erdos_paware
1.0.0
Proyek ini diselesaikan oleh Marcos Ortiz, Sayantan Roy, Karthik Prabhu, Kristina Knowles, dan Diptanil Roy, sebagai bagian dari kamp pelatihan Deep Learning Institute Erdös (Spring, 2024).
Proyek kami dirinci di bawah ini, dan Anda dapat mengikuti langkah -langkah utama melalui notebook dan data demonstrasi yang disediakan di PAW_DEMO/ direktori.
Empat notebook pertama berjalan melalui demonstrasi menggunakan sebagian kecil dari data. Notebook terakhir memberikan ringkasan hasil kami di seluruh dataset.
Diberikan permintaan pengguna yang sewenang-wenang dan set data konten yang dihasilkan manusia, bangun algoritma untuk mengidentifikasi dan memberi peringkat konten yang relevan dalam dataset, sehingga set kecocokan dapat diambil dengan cepat dan akurat
Kita tahu bahwa aplikasi akhirnya untuk hasil proyek kami digunakan dalam pipa generasi pengambilan (RAG). Makalah survei baru -baru ini, menggambarkan keadaan kain saat ini untuk model bahasa besar (LLM) membantu memberikan beberapa wawasan tentang alat apa yang mungkin cocok untuk tugas dan data khusus kami.
Langkah utama dalam kain adalah:
Data mentah yang diberikan kepada kami terdiri dari 5.528.298 posting dari Reddit, dari 34 subreddits. Data ini disediakan dalam file parket, bersama dengan kamus data.
Untuk proyek ini, kami fokus pada dua langkah pertama proses RAG: pengindeksan dan pengambilan.
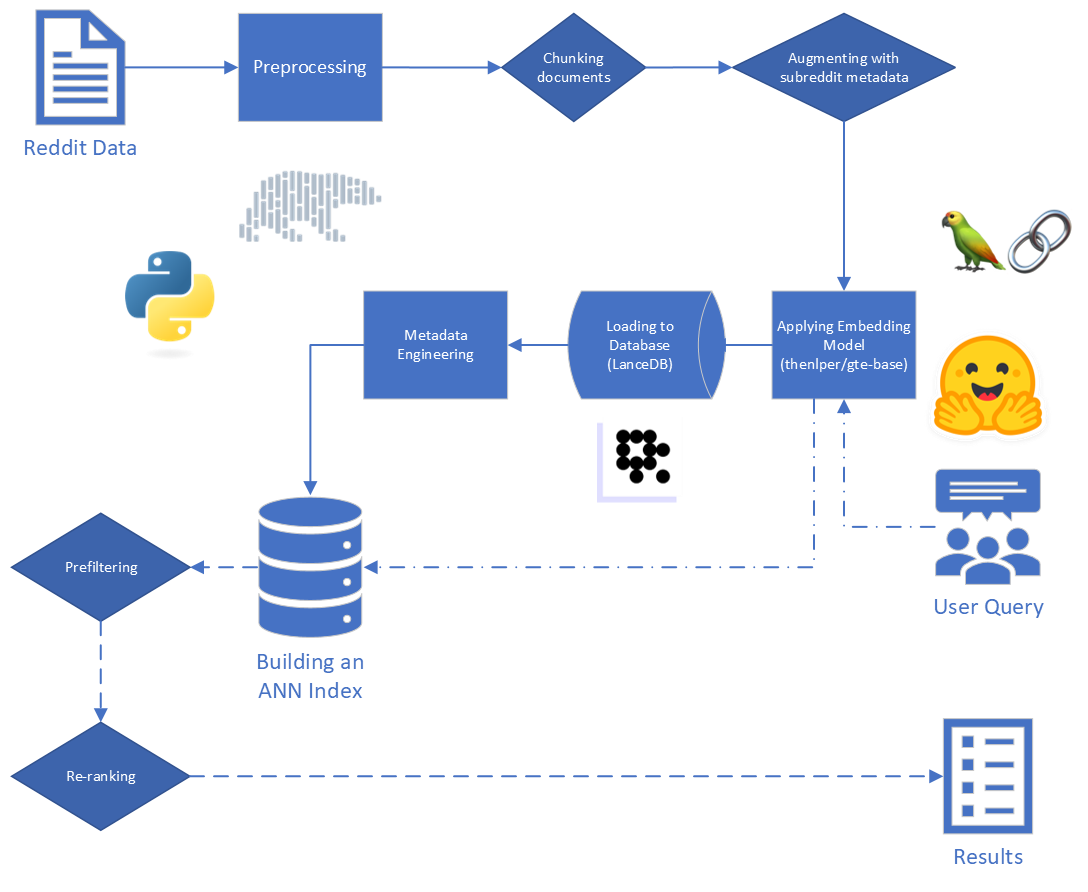
Dimulai dengan data mentah, kami melakukan beberapa pembersihan dasar:
reddit_text dari "[deleted]" atau "removed" .reddit_text yang panjangnya setidaknya 35 karakter, dan muncul lebih dari 7 kali. Kami tidak ingin segera menjatuhkan frasa umum yang lebih pendek, jika mereka mungkin berguna nanti (lihat menggunakan metadata yang direkayasa).reddit_text kosong.reddit_title adalah proxy untuk reddit_text . Jadi, kami mengganti reddit_text kosong dengan reddit_title dalam hal ini. Kami menggunakan versi dasar dari model Embeddings Teks Umum (GTE), yang didasarkan pada Kerangka Bert. Dokumentasi tentang Huggingface: Tautan.
Kami memilih model ini karena tampaknya ukuran yang masuk akal (0,22GB), ini adalah open source, dan memungkinkan penyematan teks dengan panjang 512 token. Ini berkinerja sangat baik dalam pengelompokan dan pengambilan dibandingkan dengan transformator kalimat open source lainnya yang memiliki parameter kurang dari 250m: tautan.
Selain itu, bagian dari pelatihannya dilakukan dengan menggunakan data Reddit, yang menambah daya tariknya.
Kami mempertimbangkan eksperimen dengan model lain, tetapi karena biaya komputasi yang tinggi untuk menanamkan dataset dengan setiap model baru, kami menyimpan jalan ini untuk pekerjaan di masa depan.
Kami menggunakan kerangka kerja transformator kalimat yang disediakan oleh Sbert untuk mengimplementasikan model penyematan kami, serta memeluk alat embedding wajah yang disediakan oleh Langchain
Selama embedding kami mempertimbangkan parameter berikut:
chunk_size : panjang maksimum teks untuk disematkan sebagai dokumenchunk_overlap : Setiap kali dokumen perlu dipecah menjadi potongan -potongan, berapa banyak yang harus mereka tumpang tindihKami juga bereksperimen dengan melampirkan metadata ke potongan sebelum menanamkan. Untuk melakukan ini, kami cukup menambahkan judul subreddit (atau perkiraan) ke awal potongan teks sebelum menanamkan. Misalnya, jika ada komentar di FedExers yang mengatakan "Saya sangat suka bekerja di sini karena ..." maka kita akan menambahkan "FedEx" sampai awal chunk dan menanamkan "FedEx n n Saya sangat suka bekerja di sini karena ..."
Intuisi kami adalah bahwa, dalam kasus -kasus di mana sebuah pos tidak secara eksplisit memasukkan nama perusahaan yang mereka diskusikan, kami dapat menyimpulkan informasi itu dari subreddit dan bahwa ini mungkin mendorong vektor itu lebih dekat dengan kueri kami. Misalnya, jika kita bertanya, "Mengapa karyawan suka bekerja di Disney?" dan “Mengapa karyawan suka bekerja di FedEx?” Harapan kami adalah bahwa penambahan metadata membuatnya lebih mungkin bahwa komentar di atas muncul lebih tinggi dalam hasil untuk kueri FedEx, dan mungkin lebih rendah dalam hasil untuk permintaan Disney.
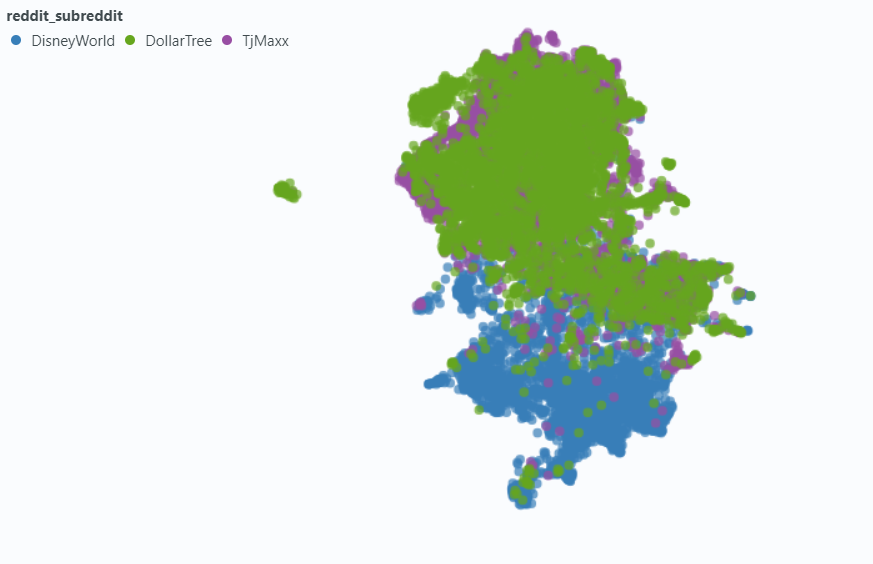
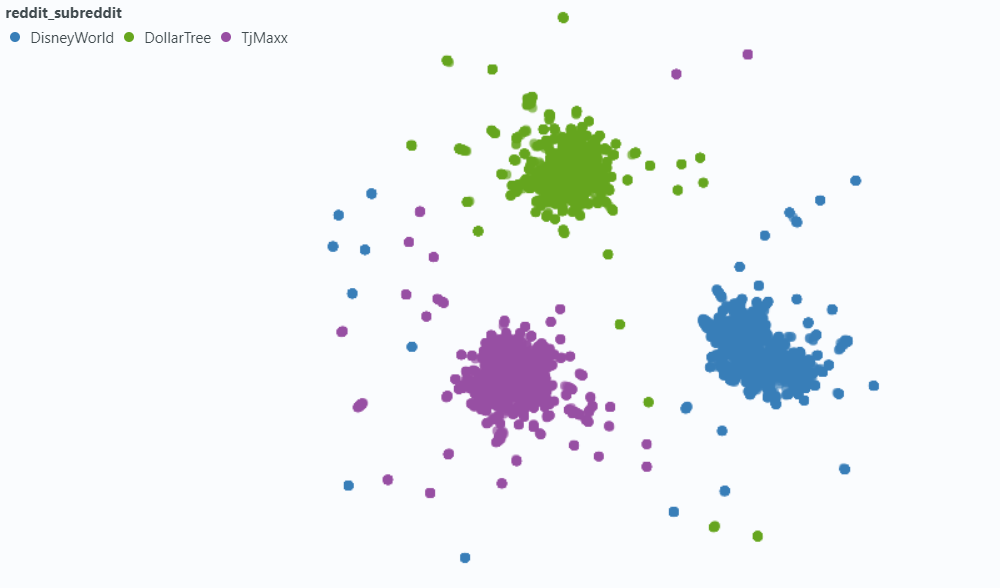
Kami menggunakan sorotan untuk memvisualisasikan efek pada sampel kecil dari data kami.
Menanamkan tanpa metadata:
Menanamkan dengan metadata:
Kami memilih LandedB (tautan) untuk menangani kebutuhan basis data vektor kami. LandedB adalah opsi open source, dan memberikan integrasi dengan Python dan Polar, yang keduanya sangat kami andalkan.
LANCEDB menyediakan kombinasi dan indeks file terbalik (IVF) dan kuantisasi produk (PQ) untuk membangun perkiraan indeks tetangga terdekat (JST).
Kedua bagian dari indeks IVF-PQ dapat disesuaikan dengan menyesuaikan parameter berikut:
Kami memperbaiki parameter pengindeksan, dan memvariasikan parameter pengambilan. Padahal, jika waktu diizinkan, kita mungkin bervariasi untuk melihat bagaimana waktu pengambilan dan akurasi terpengaruh.
Selain parameter kueri yang dibangun ke dalam indeks JST kami, kami memvariasikan variabel pra-retrieval dan pasca-retrieval lainnya untuk mencoba dan meningkatkan hasil keseluruhan kami.
Saat memberi label data, kami melihat jenis hasil umum dari hasil "terkait tetapi tidak relevan": reddit_text yang mengajukan pertanyaan yang mirip dengan kueri itu sendiri.
Sebagian besar waktu, teks -teks ini berasal dari submission (sebagai lawan komentar). Jadi, salah satu cara untuk mencoba dan meningkatkan hasil yang lebih relevan mungkin dengan menghilangkannya dari pencarian vektor. Ini cukup mudah, mengingat bahwa informasi ini terkandung dalam metadata asli kami.
Lebih jarang, tetapi masih cukup untuk diperhatikan, comment akan menunjukkan properti ini. Untuk mencoba dan mengekang dampaknya, kami merekayasa kolom metadata is_short_question untuk mencoba dan mengidentifikasi semua contoh reddit_text yang mengajukan pertanyaan singkat (dan dengan demikian tidak mungkin memberikan informasi yang berguna untuk menjawab pertanyaan -pertanyaan itu) sehingga mereka juga dapat disaring sebelum pencarian.
Untuk meningkatkan peringkat hasil setelah pengambilan, kami merekayasa beberapa metadata pemujaan yang memungkinkan kami memanfaatkan informasi yang disediakan oleh konten balasan.
Kami merekayasa dua jenis metadata:
sentiment balasan dan,agree_distance (dan disagree_distance ) untuk balasan. Dalam kasus reply_sentiment , kami menggunakan model pemrosesan bahasa alami yang sudah terlatih yang disebut "MRM8488/Distilroberta-Finetuned-Finansial-News-Analysis", untuk mengukur nada emosional di balik teks. Model ini membantu kami untuk mengklasifikasikan setiap balasan ke dalam kategori seperti positif, netral, atau negatif. Skor sentimen dari semua balasan kemudian dikumpulkan untuk mencerminkan sentimen keseluruhan terhadap setiap posting asli dan komentar berikut. Asumsi yang mendasari di sini adalah bahwa posting yang menghasilkan balasan positif yang dominan cenderung konstruktif dan informatif, sehingga berfungsi sebagai proksi untuk dukungan pengguna yang mirip dengan Upvotes di Reddit. Hipotesis kami adalah bahwa posting dengan balasan yang lebih positif akan lebih cenderung berisi informasi yang berguna.
Dalam hal agree_distance kami mengukur jarak antara setiap reddit_text dan satu set "pernyataan setuju". Lalu, setiap kali pengiriman atau komentar telah membalas, kami menambahkan top_reply_agree_distance dan avg_reply_agree_distance . Hipotesis kami adalah bahwa posting dengan balasan yang lebih dekat dengan pernyataan "setuju" akan lebih cenderung berisi informasi yang relevan. Demikian pula, posting dengan balasan yang lebih dekat dengan pernyataan "tidak setuju" akan lebih kecil kemungkinannya relevan.
Saat peringkat ulang, hasil dengan avg_reply_agree_distance yang lebih rendah ditabrak lebih tinggi, hasilnya dengan avg_reply_disagree_distance yang lebih rendah ditabrak lebih rendah.
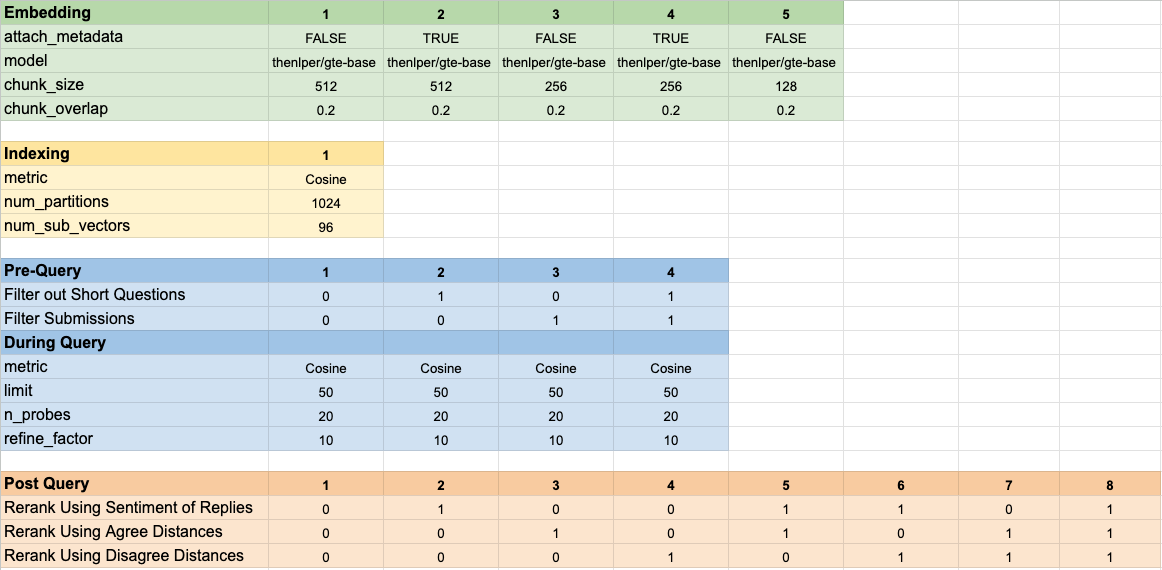
Kami menguji 160 konfigurasi model yang berbeda. Setiap konfigurasi menyertakan pilihan penyematan, strategi untuk memfilter tes sebelum melakukan pencarian vektor kami, dan strategi untuk peringkat ulang hasil yang diambil.
Hyper-parameter ini dirangkum dalam gambar di bawah ini:
Kami memiliki dua tujuan utama yang kami pikirkan ketika mengevaluasi hasil kami:
Sementara waktu pengambilan cukup mudah untuk diukur, kami perlu mengembangkan beberapa alat untuk mengukur kemajuan kami pada peringkat hasil.
Untuk menetapkan garis dasar untuk mengevaluasi peringkat hasil, kami secara manual memberi label subset hasil untuk menetapkan metrik awal relevansi. Untuk melakukan ini, kami membuat dua pertanyaan untuk masing -masing dari tiga belas kumpulan data dalam set pelatihan kami, dan memberi label 20 hasil teratas yang diambil untuk setiap kueri. Hasilnya diberi label sebagai:
Untuk setiap pasangan hasil-kueri, label akhir ditentukan oleh suara pluralitas, dengan ikatan default menjadi kurang relevan. Data berlabel manual ini kemudian digunakan untuk mengukur hasil.
Kami menggunakan tiga metrik untuk hasil peringkat. Masing -masing adalah versi yang dimodifikasi dari metrik sistem rekomendasi, disesuaikan dengan kasus penggunaan kami di mana kami tidak memiliki kebenaran tanah yang jelas, atau peringkat yang mapan dari hasil yang relevan dari yang paling relevan hingga paling tidak relevan.
Metrik ini memberikan skor yang menunjukkan seberapa dekat ke atas hasil yang relevan pertama kali diketahui muncul. Skor sempurna 1 telah dicapai jika hasil teratas dari setiap kueri relevan.
Untuk menghitung peringkat timbal balik untuk kueri yang diberikan, kami menerapkan formula berikut:
Dalam aplikasi standar, ada satu hasil "kebenaran darat" yang diketahui. Dalam aplikasi yang dimodifikasi kami, kami menerima hasil yang relevan yang diketahui sebagai kebenaran dasar.
Kami kemudian menghitung rata -rata skor ini di semua pertanyaan standar kami untuk sampai pada peringkat timbal balik rata -rata.
Metrik ini memberikan skor yang menunjukkan berapa banyak hasil relevan kami yang diketahui muncul di dekat bagian atas. Skor sempurna dari 1 dicapai jika semua hasil yang relevan diketahui muncul sebagai hasil teratas untuk semua kueri (tanpa hasil yang tidak berlabel muncul lebih tinggi dari hasil yang relevan yang diketahui.)
Untuk menghitung peringkat timbal balik yang diperluas untuk kueri yang diberikan, kami menerapkan formula berikut:
Di mana
Di mana
Dalam aplikasi standar, setiap hasil yang relevan memiliki peringkatnya sendiri, dan kontribusinya terhadap skor keseluruhan memperhitungkan peringkat ini sebagai posisi yang diharapkan dalam hasil. Dalam aplikasi yang dimodifikasi kami, kami memberikan kontribusi yang sama dengan hasil yang relevan yang diketahui yang muncul di atas posisi
Kami kemudian menghitung rata -rata skor ini di semua pertanyaan standar kami untuk sampai pada peringkat timbal balik rata -rata.
Discounted Cumulative Gain (DCG) sering digunakan sebagai metrik untuk mengevaluasi kinerja mesin pencari, dan mengukur efisiensi algoritma dalam menempatkan hasil yang relevan di bagian atas daftar pengambilan. Untuk daftar tanggapan panjang
Di mana
Karena skor DCG sangat tergantung pada panjang daftar pengambilan, kita perlu menormalkannya sehingga penilaian konsisten di seluruh skenario pengambilan kueri dengan jumlah hasil yang bervariasi. Skor Gain Kumulatif Diskon Normalisasi (NDCG) pada posisi
dimana
NDCG dapat mengambil skor relevansi ordinal (1 untuk sangat relevan, 2 untuk agak relevan, demikian juga). Kami memodifikasi skema penilaian untuk kasus kami, dengan mengubah label manusia kami (1-relevan, terkait 2 tetapi tidak relevan, tidak terkait 3) menjadi skema penilaian biner. Hasil dengan label manusia = 1 diberi skor relevansi = 1, dan yang lainnya diberi skor relevansi 0. Ini dilakukan untuk memastikan bahwa konfigurasi terbaik, seperti yang ditentukan oleh skor NDCG, seharusnya hanya mengembalikan hasil yang sangat relevan. Kami kemudian menghitung skor NDCG dari kueri standar kami dan rata -rata untuk mendapatkan skor NDCG rata -rata dari konfigurasi tertentu. Skor DCG dan skor IDCG dihitung dengan pengaturan
Di mana
Kami menggunakan parameter model berikut sebagai baseline kami untuk perbandingan:
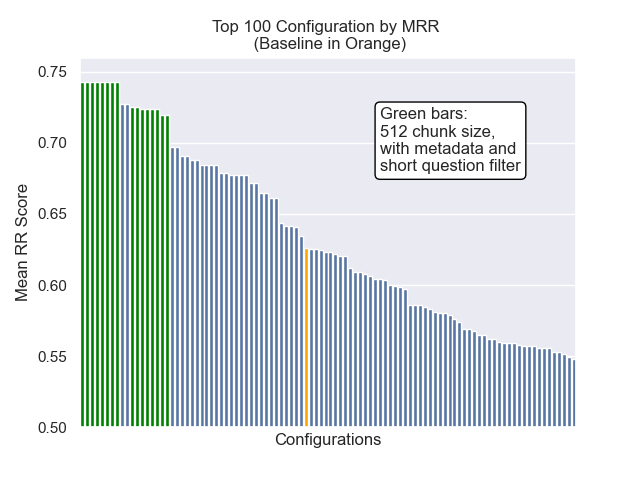
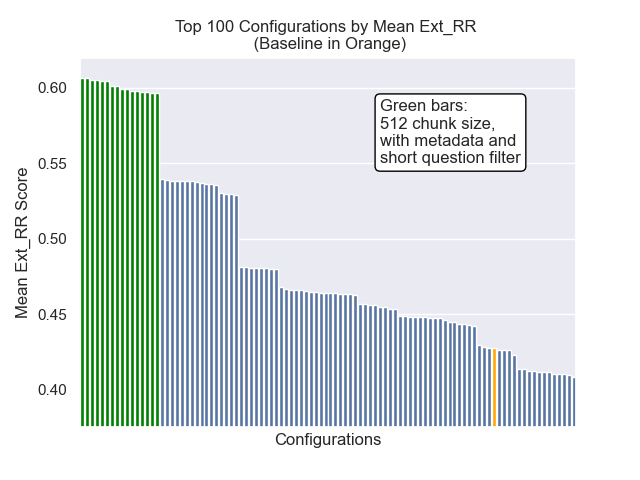
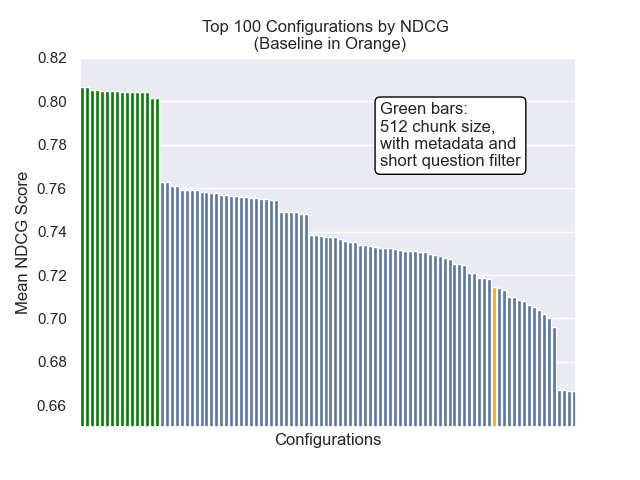
Konfigurasi dasar mencapai skor berikut di seluruh metrik kami:
| Metrik | Skor | Peringkat (dari 160) |
|---|---|---|
| Berarti peringkat timbal balik | 0.626031 | 46 |
| Peringkat timbal balik rata -rata diperpanjang | 0.427189 | 84 |
| Gain kumulatif diskon dinormalisasi | 0.714459 | 84 |
| Peringkat keseluruhan rata -rata | 71.33 |
Konfigurasi yang mencapai hasil keseluruhan terbaik (peringkat rata -rata tertinggi lintas metrik):
Konfigurasi ini mencapai skor berikut di seluruh metrik kami:
| Metrik | Skor | Peringkat (dari 160) |
|---|---|---|
| Berarti peringkat timbal balik | 0.742735 | 7 |
| Peringkat timbal balik rata -rata diperpanjang | 0.599379 | 9 |
| Gain kumulatif diskon dinormalisasi | 0.806476 | 1 |
| Peringkat keseluruhan rata -rata | 5.67 |
Di bawah ini, kita dapat melihat posisi relatif konfigurasi baseline ke keseluruhan teratas.
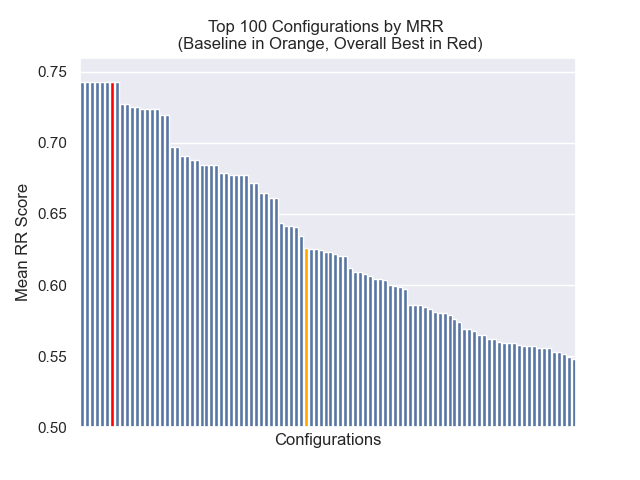
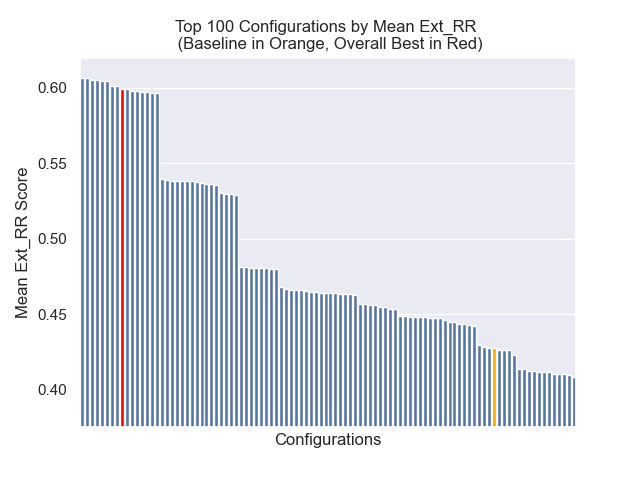
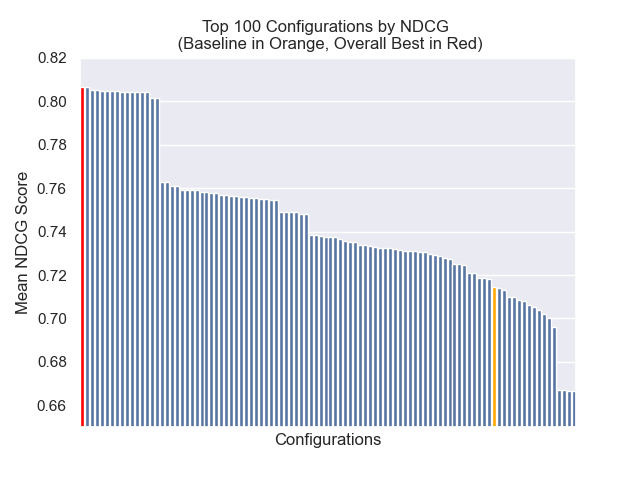
Tampaknya penurunan ukuran chunk memiliki dampak negatif yang umumnya pada hasil.
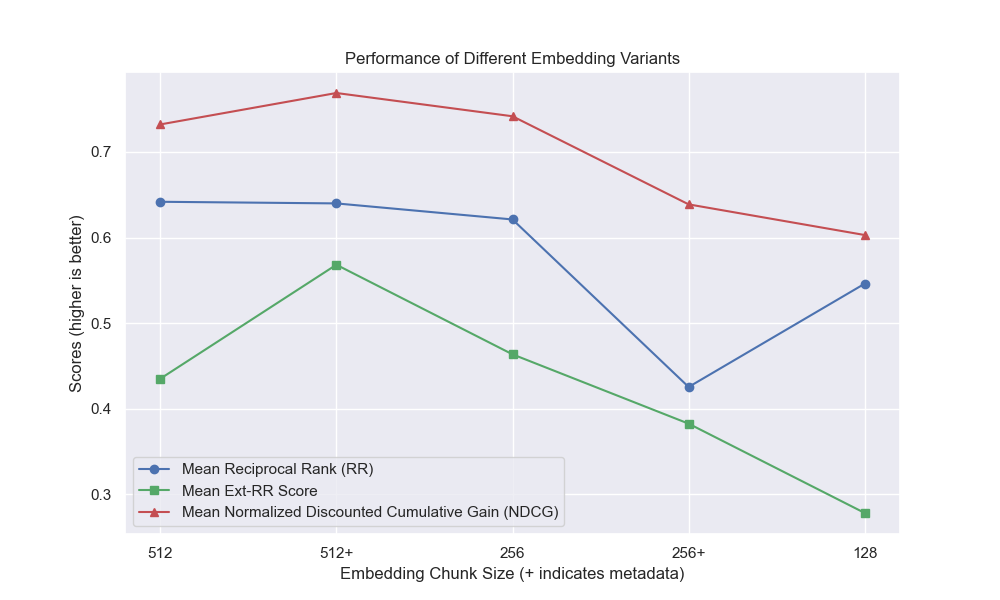
Juga, menyaring pertanyaan singkat sebelum pengambilan memiliki dampak positif terlepas dari pilihan hiperparameter lainnya.
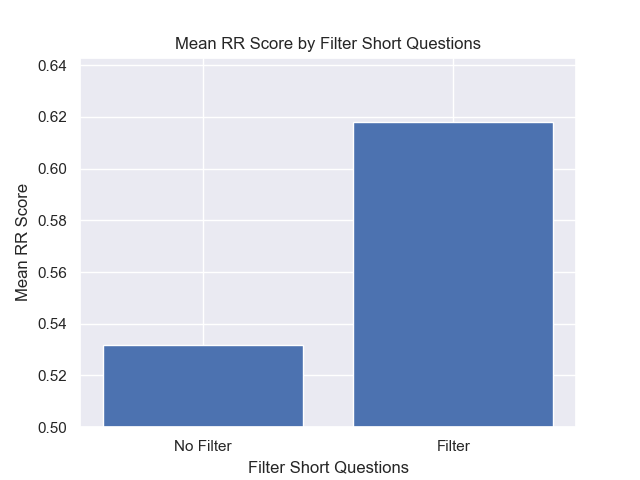
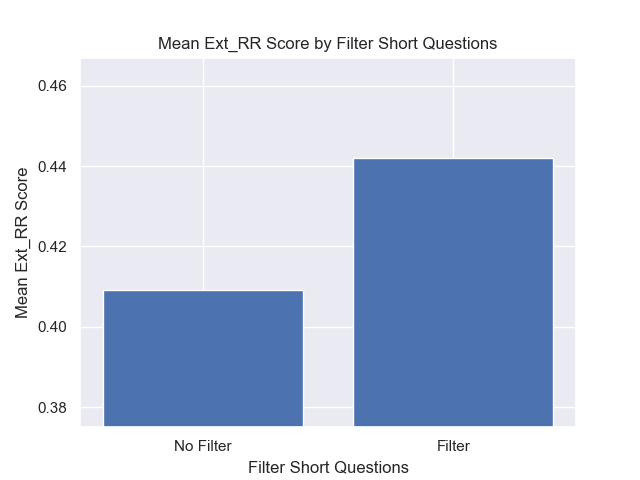
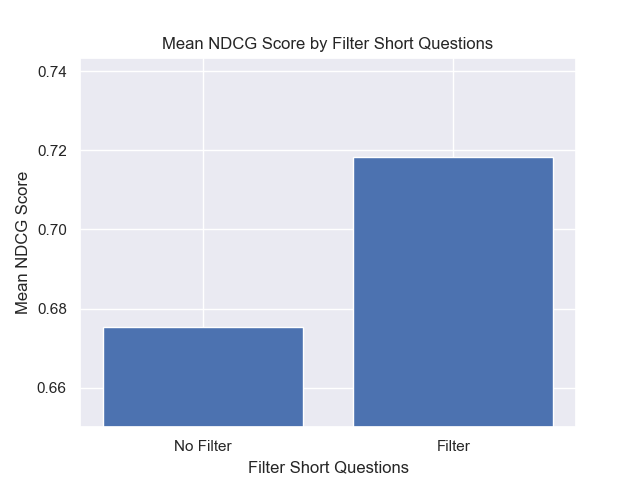
Jika kami menyoroti hanya konfigurasi yang berisi variasi ini bersama -sama (ukuran 512 chunk, dengan metadata tambahan, dan penyaringan dengan pertanyaan singkat) kami melihat seberapa baik kinerja relatif terhadap konfigurasi lainnya.
Beberapa bidang penyelidikan potensial di masa depan:


