erdos_paware
1.0.0
このプロジェクトは、エルドス研究所のディープラーニングブートキャンプ(春、2024年)の一部として、マルコスオルティス、サヤンタンロイ、カルティックプラブ、クリスティーナノウルズ、ディプタニルロイによって完了しました。
私たちのプロジェクトについては、以下に詳しく説明します。PAW_DEMO/ディレクトリで提供されるデモンストレーションノートブックとデータを通じて主要な手順に従うことができます。
最初の4つのノートブックは、データの小さなサブセットを使用してデモを歩きます。最後のノートブックは、データセット全体の結果の概要を提供しました。
任意のユーザークエリとヒューマン生成コンテンツのデータセットを考慮して、アルゴリズムを構築して、データセットの関連コンテンツを識別およびランク付けして、一致セットを迅速かつ正確に取得できるようにします。
当社のプロジェクトの結果の最終的なアプリケーションは、検索された世代(RAG)パイプラインで使用されていることを知っています。この最近の調査論文は、大規模な言語モデル(LLMS)のRAGの現在の状態を説明しました。これは、特定のタスクとデータに適しているツールについての洞察を提供するのに役立ちました。
ぼろきれの主なステップは次のとおりです。
当社に提供される生データは、34のsubredditsからのRedditからの5,528,298の投稿で構成されています。このデータは、データ辞書とともに寄木細工ファイルで提供されました。
このプロジェクトでは、RAGプロセスの最初の2つのステップであるインデックスと検索に焦点を当てています。
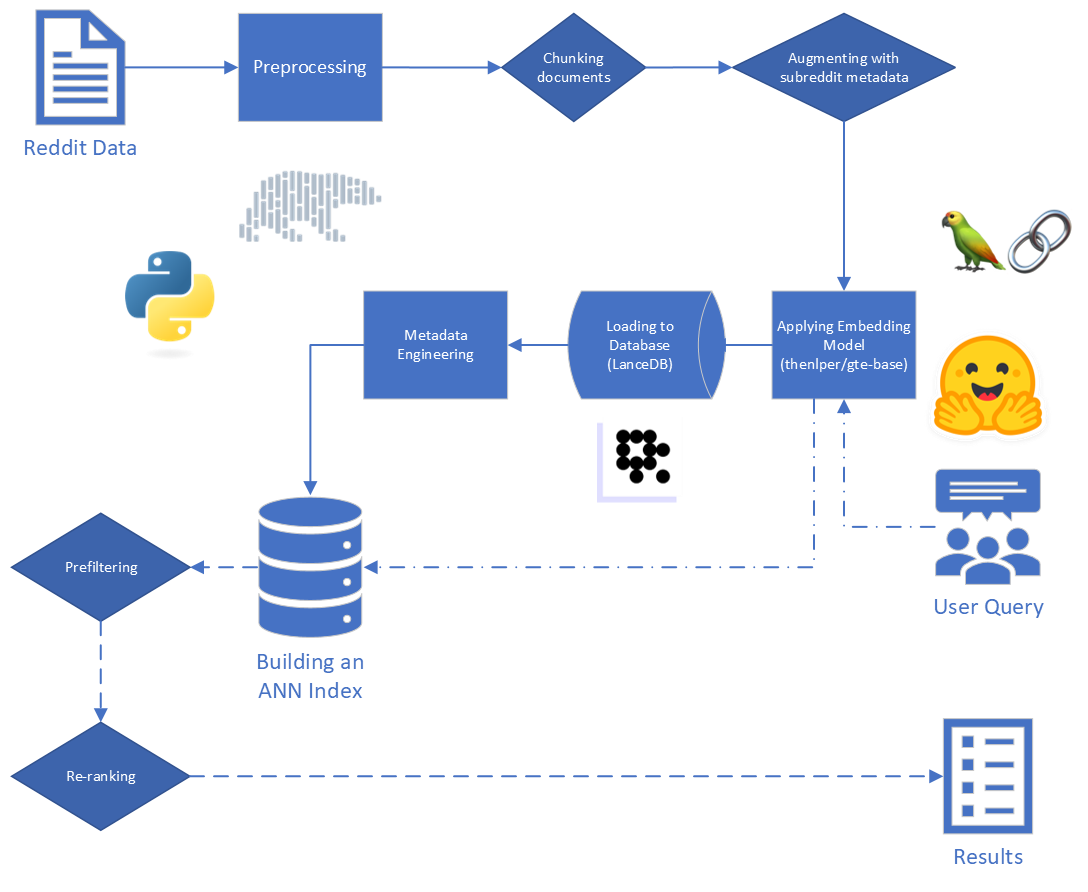
生データから始めて、基本的なクリーニングを実行しました。
"[deleted]"または"removed"のreddit_text値で行をドロップしました。reddit_text値で行を除外することによって行われました。それらが後で役立つ可能性がある場合に備えて、私たちはすぐに短い一般的なフレーズをドロップしたくありませんでした(エンジニアリングされたメタデータを使用してください)。reddit_text値を処理しました。reddit_titleがreddit_textのプロキシであることが明らかになりました。したがって、これらのインスタンスでは、空のreddit_text reddit_titleに置き換えました。 Bert Frameworkに基づいた一般的なテキスト埋め込み(GTE)モデルのベースバージョンを使用しました。 Huggingfaceのドキュメント:リンク。
このモデルは、合理的なサイズ(0.22GB)であると思われ、オープンソースであり、最大512トークンの長さまでのテキストを埋め込むことができるため、このモデルを選択しました。 250m未満のパラメーターのリンクを持つ他のオープンソース文の変圧器と比較して、クラスタリングと検索で特にうまく機能します。
さらに、トレーニングの一部はRedditデータを使用して行われ、その魅力が追加されました。
他のモデルでの実験を検討しましたが、新しいモデルごとにデータセットを埋め込むという計算コストが高いため、将来の作業のためにこの手段を保存します。
埋め込みモデルと、Langchainが提供する顔の埋め込みツールを抱きしめるために、Stbertが提供するSente Transformers Frameworkを使用して、埋め込みモデルを実装しています
埋め込み中、次のパラメーターを検討しました。
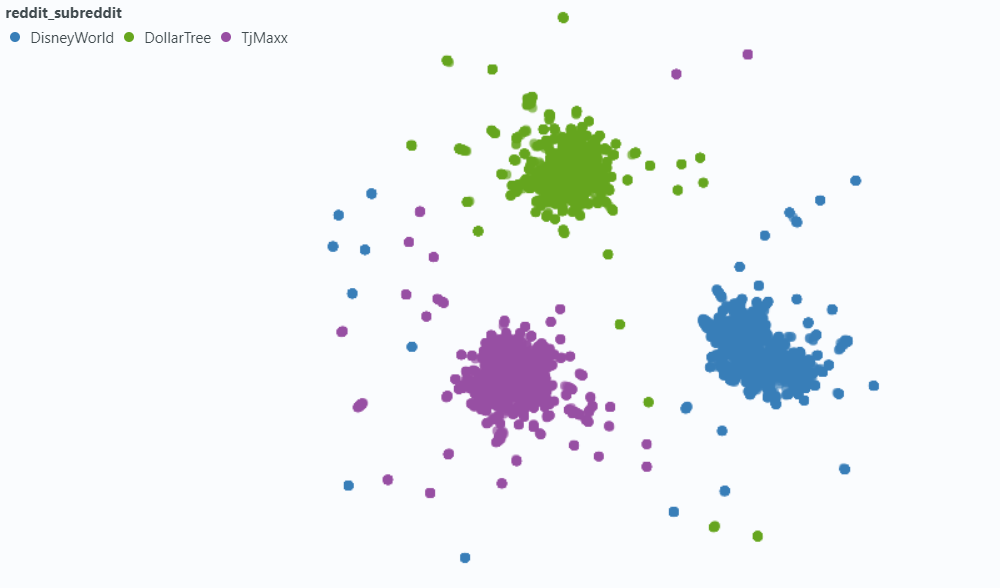
chunk_size :ドキュメントとして埋め込むテキストの最大長chunk_overlap :ドキュメントをチャンクに分割する必要があるときはいつでも、どれだけ重複すべきかまた、埋め込む前にメタデータをチャンクに取り付けることも実験しました。これを行うには、埋め込む前にテキストチャンクの開始にsubredditタイトル(または近似)を追加するだけです。たとえば、FedExersに「ここで働くのが本当に好きだ」と言っているコメントがある場合、「FedEx」をチャンクの開始に追加し、「FedEx n n私はここで働くのが本当に好きです...」
私たちの直観は、投稿に議論している会社の名前を明示的に含めていない場合、Subredditからの情報と、これがそのベクトルがクエリに近いと推測するかもしれないということでした。たとえば、「なぜ従業員はディズニーで働くのが好きなのですか?」と尋ねた場合です。 「なぜ従業員はFedExで働くのが好きなのですか?」私たちの希望は、メタデータを追加すると、上記のコメントがFedEx Queryの結果に高く表示され、おそらくディズニークエリの結果が低くなる可能性が高いことです。
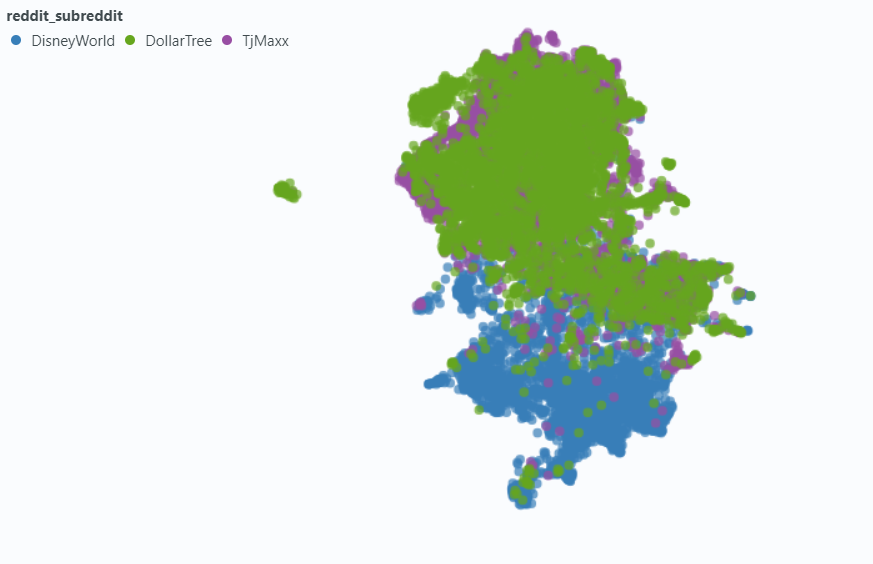
スポットライトを使用して、データの小さなサンプルに対する効果を視覚化しました。
メタデータなしで埋め込む:
メタデータに埋め込む:
Vectorデータベースのニーズを処理するために、LancedB(リンク)を選択しました。 LancedBはオープンソースのオプションであり、PythonとPolarsの両方と統合を提供します。どちらも私たちが大きく依存しています。
LancedBは、近似最寄りの傍(ANN)インデックスを構築するために、ファイルインデックス(IVF)と製品量子化(PQ)の組み合わせを提供します。
IVF-PQインデックスの両方の部分は、次のパラメーターを調整することで微調整できます。
インデックス作成パラメーターを修正し、検索パラメーターを変更しました。ただし、時間が許せば、検索時間と精度がどのように影響するかを確認するために、両方を変える可能性があります。
ANNインデックスに組み込まれているクエリパラメーターに加えて、他のさまざまな網状以前の変数とretリーバル後の変数を変えて、全体的な結果を改善しようとしました。
データにラベルを付けている間、「関連性がないが関連性がない」結果の一般的なタイプの結果に気付きました。クエリ自体と同様の質問を提起したreddit_textです。
ほとんどの場合、これらのテキストは(コメントとは対照的に) submissionから来ました。したがって、より関連性の高い結果を高めようとする1つの方法は、ベクター検索からこれらを省略することです。この情報が元のメタデータに含まれていることを考えると、これは十分に簡単です。
あまり頻繁ではありませんが、まだ気づくには十分であるため、 commentこのプロパティを示します。それらの影響を抑えようとするために、メタデータ列is_short_question設計して、短い質問を提起したすべてのreddit_text例を特定しようとします(したがって、それらの質問に答えるための有用な情報を提供することはほとんどありませんでした)。
検索後の結果のランキングを改善するために、返信コンテンツが提供する情報を活用できるようになる可能性のあるいくつかの熱心なメタデータを設計しました。
2種類のメタデータを設計しました。
sentimentの尺度とagree_distance (およびdisagree_distance )の尺度。 reply_sentimentの場合、「MRM8488/Distilroberta-Finetuned-Financial-News-Sentiment-Analysis」と呼ばれる事前に訓練された自然言語処理モデルを利用して、テキストの背後にある感情的なトーンを評価しました。このモデルは、ポジティブ、ニュートラル、ネガティブなどのカテゴリに各返信を分類するのに役立ちました。次に、すべての応答の感情スコアを集計して、各元の投稿と次のコメントに対する全体的な感情を反映しました。ここでの根本的な仮定は、主に肯定的な応答を生成する投稿は建設的かつ有益である可能性が高いため、RedditのUPVotesと同様のユーザー承認のプロキシとして機能する可能性が高いということです。私たちの仮説は、より肯定的な返信を伴う投稿には有用な情報が含まれる可能性が高いということでした。
agree_distanceの場合、各reddit_textと一連の「同意文」の間の距離を測定しました。次に、送信またはコメントに返信があるときはいつでも、 top_reply_agree_distanceとavg_reply_agree_distanceを追加しました。私たちの仮説は、「同意」ステートメントに近い返信を含む投稿は、関連情報を含む可能性が高いということでした。同様に、「同意しない」ステートメントに近い返信がある投稿は、関連する可能性が低くなります。
再ランキングの場合、 avg_reply_agree_distanceの低い結果が高くなり、 avg_reply_disagree_distanceが低いと結果が低くなりました。
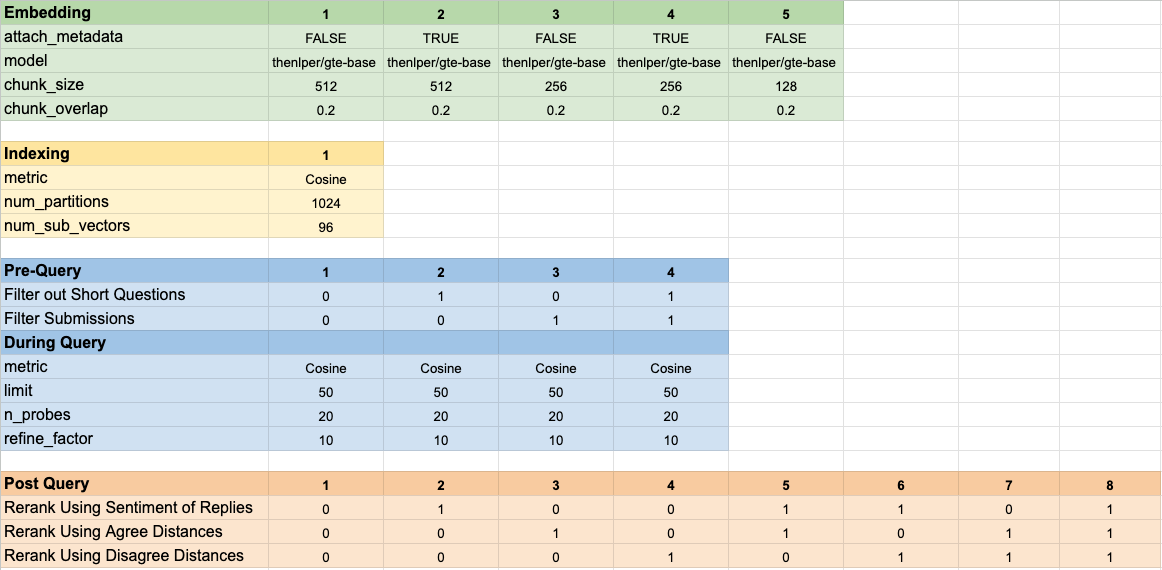
160の異なるモデル構成をテストしました。各構成には、埋め込みの選択、ベクトル検索を実行する前にテストをフィルタリングするための戦略、および取得された結果を再ランクする戦略が含まれていました。
これらのハイパーパラメーターは、以下の画像にまとめられています。
結果を評価する際に念頭に置いていた2つの主な目的がありました。
検索時間は測定するのに十分簡単ですが、結果ランキングの進捗を測定するためのツールを開発する必要がありました。
結果ランキングを評価するためのベースラインを確立するために、結果のサブセットを手動でラベル付けして、関連性の初期メトリックを確立しました。これを行うために、トレーニングセットの13のデータセットのそれぞれに2つのクエリを作成し、クエリごとに取得した上位20の結果にラベルを付けました。結果は次のようにラベル付けされました:
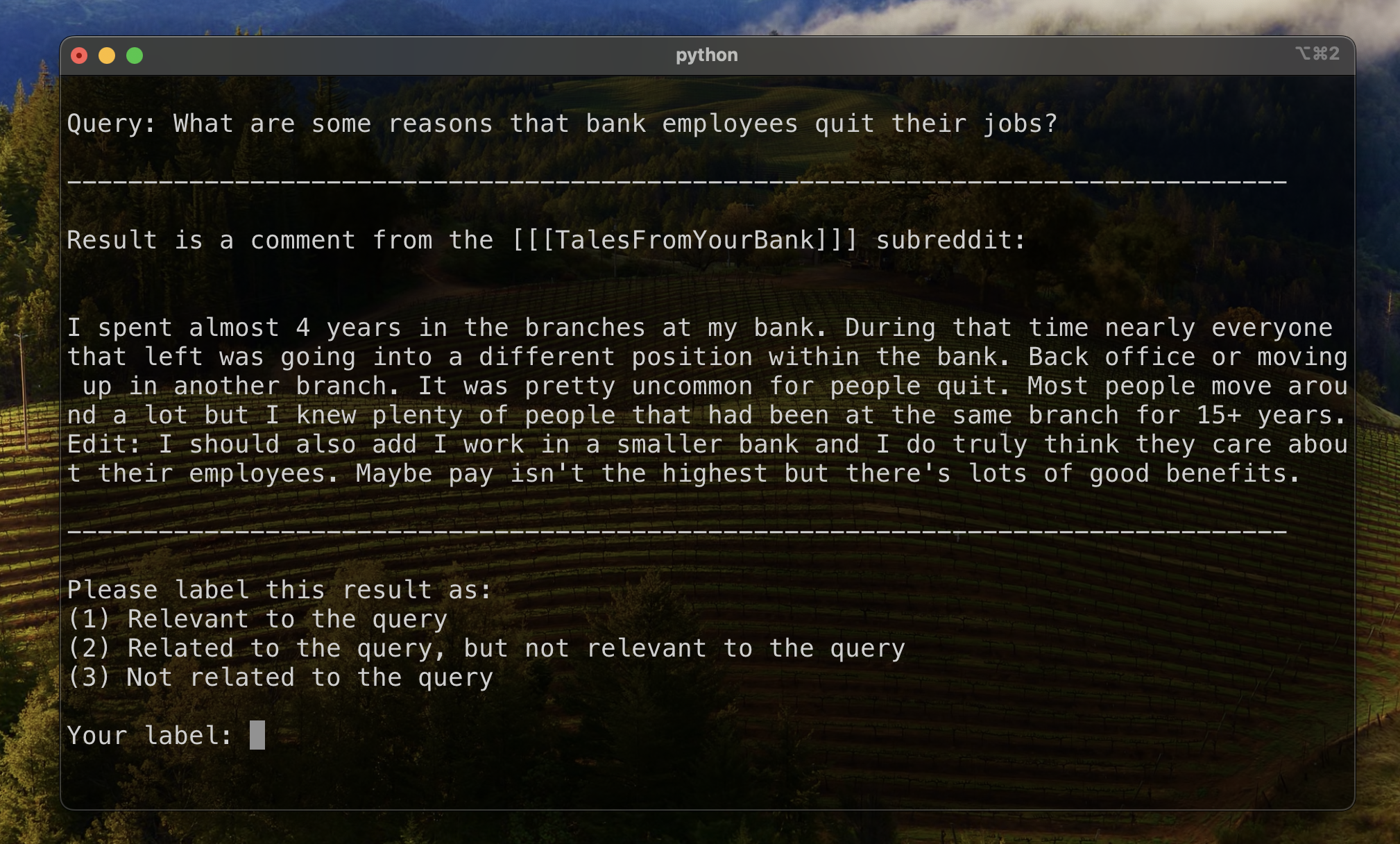
各クエリと結果のペアについて、最終ラベルは複数の投票によって決定され、絆はデフォルトの関連性が低くなりました。次に、この手動でラベル付けされたデータを使用して、結果を定量化しました。
ランキング結果に3つのメトリックを使用しました。それぞれが、明確な基本真実を持っていないユースケース、または最も関連性が最も関連性から最も関連性の高いものから関連する結果の確立されたランキングに適合した、推奨システムメトリックの変更されたバージョンです。
このメトリックは、最初に既知の関連する結果がどの程度近くに表示されるかを示すスコアを提供します。すべてのクエリのトップ結果が関連する場合、完全なスコア1が達成されます。
特定のクエリの相互ランクを計算するために、次の式を適用しました。
標準アプリケーションでは、既知の「グラウンドトゥルース」の結果が1つあります。変更されたアプリケーションでは、既知の関連する結果をグラウンドトゥルースとして受け入れました。
次に、すべての標準クエリにわたってこれらのスコアの平均を計算して、平均相互ランクに到達しました。
このメトリックは、既知の関連する結果の数が上部近くに表示されることを示すスコアを提供します。すべての既知の関連結果がすべてのクエリの最上位結果として表示される場合、1の完全なスコアが達成されます(既知の関連する結果よりも高く表示されていないラベルのない結果はありません)。
特定のクエリに拡張された相互ランクを計算するために、次の式を適用しました。
どこ
どこ
標準アプリケーションでは、関連する各結果に独自のランクがあり、全体的なスコアへの貢献度は、結果の予想される位置としてこのランクを考慮しています。変更されたアプリケーションでは、上に表示された既知の関連する結果に同じ貢献をしました
次に、すべての標準クエリにわたってこれらのスコアの平均を計算して、平均相互ランクに到達しました。
割引累積ゲイン(DCG)は、検索エンジンのパフォーマンスを評価するためにメトリックとして採用されることがよくあり、検索リストの上部に関連する結果を配置する際のアルゴリズムの効率を測定します。長さの応答のリスト
どこ
DCGスコアは検索リストの長さに強く依存しているため、結果の数が変化するクエリ検索シナリオ全体でスコアリングが一貫しているように正規化する必要があります。正規化された割引累積ゲイン(NDCG)の位置でのスコア
ここで
NDCGは、順序関連スコアを取得できます(非常に関連性が高い場合は1、ある程度関連する場合は2)。人間のラベル(1つの関連性、2関連ではあるが関連性がない、3つの関連性)をバイナリスコアリングスキームに変換することにより、私たちのケースのスコアリングスキームを変更します。 Human Label = 1の結果に関連スコア= 1が与えられ、他のすべてに関連スコア0が与えられました。これは、NDCGスコアによって決定される最適な構成が非常に関連性の高い結果のみを返すことを保証するために行われました。次に、標準クエリのNDCGスコアを計算し、平均化して特定の構成の平均NDCGスコアを取得しました。 DCGスコアとIDCGスコアは、設定によって計算されました
どこ
比較のために、次のモデルパラメーターをベースラインとして使用しました。
ベースライン構成は、メトリック全体で次のスコアを達成します。
| メトリック | スコア | ランク(160のうち) |
|---|---|---|
| 平均相互ランク | 0.626031 | 46 |
| 拡張平均相互ランク | 0.427189 | 84 |
| 正規化された割引累積ゲイン | 0.714459 | 84 |
| 平均全体のランク | 71.33 |
全体的な結果を達成した構成(メトリック全体で最高の平均ランク):
この構成は、メトリック全体で次のスコアを達成します。
| メトリック | スコア | ランク(160のうち) |
|---|---|---|
| 平均相互ランク | 0.742735 | 7 |
| 拡張平均相互ランク | 0.599379 | 9 |
| 正規化された割引累積ゲイン | 0.806476 | 1 |
| 平均全体のランク | 5.67 |
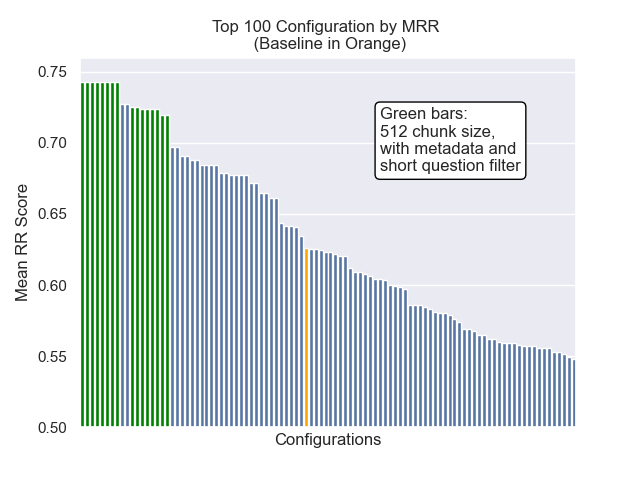
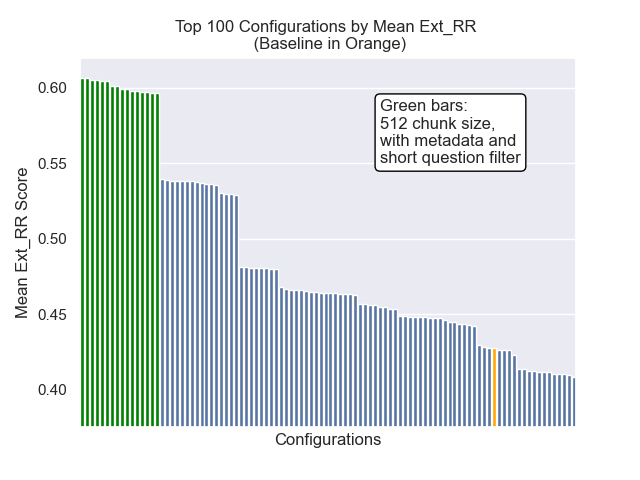
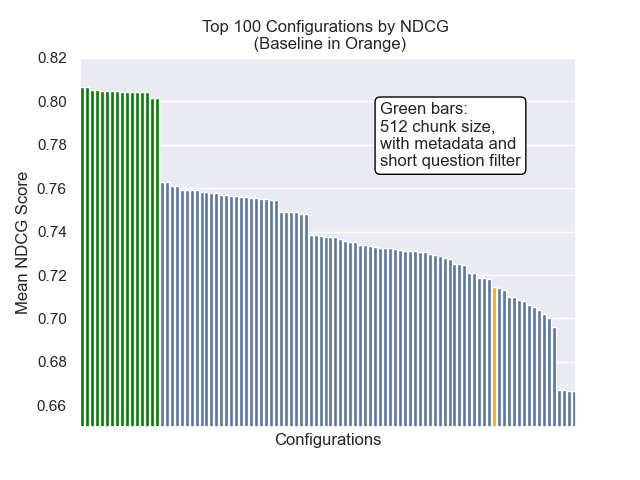
以下に、ベースライン構成の相対的な位置を全体的に上部に確認できます。
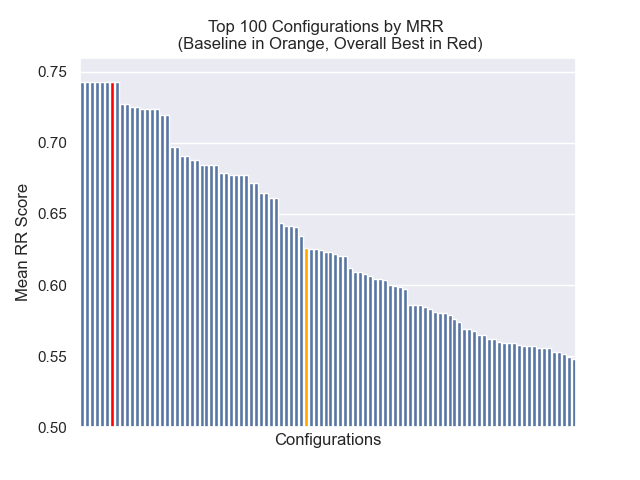
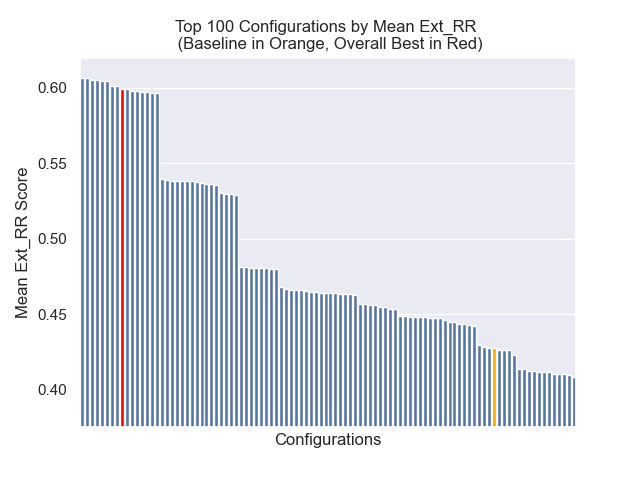
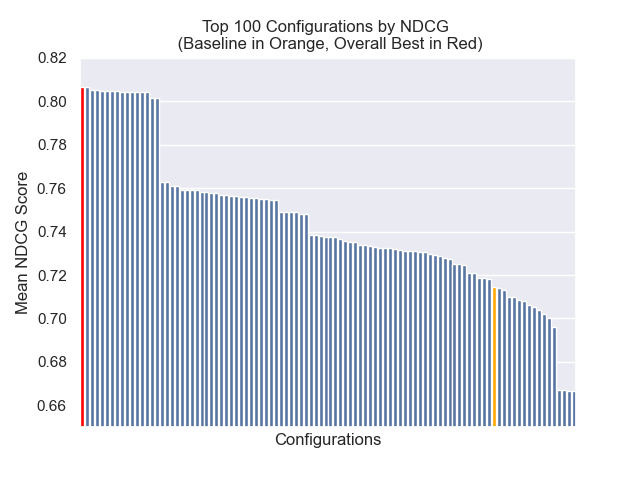
チャンクサイズの減少は、結果に一般的にマイナスの影響を与えたように見えました。
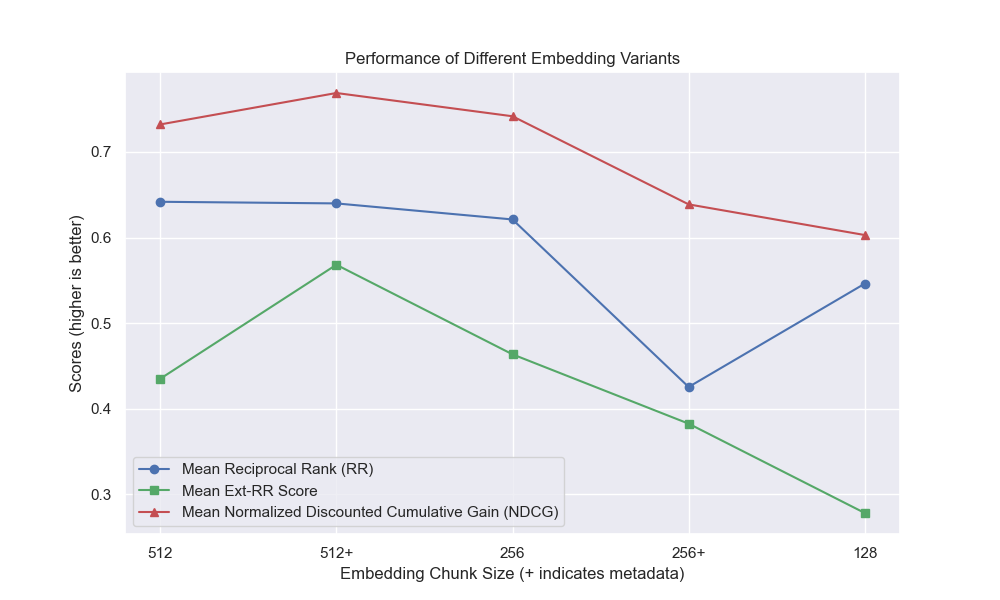
また、検索前に短い質問を除外することは、他のハイパーパラメーターの選択に関係なくプラスの影響を与えました。
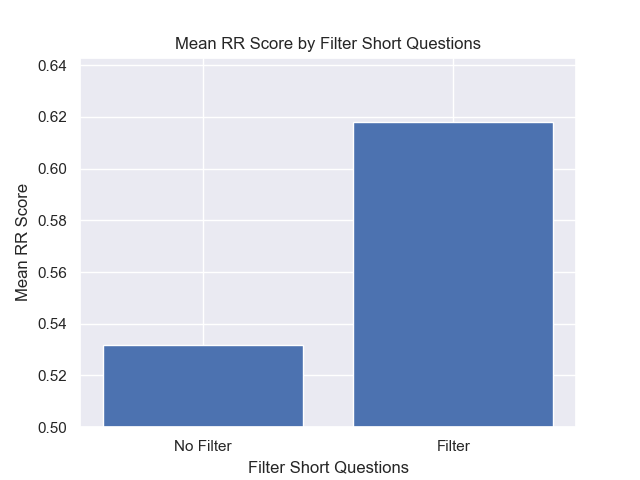
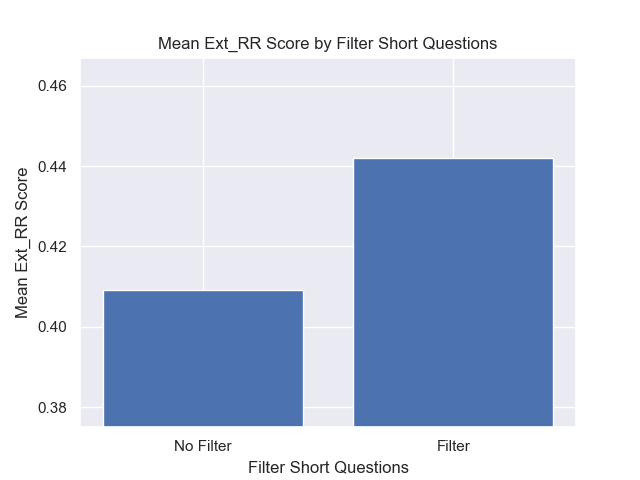
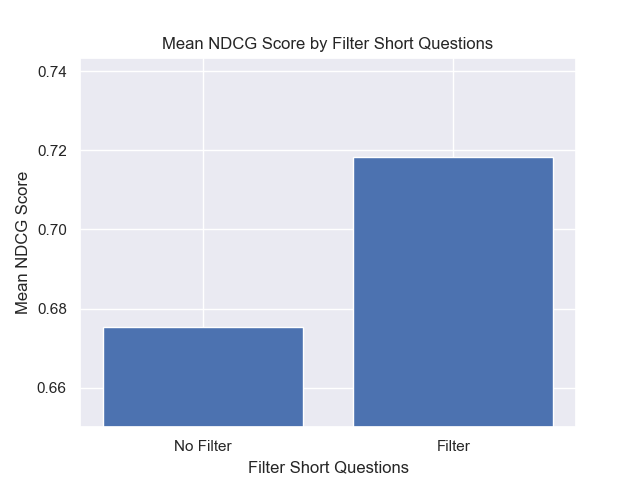
これらのバリエーションを一緒に含む構成(512チャンクサイズ、追加のメタデータを使用して、短い質問によるフィルタリング)のみを強調する場合、他の構成と比較してそれらがどれだけうまく機能するかがわかります。
潜在的な将来の調査のいくつかの分野:


