erdos_paware
1.0.0
이 프로젝트는 Erdös Institute Deep Learning Boot Camp (Spring, 2024)의 일환으로 Marcos Ortiz, Sayantan Roy, Karthik Prabhu, Kristina Knowles 및 Diptanil Roy가 완료했습니다.
우리의 프로젝트는 아래에 자세히 설명되어 있으며 PAW_DEMO/ 디렉토리에 제공된 데모 노트와 데이터를 통해 주요 단계를 따라갈 수 있습니다.
처음 4 개의 노트북은 데이터의 작은 부분 집합을 사용하여 데모를 진행합니다. 마지막 노트북은 전체 데이터 세트에 대한 결과 요약을 제공했습니다.
임의의 사용자 쿼리와 사람이 생성 한 컨텐츠 데이터 세트가 주어지면 데이터 세트에서 관련 컨텐츠를 식별하고 순위를 매기는 알고리즘을 구축하여 일치 세트를 빠르고 정확하게 검색 할 수 있습니다.
우리는 프로젝트 결과에 대한 최종 응용 프로그램이 검색된 세대 (RAG) 파이프 라인에 사용된다는 것을 알고 있습니다. LLMS (Lange Language Models)에 대한 현재의 래그 상태를 설명하는이 최근 설문 조사 논문은 특정 작업과 데이터에 어떤 도구가 적합 할 수 있는지에 대한 통찰력을 제공하는 데 도움이되었습니다.
Rag의 주요 단계는 다음과 같습니다.
미국에 제공된 원시 데이터는 34 개의 하위 구역에서 Reddit의 5,528,298 개의 게시물로 구성됩니다. 이 데이터는 데이터 사전과 함께 파크 파일로 제공되었습니다.
이 프로젝트의 경우, 우리는 RAG 프로세스의 첫 두 단계 인 색인 및 검색에 중점을 둡니다.
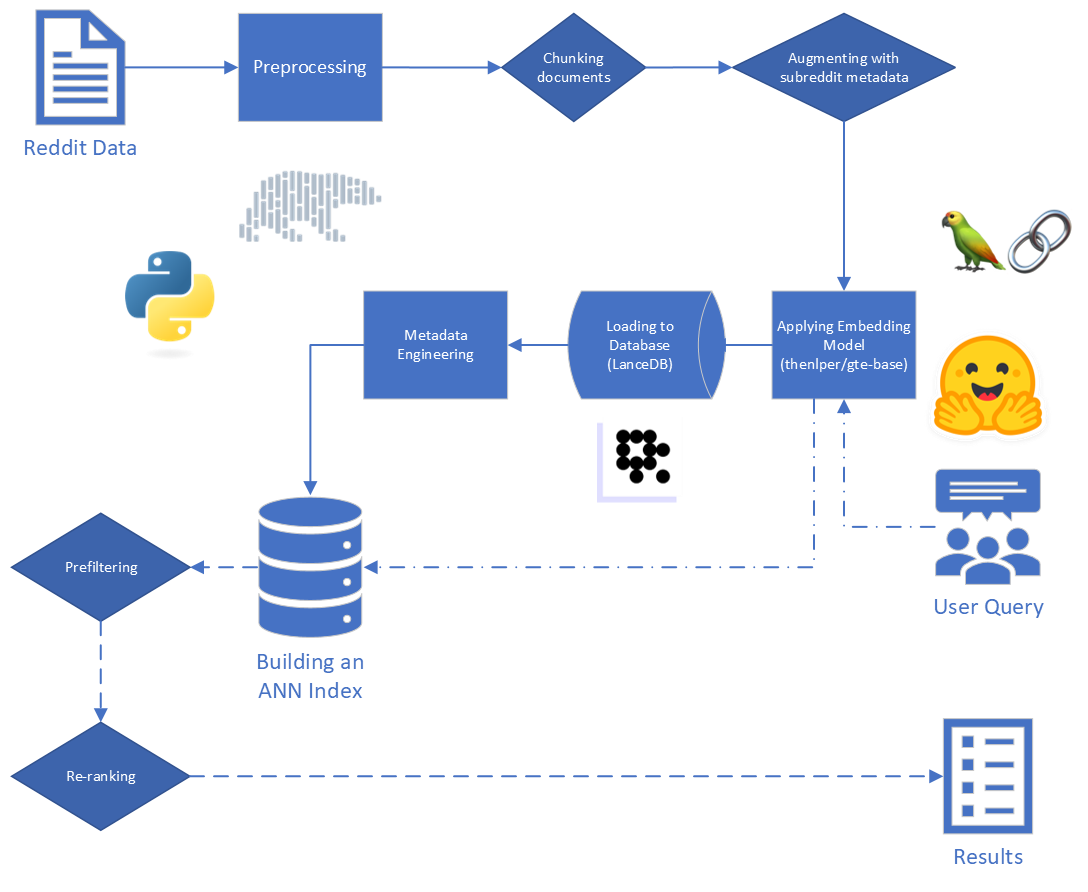
원시 데이터부터 시작하여 몇 가지 기본 청소를 수행했습니다.
"[deleted]" 또는 "removed" 의 reddit_text 값으로 줄을 떨어 뜨 렸습니다.reddit_text 값이 35 자 이상인 행을 필터링하여 7 번 이상 나타났습니다. 나중에 유용 할 수있는 경우 (엔지니어링 된 메타 데이터 사용 참조) 공통 문구가 더 짧은 공통 문구를 즉시 삭제하고 싶지 않았습니다.reddit_text 값을 처리했습니다.reddit_title reddit_text 의 프록시임을 나타 냈습니다. 그래서 우리는 빈 reddit_text 이 인스턴스에서 reddit_title 로 교체했습니다. 우리는 Bert 프레임 워크를 기반으로하는 GTE (General Text Embeddings) 모델의 기본 버전을 사용했습니다. Huggingface에 대한 문서 : 링크.
우리는이 모델이 합리적인 크기 (0.22GB) 인 것처럼 보이고 오픈 소스이며 최대 512 개의 토큰까지 텍스트를 포함시킬 수 있기 때문에이 모델을 선택했습니다. 250m 미만의 매개 변수를 가진 다른 오픈 소스 문장 변압기에 비해 클러스터링 및 검색에서 특히 잘 수행됩니다.
또한 교육의 일부는 Reddit 데이터를 사용하여 수행되었으며, 이는 호소에 추가되었습니다.
우리는 다른 모델에 대한 실험을 고려했지만 각 새로운 모델마다 데이터 세트를 포함시키는 계산 비용이 높기 때문에 향후 작업을 위해이 길을 절약합니다.
우리는 SBERT가 제공 한 문장 변압기 프레임 워크를 사용하여 임베딩 모델을 구현하고 Langchain이 제공하는 포옹 얼굴 임베딩 도구를 구현합니다.
임베딩 중에 우리는 다음과 같은 매개 변수를 고려했습니다.
chunk_size : 문서로 포함 할 텍스트의 최대 길이chunk_overlap : 문서를 청크로 나누어야 할 때마다 얼마나 많은 겹쳐야합니까?또한 임베딩하기 전에 메타 데이터를 청크에 부착하는 것을 실험했습니다. 이를 위해, 우리는 간단히 텍스트 청크 시작에 하위 레드 제목 (또는 근사)을 추가하기 전에 간단히 추가합니다. 예를 들어, FedExers에“나는 여기서 일하는 것을 정말로 좋아합니다 ...”라고 말하는 의견이 있다면 청크의 시작에“FedEx”를 추가하고“FedEx n n 여기서 일하는 것을 정말 좋아합니다 ...”
우리의 직관은 게시물에 그들이 논의하고있는 회사의 이름을 명시 적으로 포함하지 않는 경우, 우리는 하위 레드의 정보를 추론 할 수 있으며, 이것이 우리의 쿼리에 더 가까이 다가 갈 수 있다는 것을 추론 할 수 있습니다. 예를 들어,“직원들이 디즈니에서 일하는 것을 좋아하는 이유는 무엇입니까?”라고 묻는다면 그리고“직원들은 왜 FedEx에서 일하는 것을 좋아합니까?” 우리의 희망은 메타 데이터를 추가하면 위의 의견이 FedEx 쿼리 결과에서 더 높을 가능성이 높아지고 디즈니 쿼리의 결과가 낮을 가능성이 높아질 수 있습니다.
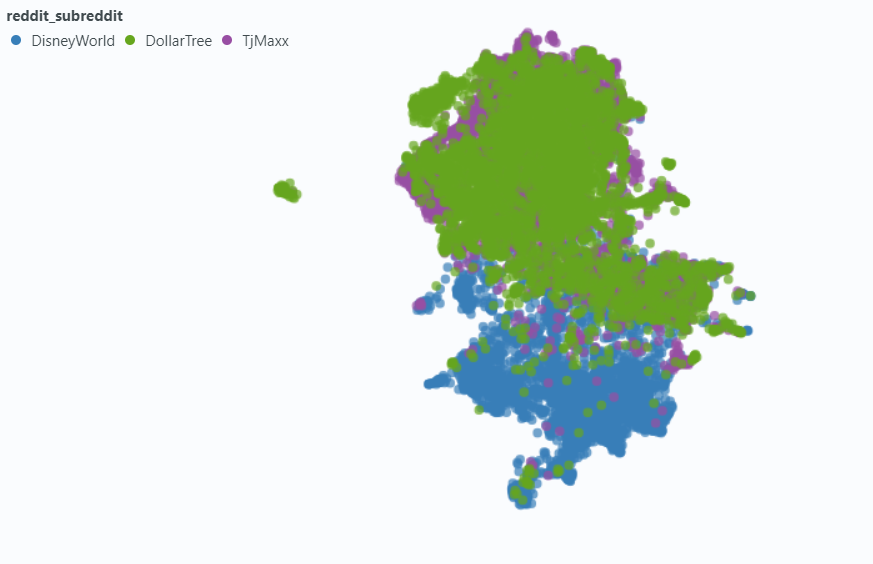
우리는 스포트라이트를 사용하여 작은 데이터 샘플에 미치는 영향을 시각화했습니다.
메타 데이터없이 포함 :
메타 데이터 포함 :
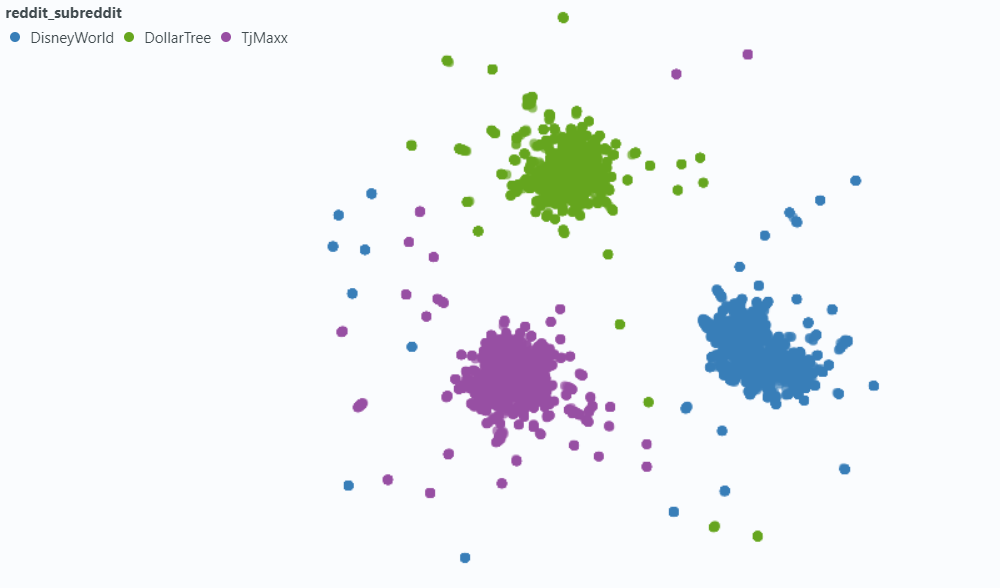
우리는 벡터 데이터베이스 요구를 처리하기 위해 LANCEB (LINK)를 선택했습니다. LANCEDB는 오픈 소스 옵션이며 파이썬 및 폴라와 통합을 제공합니다.
LANCEDB는 대략적인 이웃 (ANN) 인덱스를 구축하기 위해 파일 색인 (IVF)과 제품 양자화 (PQ)의 조합을 제공합니다.
IVF-PQ 인덱스의 두 부분은 다음 매개 변수를 조정하여 미세 조정할 수 있습니다.
인덱싱 매개 변수를 수정하고 검색 매개 변수를 변경했습니다. 그러나 시간이 허용되면 검색 시간과 정확성이 어떻게 영향을 받는지 볼 수 있습니다.
Ann Index에 내장 된 쿼리 매개 변수 외에도 전체 결과를 시도하고 향상시키기 위해 다른 재조정 및 후 레트로 리의 사후 변수가 다양했습니다.
데이터를 라벨링하는 동안 일반적인 유형의 "관련이지만 관련이 없음"결과를 발견했습니다. 쿼리 자체와 유사한 질문을 제기 한 reddit_text .
대부분의 경우,이 텍스트는 submission 에서 나왔습니다 (의견과는 달리). 따라서보다 관련성이 높은 결과를 시도하고 향상시키는 한 가지 방법은 벡터 검색에서이를 생략하는 것입니다. 이 정보가 원래 메타 데이터에 포함되어 있다는 점을 감안할 때 이것은 충분히 쉽습니다.
덜 빈번하지만 여전히 눈에 띄기에 충분하지만 comment 이 속성을 보여줄 것입니다. 그들의 영향을 시도하고 억제하기 위해, 우리는 메타 데이터 열 is_short_question 설계하여 짧은 질문을 제기 한 모든 reddit_text 예제 (따라서 해당 질문에 답하기위한 유용한 정보를 제공 할 가능성이 없음)를 검색하기 전에 필터링 할 수있었습니다.
검색 후 결과 순위를 향상시키기 위해 회신 내용에 의해 제공된 정보를 활용할 수있는 일부 지식 메타 데이터를 설계했습니다.
우리는 두 가지 유형의 메타 데이터를 설계했습니다.
sentiment 의 척도 및agree_distance (및 disagree_distance )의 척도. reply_sentiment 의 경우, 우리는 텍스트 뒤에 감정적 인 어조를 측정하기 위해 "MRM8488/DISTILROBERTA-FINETUNED-FINETUNED-FINETUNED-FINETUNED-FINETUNED-FINETUNED-FINETUNED-FINETUNED-FINETUNED-FINETUNED-FINETUNED-FINETUNED-FINETUNED-FINECIAL-NEWS-SENTIMENT-Analysis"라는 미리 훈련 된 자연 언어 처리 모델을 활용했습니다. 이 모델을 사용하면 각 답변을 양수, 중립 또는 부정적인 범주로 분류하는 데 도움이되었습니다. 그런 다음 모든 답장의 감정 점수를 집계하여 각 원본 게시물에 대한 전체 감정과 다음 주석을 반영했습니다. 여기서 근본적인 가정은 주로 긍정적 인 답장을 생성하는 게시물이 건설적이고 유익 할 가능성이 높으므로 Reddit의 Upvotes와 유사한 사용자 보증에 대한 대리 역할을한다는 것입니다. 우리의 가설은 더 긍정적 인 답변이있는 게시물에 유용한 정보가 포함될 가능성이 더 높다는 것이 었습니다.
agree_distance 의 경우 각 reddit_text 와 "동의 진술"세트 사이의 거리를 측정했습니다. 그런 다음 제출 또는 댓글이 답장 될 때마다 top_reply_agree_distance 와 avg_reply_agree_distance 추가했습니다. 우리의 가설은 "동의"진술에 더 가까운 답변이있는 게시물이 관련 정보를 포함 할 가능성이 더 높다는 것입니다. 마찬가지로, "동의하지 않는"진술에 더 가까운 답변이있는 게시물은 관련성이 낮을 것입니다.
재평가 할 때 avg_reply_agree_distance 가 낮은 결과가 높아 졌을 때 avg_reply_disagree_distance 가 낮은 결과가 낮아졌습니다.
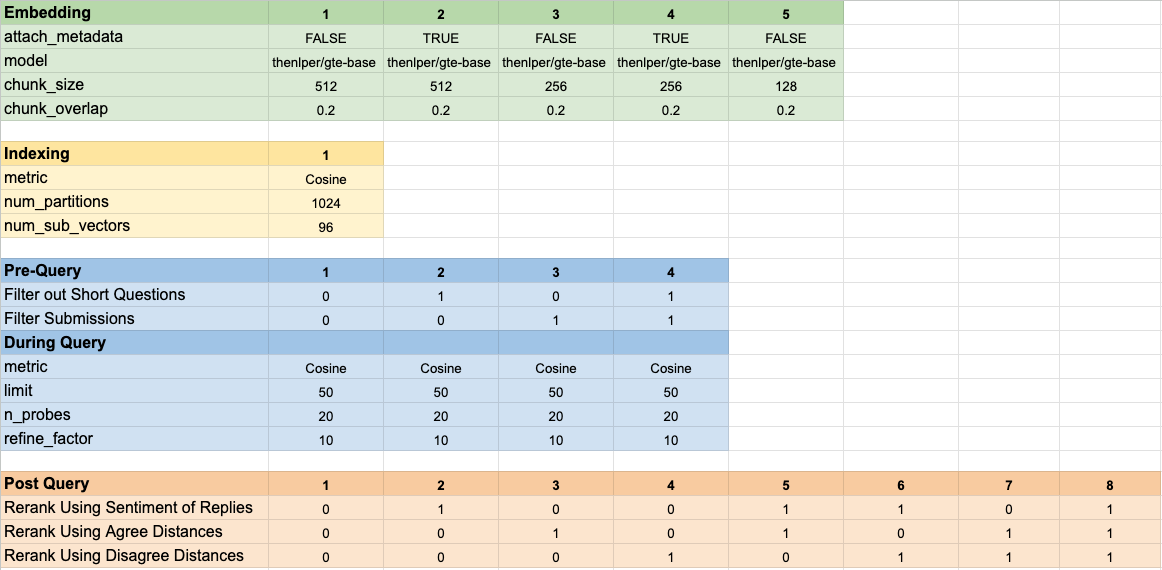
160 개의 다른 모델 구성을 테스트했습니다. 각 구성에는 임베딩 선택, 벡터 검색을 수행하기 전에 테스트를 필터링하기위한 전략 및 검색된 결과를 다시 평가하기위한 전략이 포함되었습니다.
이 하이퍼 파라미터는 아래 이미지에 요약되어 있습니다.
결과를 평가할 때 염두에 두는 두 가지 주요 목표가있었습니다.
검색 시간은 측정하기에 쉽지만 결과 순위에 대한 진행 상황을 측정하기위한 몇 가지 도구를 개발해야했습니다.
결과 순위를 평가하기위한 기준을 설정하기 위해 결과의 하위 집합을 수동으로 레이블링하여 초기 관련성을 설정했습니다. 이를 위해 교육 세트에서 13 개의 데이터 세트 각각에 대해 두 개의 쿼리를 만들었고 각 쿼리에 대해 검색된 상위 20 개 결과에 레이블을 지정했습니다. 결과는 다음과 같이 표시되었습니다.
각각의 쿼리-등록 쌍에 대해, 최종 레이블은 복수 투표에 의해 결정되었으며, 관계는 덜 관련성이 없다. 이 수동으로 레이블이 붙은 데이터를 사용하여 결과를 정량화했습니다.
순위 순위를 높이기 위해 세 가지 메트릭을 사용했습니다. 각각은 권장 시스템 메트릭의 수정 된 버전으로, 명확한 근거 진실이 없거나 가장 관련성이 가장 높은 관련 결과의 확립 된 순위가없는 사용 사례에 적합합니다.
이 메트릭은 첫 번째 알려진 관련 결과가 어떻게 나타나는지를 나타내는 점수를 제공합니다. 모든 쿼리의 최고 결과가 관련이있는 경우 완벽한 점수 1이 달성됩니다.
주어진 쿼리의 상호 순위를 계산하기 위해 다음 공식을 적용했습니다.
표준 응용 프로그램에는 단일 알려진 "지상 진실"결과가 있습니다. 수정 된 응용 프로그램에서 우리는 알려진 관련 결과를 근거 진실로 받아 들였습니다.
그런 다음 모든 표준 쿼리 에서이 점수의 평균을 계산하여 평균 상호 순위에 도달했습니다.
이 메트릭은 알려진 관련 결과가 상단 근처에 몇 개가 나타나는지를 나타내는 점수를 제공합니다. 알려진 모든 관련 결과가 모든 쿼리의 최고 결과로 나타나면 완벽한 점수 1이 달성됩니다 (알려진 관련 결과보다 더 높은 표지되지 않은 결과는 보이지 않음).
주어진 쿼리의 확장 된 상호 순위를 계산하기 위해 다음 공식을 적용했습니다.
어디
어디
표준 응용 프로그램에서 각 관련 결과는 자체 순위를 가지며 전체 점수에 대한 기여는이 순위가 결과에서 예상 위치로 고려됩니다. 수정 된 응용 프로그램에서 우리는 위에 나타난 알려진 관련 결과에 동일한 기여를했습니다.
그런 다음 모든 표준 쿼리 에서이 점수의 평균을 계산하여 평균 상호 순위에 도달했습니다.
할인 된 누적 게인 (DCG)은 종종 검색 엔진의 성능을 평가하기위한 메트릭으로 사용되며, 관련 결과를 검색 목록의 상단에 배치하는 데있어 알고리즘의 효율성을 측정합니다. 길이의 응답 목록
어디
DCG 점수는 검색 목록의 길이에 크게 의존하기 때문에 다양한 결과가있는 쿼리 검색 시나리오에서 점수가 일관되도록 정규화해야합니다. 정규화 된 할인 된 누적 이득 (NDCG) 점수는 위치에서 점수입니다
어디에
NDCG는 서수 관련성 점수를 얻을 수 있습니다 (1은 1, 2는 다소 관련성이 높습니다. 우리는 인간 라벨 (1- 관련, 2 관련이지만 관련이없고 3-8 인 관련)을 이진 스코어링 체계로 변환하여 사례의 스코어링 체계를 수정합니다. Human Label = 1을 가진 결과는 관련성 점수 = 1이 주어졌으며, 다른 모든 것은 관련성 점수가 0이되었습니다. NDCG 점수에 의해 지시 된대로 최상의 구성이 고도로 관련된 결과를 반환해야합니다. 그런 다음 표준 쿼리의 NDCG 점수를 계산하고 평균화하여 특정 구성의 평균 NDCG 점수를 얻었습니다. DCG 점수 및 IDCG 점수는 설정에 의해 계산되었습니다.
어디
우리는 다음 모델 매개 변수를 비교를위한 기준으로 사용했습니다.
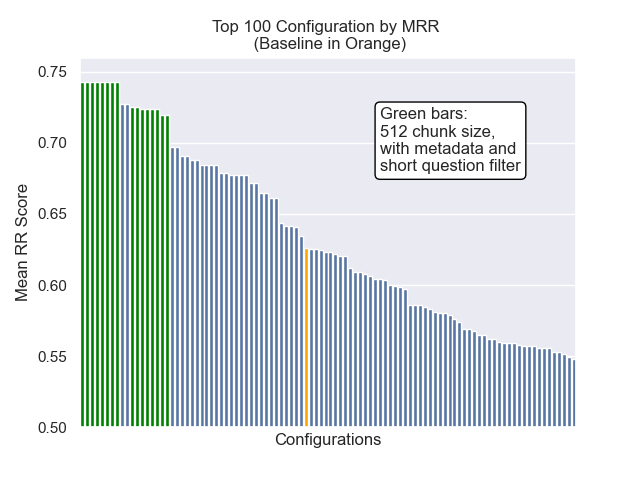
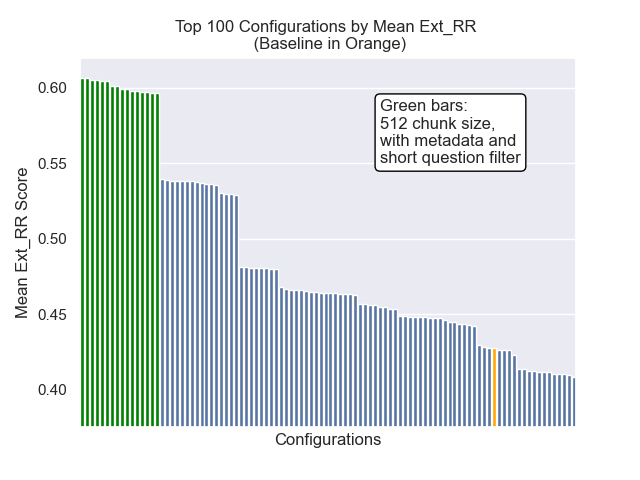
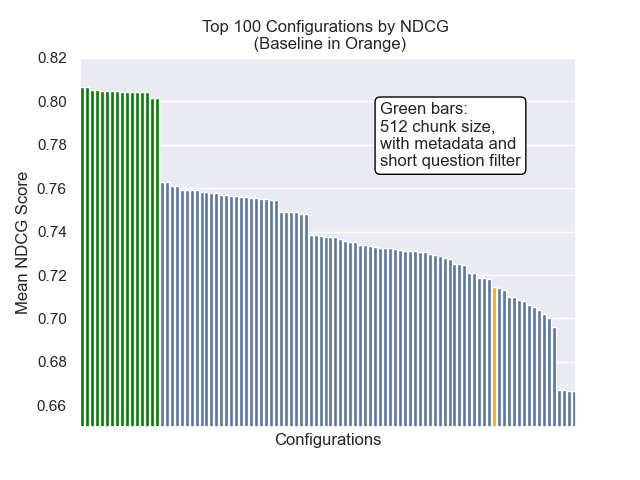
기준 구성은 메트릭스에서 다음 점수를 달성합니다.
| 메트릭 | 점수 | 순위 (160 년) |
|---|---|---|
| 평균 상호 순위 | 0.626031 | 46 |
| 연장 된 평균 상호 순위 | 0.427189 | 84 |
| 정규화 된 할인 누적 이득 | 0.714459 | 84 |
| 평균 전체 순위 | 71.33 |
최고의 전체 결과를 달성 한 구성 (메트릭스에서 가장 높은 평균 순위) :
이 구성은 메트릭스에서 다음 점수를 달성합니다.
| 메트릭 | 점수 | 순위 (160 년) |
|---|---|---|
| 평균 상호 순위 | 0.742735 | 7 |
| 연장 된 평균 상호 순위 | 0.599379 | 9 |
| 정규화 된 할인 누적 이득 | 0.806476 | 1 |
| 평균 전체 순위 | 5.67 |
아래에서는 기준 구성의 상대적 위치를 전체적으로 상단에 볼 수 있습니다.
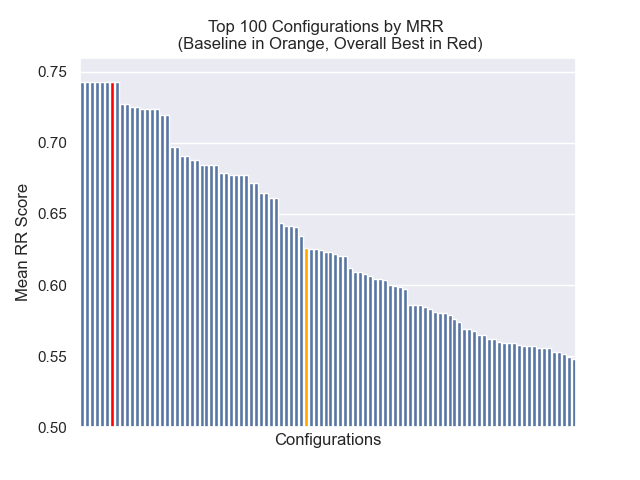
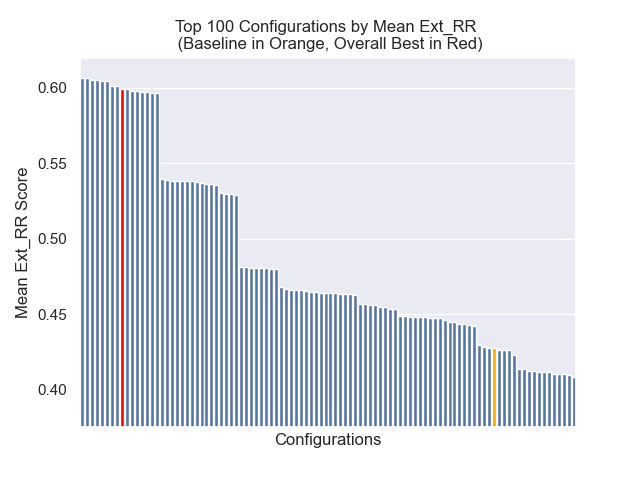
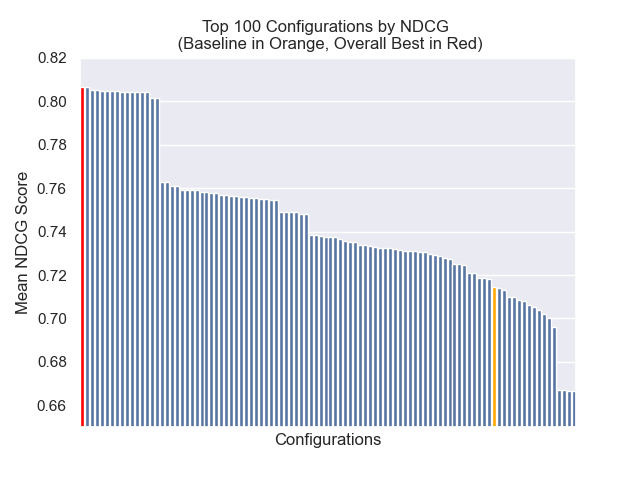
청크 크기 감소는 일반적으로 결과에 부정적인 영향을 미치는 것으로 나타났습니다.
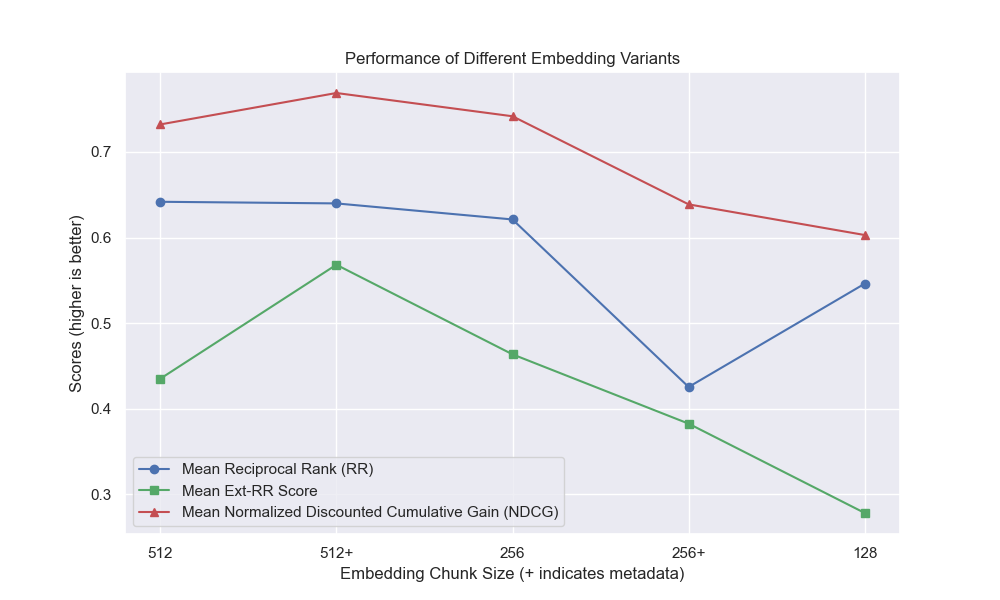
또한 검색 전에 짧은 질문을 필터링하는 것은 다른 하이퍼 파라미터 선택에 관계없이 긍정적 인 영향을 미쳤습니다.
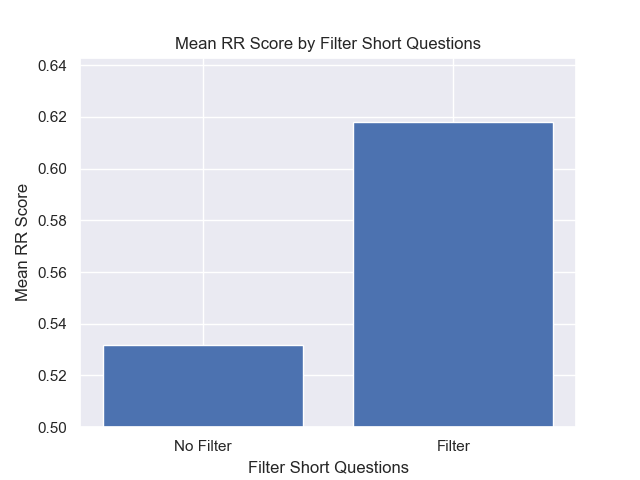
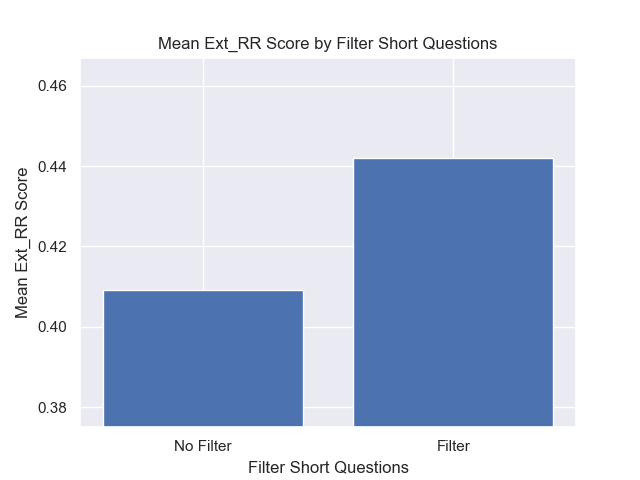
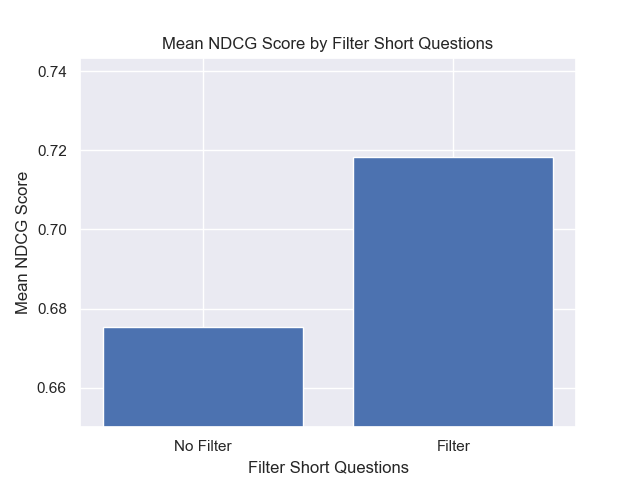
이러한 변형을 함께 포함하는 구성 (512 청크 크기, 메타 데이터가 추가 및 짧은 질문으로 필터링)을 강조하면 다른 구성과 비교하여 얼마나 잘 수행하는지 알 수 있습니다.
잠재적 인 향후 조사의 일부 영역 :


