erdos_paware
1.0.0
Ce projet a été achevé par Marcos Ortiz, Sayantan Roy, Karthik Prabhu, Kristina Knowles et Diptanil Roy, dans le cadre du Boot Camp de Deep Learning Erdös Institute (printemps, 2024).
Notre projet est détaillé ci-dessous, et vous pouvez suivre les étapes principales à travers les cahiers de démonstration et les données fournies dans le répertoire PAW_DEMO /.
Les quatre premiers ordinateurs portables parcourent une démonstration en utilisant un petit sous-ensemble des données. Le dernier carnet a fourni un résumé de nos résultats sur l'ensemble de données.
Compte tenu d'une requête utilisateur arbitraire et d'un ensemble de données de contenu généré par l'homme, créez un algorithme pour identifier et classer le contenu pertinent dans l'ensemble de données, de sorte que l'ensemble de matchs peut être récupéré rapidement et avec précision
Nous savons que l'application éventuelle pour les résultats de notre projet est utilisée dans un pipeline de génération (RAG) (RAG) de récupération. Ce récent document d'enquête, décrivant l'état actuel du RAG pour les modèles de grande langue (LLMS), a contribué à fournir un aperçu de quels outils pourraient être un bon ajustement pour notre tâche et nos données particulières.
Les étapes principales du chiffon sont:
Les données brutes fournies aux États-Unis se compose de 5 528 298 postes de Reddit, à partir de 34 subreddits. Ces données ont été fournies dans un fichier Parquet, ainsi qu'un dictionnaire de données.
Pour ce projet, nous nous concentrons sur les deux premières étapes du processus de RAG: l'indexation et la récupération.
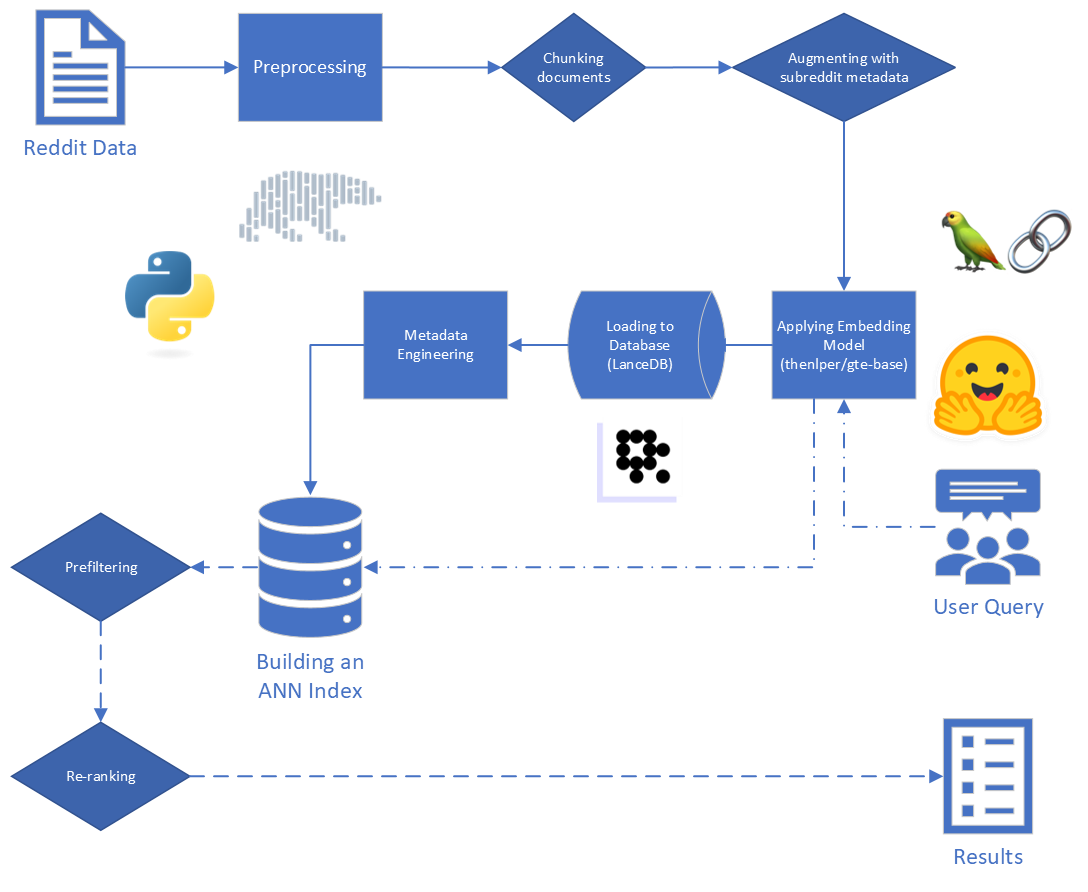
En commençant par les données brutes, nous avons effectué un nettoyage de base:
reddit_text de "[deleted]" ou "removed" .reddit_text qui mesuraient au moins 35 caractères et sont apparues plus de 7 fois. Nous ne voulions pas abandonner immédiatement des phrases courantes plus courtes, au cas où elles pourraient être utiles plus tard (voir en utilisant des métadonnées techniques).reddit_text vides.reddit_title était un indicateur indirect du reddit_text . Nous avons donc remplacé le reddit_text vide par le reddit_title dans ces cas. Nous avons utilisé la version de base du modèle General Text Embeddings (GTE), qui est basé sur le framework Bert. Documentation sur HuggingFace: lien.
Nous avons choisi ce modèle car il semblait être une taille raisonnable (0,22 Go), il est open source, et il permet de constituer des textes jusqu'à 512 jetons. Il fonctionne particulièrement bien dans le clustering et la récupération par rapport aux autres transformateurs de phrases open source qui ont moins de 250 m de paramètres: lien.
De plus, une partie de sa formation a été effectuée en utilisant les données de Reddit, ce qui a ajouté à son appel.
Nous avons envisagé l'expérimentation avec d'autres modèles, mais en raison du coût de calcul élevé de l'intégration de l'ensemble de données avec chaque nouveau modèle, nous économisons cette avenue pour les travaux futurs.
Nous utilisons le cadre de phrase Transformers fournis par SBERT pour mettre en œuvre notre modèle d'incorporation, ainsi que des outils d'intégration de visage étreintes fournis par Langchain
Pendant l'intégration, nous avons considéré les paramètres suivants:
chunk_size : la longueur maximale du texte à intégrer en tant que documentchunk_overlap : chaque fois qu'un document devait être divisé en morceaux, combien devrait-il se chevaucherNous avons également expérimenté la fixation des métadonnées aux morceaux avant de l'incorporer. Pour ce faire, nous ajoutons simplement le titre Subreddit (ou une approximation) au début d'un morceau de texte avant d'incorporer. Par exemple, s'il y a un commentaire dans les FedExers qui dit "j'aime vraiment travailler ici parce que ...", alors nous ajouterions "FedEx" au début du morceau et intégrer "FedEx n n j'aime vraiment travailler ici parce que ..."
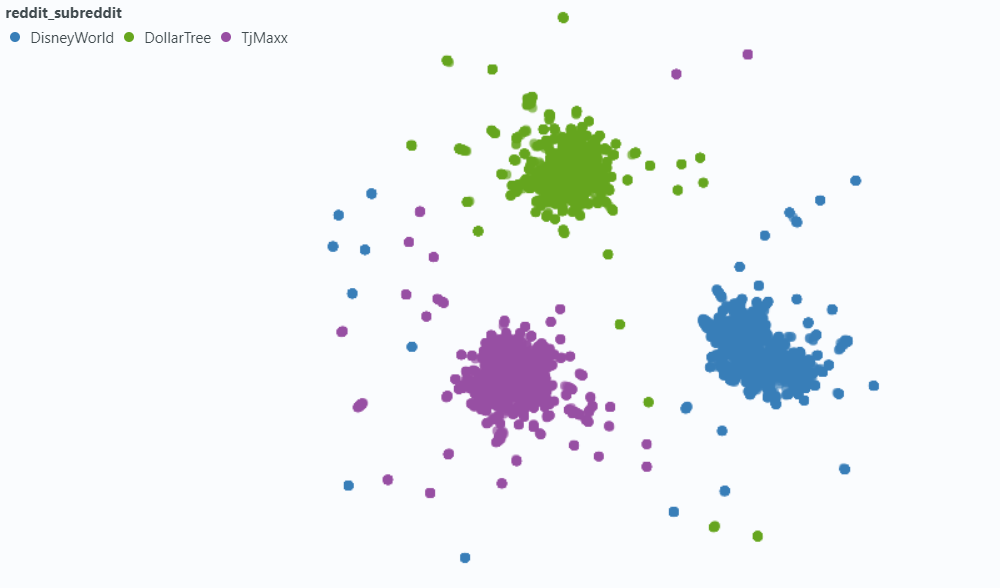
Notre intuition était que, dans les cas où un message n'inclut pas explicitement le nom de l'entreprise dont elle discute, nous pourrions en déduire que les informations du subreddit et que cela pourrait pousser ce vecteur plus proche de notre requête. Par exemple, si nous demandons «pourquoi les employés aiment-ils travailler chez Disney?» Et "Pourquoi les employés aiment-ils travailler chez FedEx?" Nous espérons que l'ajout de métadonnées rend plus probable que le commentaire ci-dessus apparaisse plus haut dans les résultats de la requête FedEx, et peut-être plus faible dans les résultats de la requête Disney.
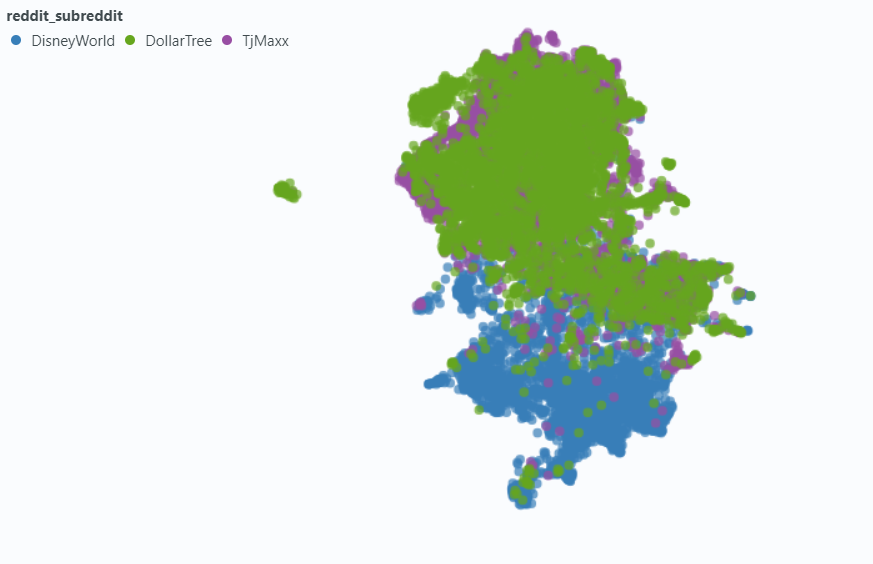
Nous avons utilisé des projecteurs pour visualiser l'effet sur un petit échantillon de nos données.
Incorporer sans métadonnées:
Incorporer avec des métadonnées:
Nous avons choisi LancedB (lien) pour gérer nos besoins de base de données vectoriels. LancedB est une option open source, et elle fournit une intégration à la fois avec Python et Polar, sur lesquelles nous dépendons fortement.
LancedB fournit une combinaison et inversé d'index de fichiers (FIV) et de quantification du produit (PQ) pour créer un index approximatif des voisins les plus proches (ANN).
Les deux partie de l'index IVF-PQ peuvent être ajustées en ajustant les paramètres suivants:
Nous avons corrigé les paramètres d'indexation et avons varié les paramètres de récupération. Cependant, si le temps autorisé, nous pourrions varier à la fois pour voir comment les temps de récupération et la précision sont affectés.
Outre les paramètres de requête intégrés dans notre index Ann, nous avons varié d'autres variables pré-retraivales et post-reévaluales pour essayer d'améliorer nos résultats globaux.
Lors de l'étiquetage des données, nous avons remarqué un type commun de résultat "lié mais non pertinent": un reddit_text qui posait une question similaire à la requête elle-même.
La plupart du temps, ces textes provenaient d'une submission (par opposition à un commentaire). Ainsi, une façon d'essayer d'élever des résultats plus pertinents pourrait être de les omettre à partir de la recherche vectorielle. C'est assez facile, étant donné que ces informations sont contenues dans nos métadonnées d'origine.
Moins fréquemment, mais encore assez pour être remarqué, un comment présenterait cette propriété. Pour essayer de freiner leur impact, nous avons conçu une colonne de métadonnées is_short_question pour essayer d'identifier tous les exemples reddit_text qui posaient de courtes questions (et il était donc peu probable de fournir des informations utiles pour répondre à ces questions) afin qu'ils puissent également être filtrés avant la recherche.
Afin d'améliorer le classement des résultats après la récupération, nous avons conçu des métadonnées indicelles qui pourraient nous permettre de tirer parti des informations fournies par le contenu des réponses.
Nous avons conçu deux types de métadonnées:
sentiment des réponses et,agree_distance (et disagree_distance ) pour les réponses. Dans le cas de reply_sentiment , nous avons utilisé un modèle de traitement du langage naturel pré-formé appelé "MRM8488 / Distilroberta-Finetuned-financial-news-Sentiment-Analysis", pour évaluer le ton émotionnel derrière les textes. Ce modèle nous a aidés à classer chaque réponse dans des catégories telles que positives, neutres ou négatives. Les scores de sentiment de toutes les réponses ont ensuite été agrégés pour refléter le sentiment global de chaque poste d'origine et les commentaires suivants. L'hypothèse sous-jacente ici est que les publications générant des réponses principalement positives sont probablement constructives et informatives, servant ainsi de proxy pour les approbations des utilisateurs similaires aux votes up dans Reddit. Nos hypothèses étaient qu'un message avec des réponses plus positives serait plus susceptible de contenir des informations utiles.
Dans le cas de agree_distance , nous avons mesuré la distance entre chaque reddit_text et un ensemble de "Instructions d'accord". Ensuite, chaque fois qu'une soumission ou un commentaire avait des réponses, nous avons ajouté le top_reply_agree_distance et l' avg_reply_agree_distance . Notre hypothèse était que les articles avec des réponses qui étaient plus proches des déclarations «d'accord» seraient plus susceptibles de contenir des informations pertinentes. De même, les messages avec des réponses qui étaient plus proches des déclarations de «désaccord» seraient moins susceptibles d'être pertinents.
Lorsque la réensemble, les résultats avec avg_reply_agree_distance plus bas ont été augmentés, les résultats avec avg_reply_disagree_distance inférieur ont été inférieurs plus bas.
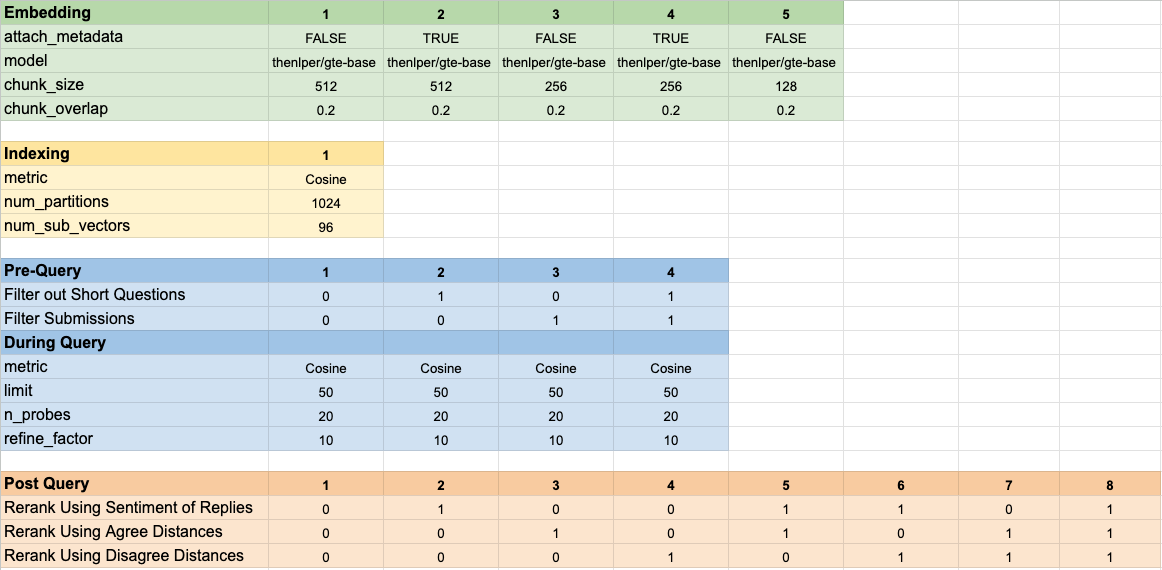
Nous avons testé 160 configurations de modèle différentes. Chaque configuration comprenait un choix d'incorporation, une stratégie de filtrage des tests avant d'effectuer notre recherche de vecteur et une stratégie pour relancer les résultats qui ont été récupérés.
Ces hyper-paramètres sont résumés dans l'image ci-dessous:
Nous avions deux objectifs principaux que nous avions en tête lors de l'évaluation de nos résultats:
Bien que le temps de récupération soit assez facile à mesurer, nous devions développer certains outils pour mesurer nos progrès dans le classement des résultats.
Pour établir une base de référence pour évaluer le classement des résultats, nous avons manuellement étiqueté un sous-ensemble de résultats pour établir une métrique initiale de pertinence. Pour ce faire, nous avons créé deux requêtes pour chacun des treize ensembles de données de notre ensemble de formation et étiqueté les 20 meilleurs résultats récupérés pour chaque requête. Les résultats ont été étiquetés comme:
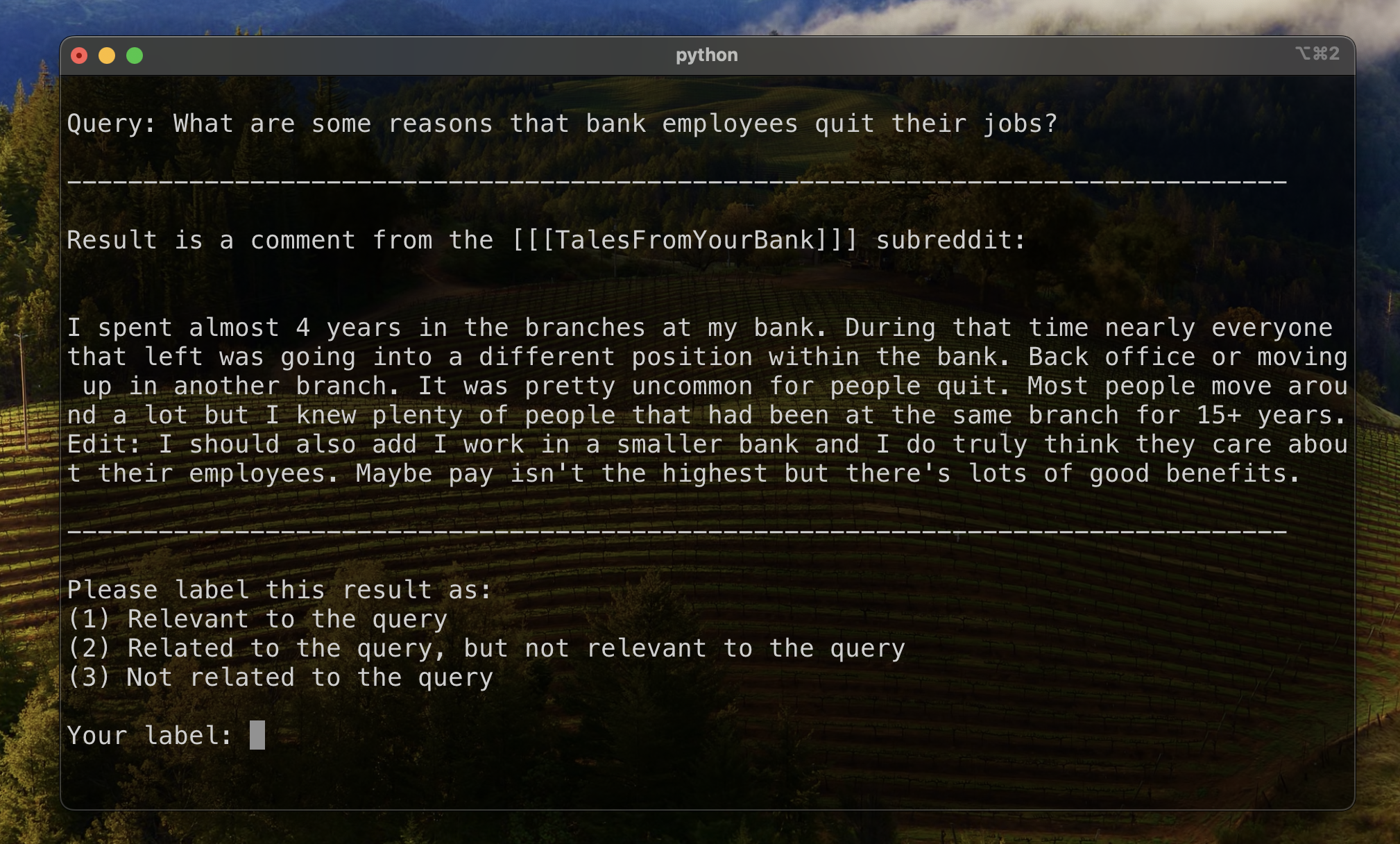
Pour chaque paire de questions de requête, l'étiquette finale a été déterminée par vote de pluralité, avec des liens défaut à moins de pertinence. Ces données étiquetées manuellement ont ensuite été utilisées pour quantifier les résultats.
Nous avons utilisé trois mesures pour le classement des résultats. Chacun est une version modifiée d'une mesure du système de recommandation, adaptée à notre cas d'utilisation où nous n'avons pas de vérité claire, ou un classement établi des résultats pertinents des plus pertinents pour les moins pertinents.
Cette métrique donne un score qui indique à quel point le haut du premier résultat pertinent connu apparaît. Un score parfait de 1 est obtenu si le résultat supérieur de chaque requête est pertinent.
Pour calculer le rang réciproque pour une requête donnée, nous avons appliqué la formule suivante:
Dans les applications standard, il y a un seul résultat connu de la "vérité du sol". Dans notre application modifiée, nous avons accepté tout résultat pertinent connu comme la vérité du terrain.
Nous avons ensuite calculé la moyenne de ces scores dans toutes nos requêtes standard pour arriver au rang réciproque moyen.
Cette métrique donne un score qui indique combien de nos résultats pertinents connus apparaissent près du sommet. Un score parfait de 1 est obtenu si tous les résultats pertinents connus apparaissent comme les résultats les plus importants pour toutes les requêtes (sans résultat non étiqueté apparaissant plus élevé que tout résultat pertinent connu.)
Pour calculer le rang réciproque étendu pour une requête donnée, nous avons appliqué la formule suivante:
où
où
Dans les applications standard, chaque résultat pertinent a son propre rang et sa contribution au score global prend en compte ce rang comme position attendue dans les résultats. Dans notre application modifiée, nous avons apporté la même contribution à tout résultat pertinent connu qui est apparu au-dessus de la position
Nous avons ensuite calculé la moyenne de ces scores dans toutes nos requêtes standard pour arriver au rang réciproque moyen.
Le gain cumulatif à prix réduit (DCG) est souvent utilisé comme métrique pour évaluer les performances d'un moteur de recherche et mesure l'efficacité de l'algorithme dans la mise en place des résultats pertinents en haut de la liste de récupération. Pour une liste de réponses de longueur
où
Étant donné que le score DCG dépend fortement de la longueur de la liste de récupération, nous devons le normaliser afin que la notation soit cohérente dans les scénarios de récupération de requête avec un nombre variable de résultats. Le score de gain cumulatif réduit normalisé (NDCG) en position
où le
NDCG peut adopter le score de pertinence ordinale (1 pour les très pertinents, 2 pour un peu pertinent, ainsi de suite). Nous modifions le schéma de notation de notre cas, en convertissant nos étiquettes humaines (1 pertinente, 2 liées mais non pertinentes, 3-non) en un schéma de notation binaire. Les résultats avec l'étiquette humaine = 1 ont reçu un score de pertinence = 1, et tout le reste a reçu un score de pertinence de 0. Nous avons ensuite calculé le score NDCG de nos requêtes standard et les avons en moyenne pour obtenir le score NDCG moyen d'une configuration particulière. Les scores DCG et les scores IDCG ont été calculés en réglant
où
Nous avons utilisé les paramètres du modèle suivants comme base de référence pour la comparaison:
La configuration de base réalise les scores suivants sur nos mesures:
| Métrique | Score | Rang (sur 160) |
|---|---|---|
| Rang réciproque moyen | 0,626031 | 46 |
| Rang moyen réciproque moyen | 0.427189 | 84 |
| Gain cumulatif à prix réduit | 0,714459 | 84 |
| Rang global moyen | 71.33 |
La configuration qui a obtenu le meilleur résultat global (rang moyen le plus élevé entre les mesures):
Cette configuration réalise les scores suivants sur nos mesures:
| Métrique | Score | Rang (sur 160) |
|---|---|---|
| Rang réciproque moyen | 0,742735 | 7 |
| Rang moyen réciproque moyen | 0,599379 | 9 |
| Gain cumulatif à prix réduit | 0,806476 | 1 |
| Rang global moyen | 5.67 |
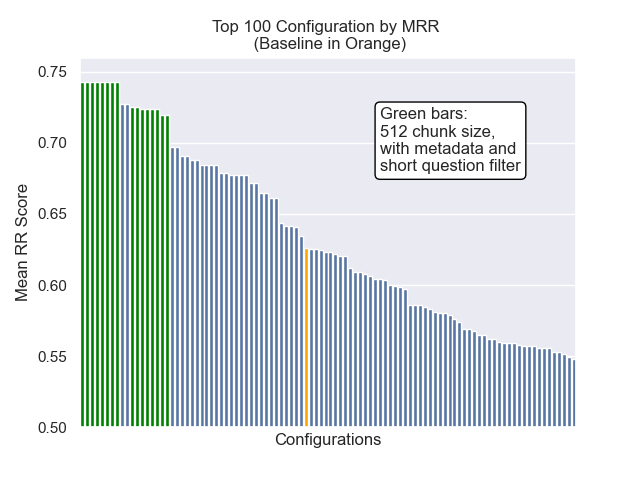
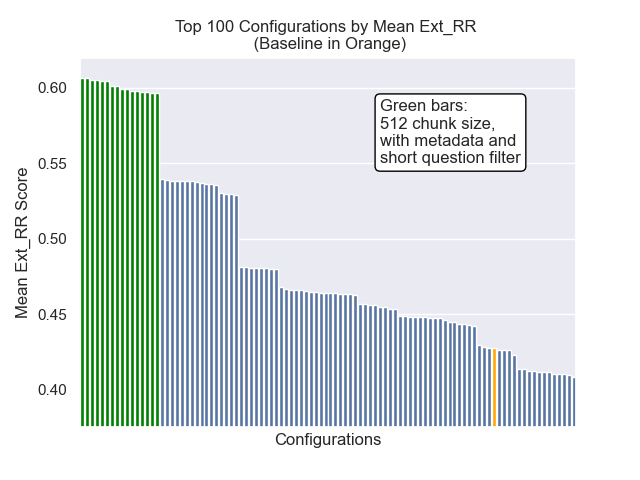
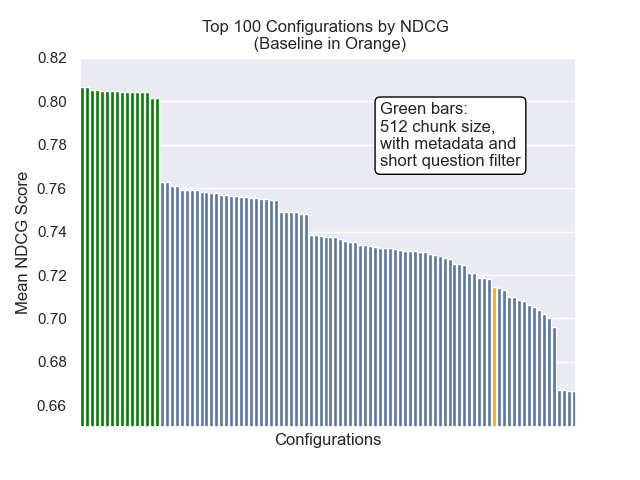
Ci-dessous, nous pouvons voir la position relative de la configuration de base vers le haut dans l'ensemble.
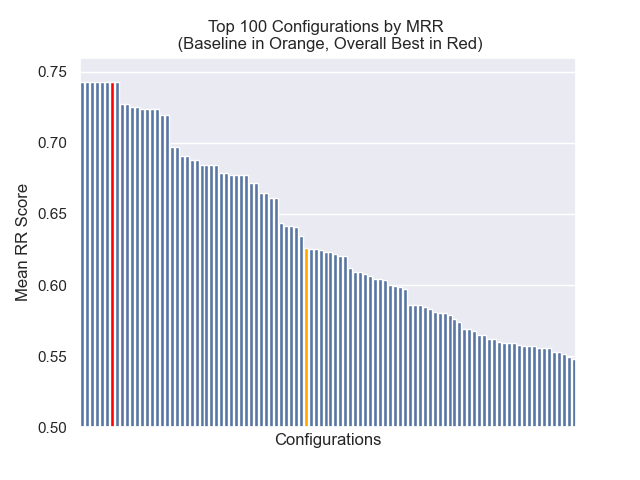
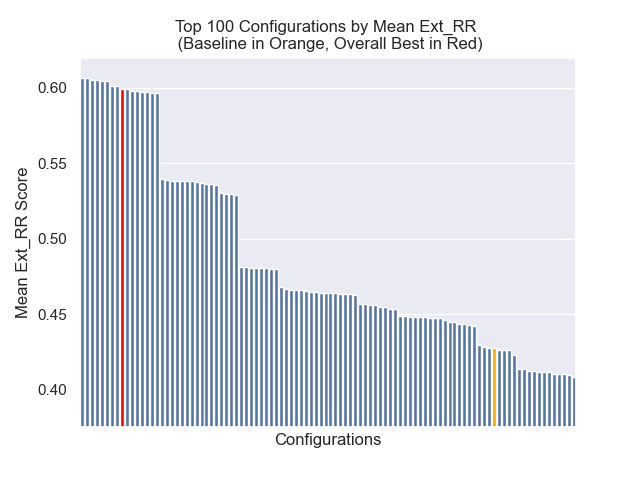
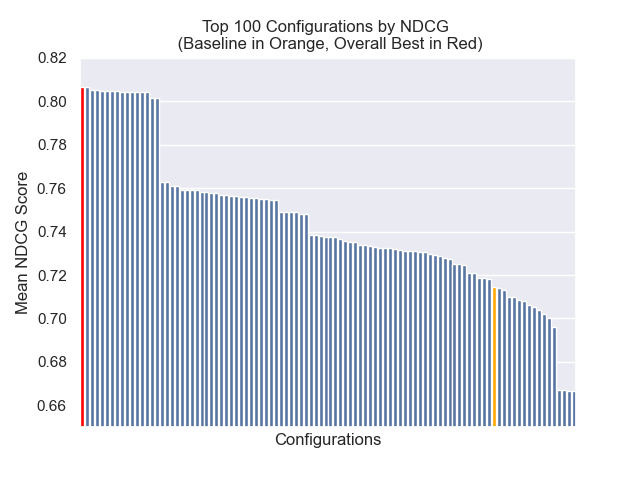
Il est apparu qu'une diminution de la taille des morceaux a eu un impact généralement négatif sur les résultats.
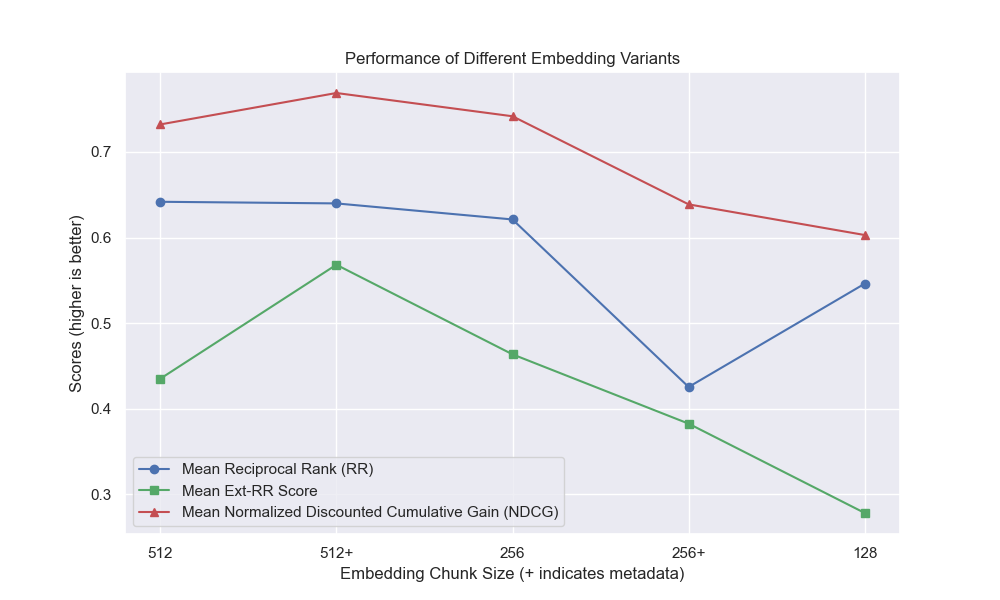
En outre, le filtrage de courtes questions avant la récupération a eu un impact positif, quels que soient les autres choix d'hyperparamètre.
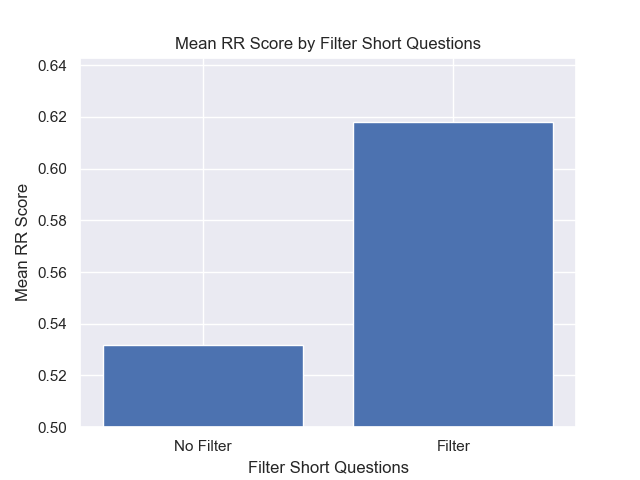
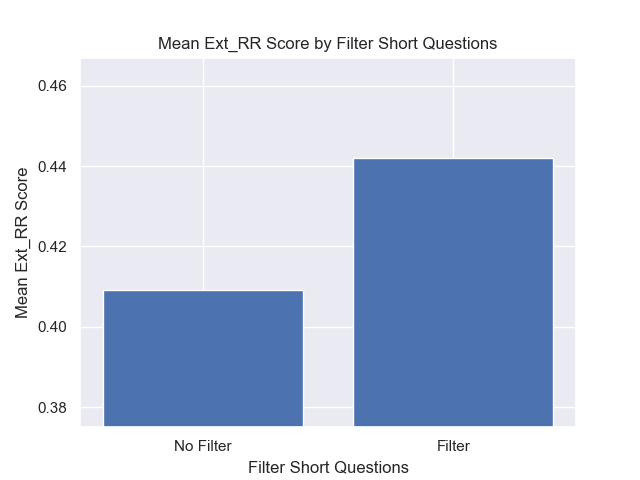
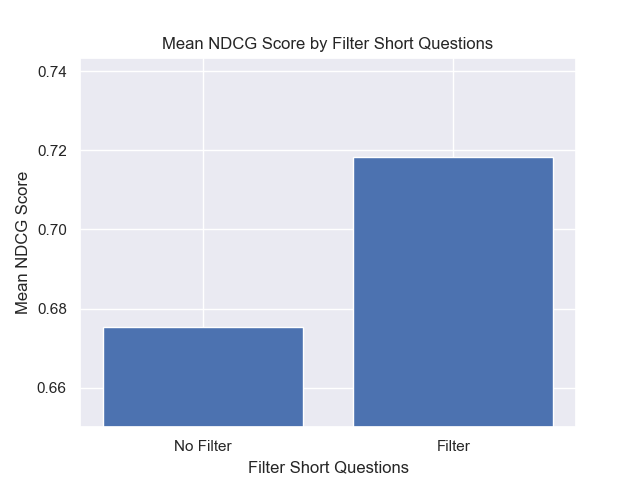
Si nous mettons en évidence uniquement la configuration qui contiennent ces variations ensemble (taille 512 des morceaux, avec des métadonnées ajoutées et filtrant par courtes questions), nous voyons à quel point ils fonctionnent par rapport aux autres configurations.
Certains domaines d'une enquête future potentielle:


