erdos_paware
1.0.0
Dieses Projekt wurde von Marcos Ortiz, Sayantan Roy, Karthik Prabhu, Kristina Knowles und Diptanil Roy im Rahmen des Deep Learning Boot Camp des Erdöss Institute (Frühling, 2024) abgeschlossen.
Unser Projekt ist nachstehend detailliert und Sie können die Hauptschritte durch die Demonstrationsnotizen und Daten im Paw_Demo/ Verzeichnis befolgen.
Die ersten vier Notizbücher gehen mit einer kleinen Teilmenge der Daten eine Demonstration durch. Das letzte Notizbuch lieferte eine Zusammenfassung unserer Ergebnisse im gesamten Datensatz.
Erstellen Sie einen Algorithmus zur Identifizierung und Einstufung des relevanten Inhalts im Datensatz, sodass der Übereinstimmungssatz schnell und genau abgerufen werden kann
Wir wissen, dass die eventuelle Anwendung für die Ergebnisse unseres Projekts in einer RAG-Pipeline (Abruf-Augmented Generation) verwendet wird. In diesem jüngsten Umfragepapier, der den aktuellen Stand des Lags für Großsprachenmodelle (LLMs) beschreibt, lieferte ein Einblick in die Tools, die für unsere speziellen Aufgabe und Daten gut geeignet sind.
Die Hauptschritte in Lappen sind:
Die für uns bereitgestellten Rohdaten bestehen aus 5.528.298 Posts von Reddit aus 34 Subreddits. Diese Daten wurden in einer Parkettdatei zusammen mit einem Datenwörterbuch bereitgestellt.
Für dieses Projekt konzentrieren wir uns auf die ersten beiden Schritte des RAG -Prozesses: Indexierung und Abruf.
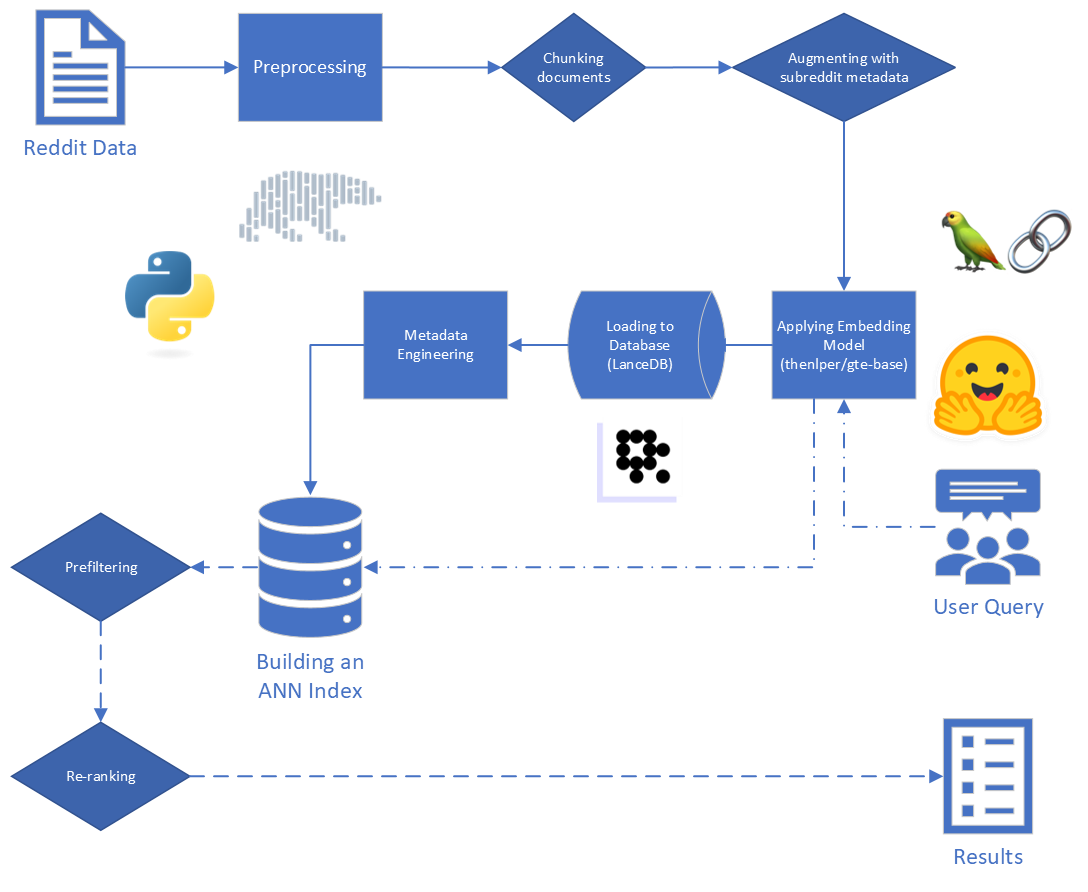
Beginnend mit den Rohdaten haben wir eine grundlegende Reinigung durchgeführt:
reddit_text -Werten von "[deleted]" oder "removed" .reddit_text -Werten herausgefiltert wurden, die mindestens 35 Zeichen lang waren und mehr als 7 Mal erschienen. Wir wollten nicht sofort kürzere häufige Sätze fallen lassen, falls sie später nützlich sein könnten (siehe Verwendung von konstruierten Metadaten).reddit_text -Werte.reddit_title ein Proxy für den reddit_text war. Also haben wir in diesen Instanzen den leeren reddit_text durch den reddit_title ersetzt. Wir haben die Basisversion des GTE -Modells (Allgemeine Texteinbettung) verwendet, das auf dem Bert -Framework basiert. Dokumentation über Umarmung: Link.
Wir haben dieses Modell ausgewählt, weil es eine vernünftige Größe (0,22 GB) zu sein schien, es ist Open Source und ermöglicht die Einbettung von Texten bis zu 512 Token. Es ist besonders gut bei Clustering und Abrufen im Vergleich zu anderen Open Source -Satztransformatoren mit weniger als 250 m Parametern: Link.
Darüber hinaus wurde ein Teil seiner Schulung mit Reddit -Daten durchgeführt, die zu seiner Anziehungskraft verstärkt wurden.
Wir haben das Experimentieren mit anderen Modellen berücksichtigt, aber aufgrund der hohen Rechenkosten für die Einbettung des Datensatzes in jedes neue Modell sparen wir diesen Weg für zukünftige Arbeiten.
Wir verwenden das von Sbert bereitgestellte Satztransformatoren -Framework, um unser Einbettungsmodell sowie die von Langchain bereitgestellten Gesichtsbettentools zu umarmen
Während der Einbettung haben wir die folgenden Parameter berücksichtigt:
chunk_size : Die maximale Textlänge des Textes als Dokument anbettetchunk_overlap : Wenn ein Dokument in Stücke unterteilt werden musste, wie viel sollten sie sich überlappenWir haben auch vor dem Einbettung mit Metadaten an Stücken experimentiert. Dazu fügen wir vor dem Einbettung einfach den Subreddit -Titel (oder eine Annäherung) zum Beginn eines Textanteils hinzu. Wenn es beispielsweise einen Kommentar in den FedExern gibt, in denen "Ich arbeite hier wirklich gerne, weil ...", würden wir "FedEx" zum Beginn des Chunk anhängen und "FedEx n n einbetten Ich arbeite wirklich gerne hier, weil ..."
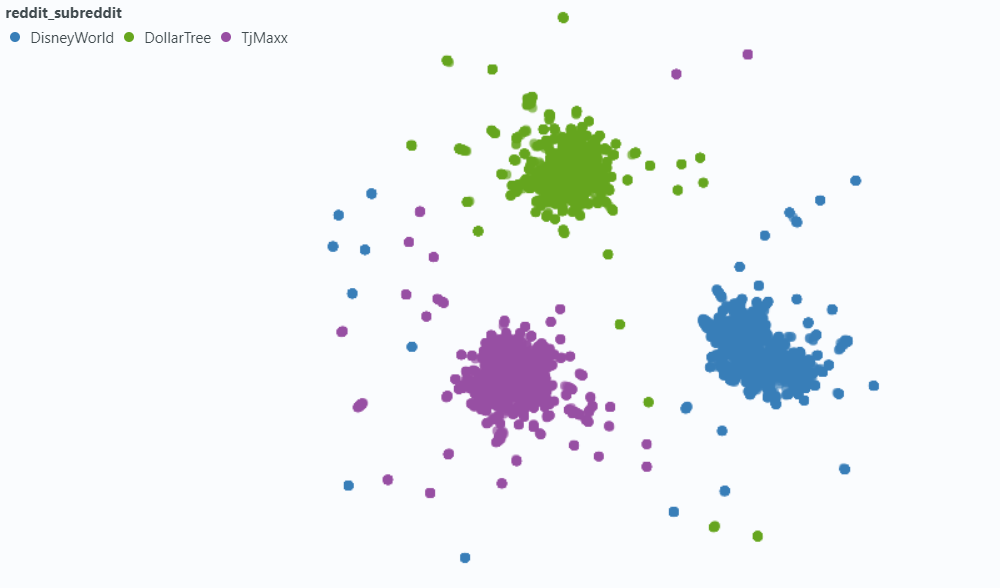
Unsere Intuition war, dass wir in den Fällen, in denen ein Beitrag nicht ausdrücklich den Namen des Unternehmens enthält, über das sie diskutieren, die Informationen aus dem Subreddit möglicherweise schließen und dass dies diesen Vektor näher an unserer Anfrage nähern könnte. Wenn wir beispielsweise fragen: "Warum arbeiten Mitarbeiter gerne bei Disney?" und "Warum arbeiten Mitarbeiter gerne bei FedEx?" Wir hoffen, dass die Hinzufügung von Metadaten es wahrscheinlicher macht, dass der obige Kommentar in den Ergebnissen für die FedEx -Abfrage höher ist und möglicherweise die Ergebnisse für die Disney -Abfrage niedriger ist.
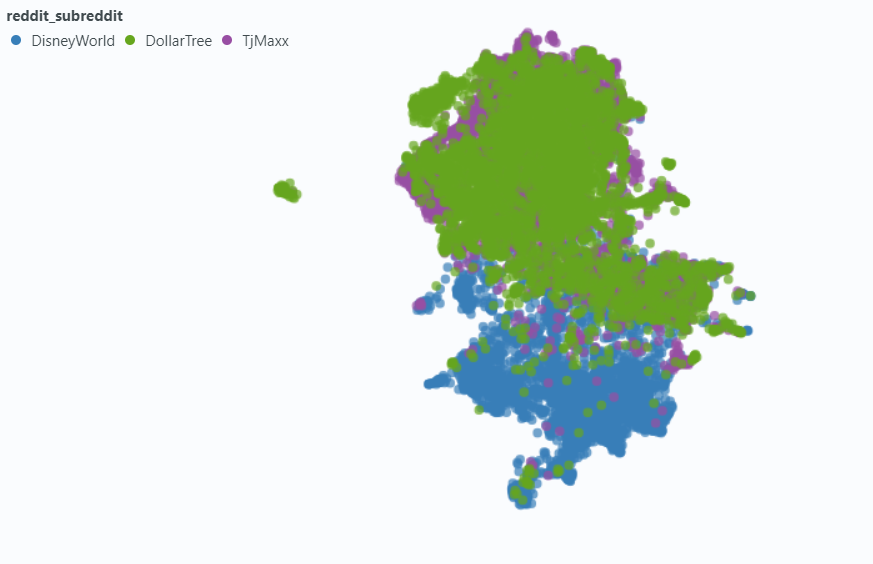
Wir haben Spotlight verwendet, um den Effekt auf eine kleine Stichprobe unserer Daten zu visualisieren.
Einbettung ohne Metadaten:
Einbettung in Metadaten:
Wir haben LancyB (Link) ausgewählt, um unsere Vektor -Datenbankanforderungen zu bearbeiten. Lancyb ist eine Open -Source -Option und bietet Integration sowohl in Python als auch in Polars, auf die wir beide stark angewiesen sind.
LancyB bietet eine Kombination aus und invertierter Dateiindex (IVF) und Produktquantisierung (PQ), um einen ungefähren Index der nächsten Nachbarn (Ann Nachbarn) zu erstellen.
Beide Teil des IVF-PQ-Index können durch Anpassen der folgenden Parameter fein abgestimmt werden:
Wir haben die Indizierungsparameter behoben und die Abrufparameter variiert. Wenn die Zeit dies zulässt, können wir uns jedoch unterscheiden, wie das Abrufen von Zeiten und die Genauigkeit beeinflusst werden.
Neben den in unseren ANN-Index integrierten Abfrageparametern haben wir andere voreinerhaltende und postretrivale Variablen variiert, um unsere Gesamtergebnisse zu verbessern.
Während des Kennzeichnungsdatens haben wir eine gemeinsame Art von "verwandtem, aber nicht relevantem" Ergebnis festgestellt: einen reddit_text , der eine ähnliche Frage wie die Abfrage selbst stellte.
Meistens stammten diese Texte aus einer submission (im Gegensatz zu einem Kommentar). Ein Weg, um zu versuchen, relevantere Ergebnisse zu erzielen, könnte darin bestehen, diese von der Vektorsuche wegzulassen. Dies ist leicht genug, da diese Informationen in unserer ursprünglichen Metadaten enthalten sind.
Weniger häufig, aber immer noch genug, um bemerkt zu werden, würde ein comment diese Eigenschaft ausstellen. Um zu versuchen, ihre Auswirkungen einzudämmen, haben wir eine Metadatenspalte is_short_question entwickelt, um alle Beispiele reddit_text zu identifizieren, die kurze Fragen stellten (und daher wahrscheinlich nicht nützliche Informationen für die Beantwortung dieser Fragen liefert), damit sie auch vor der Suche gefiltert werden konnten.
Um das Ergebnis der Ergebnisse nach dem Abrufen zu verbessern, haben wir einige aditionelle Metadaten entwickelt, mit denen wir möglicherweise Informationen durch den Inhalt der Antworten nutzen können.
Wir haben zwei Arten von Metadaten entwickelt:
sentiment von Antworten und,,agree_distance (und disagree_distance ) für Antworten. Im Falle von reply_sentiment verwendeten wir ein vorgebildetes Modell für natürliche Sprachverarbeitung mit dem Namen "MRM8488/Distilroberta-finetuned-financial-News-Sentiment-Analyse", um den emotionalen Ton hinter den Texten zu messen. Dieses Modell hat uns geholfen, jede Antwort in Kategorien wie positiv, neutral oder negativ zu klassifizieren. Die Sentiment -Scores aller Antworten wurden dann zusammengefasst, um das Gesamtgefühl gegenüber jedem ursprünglichen Beitrag und den folgenden Kommentaren widerzuspiegeln. Die zugrunde liegende Annahme ist hier, dass Beiträge, die überwiegend positive Antworten erzeugen, wahrscheinlich konstruktiv und informativ sind und dadurch als Proxy für Benutzerverbesserungen dienen, die den Upvotes in Reddit ähnlich sind. Unsere Hypothesen waren, dass ein Beitrag mit positiveren Antworten eher nützliche Informationen enthalten würde.
Im Fall von agree_distance haben wir den Abstand zwischen jedem reddit_text und einer Reihe von "Vereinbarung Anweisungen" gemessen. Immer wenn eine Einreichung oder ein Kommentar Antworten hatte, fügten wir die top_reply_agree_distance und die avg_reply_agree_distance hinzu. Unsere Hypothese war, dass Beiträge mit Antworten, die näher an "vereinbarten" Aussagen waren, eher relevante Informationen enthalten würden. In ähnlicher Weise wären Beiträge mit Antworten, die näher an "nicht einverstanden" Aussagen waren, weniger wahrscheinlich relevant.
Bei der erneuten Rangierung wurden die Ergebnisse mit niedrigerem avg_reply_agree_distance höher gestoßen, die Ergebnisse mit niedrigerem avg_reply_disagree_distance .
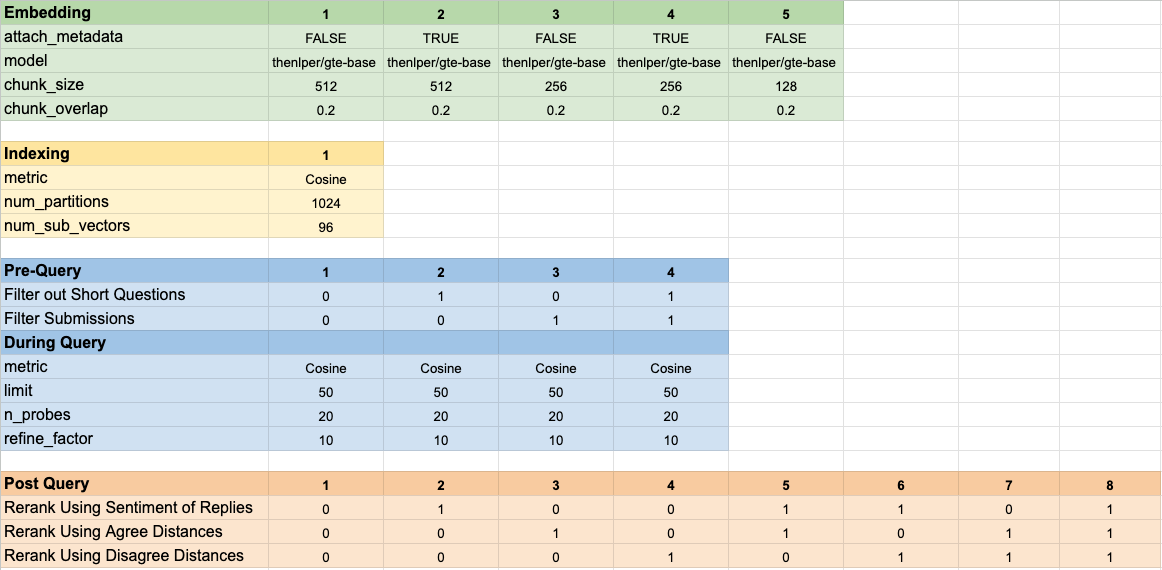
Wir haben 160 verschiedene Modellkonfigurationen getestet. Jede Konfiguration beinhaltete die Auswahl der Einbettung, eine Strategie zur Filterung der Tests vor der Durchführung unserer Vektorsuche und eine Strategie zum erneuten Spannen der abgerufenen Ergebnisse.
Diese Hyperparameter sind im Bild unten zusammengefasst:
Wir hatten zwei Hauptziele, die wir bei der Bewertung unserer Ergebnisse im Sinn hatten:
Während die Abrufzeit leicht zu messen ist, mussten wir einige Tools entwickeln, um unsere Fortschritte beim Ergebnisranking zu messen.
Um eine Grundlinie für die Bewertung des Ergebnisrankings festzulegen, haben wir eine Teilmenge von Ergebnissen manuell gekennzeichnet, um eine anfängliche Relevanzmetrie festzulegen. Zu diesem Zweck haben wir zwei Abfragen für jedes der dreizehn Datensätze in unserem Trainingssatz erstellt und die Top -20 -Ergebnisse für jede Abfrage gekennzeichnet. Die Ergebnisse wurden als:
Für jedes Abfrage-Reseult-Paar wurde das endgültige Label durch die Stimmen von Pluralität bestimmt, wobei die Verbindungen zu weniger relevant waren. Diese manuell markierten Daten wurden dann verwendet, um die Ergebnisse zu quantifizieren.
Wir haben drei Metriken für die Ranking -Ergebnisse verwendet. Jedes ist eine modifizierte Version einer Empfehlungssystemmetrik, die an unseren Anwendungsfall angepasst ist, in dem wir keine klare Grundwahrheit haben oder eine festgelegte Rangfolge der relevanten Ergebnisse von am relevantesten bis zum geringsten relevanten.
Diese Metrik gibt eine Punktzahl, die angibt, wie nahe das erste bekannte relevante Ergebnis angezeigt wird. Eine perfekte Punktzahl von 1 wird erreicht, wenn das Top -Ergebnis jeder Abfrage relevant ist.
Um den gegenseitigen Rang für eine bestimmte Abfrage zu berechnen, haben wir die folgende Formel angewendet:
In Standardanwendungen gibt es ein einzelnes Ergebnis "Bodenwahrheit". In unserer modifizierten Anwendung haben wir alle bekannten relevanten Ergebnisse als Grundwahrheit akzeptiert.
Wir haben dann den Durchschnitt dieser Ergebnisse in allen unseren Standardfragen berechnet, um den mittleren gegenseitigen Rang zu erreichen.
Diese Metrik gibt eine Punktzahl, die angibt, wie viele unserer bekannten relevanten Ergebnisse ganz oben erscheinen. Eine perfekte Punktzahl von 1 wird erzielt, wenn alle bekannten relevanten Ergebnisse als Top -Ergebnisse für alle Abfragen erscheinen (ohne dass ein unmarkiertes Ergebnis höher erscheinen als jedes bekannte relevante Ergebnis.)
Um den erweiterten gegenseitigen Rang für eine bestimmte Abfrage zu berechnen, haben wir die folgende Formel angewendet:
Wo
Wo
In Standardanwendungen hat jedes relevante Ergebnis seinen eigenen Rang, und sein Beitrag zur Gesamtpunktzahl berücksichtigt diesen Rang als erwartete Position in den Ergebnissen. In unserer modifizierten Anwendung haben wir den gleichen Beitrag zu jedem bekannten relevanten Ergebnis geleistet, das über der Position erschien
Wir haben dann den Durchschnitt dieser Ergebnisse in allen unseren Standardfragen berechnet, um den mittleren gegenseitigen Rang zu erreichen.
Der reduzierte kumulative Gewinn (DCG) wird häufig als Metrik verwendet, um die Leistung einer Suchmaschine zu bewerten, und misst die Effizienz des Algorithmus bei der Platzierung relevanter Ergebnisse ganz oben auf der Abrufliste. Für eine Liste der Längeantworten
Wo
Da der DCG -Score stark von der Länge der Abrufliste abhängt, müssen wir ihn so normalisieren, dass die Bewertung über die Abfragebrauchszenarien mit variabler Anzahl von Ergebnissen konsistent ist. Der normalisierte reduzierte kumulative Gewinn (NDCG) -Schabe an Position
wo die
NDCG kann eine ordinale Relevanzbewertung aufnehmen (1 für hochrelevante, 2 für etwas relevant, also weiter). Wir ändern das Bewertungsschema für unseren Fall, indem wir unsere menschlichen Etiketten (1 relevant, 2 bezogen, aber nicht relevant, 3-NOT-verwandt) in ein Binärbewertungsschema umwandeln. Die Ergebnisse mit Human Label = 1 erhielten eine Relevanzbewertung = 1, und alles andere erhielt eine Relevanzbewertung von 0. Dies wurde durchgeführt, um sicherzustellen, dass die beste Konfiguration, wie der NDCG -Score diktiert wurde, nur hochrelevante Ergebnisse zurückgeben sollte. Wir haben dann den NDCG -Score unserer Standardabfragen berechnet und sie gemittelt, um den mittleren NDCG -Score einer bestimmten Konfiguration zu erhalten. Die DCG -Scores und IDCG -Scores wurden durch Einstellen berechnet
Wo
Wir haben die folgenden Modellparameter als Basis zum Vergleich verwendet:
Die Basiskonfiguration erzielt die folgenden Punktzahlen in unseren Metriken:
| Metrisch | Punktzahl | Rang (von 160) |
|---|---|---|
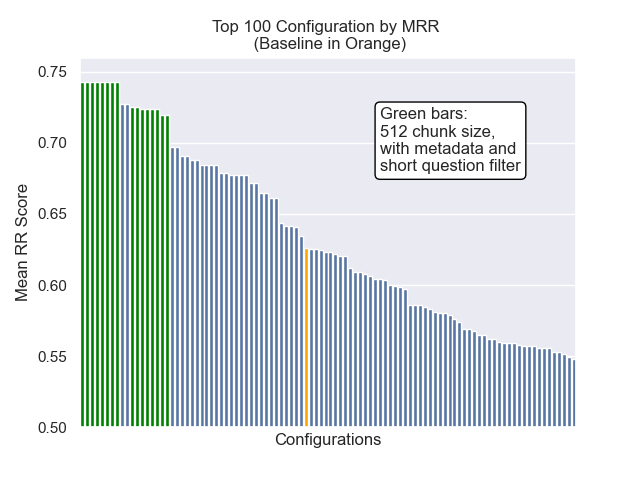
| Mittlerer wechselseitiger Rang | 0,626031 | 46 |
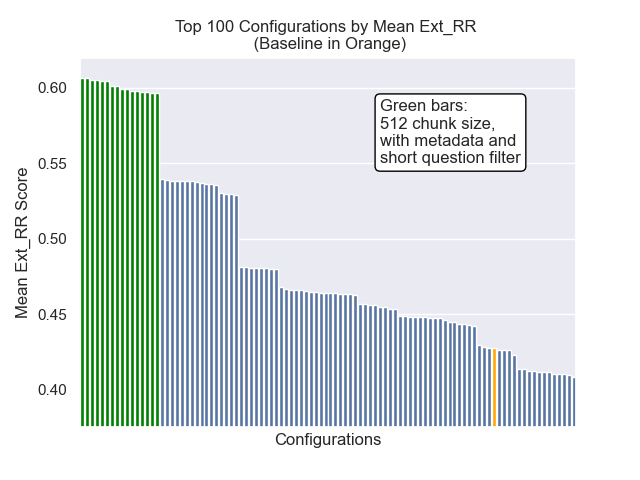
| Erweiterter mittlerer gegenseitiger Rang | 0,427189 | 84 |
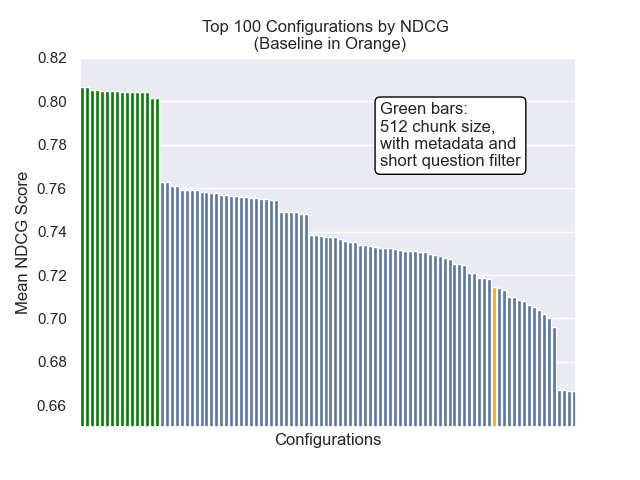
| Normalisierter reduzierter kumulativer Gewinn | 0,714459 | 84 |
| Durchschnittlicher Gesamtrang | 71.33 |
Die Konfiguration, die das beste Gesamtergebnis erzielte (höchster Durchschnittsrang über Metriken):
Diese Konfiguration erzielen die folgenden Punktzahlen in unseren Metriken:
| Metrisch | Punktzahl | Rang (von 160) |
|---|---|---|
| Mittlerer wechselseitiger Rang | 0,742735 | 7 |
| Erweiterter mittlerer gegenseitiger Rang | 0,599379 | 9 |
| Normalisierter reduzierter kumulativer Gewinn | 0,806476 | 1 |
| Durchschnittlicher Gesamtrang | 5.67 |
Im Folgenden können wir die relative Position der Baseline -Konfiguration ganz oben insgesamt sehen.
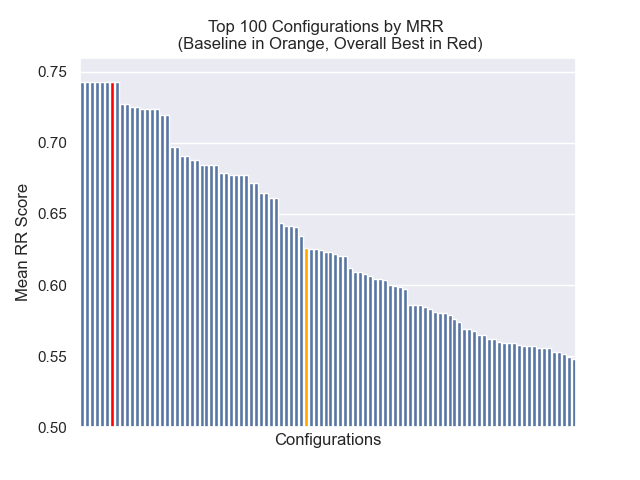
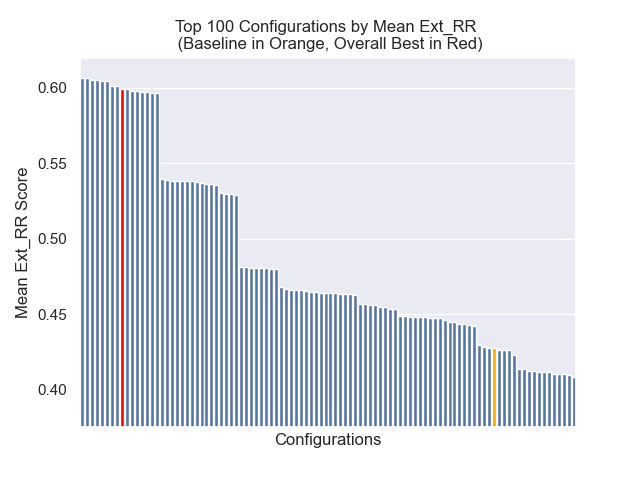
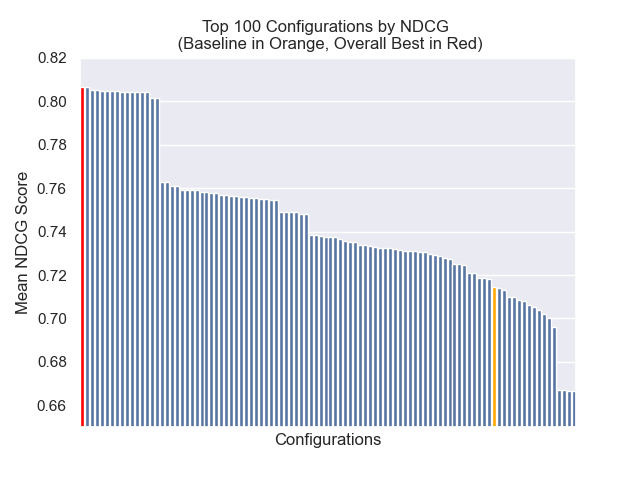
Es schien, dass eine verminderte Klopfengröße im Allgemeinen negative Auswirkungen auf die Ergebnisse hatte.
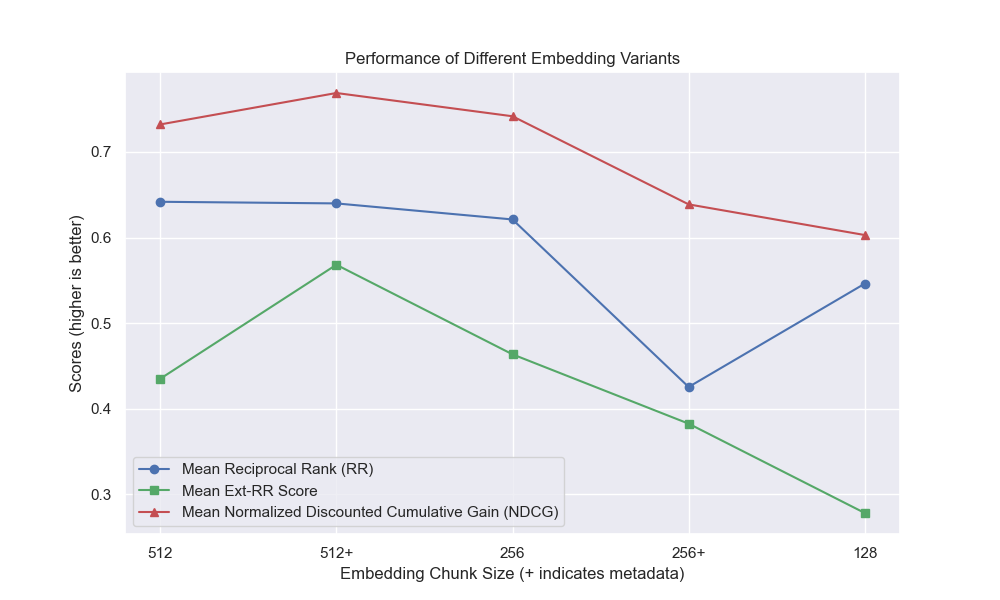
Außerdem wirkten sich die Kurzfragen vor dem Abrufen, unabhängig von anderen Hyperparametern -Auswahlmöglichkeiten, positiv aus.
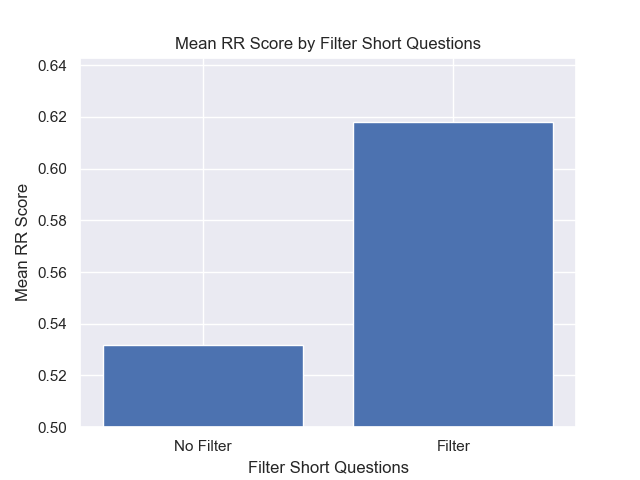
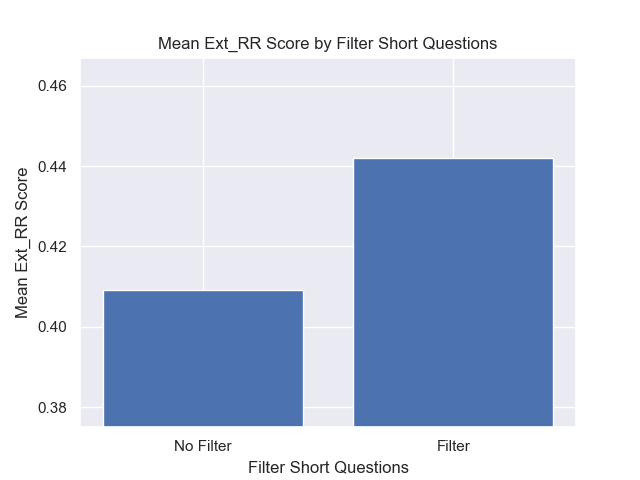
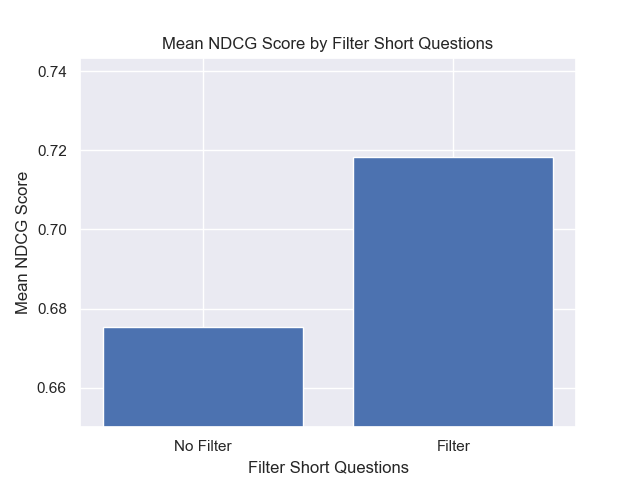
Wenn wir nur die Konfiguration hervorheben, die diese Variationen zusammen enthalten (512 -Chunk -Größe, mit zusätzlichen Metadaten und Filtern durch kurze Fragen), sehen wir, wie gut sie relativ zu anderen Konfigurationen ausführen.
Einige Bereiche potenzieller zukünftiger Untersuchungen:


