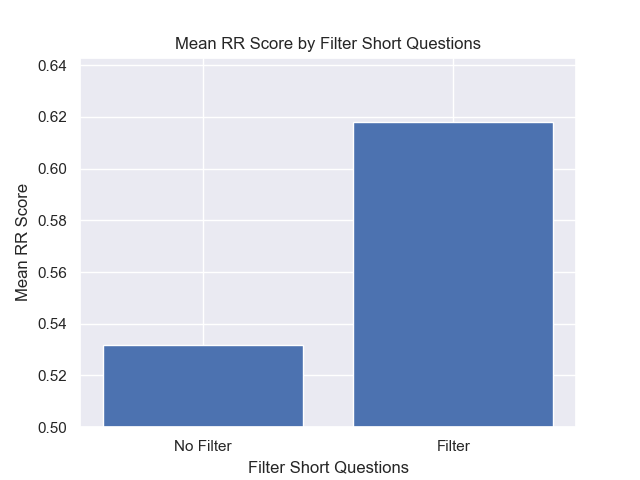
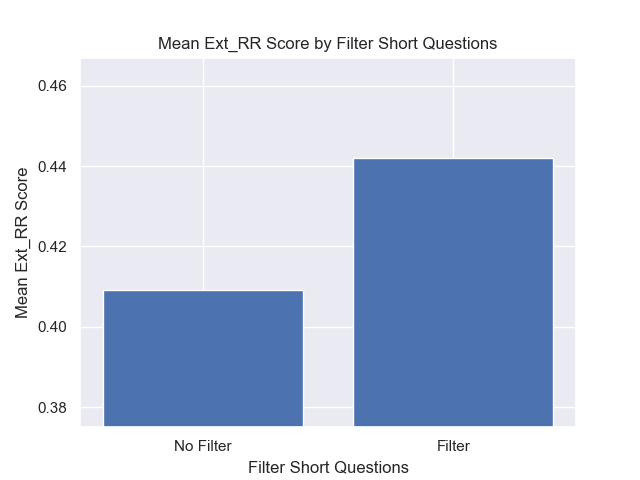
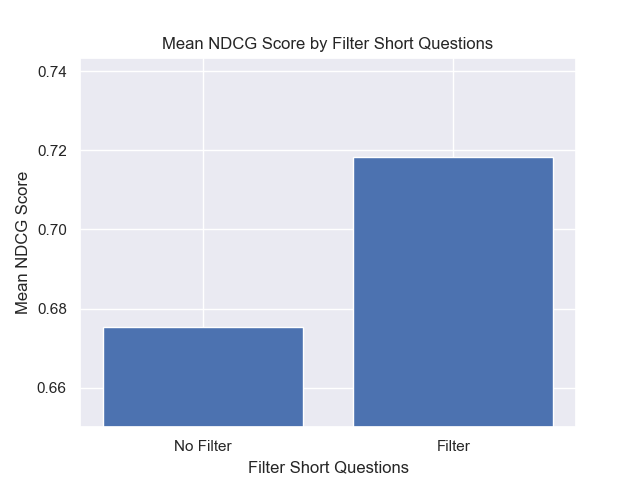
Si destacamos solo aquellas configuraciones que contienen estas variaciones juntas (tamaño de 512 fragmentos, con metadatos agregados y filtrado por preguntas cortas), vemos qué tan bien funcionan en relación con otras configuraciones.
Algunas áreas de potencial investigación futura:


