ESIM
1.0.0
Implementação do modelo ESIM para inferência de linguagem natural com Pytorch
Este repositório contém uma implementação com Pytorch do modelo seqüencial apresentado no artigo "LSTM aprimorado para inferência de linguagem natural" de Chen et al. em 2016.
A figura abaixo ilustra uma visão de alto nível da arquitetura do modelo.
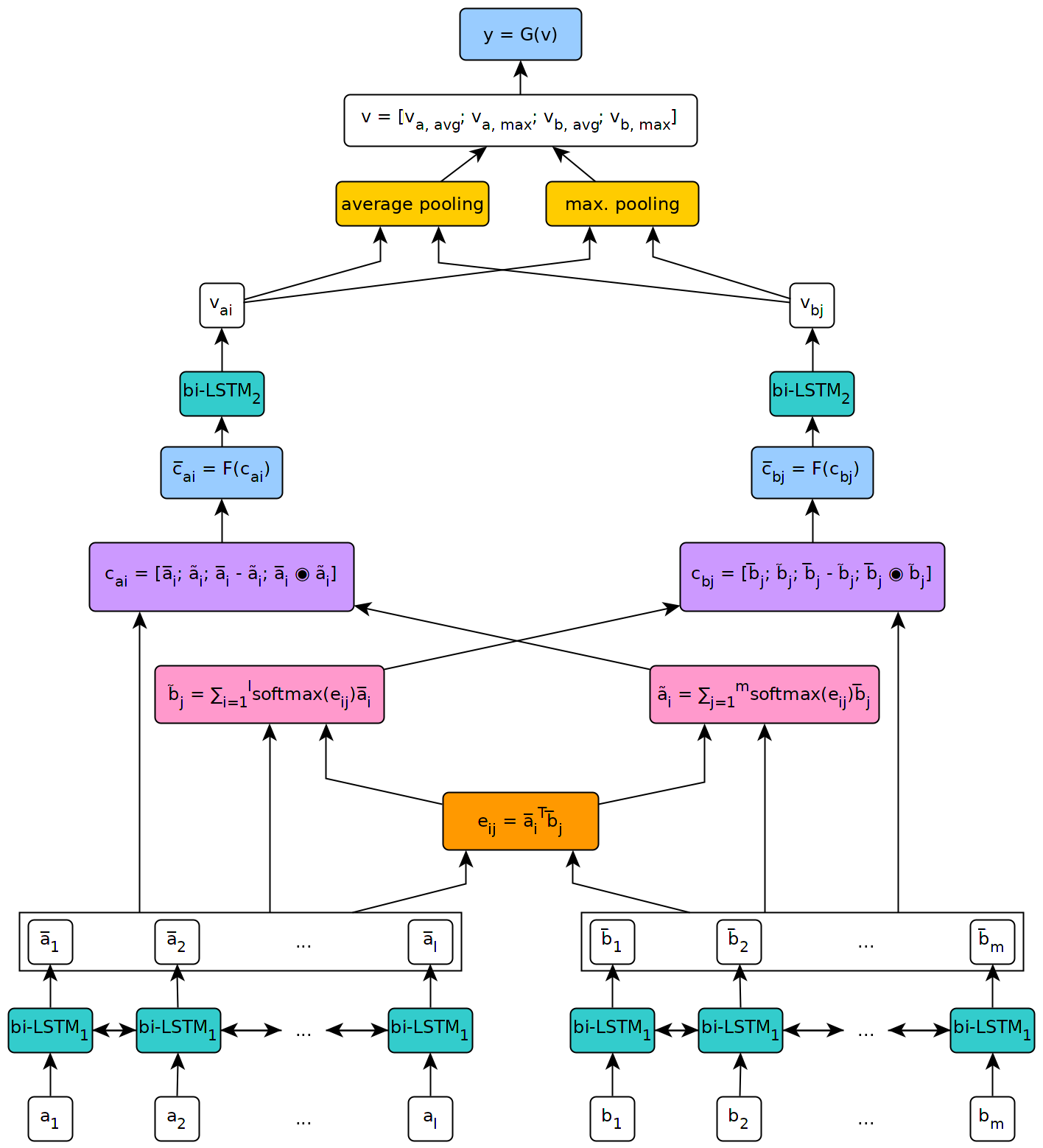
Este modelo foi implementado no contexto da tese de meu mestrado na Universidade de Genebra.
Para usar o modelo definido neste repositório, você precisará primeiro instalar o Pytorch em sua máquina seguindo as etapas descritas na página oficial do pacote (esta etapa é necessária apenas se você usar o Windows). Em seguida, para instalar as dependências necessárias para executar o modelo, basta executar o comando pip install --upgrade . De dentro do repositório clonado (na raiz e, de preferência, dentro de um ambiente virtual).
O script fetch_data.py localizado nos scripts/ pasta deste repositório pode ser usado para baixar algum conjunto de dados NLI e incorporação de palavras pré -treinadas. Por padrão, o script busca o corpus snli e a luva 840b 300D incorporando. Outros conjuntos de dados podem ser baixados simplesmente passando seu URL como argumento para o script (por exemplo, o conjunto de dados multnli).
O uso do script é o seguinte:
fetch_data.py [-h] [--dataset_url DATASET_URL]
[--embeddings_url EMBEDDINGS_URL]
[--target_dir TARGET_DIR]
Onde target_dir é o caminho para um diretório em que os dados baixados devem ser salvos (padrão para ../data/ ).
Para o Multinli, os conjuntos de testes correspondentes e incompatíveis precisam ser baixados manualmente do Kaggle e os arquivos .txt correspondentes copiados na pasta Multinli_1.0 .
Antes que o corpus e as incorporação baixado possam ser usados no modelo ESIM, eles precisam ser pré -processados. Isso pode ser feito com os scripts de pré -processamento _*. O script preprocess_snli.py pode ser usado para pré -processar snli, preprocess_mnli.py para pré -processar multinli e preprocess_bnli.py para pré -processar o conjunto de dados de quebra de nli (bnli). Observe que, ao chamar o script de bnli, os dados do SNLI deveriam ter sido pré -processados primeiro, para que o WordDict produzido para ele possa ser usado no BNLI.
O uso dos scripts é o seguinte (substitua o * por snli , mnli ou bnli ):
preprocess_*.py [-h] [--config CONFIG]
onde config é o caminho para um arquivo de configuração que define os parâmetros a serem usados para pré -processamento. Os arquivos de configuração padrão podem ser encontrados na pasta config/pré -processamento deste repositório.
O trem _*. Py scripts na pasta Scripts/Training podem ser usados para treinar o modelo ESIM em alguns dados de treinamento e validá -los em alguns dados de validação.
O uso do script é o seguinte (substitua o * por snli ou mnli ):
train_*.py [-h] [--config CONFIG] [--checkpoint CHECKPOINT]
Onde config é um arquivo de configuração (o padrão está localizado na pasta de configuração/treinamento ) e checkpoint é um ponto de verificação opcional do qual o treinamento pode ser retomado. Os pontos de verificação são criados pelo script após cada época de treinamento, com o nome Esim _*. Pth.tar , onde '*' indica o número da época.
O teste _*. Py scripts na pasta Scripts/teste podem ser usados para testar um modelo ESIM pré -treinado em alguns dados de teste.
Para testar no SNLI, use o script test_snli.py da seguinte forma:
test_snli.py [-h] test_data checkpoint
onde test_data é o caminho para algum conjunto de testes pré -processados, e checkpoint é o caminho para um ponto de verificação produzido pelo script de trens_snli.py (um dos pontos de verificação criados após as épocas de treinamento, ou o melhor modelo de treinamento , que é salvo no shats e snli . não pode ser usado para retomar o treinamento, pois não contém o estado do otimizador).
O script test_snli.py também pode ser usado no conjunto de dados NLI quebrado com um modelo pré -criado no SNLI.
Para testar no Multinli, use o script test_mnli.py da seguinte forma:
test_mnli.py [-h] [--config CONFIG] checkpoint
Onde config é um arquivo de configuração (um padrão está disponível no Config/Testing ) e checkpoint é um ponto de verificação produzido pelo script do Train_mnli.py .
O script test_mnli.py faz previsões nos conjuntos de testes correspondentes e incompatíveis da Multinli e os salva em arquivos .csv. Para obter a precisão da classificação associada às previsões do modelo, os arquivos .CSV que ele produz precisam ser enviados às competições Kaggle para Multinli.
Um modelo pré-treinado no SNLI é disponibilizado na pasta Data/Points/SNLI deste repositório. O modelo foi treinado com os parâmetros definidos nos arquivos de configuração padrão fornecidos na configuração/ . Para testá -lo, basta executar python test_snli.py ../../preprocessed/SNLI/test_data.pkl ../../data/checkpoints/best.pth.tar de dentro da pasta Scripts/Testing .
O modelo pré -treinado atinge o desempenho a seguir no conjunto de dados do SNLI:
| Dividir | Precisão (%) |
|---|---|
| Trem | 93.2 |
| Dev | 88.4 |
| Teste | 88.0 |
Os resultados estão alinhados com os apresentados no artigo por Chen et al.
No conjunto de dados de quebra de NLI, publicado por Glockner et al. Em 2018, o modelo atinge 65,5% de precisão, conforme relatado no artigo.
Em Multinli, o modelo atinge a seguinte precisão:
| Dividir | Combinado | Incompatível |
|---|---|---|
| Dev | 77,0 % | 76,8 % |
| Teste | 76,6 % | 75,8 % |
Esses resultados estão um pouco acima do relatado por Williams et al. em seu papel multinli.


