erdos_paware
1.0.0
Этот проект был завершен Маркосом Ортисом, Саяном Роем, Картиком Прабху, Кристиной Ноулз и Диптанилом Роем, в рамках учебного лагеря Института Эрдоса (весна, 2024).
Наш проект подробно описан ниже, и вы можете выполнить вместе с основными шагами через демонстрационные ноутбуки и данные, представленные в каталоге PAW_DEMO/.
Первые четыре ноутбука проходят демонстрацию, используя небольшое подмножество данных. Последний ноутбук предоставил краткое изложение наших результатов по всему набору данных.
Учитывая произвольный пользовательский запрос и набор данных сгенерированного человеком контента, создайте алгоритм для выявления и ранжирования соответствующего контента в наборе данных, так что набор соответствия можно получить быстро и точно извлекать
Мы знаем, что возможным применением для результатов нашего проекта является использование в конвейере по поиску-аугментированию (RAG). Этот недавний документ для опроса, описывающий текущее состояние тряпки для крупных языковых моделей (LLMS), помогло дать некоторое представление о том, какие инструменты могут подходить для нашей конкретной задачи и данных.
Основные шаги в тряпке:
Необработанные данные, предоставленные для США, состоит из 5528 298 постов из Reddit, из 34 субреддитов. Эти данные были предоставлены в паркете, а также словарь данных.
Для этого проекта мы сосредоточены на первых двух этапах процесса Rag: индексация и поиск.
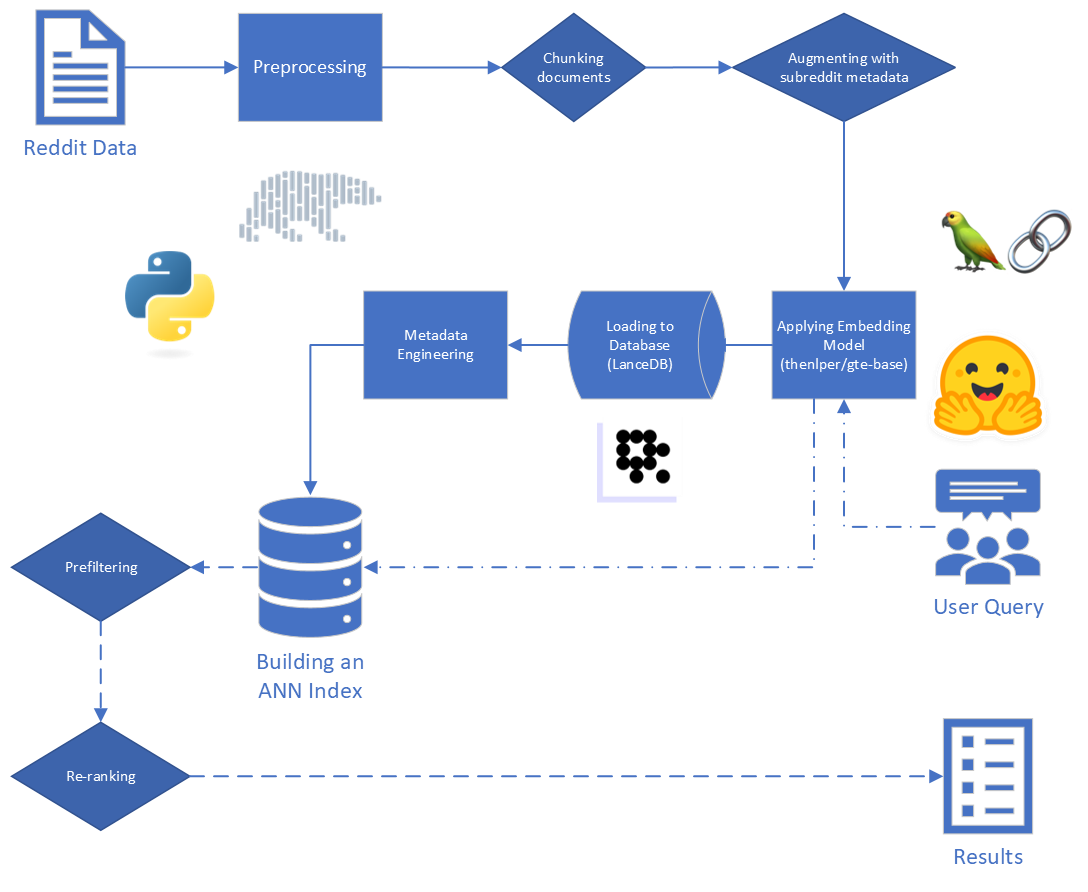
Начиная с необработанных данных, мы выполнили некоторую базовую очистку:
reddit_text "[deleted]" или "removed" .reddit_text , которые были не менее 35 символов, и появились более 7 раз. Мы не хотели немедленно отбрасывать более короткие общие фразы, если они могут быть полезны позже (см. Использование инженерных метаданных).reddit_text .reddit_title был прокси для reddit_text . Итак, мы заменили пустой reddit_text на reddit_title в этих случаях. Мы использовали базовую версию модели общего текста (GTE), которая основана на структуре BERT. Документация по Huggingface: ссылка.
Мы выбрали эту модель, потому что она, казалось, была разумным размером (0,22 ГБ), она является открытым исходным кодом, и она позволяет внедрять тексты до 512 токенов в длину. Он особенно хорошо работает в кластеризации и поиске по сравнению с другими трансформаторами предложений с открытым исходным кодом, которые имеют менее 250 м. Параметров: ссылка.
Более того, часть его обучения была выполнена с использованием данных Reddit, которые добавили к его привлекательности.
Мы рассмотрели эксперименты с другими моделями, но из -за высокой вычислительной стоимости внедрения набора данных в каждую новую модель мы сохраняем этот путь для будущей работы.
Мы используем структуру трансформаторов предложений, предоставленную Sbert для реализации нашей модели встраивания, а также обнимающих инструментов встраивания лица, предоставленных Langchain
Во время внедрения мы рассмотрели следующие параметры:
chunk_size : максимальная длина текста для встраивания в качестве документаchunk_overlap : всякий раз, когда документ должен был быть разбит на куски, сколько они должны перекрыватьсяМы также экспериментировали с прикреплением метаданных к кусочкам перед внедрением. Для этого мы просто добавляем заголовок SubredDit (или приближение) к началу текстового куски перед внедрением. Например, если в FedExers есть комментарий, в котором говорится: «Мне очень нравится работать здесь, потому что ...», тогда мы бы добавили «FedEx» в начало чанка и внедряют «FedEx n n, мне очень нравится работать здесь, потому что ...»
Наша интуиция состояла в том, что в тех случаях, когда пост явно не включает название компании, которую они обсуждают, мы могли бы сделать вывод этой информации из SubredDit и что это может подтолкнуть этот вектор более ближайший к нашему запросу. Например, если мы спрашиваем: «Почему сотрудники любят работать в Disney?» и «Почему сотрудникам нравится работать в FedEx?» Мы надеемся, что добавление метаданных повышает вероятность того, что вышеупомянутый комментарий проявляется выше в результатах для запроса FedEx и, возможно, ниже в результатах для запроса Disney.
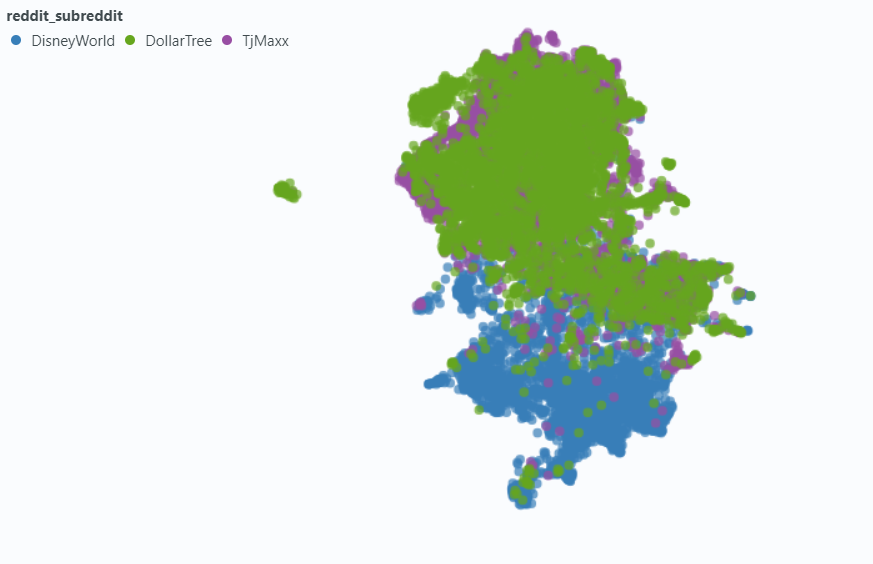
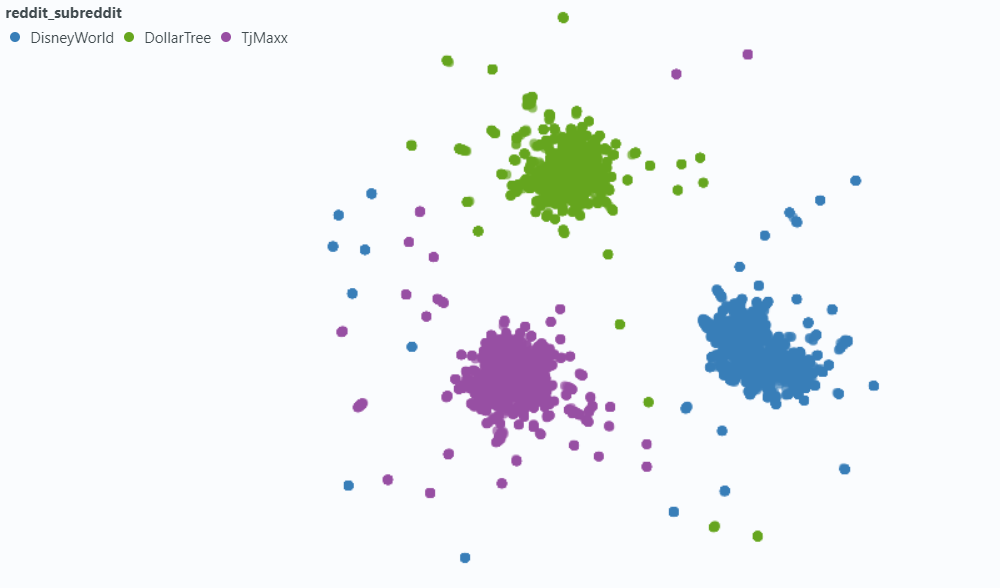
Мы использовали Spotlight, чтобы визуализировать влияние на небольшую выборку наших данных.
Внедрение без метаданных:
Внедрение в метаданные:
Мы выбрали LANCEDB (ссылку) для решения наших потребностей в векторной базе данных. LancedB является опцией с открытым исходным кодом, и он обеспечивает интеграцию как с Python, так и с полярами, на которых мы в значительной степени зависим.
LANCEDB предоставляет комбинацию и инвертированного индекса файлов (ЭКО) и квантования продукта (PQ) для создания приблизительного индекса ближайших соседей (ANN).
Обе часть индекса ЭКФ-PQ можно точно настроить путем настройки следующих параметров:
Мы исправили параметры индексации и варьировали параметры поиска. Хотя, если время разрешено, мы могли бы различаться, чтобы увидеть, как повлияют время поиска и точность.
Помимо параметров запроса, которые встроены в наш индекс ANN, мы изменяли другие предварительные и пост-протекальные переменные, чтобы попытаться улучшить наши общие результаты.
Во время маркировки данных мы заметили общий тип «связанного, но не релевантного» результата: reddit_text , который поставил вопрос, похожий на сам запрос.
Большую часть времени эти тексты происходили из -за submission (в отличие от комментария). Таким образом, одним из способов попытаться поднять более актуальные результаты, чтобы опустить их из векторного поиска. Это достаточно просто, учитывая, что эта информация содержится в наших оригинальных метаданных.
Реже, но все еще достаточно, чтобы его заметили, comment будет демонстрировать это свойство. Чтобы попытаться обуздать их влияние, мы разработали столбец метаданных is_short_question чтобы попытаться определить все примеры reddit_text , которые задавали короткие вопросы (и, следовательно, вряд ли предоставили полезную информацию для ответа на эти вопросы), чтобы их также могли отфильтровать перед поиском.
Чтобы улучшить рейтинг результатов после извлечения, мы разработали некоторые природные метаданные, которые могли бы позволить нам использовать информацию, предоставленную содержанием ответов.
Мы спроектировали два типа метаданных:
sentiment ответов и,agree_distance (и disagree_distance ) для ответов. В случае reply_sentiment мы использовали предварительно обученную модель обработки естественного языка под названием «MRM8488/DistilRoberta-FineTuned-Financial-News-Sentiment-анализ», чтобы оценить эмоциональный тонус за текстами. Эта модель помогла нам классифицировать каждый ответ по таким категориям, как положительный, нейтральный или отрицательный. Оценки настроений всех ответов были затем агрегированы, чтобы отразить общее мнение о каждом оригинальном сообщении и следующие комментарии. Основное предположение здесь заключается в том, что посты, генерирующие преимущественно положительные ответы, вероятно, будут конструктивными и информативными, тем самым служащих прокси для одобрений пользователей, аналогичных проведениям в Reddit. Наши гипотезы состояли в том, что пост с более положительными ответами будет с большей вероятностью содержать полезную информацию.
В случае agree_distance мы измерили расстояние между каждым reddit_text и набором «согласных операторов». Затем, когда в представлении или комментарии были ответы, мы добавляли top_reply_agree_distance и avg_reply_agree_distance . Наша гипотеза заключалась в том, что посты с ответами, которые были ближе к заявлениям «согласны», с большей вероятностью будут содержать соответствующую информацию. Точно так же сообщения с ответами, которые были ближе к «не согласным» заявлениям, будут менее вероятно, будут актуальны.
При повторной оценке результаты с более низким avg_reply_agree_distance были увеличены выше, результаты с более низким avg_reply_disagree_distance были увеличены ниже.
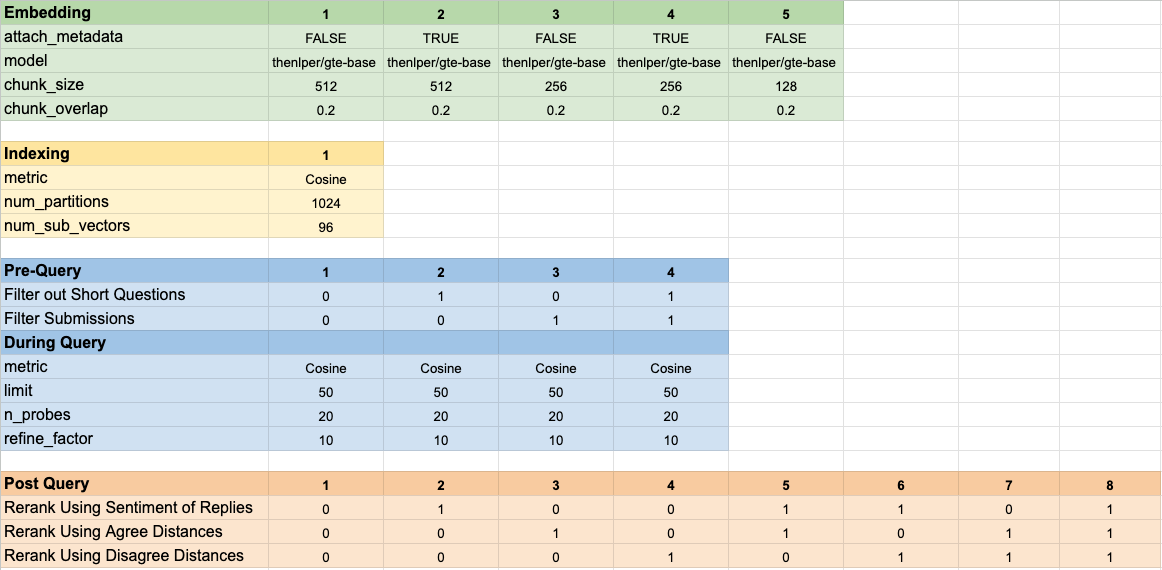
Мы протестировали 160 различных конфигураций модели. Каждая конфигурация включала выбор внедрения, стратегию фильтрации тестов перед выполнением нашего векторного поиска, а также стратегию для повторного ранжирования полученных результатов.
Эти гиперпараметры суммированы на изображении ниже:
У нас было две основные цели, которые мы имели в виду при оценке наших результатов:
Хотя время поиска достаточно просто для измерения, нам нужно было разработать некоторые инструменты для измерения нашего прогресса в рейтинге результатов.
Чтобы установить базовую линию для оценки ранжирования результатов, мы вручную назвали подмножество результатов, чтобы установить первоначальный показатель актуальности. Для этого мы создали два запроса для каждого из тринадцати наборов данных в нашем учебном наборе и назвали 20 лучших результатов, полученных для каждого запроса. Результаты были помечены как:
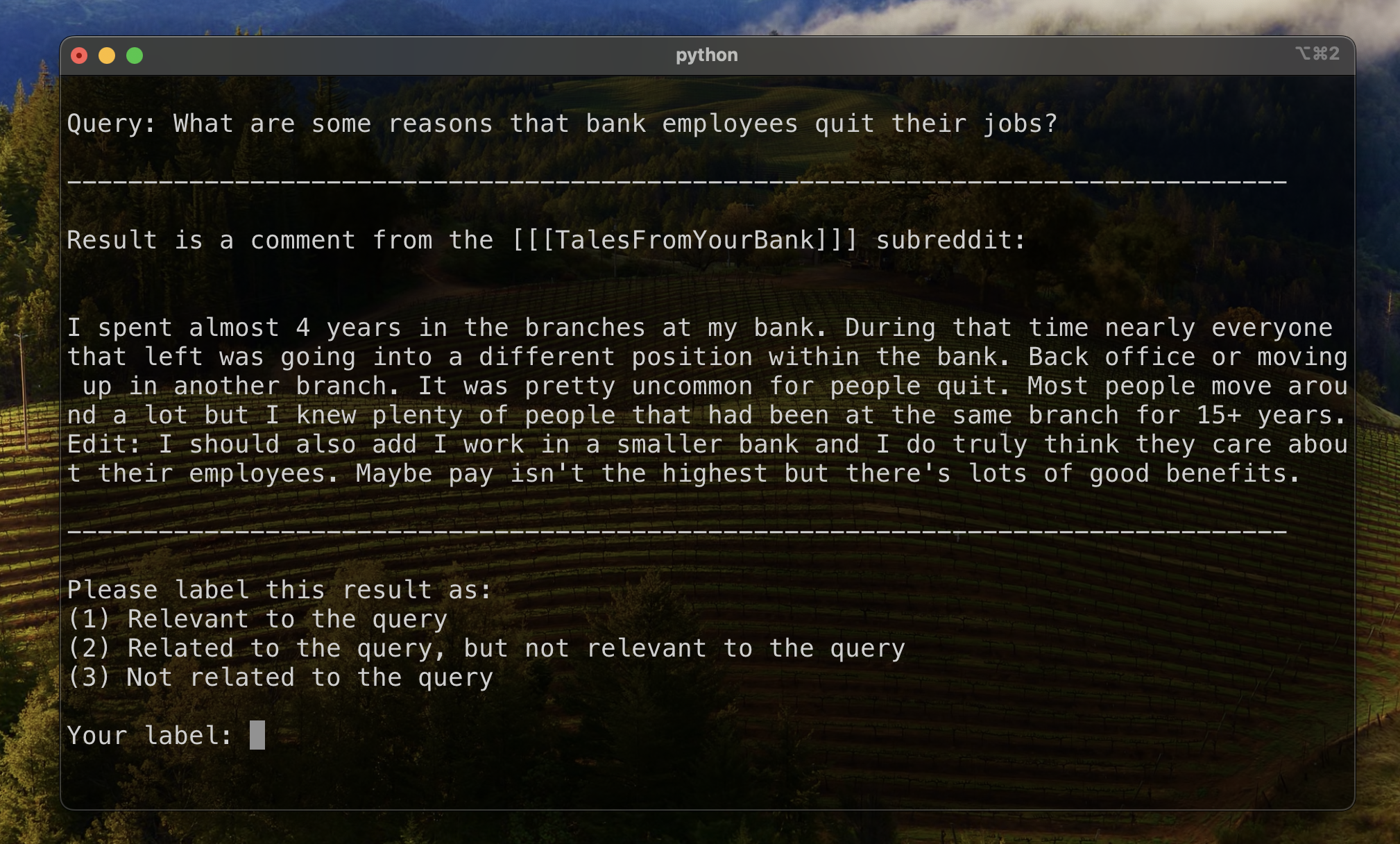
Для каждой пары-запросов, окончательная этикетка была определена голосованием множества, при этом связывания не выполняли менее актуальные. Эти данные вручную меченые данные использовались для количественной оценки результатов.
Мы использовали три показателя для результатов ранжирования. Каждый из них представляет собой модифицированную версию метрики рекомендательной системы, адаптированную к нашему варианту использования, когда у нас нет четкой основы истины или устоявшегося ранжирования соответствующих результатов, наиболее соответствующих наименее актуальным.
Этот показатель дает оценку, которая указывает, насколько близко к вершине появляется первый известный соответствующий результат. Идеальный балл 1 достигается, если актуален верхний результат каждого запроса.
Чтобы вычислить взаимный ранг для данного запроса, мы применили следующую формулу:
В стандартных приложениях существует единственный известный результат «основной правды». В нашем модифицированном заявлении мы приняли любой известный соответствующий результат в качестве основной истины.
Затем мы вычислили среднее из этих баллов по всем нашим стандартным запросам, чтобы достичь среднего взаимного ранга.
Этот показатель дает оценку, которая указывает, сколько из наших известных соответствующих результатов появляется вверху. Идеальная оценка 1 достигается, если все известные соответствующие результаты появляются в качестве лучших результатов для всех запросов (без нематборенных результатов, показанных выше, чем любой известный соответствующий результат.)
Чтобы вычислить расширенный взаимный ранг для данного запроса, мы применили следующую формулу:
где
где
В стандартных приложениях каждый соответствующий результат имеет свой собственный ранг, и его вклад в общий балл учитывает этот ранг в качестве ожидаемой позиции в результатах. В нашем модифицированном приложении мы внесли такой же вклад в любой известный соответствующий результат, который появился выше.
Затем мы вычислили среднее из этих баллов по всем нашим стандартным запросам, чтобы достичь среднего взаимного ранга.
Совокупный дисконтированный усиление (DCG) часто используется в качестве метрики для оценки эффективности поисковой системы и измеряет эффективность алгоритма в размещении соответствующих результатов в верхней части списка поиска. Для списка ответов длины
где
Поскольку оценка DCG сильно зависит от длины списка поиска, нам необходимо нормализовать его так, чтобы оценка была последовательной между сценариями поиска запросов с переменным количеством результатов. Нормализованный совокупный совокупный балл (NDCG) в позиции
где
NDCG может получить оценку порядкового актуальности (1 для очень актуального, 2 для несколько актуального, так далее). Мы изменяем схему оценки нашего случая, преобразуя наши человеческие этикетки (1 релевантные, связанные с 2, но не релевантными, 3-не связанные) в схему бинарной оценки. Результаты с человеческой меткой = 1 получили оценку актуальности = 1, а все остальное получило оценку актуальности 0. Это было сделано, чтобы гарантировать, что наилучшая конфигурация, диктуя показателем NDCG, должна только возвращать очень актуальные результаты. Затем мы вычислили оценку NDCG наших стандартных запросов и усреднили их, чтобы получить среднюю оценку NDCG конкретной конфигурации. Оценки DCG и оценки IDCG были рассчитаны путем настройки
где
Мы использовали следующие параметры модели в качестве нашей базовой линии для сравнения:
Базовая конфигурация достигает следующих результатов по нашим метрикам:
| Показатель | Счет | Ранг (из 160) |
|---|---|---|
| Среднее взаимное звание | 0,626031 | 46 |
| Расширенное среднее взаимное звание | 0,427189 | 84 |
| Нормализованный совокупный кумулятивный прирост | 0,714459 | 84 |
| Средний общий рейтинг | 71.33 |
Конфигурация, которая достигла наилучшего общего результата (самый высокий средний ранг по метрикам):
Эта конфигурация достигает следующих результатов в наших метриках:
| Показатель | Счет | Ранг (из 160) |
|---|---|---|
| Среднее взаимное звание | 0,742735 | 7 |
| Расширенное среднее взаимное звание | 0,599379 | 9 |
| Нормализованный совокупный кумулятивный прирост | 0,806476 | 1 |
| Средний общий рейтинг | 5.67 |
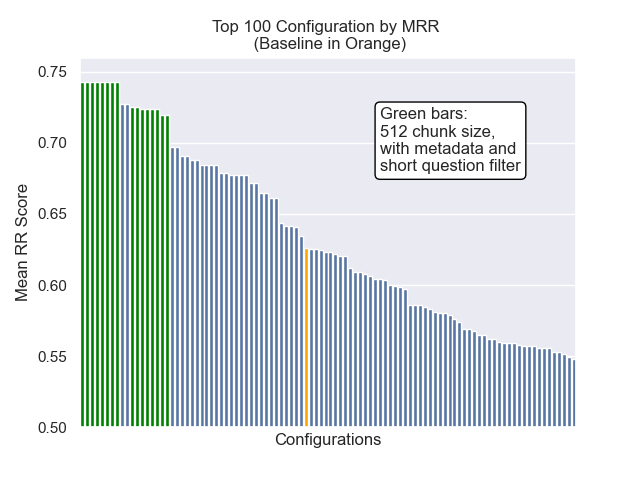
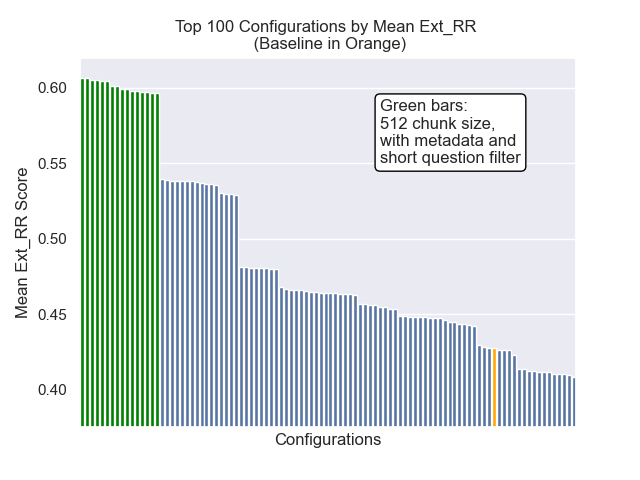
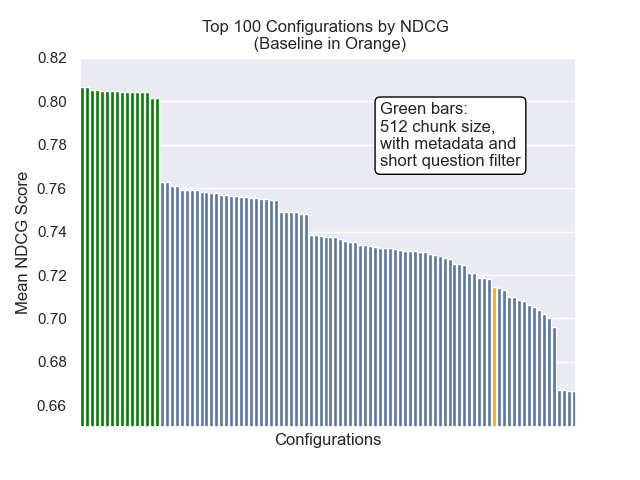
Ниже мы можем увидеть относительное положение базовой конфигурации к вершине в целом.
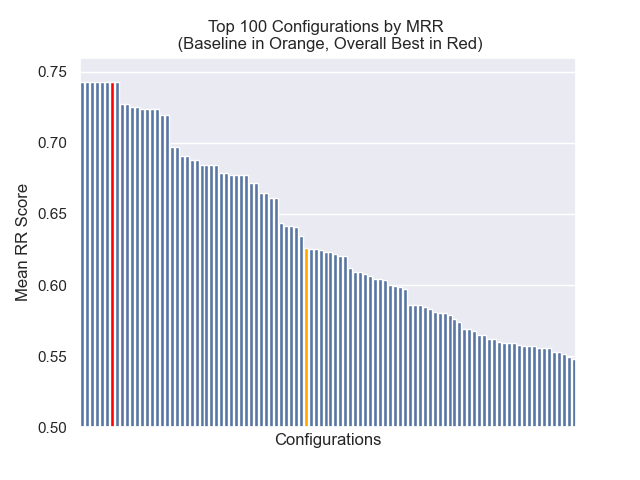
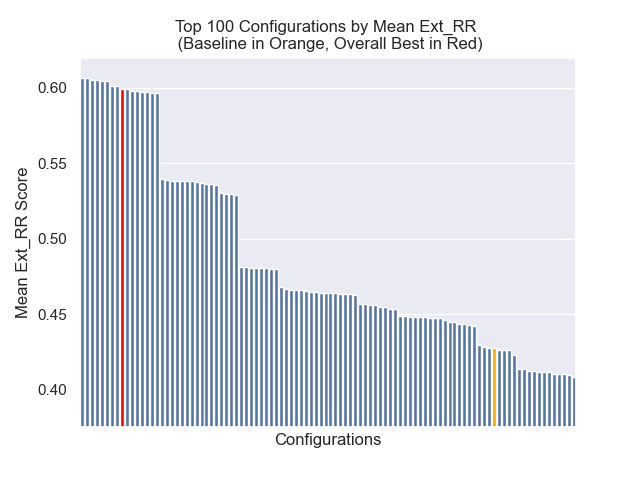
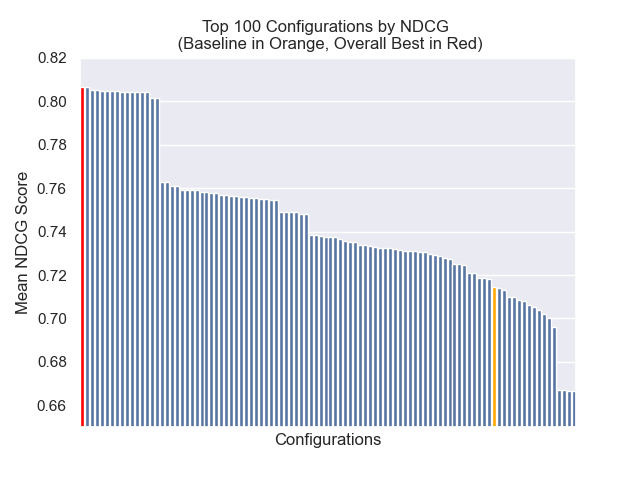
Оказалось, что снижение размера куски оказало в целом отрицательное влияние на результаты.
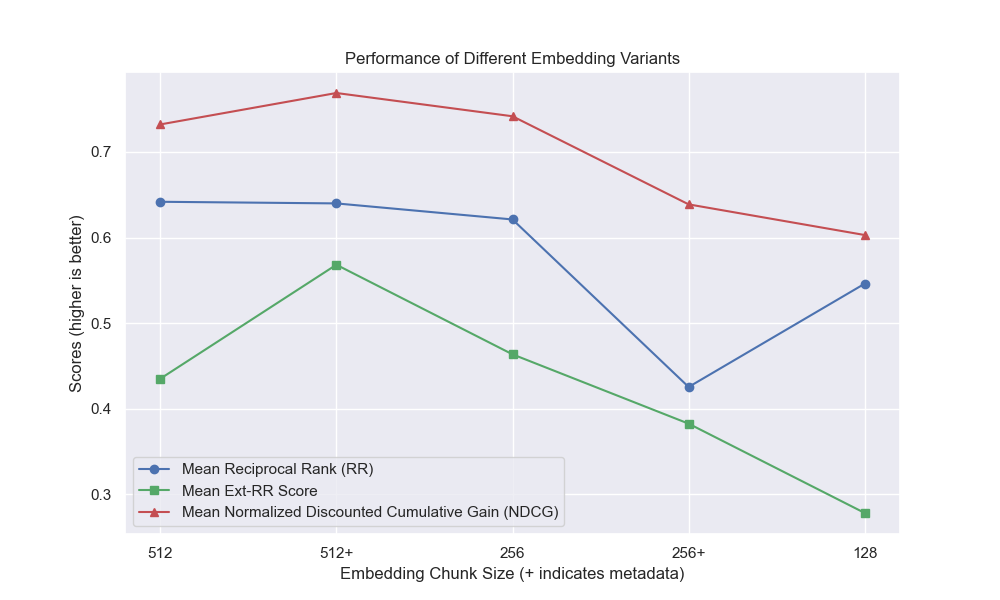
Кроме того, фильтрация коротких вопросов до поиска оказала положительное влияние независимо от других вариантов гиперпараметрических.
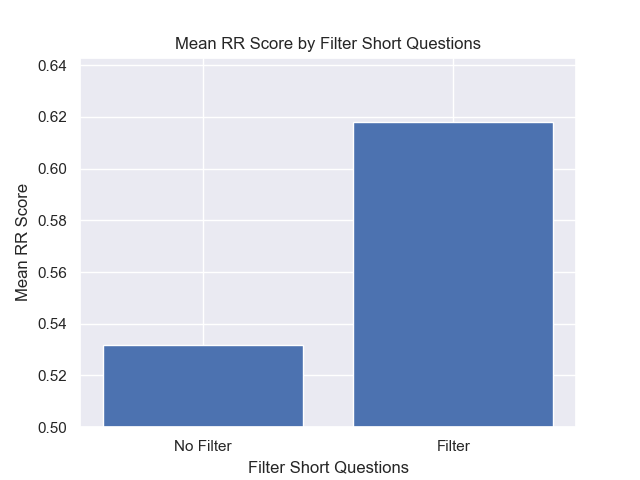
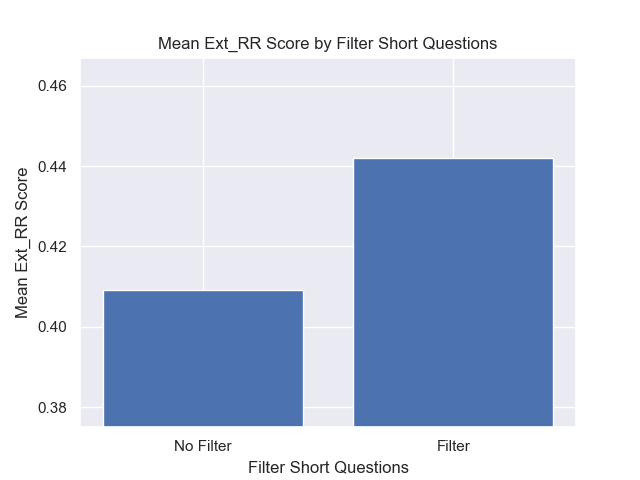
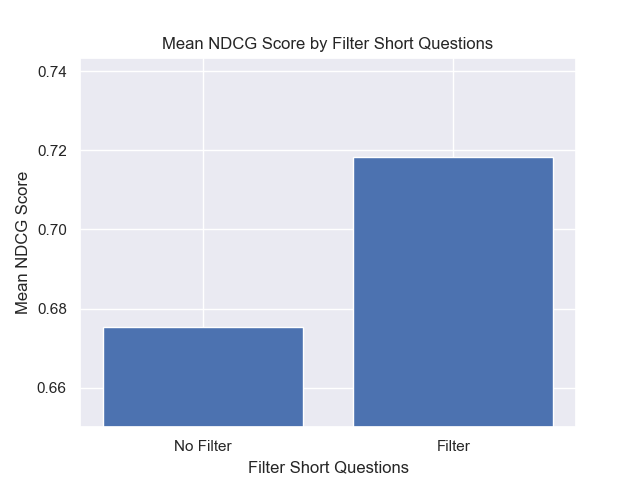
Если мы выделяем только тех конфигурации, которые содержат эти вариации вместе (512 размер чанка, с добавленными метаданными и фильтрацией по коротким вопросам), мы видим, насколько хорошо они работают по сравнению с другими конфигурациями.
Некоторые области потенциального будущего расследования:


