ESIM
1.0.0
使用Pytorch实施自然语言推断的ESIM模型
该存储库包含了Chen等人“增强自然语言推断的LSTM的LSTM”中列出的顺序模型的实现。 2016年。
下图说明了模型架构的高级视图。
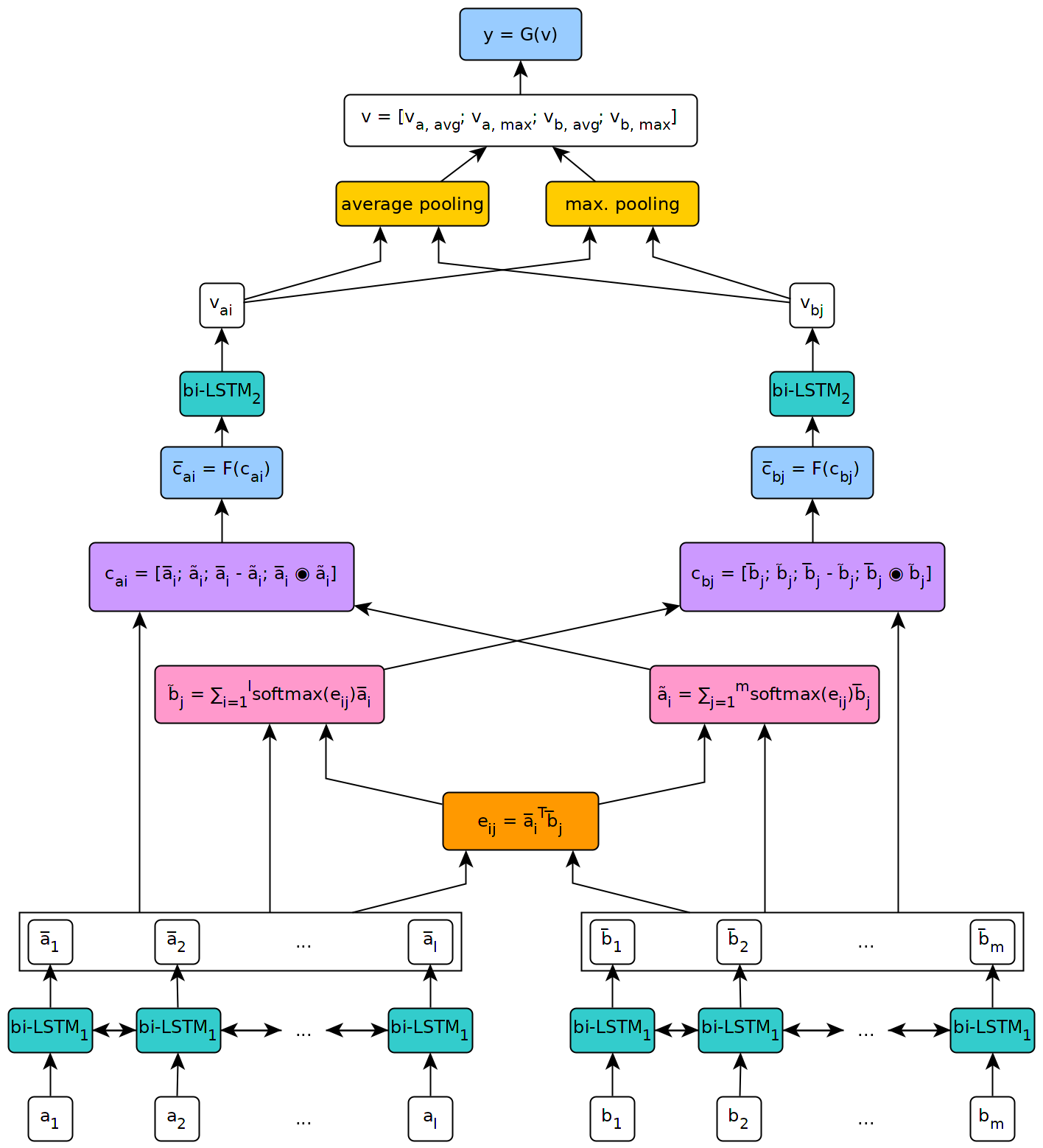
该模型是在我在日内瓦大学硕士论文的背景下实施的。
要使用此存储库中定义的模型,首先需要按照软件包官方页面上描述的步骤在计算机上安装Pytorch(仅在使用Windows时才需要此步骤)。然后,要安装运行模型所需的依赖项,只需执行命令pip install --upgrade .从克隆的存储库中(在根部,最好是在虚拟环境中)。
位于此存储库的脚本/文件夹中的fetch_data.py脚本可用于下载一些NLI数据集和验证的单词嵌入。默认情况下,脚本获取SNLI语料库和Glove 840B 300D嵌入。可以通过简单地将其URL作为参数传递给脚本(例如Multnli数据集)来下载其他数据集。
脚本的用法如下:
fetch_data.py [-h] [--dataset_url DATASET_URL]
[--embeddings_url EMBEDDINGS_URL]
[--target_dir TARGET_DIR]
其中target_dir是必须保存下载数据的目录的路径(默认为../ data/ )。
对于Multinli,需要从Kaggle手动下载匹配和错配的测试集,并在MultinLi_1.0数据集文件夹中复制的相应.txt文件。
在可以在ESIM模型中使用下载的语料库和嵌入式之前,需要对它们进行预处理。可以使用此存储库的脚本/预处理文件夹中的PY py脚本进行预处理_*。 preprocess_snli.py脚本可用于预处理snli, preprocess_mnli.py进行preprocess multinli和preprocess_bnli.py ,以预先处理破坏NLI(BNLI)数据集。请注意,调用脚本fot fot fot bnli时,应该先对SNLI数据进行预处理,以便可以在BNLI上使用它的词数。
脚本的用法如下(用SNLI , MNLI或BNLI替换 *):
preprocess_*.py [-h] [--config CONFIG]
其中config是定义用于预处理的参数的配置文件的路径。默认配置文件可以在此存储库的“配置/预处理文件夹”中找到。
脚本/培训文件夹中的py脚本_*。可用于在某些培训数据上训练ESIM模型并在某些验证数据中验证它。
脚本的用法是以下(替换为snli或mnli ):
train_*.py [-h] [--config CONFIG] [--checkpoint CHECKPOINT]
其中config为配置文件(默认文件位于配置/培训文件夹中), checkpoint是可选的检查点,可以从中恢复培训。检查点是由脚本创建的,每个训练时期之后,名称为esim _*。pth.tar ,其中'*'指示时代的数字。
脚本/测试文件夹中的测试_*。PY脚本可用于在某些测试数据上测试验证的ESIM模型。
要在SNLI上进行测试,请使用test_snli.py脚本如下:
test_snli.py [-h] test_data checkpoint
其中test_data是通往一些预处理测试集的途径, checkpoint是通往train_snli.py脚本产生的检查点的途径(训练时期后创建的检查点之一,或者在培训期间看到的最佳模型,该检查点保存在数据/snli/snli/snli/best.pth.tar -best.pth.tar- the Esim the Esim itsim the lift and liftar and liftar the lif。不能用于恢复培训,因为它不包含优化器的状态)。
test_snli.py脚本也可以在SNLI上预处理的模型上使用Breaking NLI数据集。
要在Multinli上进行测试,请使用test_mnli.py脚本如下:
test_mnli.py [-h] [--config CONFIG] checkpoint
其中config是一个配置文件(默认文件在配置/测试中可用),并且checkpoint是由train_mnli.py脚本产生的检查点。
test_mnli.py脚本对Multinli匹配和不匹配的测试集进行了预测,并将其保存在.CSV文件中。为了获得与模型预测相关联的分类精度,它产生的.CSV文件需要提交给Multinli的Kaggle竞赛。
该存储库的数据/检查点/SNLI文件夹中提供了对SNLI进行预训练的模型。该模型接受了在配置/提供的默认配置文件中定义的参数。要进行测试,只需执行python test_snli.py ../../preprocessed/SNLI/test_data.pkl ../../data/checkpoints/best.pth.tar来自脚本/testing文件夹。
验证的模型在SNLI数据集上实现了以下性能:
| 分裂 | 准确性 (%) |
|---|---|
| 火车 | 93.2 |
| 开发 | 88.4 |
| 测试 | 88.0 |
结果与Chen等人在论文中提出的结果一致。
在Breaking NLI数据集上,由Glockner等人出版。正如本文报道的那样,2018年,该模型的精度达到了65.5% 。
在Multinli上,该模型达到以下准确性:
| 分裂 | 匹配 | 不匹配 |
|---|---|---|
| 开发 | 77.0% | 76.8% |
| 测试 | 76.6% | 75.8% |
这些结果略高于Williams等人报道的结果。在他们的Multinli论文中。


