erdos_paware
1.0.0
Este projeto foi concluído por Marcos Ortiz, Sayantan Roy, Karthik Prabhu, Kristina Knowles e Diptanil Roy, como parte do campo de treinamento de aprendizado profundo Erdös (primavera, 2024).
Nosso projeto está detalhado abaixo e você pode acompanhar as etapas principais através dos notebooks e dados de demonstração fornecidos no diretório paw_demo/.
Os quatro primeiros cadernos passam por uma demonstração usando um pequeno subconjunto dos dados. O último caderno forneceu um resumo de nossos resultados em todo o conjunto de dados.
Dada uma consulta de usuário arbitrária e um conjunto de dados de conteúdo gerado pelo ser humano, crie um algoritmo para identificar e classificar o conteúdo relevante no conjunto de dados, de modo que o conjunto de correspondências possa ser recuperado com rapidez e precisão
Sabemos que o eventual aplicação para os resultados do nosso projeto é o uso em um pipeline de geração de recuperação upmentada (RAG). Este artigo recente de pesquisa, descrevendo o estado atual do RAG para grandes modelos de idiomas (LLMS), ajudou a fornecer algumas dicas sobre quais ferramentas podem ser uma boa opção para nossa tarefa e dados específicos.
Os principais passos do RAG são:
Os dados brutos fornecidos a nós consistem em 5.528.298 postagens do Reddit, de 34 subredits. Esses dados foram fornecidos em um arquivo parquet, juntamente com um dicionário de dados.
Para este projeto, estamos focados nas duas primeiras etapas do processo de RAG: indexação e recuperação.
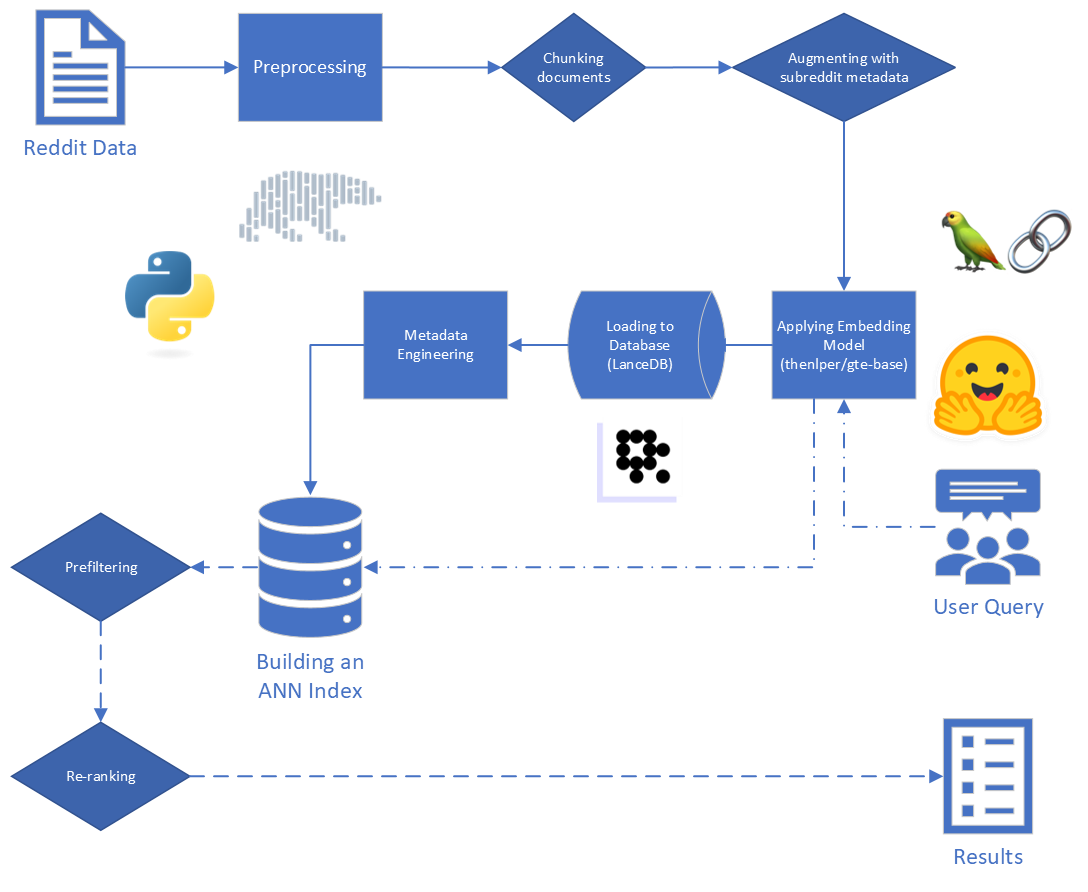
Começando com os dados brutos, realizamos algumas limpeza básica:
reddit_text de "[deleted]" ou "removed" .reddit_text com pelo menos 35 caracteres e apareceu mais de 7 vezes. Não queríamos soltar imediatamente frases comuns mais curtas, caso elas possam ser úteis mais tarde (consulte o uso de metadados projetados).reddit_text .reddit_title era um proxy para o reddit_text . Então, substituímos o reddit_text vazio pelo reddit_title nessas instâncias. Utilizamos a versão base do modelo de incorporação de texto geral (GTE), que é baseado na estrutura do BERT. Documentação no HuggingFace: Link.
Escolhemos esse modelo porque parecia ser um tamanho razoável (0,22 GB), é de código aberto e permite a incorporação de textos de até 512 tokens de comprimento. Ele tem um desempenho especialmente bom em agrupamento e recuperação em comparação com outros transformadores de frases de código aberto que possuem menos de 250m parâmetros: link.
Além disso, parte de seu treinamento foi realizada usando dados do Reddit, o que aumentou seu apelo.
Consideramos a experimentação com outros modelos, mas devido ao alto custo computacional de incorporar o conjunto de dados a cada novo modelo, salvamos essa avenida para trabalhos futuros.
Usamos a estrutura de Transformers de sentenças fornecida pela Sbert para implementar nosso modelo de incorporação, além de abraçar ferramentas de incorporação de rosto fornecidas pela Langchain
Durante a incorporação, consideramos os seguintes parâmetros:
chunk_size : o comprimento máximo do texto para incorporar como um documentochunk_overlap : Sempre que um documento precisava ser dividido em pedaços, quanto eles devem se sobreporTambém experimentamos anexar metadados a pedaços antes da incorporação. Para fazer isso, simplesmente adicionamos o título do subreddit (ou uma aproximação) ao início de um pedaço de texto antes de incorporar. Por exemplo, se houver um comentário nos Fedxers que diz: "Eu realmente gosto de trabalhar aqui porque ...", anexaríamos "FedEx" ao início do pedaço e incorporaríamos "FedEx n n, eu realmente gosto de trabalhar aqui porque ..."
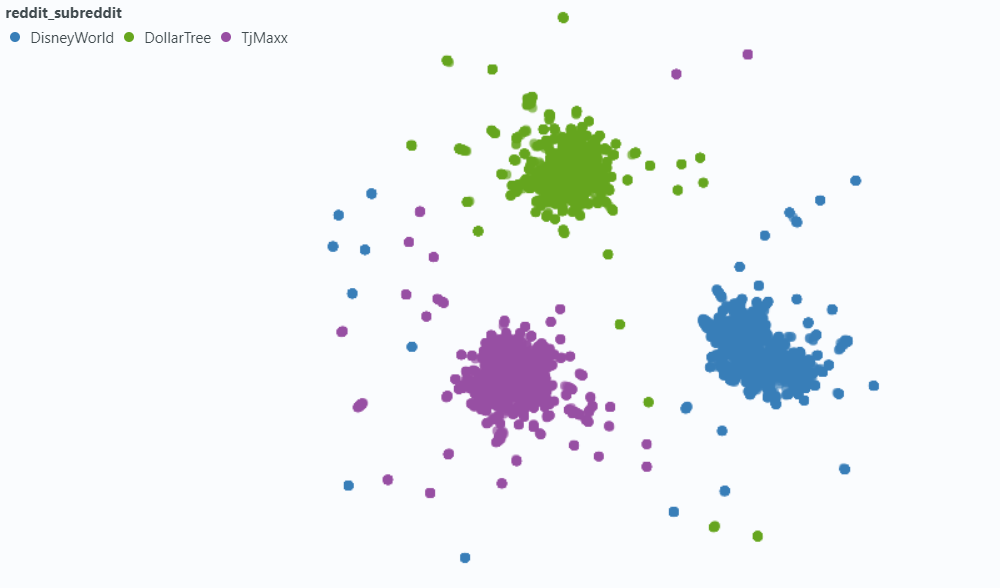
Nossa intuição foi que, nos casos em que um post não inclui explicitamente o nome da empresa que eles estão discutindo, podemos inferir essas informações do subreddit e que isso pode cutucar esse vetor mais próximo de nossa consulta. Por exemplo, se perguntarmos "por que os funcionários gostam de trabalhar na Disney?" e "Por que os funcionários gostam de trabalhar na FedEx?" Nossa esperança é que a adição de metadados aumente a probabilidade de que o comentário acima apareça mais alto nos resultados da consulta da FedEx e talvez mais baixo nos resultados da consulta da Disney.
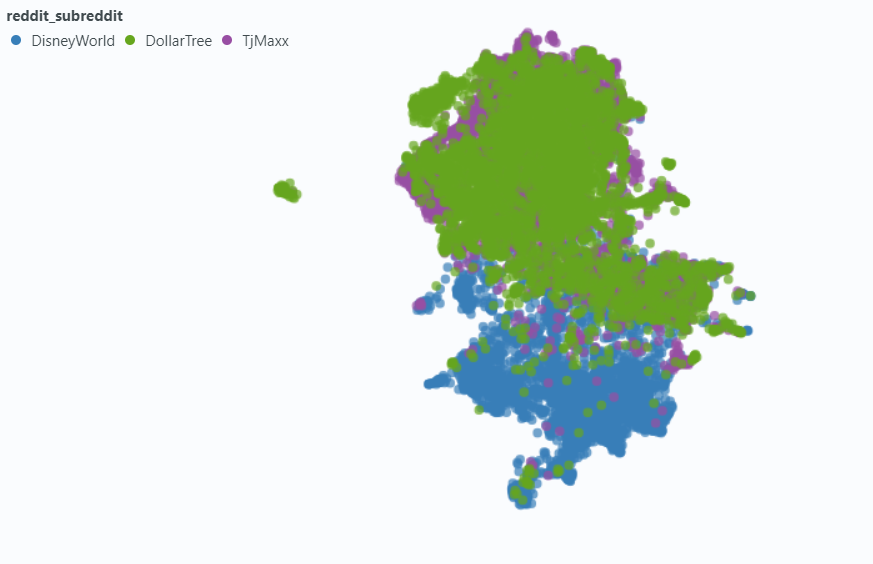
Usamos o Spotlight para visualizar o efeito em uma pequena amostra de nossos dados.
Incorporação sem metadados:
Incorporando com metadados:
Escolhemos o lancedb (link) para lidar com as necessidades do banco de dados do vetor. O LancedB é uma opção de código aberto e fornece integração com Python e Polars, os quais somos fortemente dependentes.
O LancedB fornece uma combinação e o índice de arquivos invertido (IVF) e a quantização do produto (PQ) para criar um índice aproximado de vizinhos mais próximos (Ann).
Ambas as partes do índice de fertilização in vitro podem ser ajustadas ajustando os seguintes parâmetros:
Corrigimos os parâmetros de indexação e variamos os parâmetros de recuperação. No entanto, se o tempo permitido, podemos variar tanto para ver como os tempos de recuperação e a precisão são impactados.
Além dos parâmetros de consulta incorporados ao nosso índice de RNA, variamos outras variáveis pré-revisor e pós-revieval para tentar melhorar nossos resultados gerais.
Enquanto rotula os dados, notamos um tipo comum de resultado "relacionado, mas não relevante": um reddit_text que colocou uma pergunta semelhante à própria consulta.
Na maioria das vezes, esses textos vieram de uma submission (em oposição a um comentário). Portanto, uma maneira de tentar elevar resultados mais relevantes pode ser omiti -los na pesquisa de vetores. Isso é fácil, já que essas informações estão contidas em nossos metadados originais.
Com menos frequência, mas ainda o suficiente para ser notado, um comment exibiria essa propriedade. Para tentar conter seu impacto, projetamos uma coluna de metadados is_short_question para tentar identificar todos os exemplos reddit_text que fizeram perguntas curtas (e, portanto, é improvável que forneça informações úteis para responder a essas perguntas) para que elas também pudessem ser filtradas antes da pesquisa.
Para melhorar a classificação dos resultados após a recuperação, projetamos alguns metadados adicionais que podem nos permitir alavancar as informações fornecidas pelo conteúdo das respostas.
Projetamos dois tipos de metadados:
sentiment de respostas e,agree_distance (e disagree_distance ) para respostas. No caso de reply_sentiment , utilizamos um modelo de processamento de linguagem natural pré-treinado chamado "MRM8488/Distilroberta-Finetuned-Ingial-News-sessal-análise", para avaliar o tom emocional por trás dos textos. Esse modelo nos ajudou a classificar cada resposta em categorias como positiva, neutra ou negativa. As pontuações de sentimento de todas as respostas foram então agregadas para refletir o sentimento geral em relação a cada postagem original e os seguintes comentários. A suposição subjacente aqui é que as postagens que geram respostas predominantemente positivas provavelmente serão construtivas e informativas, servindo assim como um proxy para endossos de usuários semelhantes aos upvotes no Reddit. Nossas hipóteses foram que um post com respostas mais positivas teria maior probabilidade de conter informações úteis.
No caso de agree_distance , medimos a distância entre cada reddit_text e um conjunto de "declarações de concordância". Em seguida, sempre que um envio ou comentário tinham respostas, adicionamos o top_reply_agree_distance e o avg_reply_agree_distance . Nossa hipótese era que as postagens com respostas que estavam mais próximas das declarações de "concordo" teriam maior probabilidade de conter informações relevantes. Da mesma forma, postagens com respostas mais próximas de declarações "discordadas" teriam menos probabilidade de serem relevantes.
Ao renomear, os resultados com avg_reply_agree_distance MAIS SUBSTITUIVOS foram atingidos mais altos, os resultados com avg_reply_disagree_distance foram mais baixos.
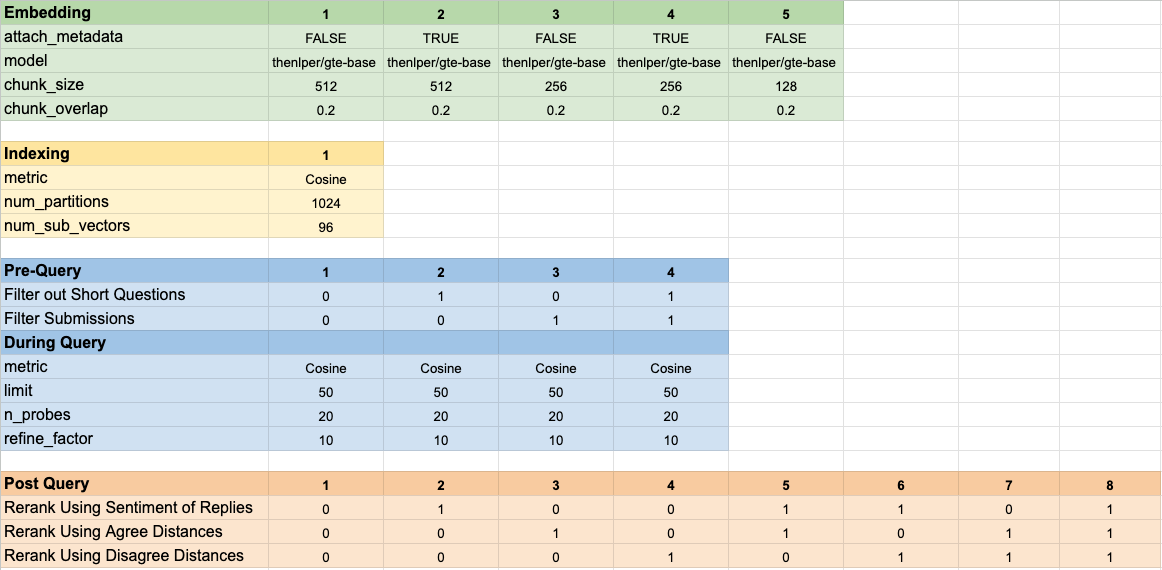
Testamos 160 configurações de modelo diferentes. Cada configuração incluiu uma escolha de incorporação, uma estratégia para filtrar os testes antes de executar nossa pesquisa de vetores e uma estratégia para renomear os resultados que foram recuperados.
Esses hiper-parâmetros estão resumidos na imagem abaixo:
Tivemos dois objetivos principais que tínhamos em mente ao avaliar nossos resultados:
Embora o tempo de recuperação seja fácil de medir, precisávamos desenvolver algumas ferramentas para medir nosso progresso na classificação dos resultados.
Para estabelecer uma linha de base para avaliar a classificação de resultados, rotulamos manualmente um subconjunto de resultados para estabelecer uma métrica inicial de relevância. Para fazer isso, criamos duas consultas para cada um dos treze conjuntos de dados em nosso conjunto de treinamento e rotulamos os 20 principais resultados recuperados para cada consulta. Os resultados foram rotulados como:
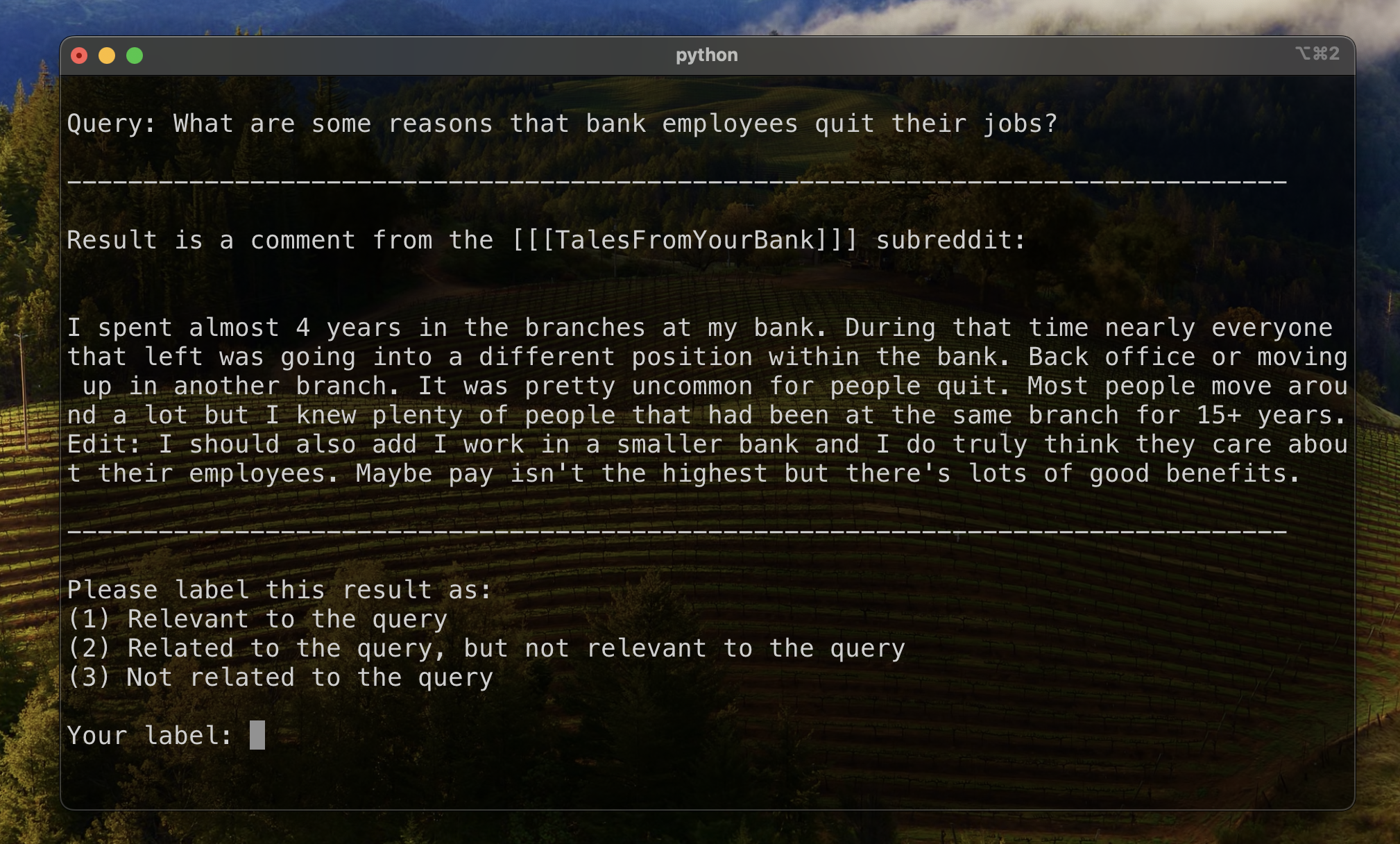
Para cada par de resultos de consulta, o rótulo final foi determinado pelo voto da pluralidade, com laços em falta a menos relevantes. Esses dados rotulados manualmente foram usados para quantificar os resultados.
Utilizamos três métricas para os resultados da classificação. Cada um é uma versão modificada de uma métrica do sistema de recomendação, adaptada ao nosso caso de uso, onde não temos uma verdade clara ou uma classificação estabelecida de resultados relevantes do mais relevante para o menos relevante.
Essa métrica fornece uma pontuação que indica o quão perto do topo o primeiro resultado relevante conhecido aparece. Uma pontuação perfeita de 1 é alcançada se o resultado superior de cada consulta for relevante.
Para calcular a classificação recíproca para uma determinada consulta, aplicamos a seguinte fórmula:
Em aplicações padrão, há um único resultado conhecido de "Verdade Ground". Em nossa aplicação modificada, aceitamos qualquer resultado relevante conhecido como a verdade fundamental.
Em seguida, calculamos a média dessas pontuações em todas as nossas consultas padrão para chegar à classificação recíproca média.
Essa métrica fornece uma pontuação que indica quantos de nosso resultado relevante conhecido aparecem perto do topo. Uma pontuação perfeita de 1 é alcançada se todos os resultados relevantes conhecidos aparecerem como os principais resultados para todas as consultas (sem nenhum resultado não marcado parecendo mais alto do que qualquer resultado relevante conhecido.)
Para calcular a classificação recíproca estendida para uma determinada consulta, aplicamos a seguinte fórmula:
onde
onde
Em aplicativos padrão, cada resultado relevante tem sua própria classificação e sua contribuição para a pontuação geral leva em consideração essa classificação como sua posição esperada nos resultados. Em nossa aplicação modificada, demos a mesma contribuição a qualquer resultado relevante conhecido que apareceu acima da posição
Em seguida, calculamos a média dessas pontuações em todas as nossas consultas padrão para chegar à classificação recíproca média.
O ganho cumulativo com desconto (DCG) é frequentemente empregado como uma métrica para avaliar o desempenho de um mecanismo de pesquisa e mede a eficiência do algoritmo na colocação de resultados relevantes na parte superior da lista de recuperação. Para uma lista de respostas de comprimento
onde
Como a pontuação do DCG depende fortemente do comprimento da lista de recuperação, precisamos normalizá -la para que a pontuação seja consistente nos cenários de recuperação de consultas com número variável de resultados. A pontuação normalizada de ganho cumulativo com desconto (NDCG) na posição
onde o
O NDCG pode assumir a pontuação de relevância ordinal (1 para altamente relevante, 2 para um tanto relevante, assim por diante). Modificamos o esquema de pontuação para o nosso caso, convertendo nossos rótulos humanos (1 relevante, 2 relacionados, mas não relevantes, 3-não relacionados) em um esquema de pontuação binária. Os resultados com o rótulo humano = 1 receberam uma pontuação de relevância = 1 e tudo o mais recebeu uma pontuação de relevância de 0. Isso foi feito para garantir que a melhor configuração, conforme ditado pela pontuação do NDCG, deve retornar apenas resultados altamente relevantes. Em seguida, calculamos a pontuação do NDCG de nossas consultas padrão e a calculamos a média para obter a pontuação média do NDCG de uma configuração específica. As pontuações do DCG e as pontuações do IDCG foram calculadas por configuração
onde
Usamos os seguintes parâmetros do modelo como nossa linha de base para comparação:
A configuração da linha de base obtém as seguintes pontuações em nossas métricas:
| Métrica | Pontuação | Classificação (de 160) |
|---|---|---|
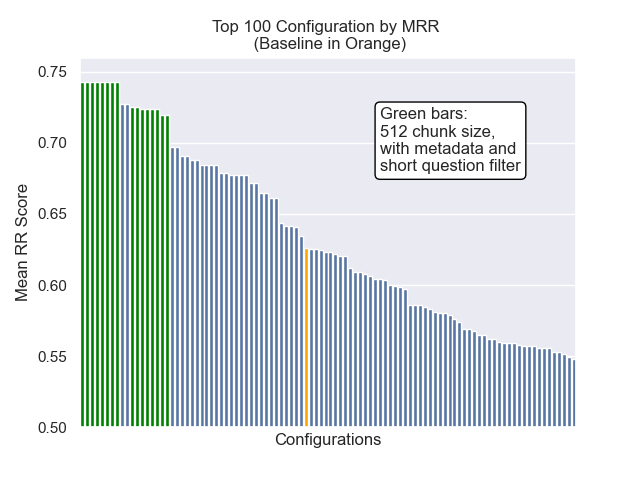
| Classificação recíproca média | 0,626031 | 46 |
| Classificação recíproca média estendida | 0,427189 | 84 |
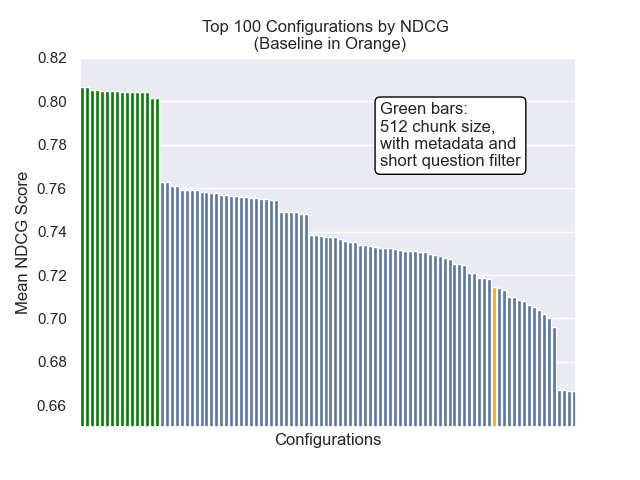
| Ganho cumulativo com desconto normalizado | 0,714459 | 84 |
| Classificação geral média | 71.33 |
A configuração que alcançou o melhor resultado geral (maior classificação média entre métricas):
Esta configuração obtém as seguintes pontuações em nossas métricas:
| Métrica | Pontuação | Classificação (de 160) |
|---|---|---|
| Classificação recíproca média | 0,742735 | 7 |
| Classificação recíproca média estendida | 0,599379 | 9 |
| Ganho cumulativo com desconto normalizado | 0,806476 | 1 |
| Classificação geral média | 5.67 |
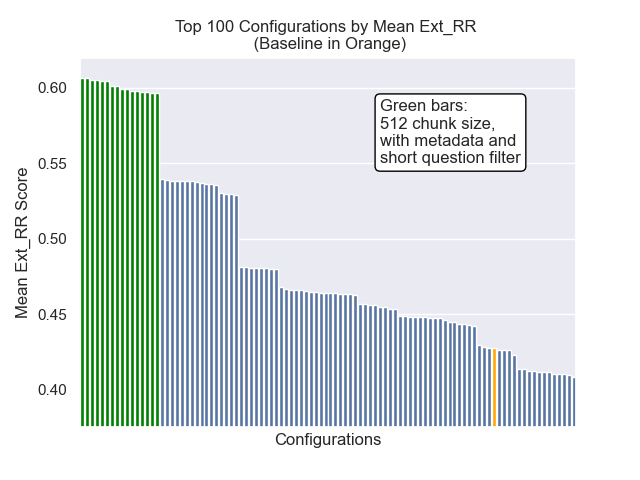
Abaixo, podemos ver a posição relativa da configuração da linha de base para o topo geral.
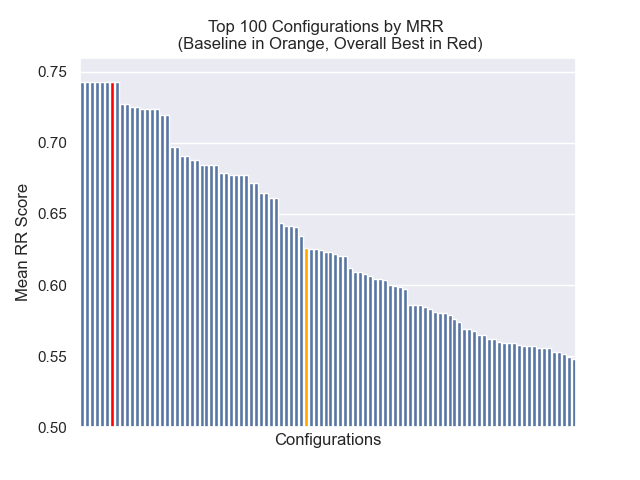
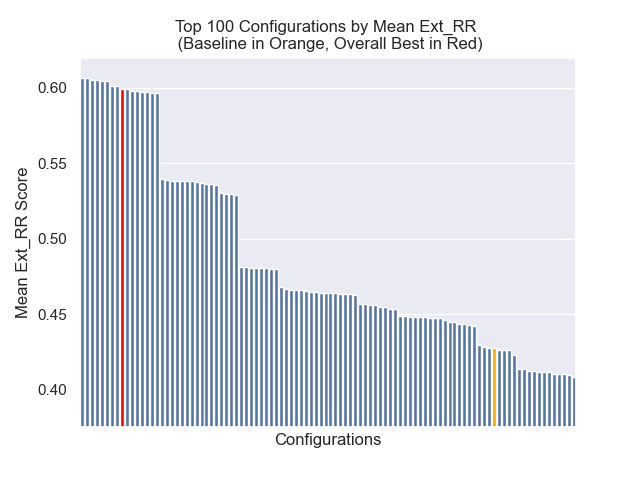
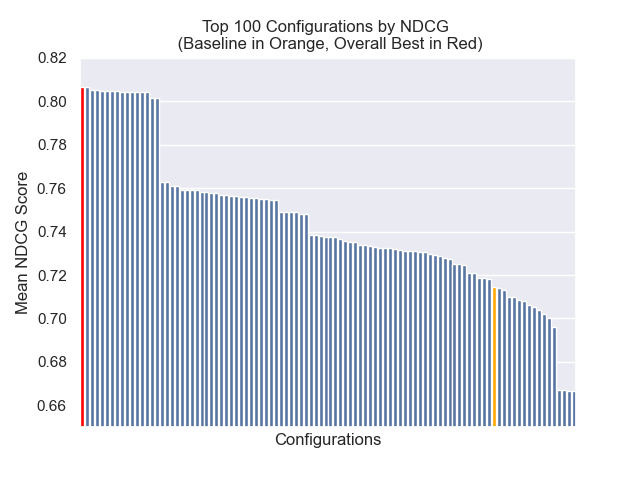
Parecia que a diminuição do tamanho do pedaço teve um impacto geralmente negativo nos resultados.
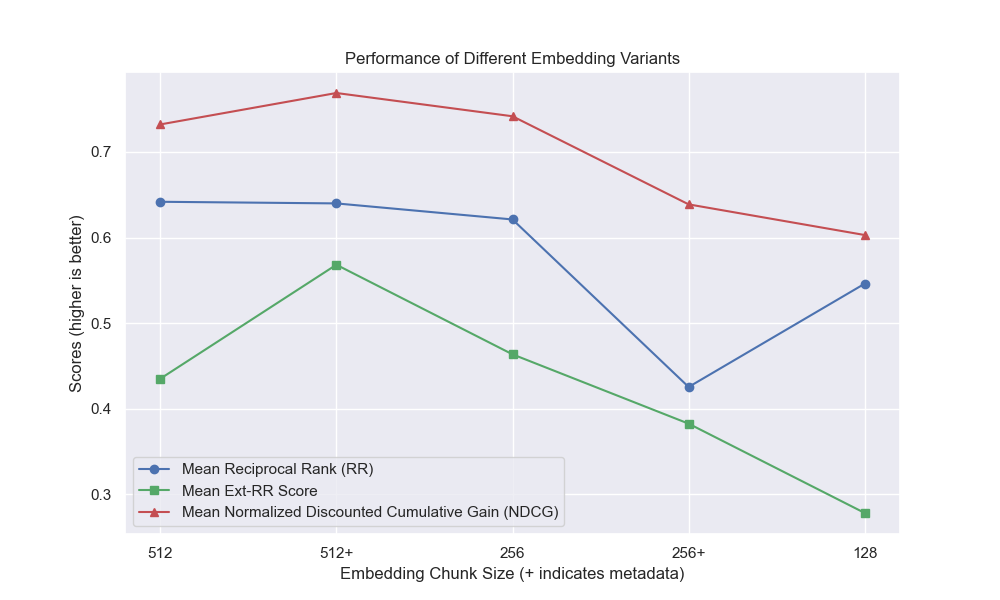
Além disso, filtrar perguntas curtas antes da recuperação teve um impacto positivo, independentemente de outras opções de hiperparâmetro.
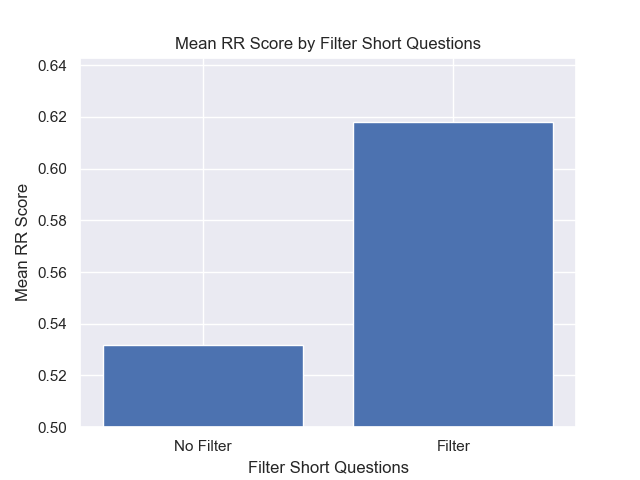
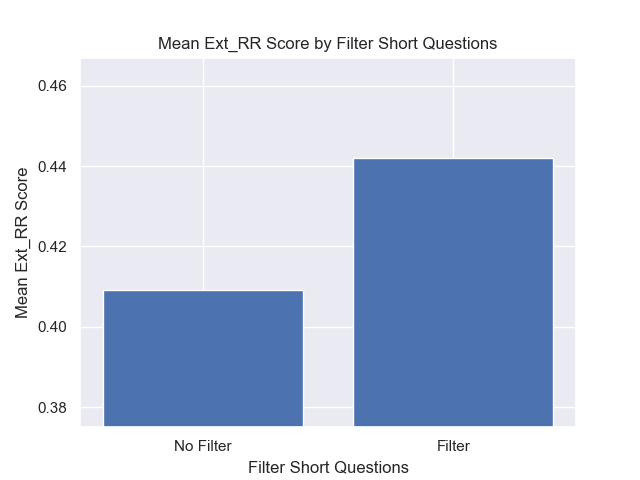
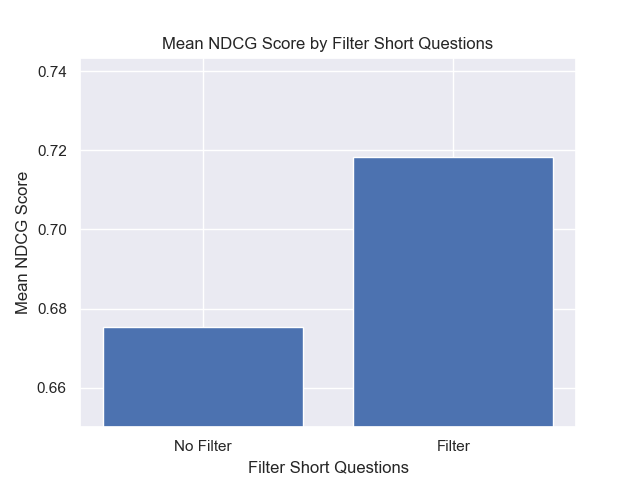
Se destacarmos apenas aquelas configurações que contêm essas variações (512 tamanho de pedaço, com metadados adicionados e filtragem por perguntas curtas), vemos como eles funcionam em relação a outras configurações.
Algumas áreas de potencial investigação futura:


