erdos_paware
1.0.0
تم الانتهاء من هذا المشروع من قبل ماركوس أورتيز ، سايانتان روي ، كارثيك برابهو ، كريستينا نولز ، وديبتانيل روي ، كجزء من معسكر التمهيد العميق في معهد Erdös (Spring ، 2024).
تم تفصيل مشروعنا أدناه ، ويمكنك متابعته مع الخطوات الرئيسية من خلال دفاتر ملاحظات التوضيح والبيانات المقدمة في PAW_DEMO/ DIRECTORY.
تسير دفاتر الملاحظات الأربعة الأولى عبر عرض عرضية باستخدام مجموعة فرعية صغيرة من البيانات. قدم دفتر الملاحظات الأخير ملخصًا لنتائجنا على مجموعة البيانات بأكملها.
بالنظر إلى استعلام مستخدم تعسفي ومجموعة بيانات للمحتوى الذي تم إنشاؤه البشري ، قم بإنشاء خوارزمية لتحديد المحتوى ذي الصلة وتصنيفه في مجموعة البيانات ، بحيث يمكن استرداد مجموعة المطابقة بسرعة ودقة
نحن نعلم أن التطبيق النهائي لنتائج مشروعنا يستخدم في خط أنابيب الجيل (RAG) الذي تم تجهيزه. ساعدت ورقة المسح الحديثة هذه ، التي تصف الحالة الحالية لنماذج اللغة الكبيرة (LLMS) بتوفير بعض الأفكار حول الأدوات التي قد تكون مناسبة لمهمتنا وبياناتنا الخاصة.
الخطوات الرئيسية في الخرقة هي:
تتكون البيانات الأولية المقدمة إلى الولايات المتحدة من 5،528،298 مشاركة من Reddit ، من 34 Subreddits. تم توفير هذه البيانات في ملف parquet ، جنبا إلى جنب مع قاموس البيانات.
لهذا المشروع ، نركز على الخطوتين الأوليين من عملية الخرقة: الفهرسة والاسترجاع.
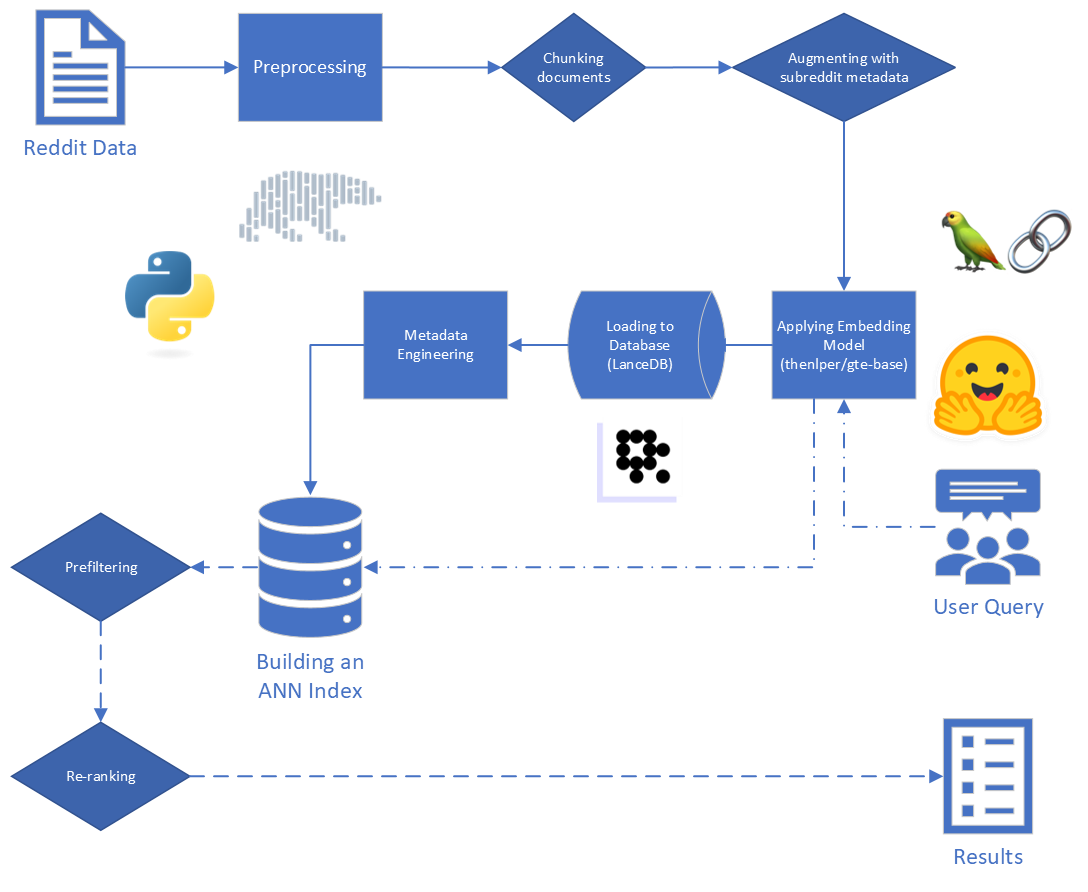
بدءًا من البيانات الخام ، أجرينا بعض التنظيف الأساسي:
reddit_text من "[deleted]" أو "removed" .reddit_text التي يبلغ طولها 35 حرفًا على الأقل ، وظهرت أكثر من 7 مرات. لم نرغب في إسقاط عبارات شائعة أقصر على الفور ، في حالة وجودها مفيدًا لاحقًا (انظر استخدام البيانات الوصفية الهندسية).reddit_text فارغة.reddit_title كان وكيلًا لـ reddit_text . لذلك ، استبدلنا reddit_text الفارغ مع reddit_title في هذه الحالات. استخدمنا الإصدار الأساسي من نموذج تضمينات النص العام (GTE) ، والذي يعتمد على إطار Bert. الوثائق على Huggingface: الرابط.
لقد اخترنا هذا النموذج لأنه يبدو أنه حجم معقول (0.22 جيجابايت) ، وهو مفتوح المصدر ، ويسمح بتضمين النصوص التي يصل طولها إلى 512 رمزًا. إنه يعمل بشكل جيد بشكل خاص في التجميع والاسترجاع مقارنة بمحولات الجملة الأخرى مفتوحة المصدر والتي تحتوي على أقل من 250 متر معلمات: Link.
علاوة على ذلك ، تم إجراء جزء من تدريبه باستخدام بيانات Reddit ، والتي أضافت إلى جاذبيتها.
لقد فكرنا في التجربة مع نماذج أخرى ، ولكن نظرًا للتكلفة الحسابية العالية لتضمين مجموعة البيانات مع كل نموذج جديد ، فإننا نوفر هذا الطريق للعمل في المستقبل.
نستخدم إطار عمل Transformers الذي توفره Sbert لتنفيذ نموذج التضمين الخاص بنا ، بالإضافة إلى معانقة أدوات تضمين الوجه التي توفرها Langchain
أثناء التضمين ، نظرنا في المعلمات التالية:
chunk_size : الحد الأقصى لطول النص لتضمينه كمستندchunk_overlap : كلما احتاجت إلى تقسيم وثيقة إلى قطع ، كم يجب أن تتداخللقد جربنا أيضًا ربط البيانات الوصفية بالقطع قبل التضمين. للقيام بذلك ، نضيف ببساطة عنوان SubredDit (أو تقريب) إلى بداية نص نص قبل التضمين. على سبيل المثال ، إذا كان هناك تعليق في FedExers يقول "أنا حقًا أحب العمل هنا لأن ..." ، فسنقوم بإلحاق "FedEx" ببداية القطعة وتضمين "FedEx n n أحب العمل هنا حقًا لأن ..."
كان حدسنا هو أنه في الحالات التي لا يتضمن فيها المنشور بشكل صريح اسم الشركة التي يناقشونها ، قد نستنتج أن المعلومات من subreddit وأن هذا قد يدفع هذا المتجه أقرب إلى استعلامنا. على سبيل المثال ، إذا سألنا "لماذا يحب الموظفون العمل في ديزني؟" و "لماذا الموظفين يحبون العمل في FedEx؟" أملنا هو أن إضافة البيانات الوصفية تجعل من المرجح أن يظهر التعليق أعلاه في نتائج استعلام FedEx ، وربما أقل في نتائج استعلام ديزني.
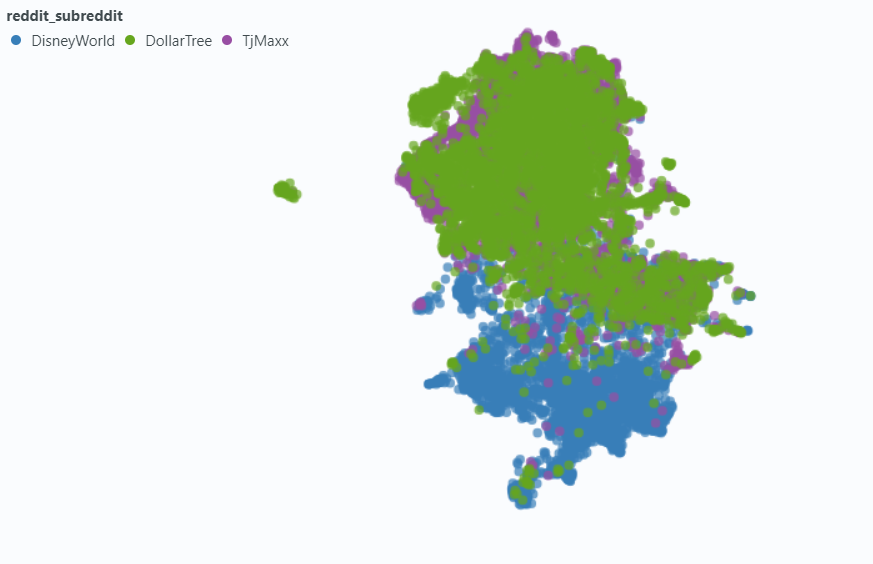
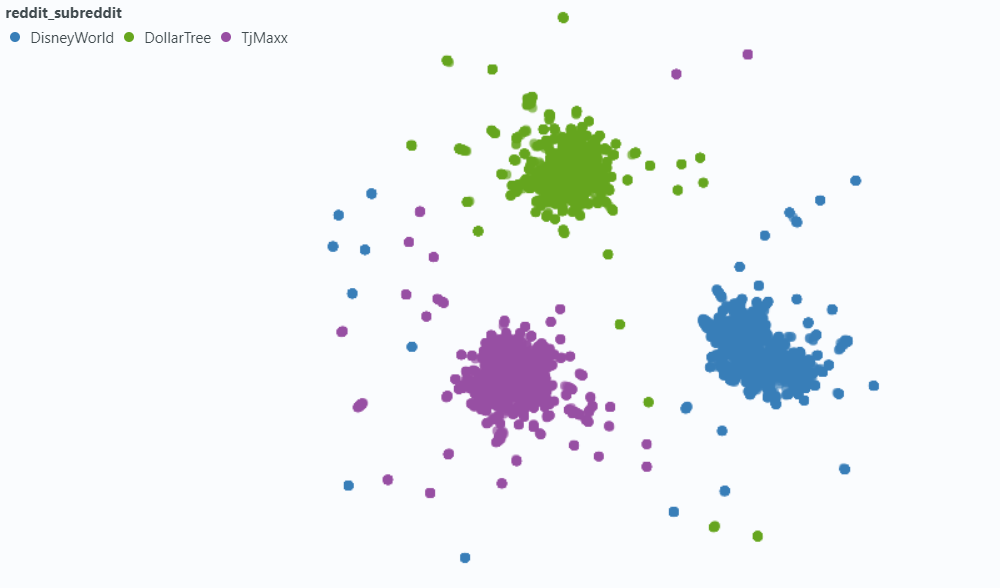
استخدمنا الأضواء لتصور التأثير على عينة صغيرة من بياناتنا.
التضمين بدون بيانات تعريف:
التضمين مع البيانات الوصفية:
لقد اخترنا LocentB (Link) للتعامل مع احتياجات قاعدة بيانات المتجه. LocentBeB هو خيار مفتوح المصدر ، ويوفر التكامل مع كل من Python و Polars ، وكلاهما نعتمد عليه بشكل كبير.
يوفر LocationB مزيجًا من مؤشر الملفات المقلوب (IVF) وكمية المنتج (PQ) لبناء مؤشر تقريبي أقرب جيران (ANN).
يمكن ضبط كلا الجزء من فهرس IVF-PQ عن طريق ضبط المعلمات التالية:
قمنا بإصلاح معلمات الفهرسة ، وتبادوا معلمات الاسترجاع. رغم ذلك ، إذا سمح الوقت ، فقد نختلف لمعرفة كيف تتأثر أوقات الاسترجاع والدقة.
إلى جانب معلمات الاستعلام المدمجة في مؤشر ANN الخاص بنا ، قمنا بتنوع متغيرات أخرى قبل الاسترجاع وما بعد الاسترجاع لمحاولة تحسين نتائجنا الإجمالية.
أثناء وضع علامة على البيانات ، لاحظنا نوعًا شائعًا من النتيجة "ذات الصلة ولكن غير ذات صلة": reddit_text الذي طرح سؤالًا مشابهًا للاستعلام نفسه.
معظم الوقت ، جاءت هذه النصوص من submission (على عكس التعليق). لذلك ، قد تكون إحدى الطرق لمحاولة رفع النتائج ذات الصلة هي حذفها من البحث المتجه. هذا سهل بما فيه الكفاية ، بالنظر إلى أن هذه المعلومات موجودة في بيانات التعريف الأصلية لدينا.
في كثير من الأحيان ، ولكن لا يزال يكفي أن نلاحظ ، سيظهر comment هذا العقار. لمحاولة الحد من تأثيرها ، قمنا بتصميم عمود بيانات التعريف is_short_question لمحاولة تحديد جميع أمثلة reddit_text التي طرحت أسئلة قصيرة (وبالتالي كان من غير المحتمل تقديم معلومات مفيدة للإجابة على هذه الأسئلة) حتى يمكن تصفيةها أيضًا قبل البحث.
من أجل تحسين ترتيب النتائج بعد الاسترجاع ، قمنا بتصميم بعض البيانات الوصفية الدهنية التي قد تسمح لنا بالاستفادة من المعلومات التي يقدمها محتوى الردود.
لقد صممنا نوعين من البيانات الوصفية:
sentiment الردود و ،agree_distance (و disagree_distance ) للردود. في حالة reply_sentiment ، استخدمنا نموذجًا معالجة اللغة الطبيعية المدربين مسبقًا يسمى "MRM8488/Distilroberta-finetonged-finalsial-news-sentiment-sentiment" ، لقياس النغمة العاطفية وراء النصوص. ساعدنا هذا النموذج في تصنيف كل رد على فئات مثل الإيجابية أو المحايدة أو السلبية. ثم تم تجميع الدرجات المشاعر لجميع الردود لتعكس المشاعر الشاملة تجاه كل منشور أصلي والتعليقات التالية. الافتراض الأساسي هنا هو أن المنشورات التي تولد في الغالب من الردود الإيجابية من المحتمل أن تكون بناءة وغنية بالمعلومات ، وبالتالي بمثابة وكيل لتأييد المستخدمين المشابهة للضغط في Reddit. كانت فرضياتنا هي أن المنشور الذي يحتوي على ردود أكثر إيجابية سيكون أكثر عرضة لاحتواء معلومات مفيدة.
في حالة agree_distance قمنا بقياس المسافة بين كل reddit_text ومجموعة من "عبارات الموافقة". ثم ، كلما كان هناك تقديم أو تعليق ، أضفنا top_reply_agree_distance و avg_reply_agree_distance . كانت فرضيتنا هي أن المشاركات التي تحتوي على ردود أقرب إلى عبارات "الموافقة" ستكون أكثر عرضة لاحتواء المعلومات ذات الصلة. وبالمثل ، فإن المشاركات التي تحتوي على ردود كانت أقرب إلى عبارات "الاختلاف" ستكون أقل احتمالًا.
عند إعادة التصنيف ، كانت النتائج مع انخفاض avg_reply_agree_distance أعلى ، وكانت النتائج مع انخفاض avg_reply_disagree_distance أقل.
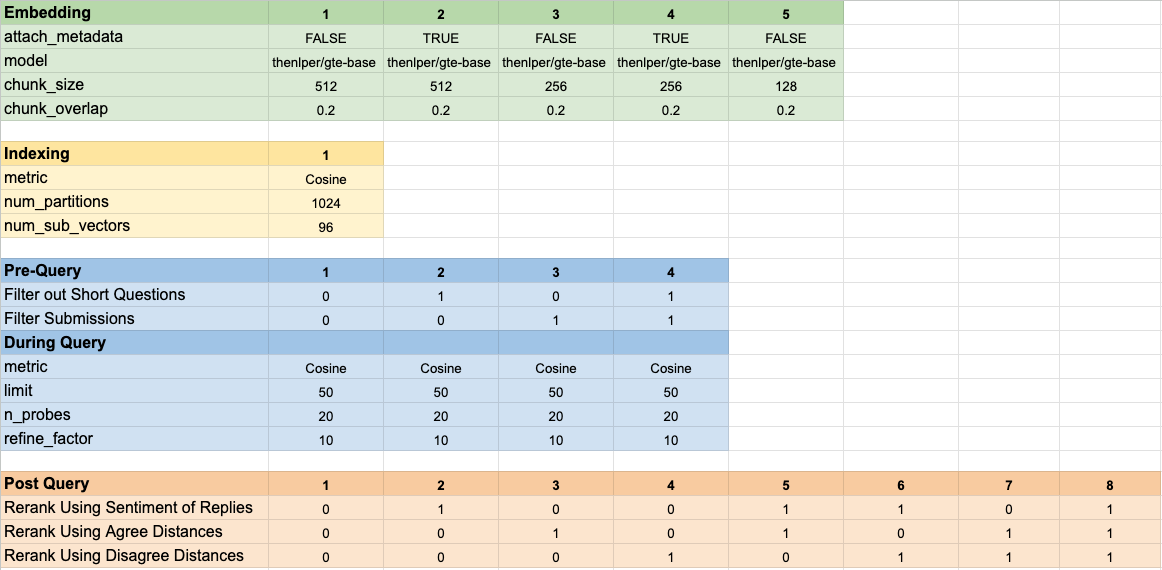
اختبرنا 160 تكوينات نموذج مختلفة. تضمن كل تكوين اختيار التضمين ، واستراتيجية لتصفية الاختبارات قبل إجراء بحث المتجه الخاص بنا ، واستراتيجية لإعادة تشغيل النتائج التي تم استردادها.
تم تلخيص هذه المعلمات المفرطة في الصورة أدناه:
كان لدينا هدفين رئيسيين كان لدينا في الاعتبار عند تقييم نتائجنا:
على الرغم من أن وقت الاسترجاع سهل بما يكفي لقياسه ، إلا أننا نحتاج إلى تطوير بعض الأدوات لقياس تقدمنا في تصنيف النتائج.
لإنشاء خط أساس لتقييم تصنيف النتائج ، وصفنا يدويًا مجموعة فرعية من النتائج لإنشاء مقياس الأولي الأولي. للقيام بذلك ، أنشأنا استفسارين لكل مجموعة من مجموعات البيانات الثلاثة عشر في مجموعة التدريب الخاصة بنا ، ووصفنا أفضل 20 نتيجة تم استردادها لكل استعلام. تم تصنيف النتائج على النحو التالي:
لكل زوج من زوج الاستعلام ، تم تحديد العلامة النهائية عن طريق التصويت التعددي ، مع الافتراضات التي تتخلف عن صلة بأقل صلة. ثم تم استخدام هذه البيانات المسمى يدويًا لتحديد النتائج.
استخدمنا ثلاث مقاييس لتصنيف النتائج. كل منها عبارة عن نسخة معدلة من مقياس نظام التوصية ، تم تكييفه مع حالة الاستخدام الخاصة بنا حيث لا نملك حقيقة واضحة ، أو تصنيفًا ثابتًا للنتائج ذات الصلة من الأكثر أهمية إلى الأقل صلة.
يعطي هذا المقياس درجة تشير إلى مدى قرب النتيجة المعروفة الأولى المعروفة. يتم تحقيق درجة مثالية من 1 إذا كانت النتيجة العليا لكل استعلام ذات صلة.
لحساب الترتيب المتبادل لاستعلام معين ، طبقنا الصيغة التالية:
في التطبيقات القياسية ، هناك نتيجة "الحقيقة الأرضية" المعروفة. في تطبيقنا المعدل ، قبلنا أي نتيجة معروفة ذات صلة بالحقيقة الأرضية.
ثم قمنا بحساب متوسط هذه الدرجات عبر جميع استفساراتنا القياسية للوصول إلى المرتبة المتبادلة المتوسطة.
يعطي هذا المقياس درجة تشير إلى عدد النتيجة المعروفة المعروفة التي تظهر بالقرب من الأعلى. يتم تحقيق درجة مثالية من 1 إذا ظهرت جميع النتائج المعروفة ذات الصلة كأفضل النتائج لجميع الاستعلامات (مع عدم وجود نتيجة غير مسموعة أعلى من أي نتيجة معروفة ذات صلة.)
لحساب الرتبة المتبادلة الممتدة لاستعلام معين ، طبقنا الصيغة التالية:
أين
أين
في التطبيقات القياسية ، كل نتيجة ذات صلة لها رتبتها الخاصة ، ومساهمتها في النتيجة الإجمالية تأخذ في الاعتبار هذا الرتبة كموقفها المتوقع في النتائج. في تطبيقنا المعدل ، قدمنا نفس المساهمة في أي نتيجة معروفة ذات صلة ظهرت أعلاه
ثم قمنا بحساب متوسط هذه الدرجات عبر جميع استفساراتنا القياسية للوصول إلى المرتبة المتبادلة المتوسطة.
غالبًا ما يتم استخدام الربح التراكمي المخفض (DCG) كمقياس لتقييم أداء محرك البحث ، ويقيس كفاءة الخوارزمية في وضع النتائج ذات الصلة في أعلى قائمة الاسترجاع. للحصول على قائمة من ردود الطول
أين
نظرًا لأن درجة DCG تعتمد بشدة على طول قائمة الاسترجاع ، نحتاج إلى تطبيعها بحيث يكون التسجيل متسقًا عبر سيناريوهات استرجاع الاستعلام مع عدد متغير من النتائج. درجة الربح التراكمي المخفض (NDCG) في الموضع
حيث
يمكن لـ NDCG أن تحصل على درجة الأهمية الترتيبية (1 لرواية عالية ، 2 بالنسبة إلى إلى حد ما ، على هذا النحو). نقوم بتعديل مخطط التسجيل لحالتنا ، من خلال تحويل ملصقاتنا البشرية (1-RELEVANT ، 2 ذات الصلة ولكن غير ذات صلة ، 3 لا صلة) إلى مخطط تسجيل ثنائي. تم إعطاء النتائج مع التسمية البشرية = 1 درجة صلة = 1 ، وتم إعطاء كل شيء آخر درجة صلة من 0. وقد تم ذلك لضمان أن أفضل تكوين ، كما تمليه درجة NDCG ، يجب أن يعيد فقط النتائج ذات الصلة للغاية. بعد ذلك ، قمنا بحساب درجة NDCG من استعلاماتنا القياسية وبلغنا متوسطها للحصول على درجة NDCG المتوسطة لتكوين معين. تم حساب درجات DCG وعشرات IDCG عن طريق الإعداد
أين
استخدمنا معلمات النموذج التالية كخط أساسي للمقارنة:
يحقق التكوين الأساسي الدرجات التالية عبر مقاييسنا:
| متري | نتيجة | رتبة (من أصل 160) |
|---|---|---|
| يعني الرتبة المتبادلة | 0.626031 | 46 |
| متوسط متوسط الترتيب المتبادل | 0.427189 | 84 |
| مكاسب تراكمية مخفضة تطبيع | 0.714459 | 84 |
| متوسط الرتبة الإجمالية | 71.33 |
التكوين الذي حقق أفضل نتيجة إجمالية (أعلى متوسط رتبة عبر المقاييس):
يحقق هذا التكوين الدرجات التالية عبر مقاييسنا:
| متري | نتيجة | رتبة (من أصل 160) |
|---|---|---|
| يعني الرتبة المتبادلة | 0.742735 | 7 |
| متوسط متوسط الترتيب المتبادل | 0.599379 | 9 |
| مكاسب تراكمية مخفضة تطبيع | 0.806476 | 1 |
| متوسط الرتبة الإجمالية | 5.67 |
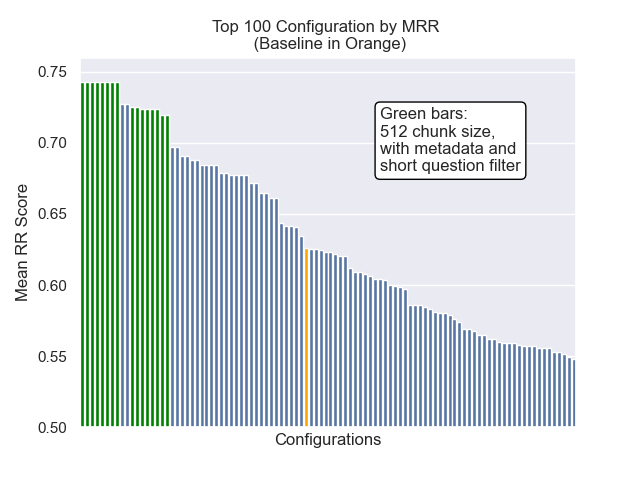
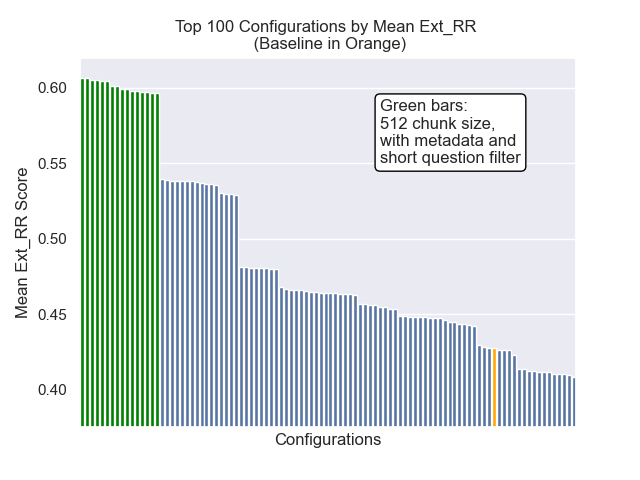
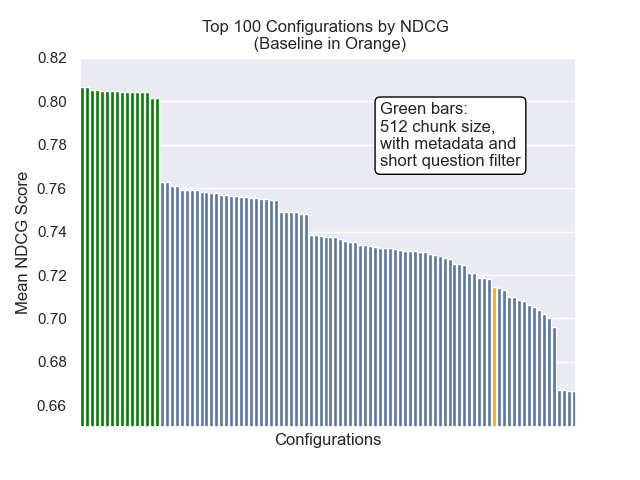
أدناه ، يمكننا أن نرى الموضع النسبي لتكوين خط الأساس إلى الأعلى بشكل عام.
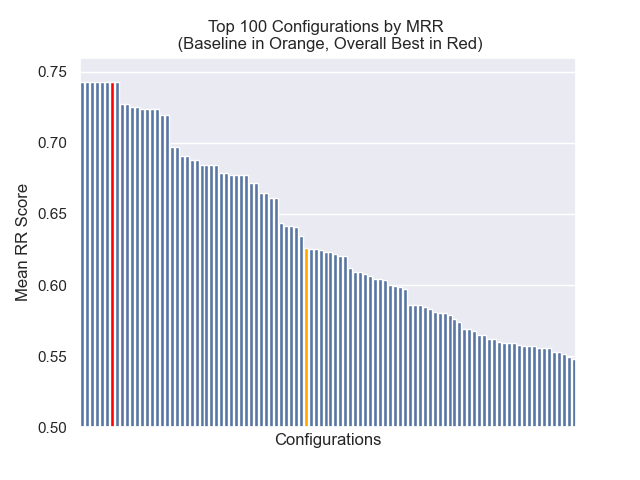
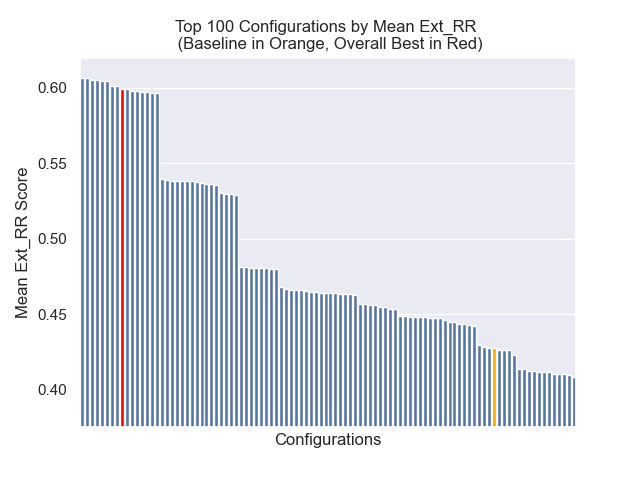
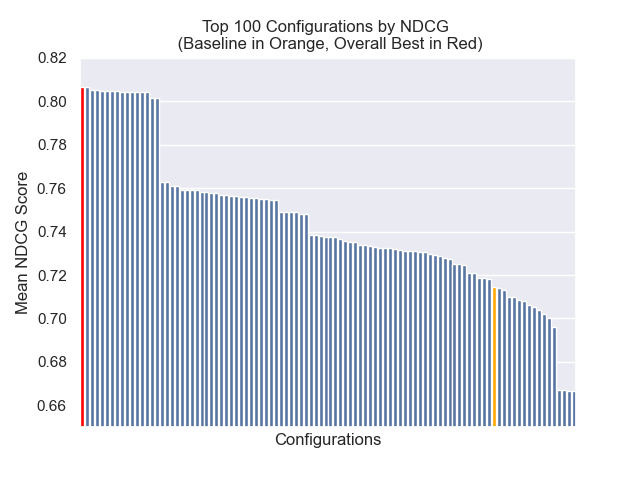
يبدو أن انخفاض حجم القطعة كان له تأثير سلبي بشكل عام على النتائج.
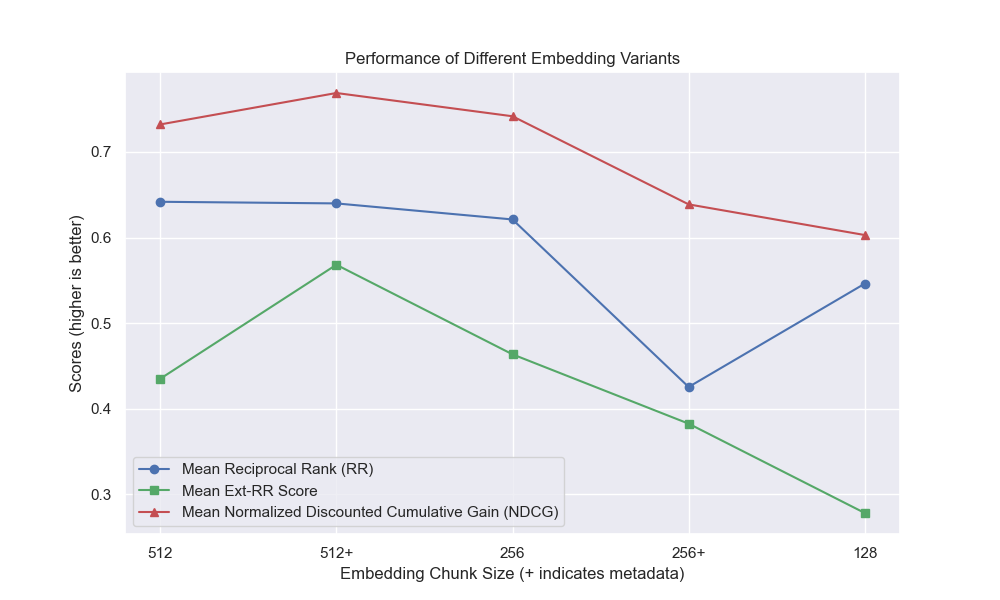
أيضًا ، كان لتصفية الأسئلة القصيرة قبل الاسترجاع تأثيرًا إيجابيًا بغض النظر عن خيارات مقياس الفائقة الأخرى.
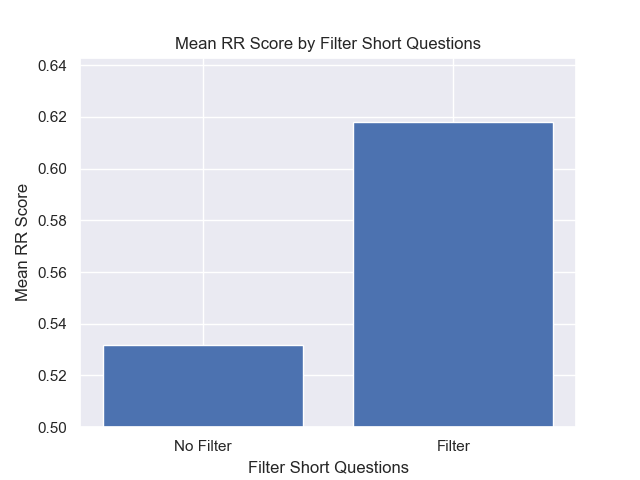
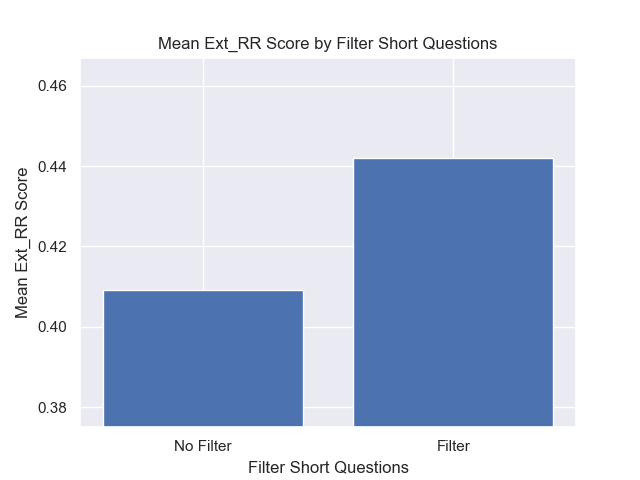
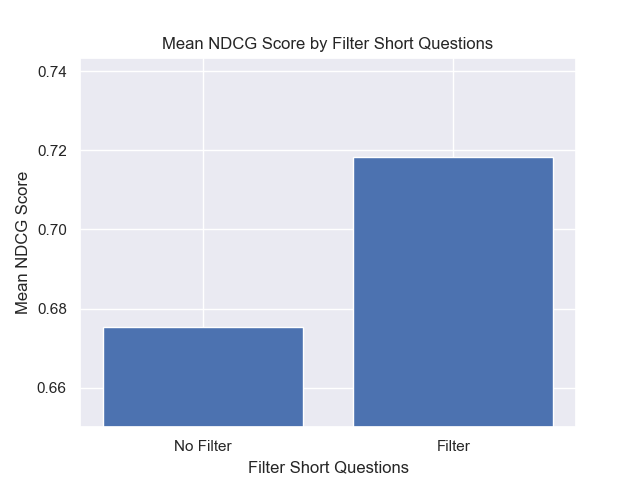
إذا قمنا بتسليط الضوء على تلك التكوينات التي تحتوي على هذه الاختلافات معًا (512 حجم قطعة ، مع بيانات تعريف إضافية ، وتصفية بأسئلة قصيرة) ، نرى مدى أدائها بالنسبة إلى التكوينات الأخرى.
بعض مجالات التحقيق المستقبلي المحتمل:


