erdos_paware
1.0.0
โครงการนี้เสร็จสมบูรณ์โดย Marcos Ortiz, Sayantan Roy, Karthik Prabhu, Kristina Knowles และ Diptanil Roy ซึ่งเป็นส่วนหนึ่งของค่าย Boot Deep Institute Erdös (ฤดูใบไม้ผลิ, 2024)
โครงการของเรามีรายละเอียดด้านล่างและคุณสามารถทำตามขั้นตอนหลักผ่านสมุดบันทึกการสาธิตและข้อมูลที่ให้ไว้ในไดเรกทอรี PAW_Demo/ ไดเรกทอรี
โน้ตบุ๊กสี่เล่มแรกเดินผ่านการสาธิตโดยใช้ชุดข้อมูลย่อยขนาดเล็ก โน้ตบุ๊กล่าสุดให้ข้อมูลสรุปของผลลัพธ์ของเราในชุดข้อมูลทั้งหมด
ด้วยการสืบค้นผู้ใช้โดยพลการและชุดข้อมูลของเนื้อหาที่มนุษย์สร้างขึ้นสร้างอัลกอริทึมเพื่อระบุและจัดอันดับเนื้อหาที่เกี่ยวข้องในชุดข้อมูลเช่นชุดการจับคู่สามารถเรียกคืนได้อย่างรวดเร็วและแม่นยำ
เรารู้ว่าแอปพลิเคชันในที่สุดสำหรับผลลัพธ์ของโครงการของเรานั้นใช้ในไปป์ไลน์การดึง (RAG) รายงานการสำรวจเมื่อเร็ว ๆ นี้ซึ่งอธิบายถึงสถานะปัจจุบันของ RAG สำหรับแบบจำลองภาษาขนาดใหญ่ (LLMS) ช่วยให้ข้อมูลเชิงลึกเกี่ยวกับเครื่องมือที่เหมาะสมกับงานและข้อมูลเฉพาะของเรา
ขั้นตอนหลักในผ้าขี้ริ้วคือ:
ข้อมูลดิบที่ให้ไว้กับสหรัฐอเมริกาประกอบด้วยโพสต์ 5,528,298 โพสต์จาก Reddit จาก 34 subreddits ข้อมูลนี้มีให้ในไฟล์ Parquet พร้อมกับพจนานุกรมข้อมูล
สำหรับโครงการนี้เราเพ่งความสนใจไปที่สองขั้นตอนแรกของกระบวนการ RAG: การจัดทำดัชนีและการดึงข้อมูล
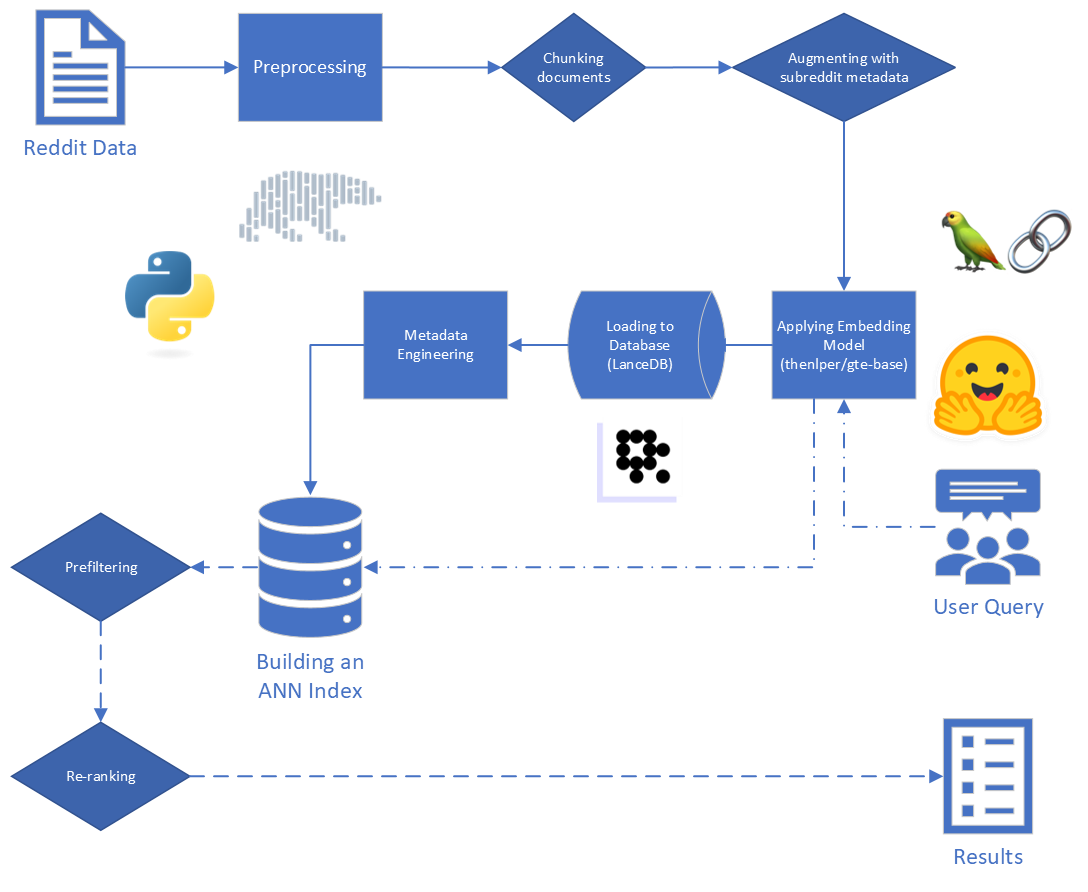
เริ่มต้นด้วยข้อมูลดิบเราทำการทำความสะอาดขั้นพื้นฐาน:
reddit_text ของ "[deleted]" หรือ "removed"reddit_text ที่มีความยาวอย่างน้อย 35 อักขระและปรากฏมากกว่า 7 ครั้ง เราไม่ต้องการวางวลีทั่วไปที่สั้นลงทันทีในกรณีที่พวกเขาอาจมีประโยชน์ในภายหลัง (ดูการใช้ข้อมูลเมตาที่ได้รับการออกแบบทางวิศวกรรม)reddit_text ที่ว่างเปล่าreddit_title เป็นพร็อกซีสำหรับ reddit_text ดังนั้นเราจึงแทนที่ reddit_text ที่ว่างเปล่าด้วย reddit_title ในอินสแตนซ์เหล่านี้ เราใช้รุ่นพื้นฐานของโมเดลข้อความทั่วไป Embeddings (GTE) ซึ่งใช้เฟรมเวิร์ก Bert เอกสารเกี่ยวกับ HuggingFace: ลิงค์
เราเลือกรุ่นนี้เพราะดูเหมือนว่าจะมีขนาดที่สมเหตุสมผล (0.22GB) มันเป็นโอเพ่นซอร์สและอนุญาตให้ฝังข้อความได้สูงสุด 512 โทเค็น มันทำงานได้ดีเป็นพิเศษในการจัดกลุ่มและการดึงข้อมูลเมื่อเทียบกับหม้อแปลงประโยคโอเพนซอร์สอื่น ๆ ที่มีพารามิเตอร์น้อยกว่า 250 เมตร: ลิงก์
นอกจากนี้ส่วนหนึ่งของการฝึกอบรมได้ดำเนินการโดยใช้ข้อมูล Reddit ซึ่งเพิ่มการอุทธรณ์
เราพิจารณาการทดลองกับโมเดลอื่น ๆ แต่เนื่องจากค่าใช้จ่ายในการคำนวณสูงของการฝังชุดข้อมูลด้วยแต่ละรุ่นใหม่เราจึงบันทึกช่องทางนี้สำหรับการทำงานในอนาคต
เราใช้กรอบการทำงานของประโยคที่จัดทำโดย Sbert เพื่อใช้โมเดลการฝังของเรารวมถึงการกอดเครื่องมือฝังใบหน้าที่จัดทำโดย Langchain
ในระหว่างการฝังเราพิจารณาพารามิเตอร์ต่อไปนี้:
chunk_size : ความยาวสูงสุดของข้อความที่จะฝังเป็นเอกสารchunk_overlap : เมื่อใดก็ตามที่เอกสารจำเป็นต้องแบ่งออกเป็นชิ้นพวกเขาควรทับซ้อนกันเท่าไหร่นอกจากนี้เรายังทดลองกับการติดตั้งข้อมูลเมตากับชิ้นก่อนที่จะฝัง ในการทำเช่นนี้เราเพียงเพิ่มชื่อ subreddit (หรือการประมาณ) ลงในจุดเริ่มต้นของข้อความที่มีก่อนที่จะฝัง ตัวอย่างเช่นหากมีความคิดเห็นใน Fedexers ที่บอกว่า“ ฉันชอบทำงานที่นี่มากเพราะ ... ” จากนั้นเราจะผนวก“ FedEx” เข้ากับจุดเริ่มต้นของก้อนและฝัง“ FedEx n n ฉันชอบทำงานที่นี่เพราะ ... ”
สัญชาตญาณของเราคือในกรณีที่โพสต์ไม่ได้รวมชื่อของ บริษัท ที่พวกเขากำลังพูดคุยกันอย่างชัดเจนเราอาจอนุมานว่าข้อมูลจาก subreddit และสิ่งนี้อาจทำให้เวกเตอร์ใกล้เคียงกับการสืบค้นของเรามากขึ้น ตัวอย่างเช่นถ้าเราถามว่า“ ทำไมพนักงานถึงทำงานที่ดิสนีย์” และ“ ทำไมพนักงานชอบทำงานที่ FedEx?” ความหวังของเราคือการเพิ่มข้อมูลเมตาทำให้มีโอกาสมากขึ้นที่ความคิดเห็นข้างต้นแสดงให้เห็นถึงผลลัพธ์ที่สูงขึ้นสำหรับการสืบค้น FedEx และอาจลดลงในผลลัพธ์สำหรับการสืบค้นดิสนีย์
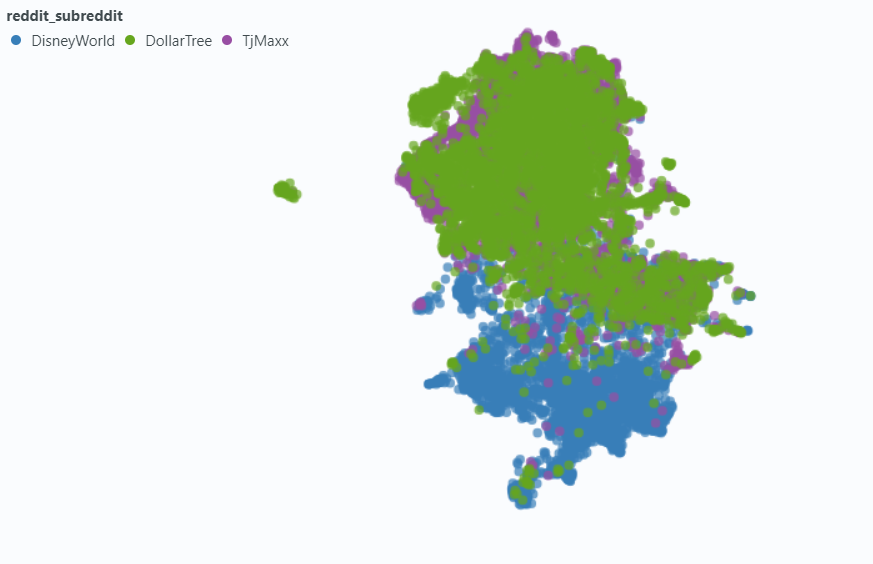
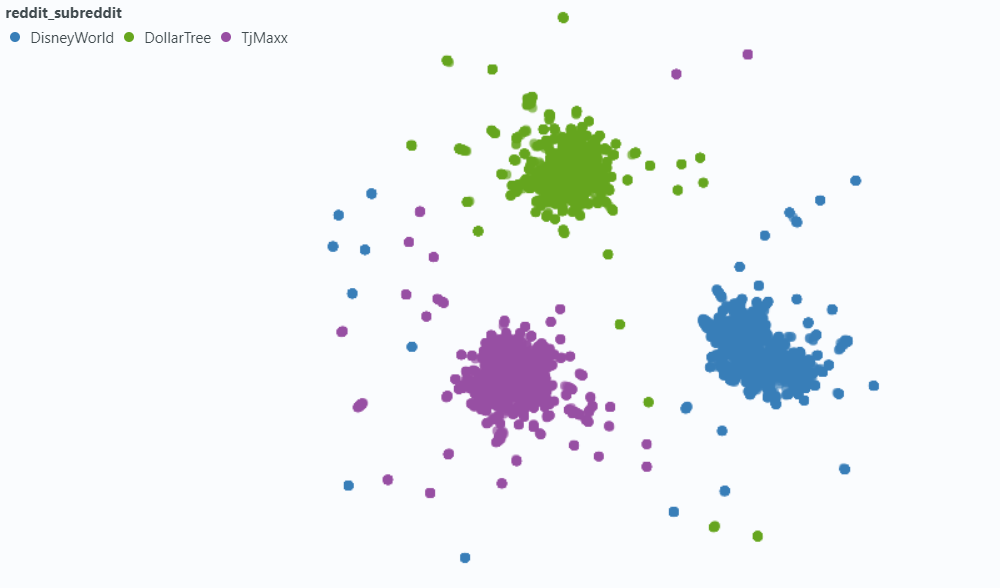
เราใช้สปอตไลท์เพื่อแสดงให้เห็นถึงผลกระทบต่อตัวอย่างข้อมูลขนาดเล็กของเรา
ฝังโดยไม่มีข้อมูลเมตา:
ฝังด้วยข้อมูลเมตา:
เราเลือก LancedB (ลิงก์) เพื่อจัดการกับความต้องการฐานข้อมูลเวกเตอร์ของเรา LancedB เป็นตัวเลือกโอเพนซอร์สและให้การรวมเข้ากับ Python และ Polars ซึ่งทั้งสองอย่างนี้เราพึ่งพาอย่างมาก
LancedB จัดเตรียมการรวมกันของดัชนีไฟล์และกลับด้าน (IVF) และปริมาณผลิตภัณฑ์ (PQ) เพื่อสร้างดัชนีเพื่อนบ้านที่ใกล้ที่สุด (ANN) โดยประมาณ
ทั้งสองส่วนของดัชนี IVF-PQ สามารถปรับได้อย่างละเอียดโดยการปรับพารามิเตอร์ต่อไปนี้:
เราแก้ไขพารามิเตอร์การจัดทำดัชนีและเปลี่ยนแปลงพารามิเตอร์การดึง แม้ว่าหากเวลาที่ได้รับอนุญาตเราอาจแตกต่างกันไปทั้งคู่เพื่อดูว่าเวลาในการดึงและความแม่นยำได้รับผลกระทบอย่างไร
นอกเหนือจากพารามิเตอร์การสืบค้นที่สร้างขึ้นในดัชนี ANN ของเราแล้วเรายังเปลี่ยนแปลงตัวแปรก่อนการแก้ไขและหลังการแก้ไขอื่น ๆ เพื่อลองและปรับปรุงผลลัพธ์โดยรวมของเรา
ในขณะที่ข้อมูลการติดฉลากเราสังเกตเห็นผลลัพธ์ "ที่เกี่ยวข้อง แต่ไม่เกี่ยวข้อง" ประเภททั่วไป: reddit_text ที่ตั้งคำถามคล้ายกับการสืบค้นเอง
ส่วนใหญ่ข้อความเหล่านี้มาจาก submission (ตรงข้ามกับความคิดเห็น) ดังนั้นวิธีหนึ่งในการลองและยกระดับผลลัพธ์ที่เกี่ยวข้องมากขึ้นอาจละเว้นสิ่งเหล่านี้จากการค้นหาเวกเตอร์ นี่เป็นเรื่องง่ายพอเนื่องจากข้อมูลนี้มีอยู่ในข้อมูลเมตาดั้งเดิมของเรา
น้อยกว่า แต่ก็ยังเพียงพอที่จะสังเกตเห็น comment จะแสดงคุณสมบัตินี้ ในการลองและลดผลกระทบของพวกเขาเราได้ออกแบบคอลัมน์เมตาดาต้า is_short_question เพื่อลองและระบุตัวอย่าง reddit_text ทั้งหมดที่ตั้งคำถามสั้น ๆ (และไม่น่าจะให้ข้อมูลที่เป็นประโยชน์สำหรับการตอบคำถามเหล่านั้น) เพื่อให้พวกเขาสามารถกรองก่อนการค้นหา
เพื่อปรับปรุงการจัดอันดับผลลัพธ์หลังจากการดึงข้อมูลเราได้ออกแบบเมตาดาต้าแบบ aditional บางอย่างที่อาจช่วยให้เราสามารถใช้ประโยชน์จากข้อมูลที่ได้รับจากเนื้อหาของการตอบกลับ
เราออกแบบข้อมูลเมตาสองประเภท:
sentiment ของการตอบกลับและagree_distance (และ disagree_distance ) สำหรับการตอบกลับ ในกรณีของ reply_sentiment เราใช้รูปแบบการประมวลผลภาษาธรรมชาติที่ผ่านการฝึกอบรมมาก่อนที่เรียกว่า "MRM8488/Distilroberta-Finetuned-Financial-News-enalysis" เพื่อวัดเสียงทางอารมณ์ที่อยู่เบื้องหลังตำรา โมเดลนี้ช่วยให้เราจำแนกการตอบกลับแต่ละครั้งเป็นหมวดหมู่เช่นบวกเป็นกลางหรือลบ คะแนนความเชื่อมั่นของการตอบกลับทั้งหมดนั้นถูกรวมเข้าด้วยกันเพื่อสะท้อนความเชื่อมั่นโดยรวมที่มีต่อโพสต์ต้นฉบับแต่ละรายการและความคิดเห็นต่อไปนี้ สมมติฐานพื้นฐานที่นี่คือโพสต์ที่สร้างการตอบกลับเชิงบวกส่วนใหญ่มีแนวโน้มที่จะสร้างสรรค์และให้ข้อมูลซึ่งจะทำหน้าที่เป็นพร็อกซีสำหรับการรับรองผู้ใช้ที่คล้ายกับ upvotes ใน reddit สมมติฐานของเราคือโพสต์ที่มีการตอบกลับในเชิงบวกมากขึ้นมีแนวโน้มที่จะมีข้อมูลที่เป็นประโยชน์มากกว่า
ในกรณีของ agree_distance เราวัดระยะห่างระหว่างแต่ละ reddit_text และชุดของ "คำสั่งตกลง" จากนั้นเมื่อใดก็ตามที่การส่งหรือความคิดเห็นมีการตอบกลับเราจะเพิ่ม top_reply_agree_distance และ avg_reply_agree_distance สมมติฐานของเราคือโพสต์ที่มีคำตอบที่ใกล้เคียงกับคำสั่ง "ตกลง" จะมีแนวโน้มที่จะมีข้อมูลที่เกี่ยวข้องมากขึ้น ในทำนองเดียวกันการโพสต์ที่มีคำตอบที่ใกล้เคียงกับคำสั่ง "ไม่เห็นด้วย" จะมีโอกาสน้อยกว่าที่จะเกี่ยวข้อง
เมื่อจัดอันดับใหม่ผลลัพธ์ที่มี avg_reply_agree_distance ต่ำกว่าจะถูกกระแทกสูงขึ้นผลลัพธ์ที่มี avg_reply_disagree_distance ต่ำกว่า
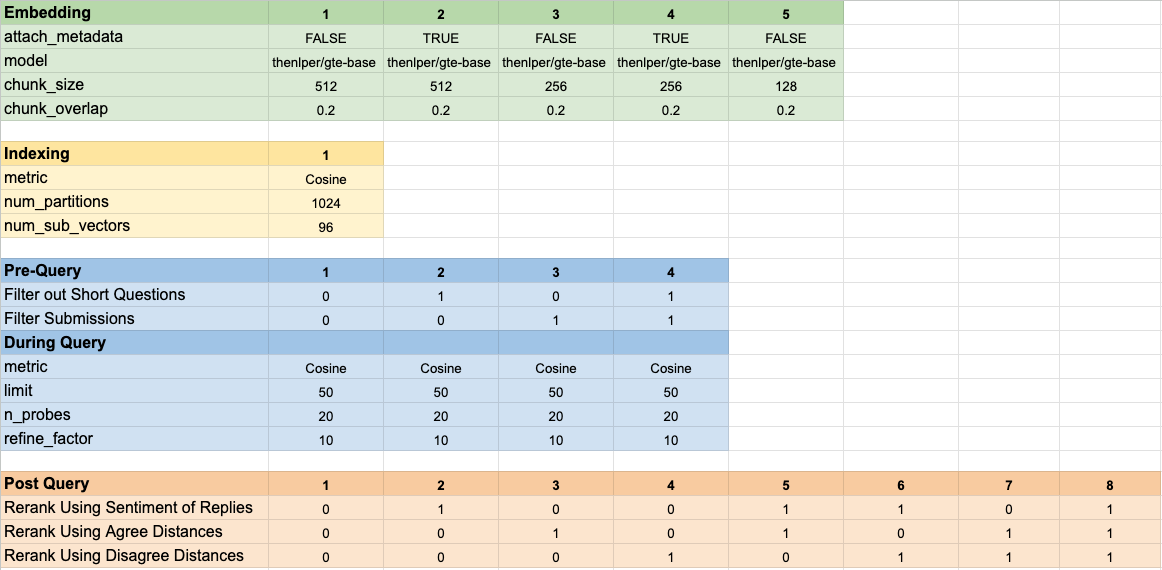
เราทดสอบการกำหนดค่าโมเดลที่แตกต่างกัน 160 ครั้ง การกำหนดค่าแต่ละครั้งรวมถึงตัวเลือกการฝังกลยุทธ์สำหรับการกรองการทดสอบก่อนทำการค้นหาเวกเตอร์ของเราและกลยุทธ์สำหรับการจัดอันดับผลลัพธ์ที่เรียกคืนอีกครั้ง
พารามิเตอร์ไฮเปอร์เหล่านี้สรุปไว้ในภาพด้านล่าง:
เรามีวัตถุประสงค์หลักสองประการที่เราคำนึงถึงเมื่อประเมินผลลัพธ์ของเรา:
ในขณะที่เวลาการดึงข้อมูลนั้นง่ายพอที่จะวัดได้เราจำเป็นต้องพัฒนาเครื่องมือบางอย่างเพื่อวัดความคืบหน้าของเราในการจัดอันดับผลลัพธ์
เพื่อสร้างพื้นฐานสำหรับการประเมินการจัดอันดับผลลัพธ์เราระบุว่าชุดย่อยของผลลัพธ์เพื่อสร้างตัวชี้วัดเริ่มต้นของความเกี่ยวข้อง ในการทำเช่นนี้เราได้สร้างแบบสอบถามสองแบบสำหรับชุดข้อมูลสิบสามชุดในชุดการฝึกอบรมของเราและติดป้ายผลลัพธ์ 20 อันดับแรกที่เรียกคืนสำหรับแต่ละแบบสอบถาม ผลลัพธ์ถูกระบุว่า:
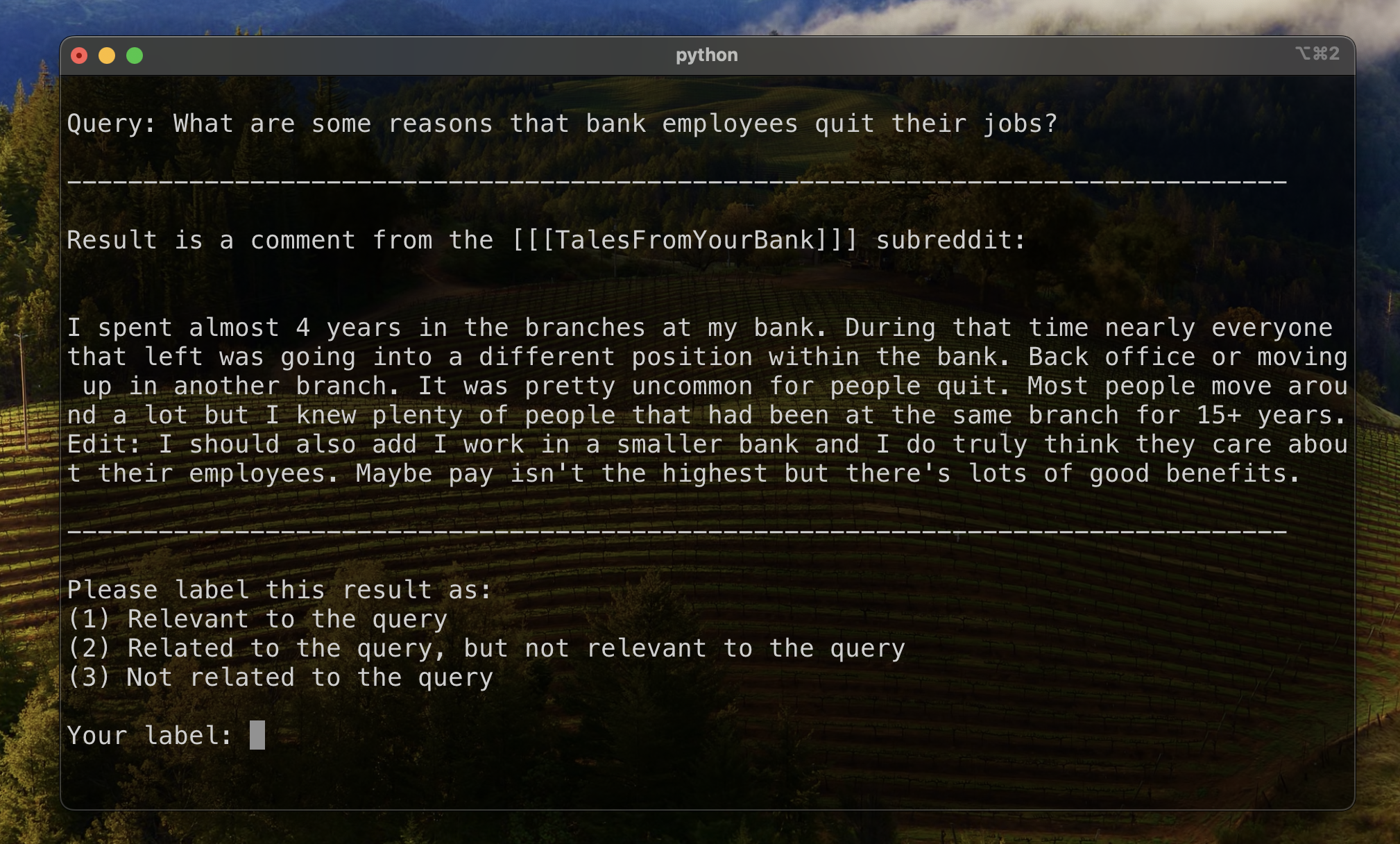
สำหรับคู่ที่มีการตอบคำถามแต่ละคู่ฉลากสุดท้ายจะถูกกำหนดโดยการโหวตส่วนใหญ่โดยมีความสัมพันธ์ผิดนัดให้กับความเกี่ยวข้องน้อยลง ข้อมูลที่มีป้ายกำกับด้วยตนเองนี้ถูกใช้เพื่อหาปริมาณผลลัพธ์
เราใช้สามเมตริกสำหรับผลการจัดอันดับ แต่ละรุ่นเป็นรุ่นที่ได้รับการดัดแปลงของตัวชี้วัดระบบผู้แนะนำปรับให้เข้ากับกรณีการใช้งานของเราซึ่งเราไม่มีความจริงพื้นฐานที่ชัดเจนหรือการจัดอันดับผลลัพธ์ที่เกี่ยวข้องจากที่เกี่ยวข้องกับความเกี่ยวข้องน้อยที่สุด
ตัวชี้วัดนี้ให้คะแนนที่ระบุว่าใกล้กับด้านบนของผลลัพธ์ที่เกี่ยวข้องที่รู้จักครั้งแรกจะปรากฏขึ้นอย่างไร คะแนนที่สมบูรณ์แบบของ 1 ทำได้หากผลลัพธ์ด้านบนของการสืบค้นทุกครั้งมีความเกี่ยวข้อง
ในการคำนวณอันดับซึ่งกันและกันสำหรับแบบสอบถามที่กำหนดเราใช้สูตรต่อไปนี้:
ในแอปพลิเคชันมาตรฐานมีผลลัพธ์ "ความจริงภาคพื้นดิน" ที่รู้จักกันเดียว ในแอปพลิเคชันที่ได้รับการแก้ไขของเราเรายอมรับผลลัพธ์ที่เกี่ยวข้องใด ๆ ที่เป็นที่รู้จักเป็นความจริงพื้นฐาน
จากนั้นเราคำนวณค่าเฉลี่ยของคะแนนเหล่านี้ในแบบสอบถามมาตรฐานทั้งหมดของเราเพื่อมาถึงอันดับเฉลี่ยซึ่งกันและกัน
ตัวชี้วัดนี้ให้คะแนนที่ระบุว่าผลลัพธ์ที่เกี่ยวข้องที่เรารู้จักนั้นปรากฏอยู่ใกล้กับด้านบน คะแนนที่สมบูรณ์แบบของ 1 จะทำได้หากผลลัพธ์ที่เกี่ยวข้องทั้งหมดที่รู้จักปรากฏเป็นผลลัพธ์สูงสุดสำหรับการสืบค้นทั้งหมด (โดยไม่มีผลลัพธ์ที่ไม่มีป้ายกำกับปรากฏสูงกว่าผลลัพธ์ที่เกี่ยวข้องที่ทราบใด ๆ
ในการคำนวณอันดับซึ่งกันและกันสำหรับการสืบค้นที่กำหนดเราใช้สูตรต่อไปนี้:
ที่ไหน
ที่ไหน
ในแอพพลิเคชั่นมาตรฐานแต่ละผลลัพธ์ที่เกี่ยวข้องมีอันดับของตัวเองและการมีส่วนร่วมในคะแนนโดยรวมจะคำนึงถึงอันดับนี้เป็นตำแหน่งที่คาดหวังในผลลัพธ์ ในแอปพลิเคชันที่ได้รับการแก้ไขของเราเราให้การสนับสนุนเช่นเดียวกันกับผลลัพธ์ที่เกี่ยวข้องที่ทราบซึ่งปรากฏข้างต้นตำแหน่ง
จากนั้นเราคำนวณค่าเฉลี่ยของคะแนนเหล่านี้ในแบบสอบถามมาตรฐานทั้งหมดของเราเพื่อมาถึงอันดับเฉลี่ยซึ่งกันและกัน
ส่วนลดที่เพิ่มขึ้นสะสม (DCG) มักใช้เป็นตัวชี้วัดเพื่อประเมินประสิทธิภาพของเครื่องมือค้นหาและวัดประสิทธิภาพของอัลกอริทึมในการวางผลลัพธ์ที่เกี่ยวข้องที่ด้านบนของรายการดึงข้อมูล สำหรับรายการคำตอบที่มีความยาว
ที่ไหน
เนื่องจากคะแนน DCG ขึ้นอยู่กับความยาวของรายการดึงข้อมูลเราจึงต้องทำให้เป็นมาตรฐานเพื่อให้การให้คะแนนสอดคล้องกันในสถานการณ์การดึงแบบสอบถามที่มีจำนวนตัวแปร คะแนนลดราคาลดลงปกติ (NDCG) ที่ตำแหน่ง
ที่ไหน
NDCG สามารถทำคะแนนความเกี่ยวข้องตามลำดับ (1 สำหรับความเกี่ยวข้องสูง 2 สำหรับความเกี่ยวข้องค่อนข้างมาก) เราปรับเปลี่ยนรูปแบบการให้คะแนนสำหรับกรณีของเราโดยการแปลงฉลากมนุษย์ของเรา (1 ที่เกี่ยวข้อง 2 เกี่ยวข้อง แต่ไม่เกี่ยวข้อง 3-not เกี่ยวข้อง) เป็นรูปแบบการให้คะแนนแบบไบนารี ผลลัพธ์ที่มีฉลากมนุษย์ = 1 ได้รับคะแนนความเกี่ยวข้อง = 1 และทุกอย่างอื่นได้รับคะแนนความเกี่ยวข้องเป็น 0 สิ่งนี้ทำเพื่อให้แน่ใจว่าการกำหนดค่าที่ดีที่สุดตามที่กำหนดโดยคะแนน NDCG ควรส่งคืนผลลัพธ์ที่เกี่ยวข้องสูงเท่านั้น จากนั้นเราคำนวณคะแนน NDCG ของแบบสอบถามมาตรฐานของเราและเฉลี่ยพวกเขาเพื่อให้ได้คะแนนเฉลี่ย NDCG ของการกำหนดค่าเฉพาะ คะแนน DCG และคะแนน IDCG คำนวณโดยการตั้งค่า
ที่ไหน
เราใช้พารามิเตอร์โมเดลต่อไปนี้เป็นพื้นฐานของเราสำหรับการเปรียบเทียบ:
การกำหนดค่าพื้นฐานบรรลุคะแนนต่อไปนี้ในตัวชี้วัดของเรา:
| ตัวชี้วัด | คะแนน | อันดับ (จาก 160) |
|---|---|---|
| เฉลี่ยอันดับซึ่งกันและกัน | 0.626031 | 46 |
| การขยายค่าเฉลี่ยซึ่งกันและกัน | 0.427189 | 84 |
| กำไรสะสมลดลงปกติ | 0.714459 | 84 |
| อันดับโดยรวมโดยเฉลี่ย | 71.33 |
การกำหนดค่าที่ได้ผลลัพธ์โดยรวมที่ดีที่สุด (อันดับเฉลี่ยสูงสุดในการวัด):
การกำหนดค่านี้บรรลุคะแนนต่อไปนี้ในตัวชี้วัดของเรา:
| ตัวชี้วัด | คะแนน | อันดับ (จาก 160) |
|---|---|---|
| เฉลี่ยอันดับซึ่งกันและกัน | 0.742735 | 7 |
| การขยายค่าเฉลี่ยซึ่งกันและกัน | 0.599379 | 9 |
| กำไรสะสมลดลงปกติ | 0.806476 | 1 |
| อันดับโดยรวมโดยเฉลี่ย | 5.67 |
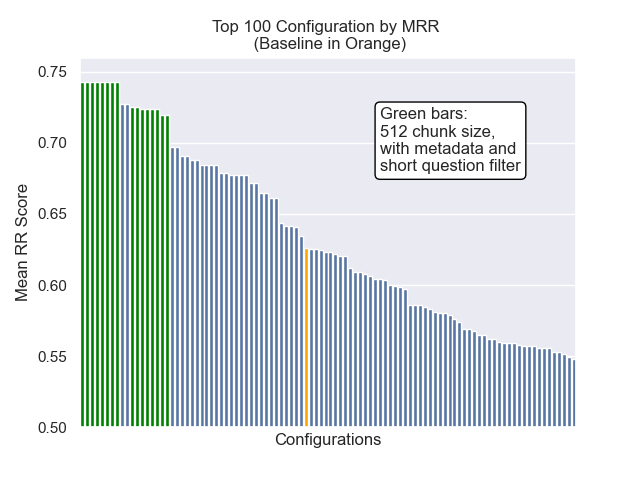
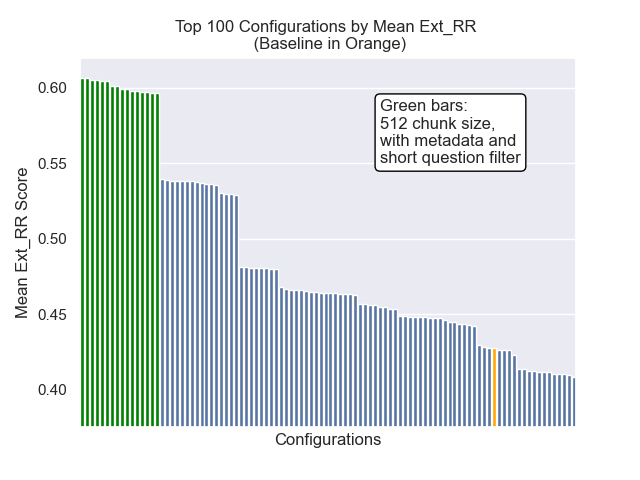
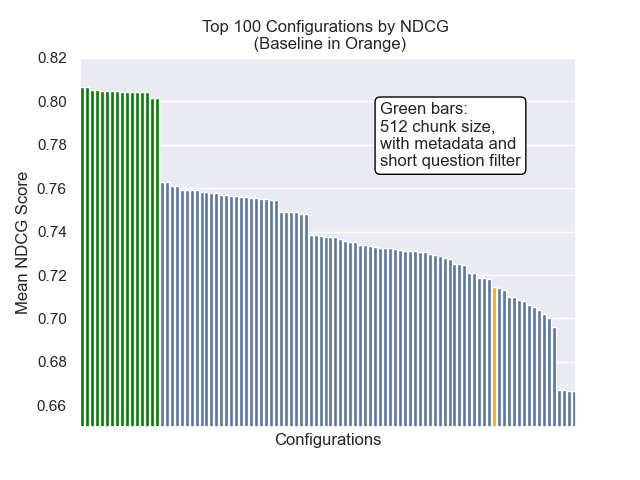
ด้านล่างเราสามารถเห็นตำแหน่งสัมพัทธ์ของการกำหนดค่าพื้นฐานไปยังส่วนบนโดยรวม
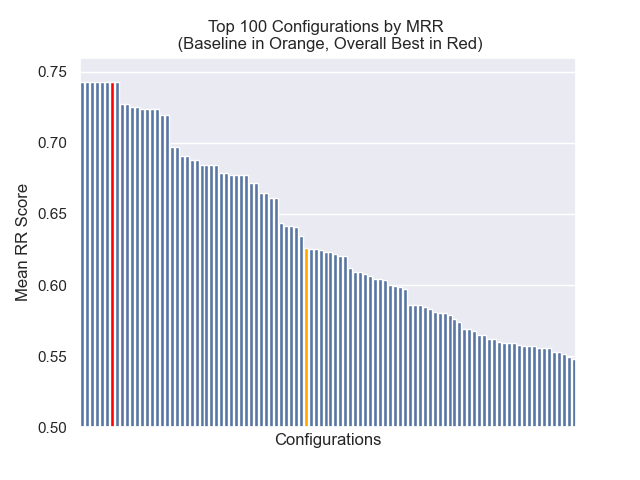
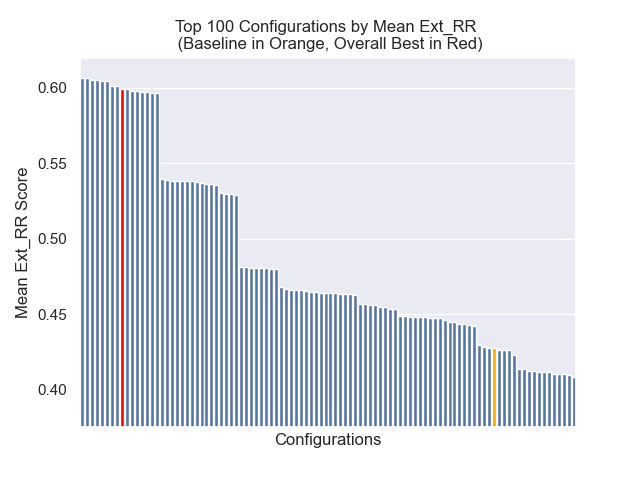
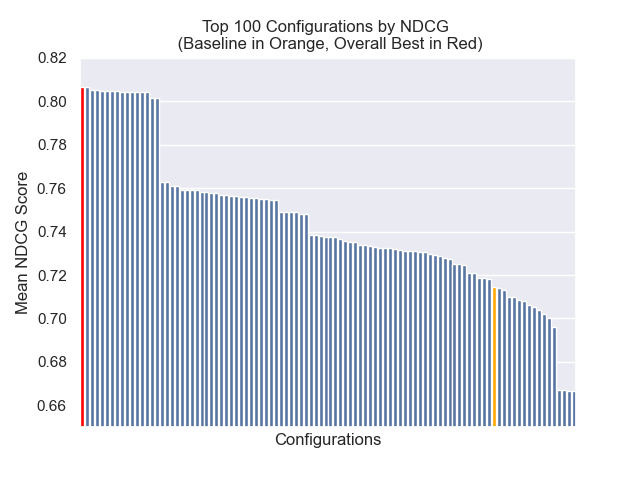
ปรากฏว่าขนาดก้อนลดลงมีผลกระทบเชิงลบต่อผลลัพธ์โดยทั่วไป
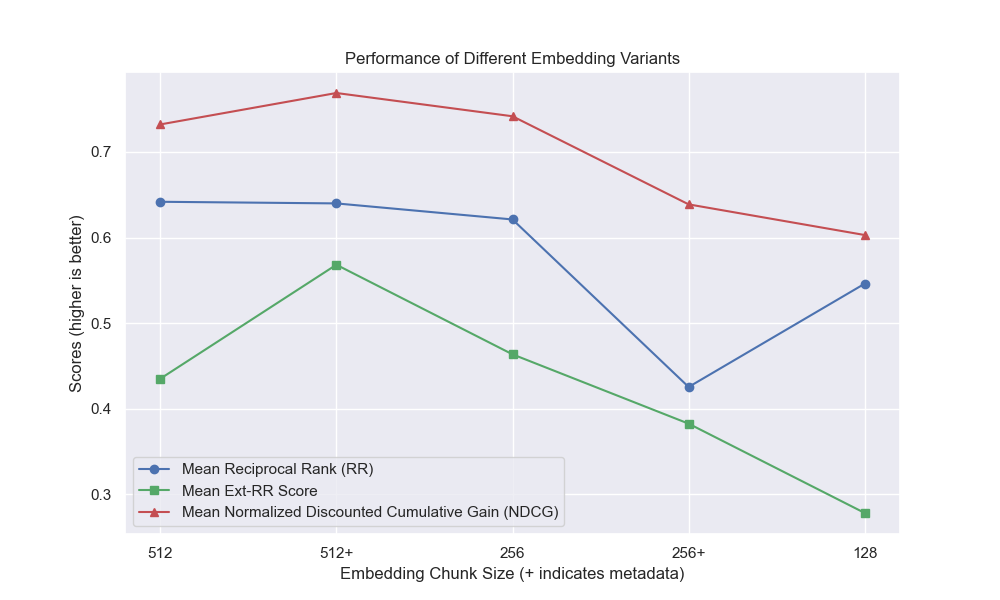
นอกจากนี้การกรองคำถามสั้น ๆ ก่อนการดึงข้อมูลมีผลกระทบเชิงบวกโดยไม่คำนึงถึงตัวเลือกไฮเปอร์พารามิเตอร์อื่น ๆ
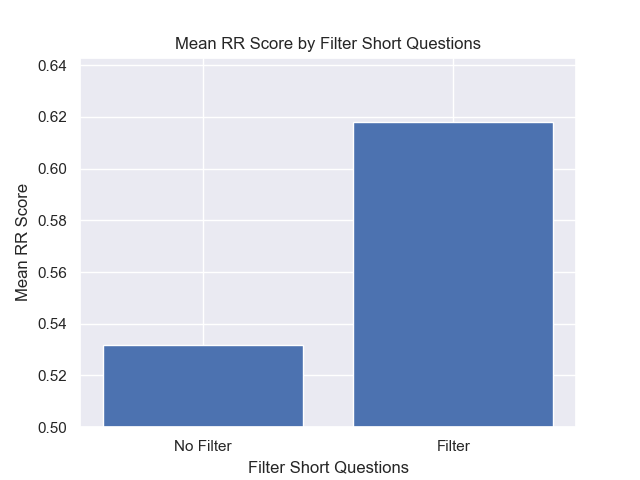
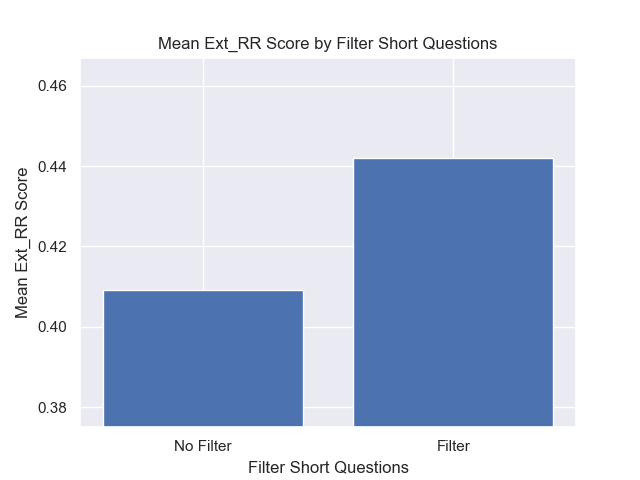
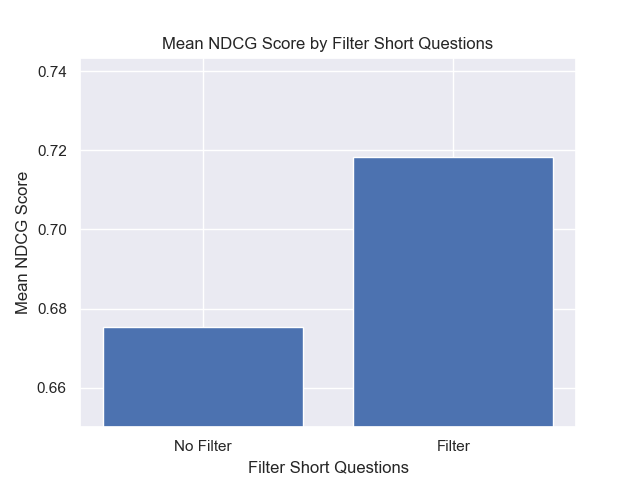
หากเราเน้นเพียงแค่การกำหนดค่าที่มีรูปแบบเหล่านี้เข้าด้วยกัน (ขนาดก้อน 512 พร้อมกับข้อมูลเมตาเพิ่มและการกรองตามคำถามสั้น ๆ ) เราจะเห็นว่าพวกเขาทำงานได้ดีแค่ไหนเมื่อเทียบกับการกำหนดค่าอื่น ๆ
บางพื้นที่ของการสอบสวนในอนาคตที่มีศักยภาพ:


