ESIM
1.0.0
การใช้แบบจำลอง ESIM สำหรับการอนุมานภาษาธรรมชาติด้วย pytorch
ที่เก็บนี้มีการใช้งานด้วย pytorch ของแบบจำลองลำดับที่นำเสนอในกระดาษ "ปรับปรุง LSTM สำหรับการอนุมานภาษาธรรมชาติ" โดย Chen et al ในปี 2559
รูปด้านล่างแสดงให้เห็นถึงมุมมองระดับสูงของสถาปัตยกรรมของโมเดล
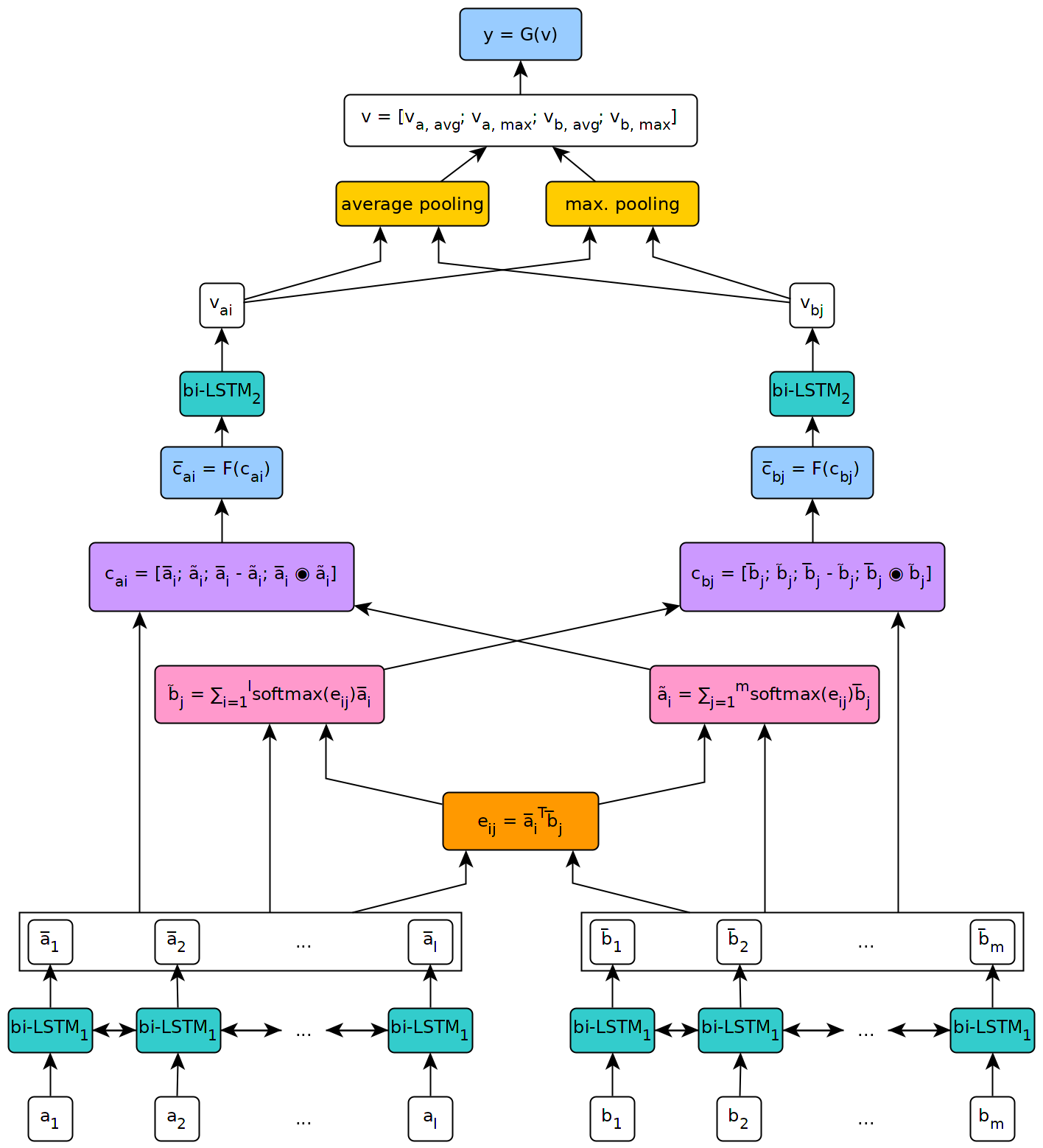
แบบจำลองนี้ถูกนำไปใช้ในบริบทของวิทยานิพนธ์ปริญญาโทของฉันที่มหาวิทยาลัยเจนีวา
ในการใช้โมเดลที่กำหนดไว้ในที่เก็บนี้คุณจะต้องติดตั้ง pytorch บนเครื่องของคุณก่อนที่จะทำตามขั้นตอนที่อธิบายไว้ในหน้าอย่างเป็นทางการของแพ็คเกจ (ขั้นตอนนี้จำเป็นก็ต่อเมื่อคุณใช้ Windows) จากนั้นในการติดตั้งการพึ่งพาที่จำเป็นในการเรียกใช้โมเดลเพียงแค่เรียกใช้ pip install --upgrade . จากภายในที่เก็บโคลน (ที่รากและควรอยู่ในสภาพแวดล้อมเสมือนจริง)
สคริปต์ fetch_data.py ที่อยู่ใน สคริปต์/ โฟลเดอร์ของที่เก็บนี้สามารถใช้ในการดาวน์โหลดชุดข้อมูล NLI บางส่วนและการฝังคำที่ผ่านการปรับแต่ง โดยค่าเริ่มต้นสคริปต์จะดึงคลังข้อมูล SNLI และถุงมือ 840B 300D ฝัง ชุดข้อมูลอื่น ๆ สามารถดาวน์โหลดได้เพียงแค่ส่ง URL เป็นอาร์กิวเมนต์ไปยังสคริปต์ (ตัวอย่างเช่นชุดข้อมูล MultNLI)
การใช้สคริปต์มีดังต่อไปนี้:
fetch_data.py [-h] [--dataset_url DATASET_URL]
[--embeddings_url EMBEDDINGS_URL]
[--target_dir TARGET_DIR]
โดยที่ target_dir เป็นเส้นทางไปยังไดเรกทอรีที่ต้องบันทึกข้อมูลที่ดาวน์โหลดมา (ค่าเริ่มต้นเป็น ../data /)
สำหรับ MultinLI ชุดทดสอบที่ตรงกันและไม่ตรงกันจะต้องดาวน์โหลดด้วยตนเองจาก Kaggle และไฟล์. txt ที่สอดคล้องกันที่คัดลอกในโฟลเดอร์ชุดข้อมูล MultInLI_1.0
ก่อนที่จะใช้คลังข้อมูลและการฝังตัวในรุ่น ESIM พวกเขาจะต้องถูกประมวลผลล่วงหน้า สามารถทำได้ด้วย การประมวลผลล่วงหน้า _*. สคริปต์ PY ใน สคริปต์/โฟลเดอร์การประมวลผลล่วงหน้า ของที่เก็บนี้ preprocess_snli.py สคริปต์สามารถใช้ในการประมวลผล preprocess snli, preprocess_mnli.py เพื่อประมวลผล preprocess multinli และ preprocess_bnli.py เพื่อประมวลผลชุดข้อมูล NLI (BNLI) โปรดทราบว่าเมื่อเรียกสคริปต์ FOT BNLI ข้อมูล SNLI ควรได้รับการประมวลผลล่วงหน้าก่อนเพื่อให้คำที่ผลิตขึ้นสามารถใช้กับ BNLI ได้
การใช้สคริปต์ของสคริปต์เป็นสิ่งต่อไปนี้ (แทนที่ * ด้วย snli , mnli หรือ bnli ):
preprocess_*.py [-h] [--config CONFIG]
โดยที่ config เป็นพา ธ ไปยังไฟล์กำหนดค่าที่กำหนดพารามิเตอร์ที่จะใช้สำหรับการประมวลผลล่วงหน้า ไฟล์การกำหนดค่าเริ่มต้นสามารถพบได้ในโฟลเดอร์ กำหนดค่า/การประมวลผลล่วงหน้า ของที่เก็บนี้
รถไฟ _*. สคริปต์ PY ใน สคริปต์/โฟลเดอร์การฝึกอบรม สามารถใช้ในการฝึกอบรมแบบจำลอง ESIM บนข้อมูลการฝึกอบรมบางอย่างและตรวจสอบข้อมูลการตรวจสอบความถูกต้อง
การใช้งานของสคริปต์มีดังต่อไปนี้ (แทนที่ * ด้วย SNLI หรือ MNLI ):
train_*.py [-h] [--config CONFIG] [--checkpoint CHECKPOINT]
โดยที่ config เป็นไฟล์การกำหนดค่า (ไฟล์เริ่มต้นอยู่ในโฟลเดอร์ config/training ) และ checkpoint เป็นจุดตรวจสอบเพิ่มเติมซึ่งสามารถฝึกอบรมต่อได้ จุดตรวจจะถูกสร้างขึ้นโดยสคริปต์หลังจากการฝึกอบรมแต่ละครั้งด้วยชื่อ esim _*. pth.tar โดยที่ '*' หมายถึงหมายเลขของยุค
การทดสอบ _*. สคริปต์ PY ใน สคริปต์/โฟลเดอร์ทดสอบ สามารถใช้เพื่อทดสอบโมเดล ESIM ที่ผ่านการฝึกอบรมเกี่ยวกับข้อมูลการทดสอบบางอย่าง
ในการทดสอบ SNLI ให้ใช้สคริปต์ test_snli.py ดังนี้:
test_snli.py [-h] test_data checkpoint
โดยที่ test_data เป็นเส้นทางไปยังชุดทดสอบที่ประมวลผลล่วงหน้าและ checkpoint เป็นเส้นทางไปยังจุดตรวจ ที่ ผลิตโดยสคริปต์ train_snli.py (ทั้งหนึ่งในจุดตรวจที่สร้างขึ้นหลังจากการฝึกอบรมยุค หรือ แบบจำลองที่ดี ที่สุด ที่เห็น ไม่สามารถใช้ในการฝึกอบรมต่อเนื่องจากไม่มีสถานะของ Optimizer)
สคริปต์ test_snli.py ยังสามารถใช้กับชุดข้อมูล NLI ที่แตกหักด้วยแบบจำลองที่ใช้ใน SNLI
ในการทดสอบ multinli ให้ใช้สคริปต์ test_mnli.py ดังนี้:
test_mnli.py [-h] [--config CONFIG] checkpoint
โดยที่ config เป็นไฟล์การกำหนดค่า (ไฟล์เริ่มต้นมีอยู่ใน การกำหนดค่า/การทดสอบ ) และ checkpoint เป็นจุดตรวจสอบที่ผลิตโดยสคริปต์ train_mnli.py
สคริปต์ test_mnli.py ทำการคาดการณ์เกี่ยวกับชุดทดสอบที่จับคู่และไม่ตรงกันของ MultinLI และบันทึกไว้ในไฟล์. csv เพื่อให้ได้ความแม่นยำในการจำแนกประเภทที่เกี่ยวข้องกับการคาดการณ์ของโมเดลไฟล์. csv ที่สร้างขึ้นจะต้องส่งไปยังการแข่งขัน Kaggle สำหรับ multinli
แบบจำลองที่ผ่านการฝึกอบรมล่วงหน้าเกี่ยวกับ SNLI นั้นมีอยู่ในโฟลเดอร์ ข้อมูล/จุดตรวจ/SNLI ของที่เก็บนี้ โมเดลได้รับการฝึกอบรมด้วยพารามิเตอร์ที่กำหนดไว้ในไฟล์การกำหนดค่าเริ่มต้นที่มีให้ใน config/ ในการทดสอบเพียงแค่เรียกใช้ python test_snli.py ../../preprocessed/SNLI/test_data.pkl ../../data/checkpoints/best.pth.tar จากภายใน สคริปต์/โฟลเดอร์ทดสอบ
โมเดลที่ผ่านการฝึกฝนได้รับประสิทธิภาพต่อไปนี้ในชุดข้อมูล SNLI:
| แยก | ความแม่นยำ (%) |
|---|---|
| รถไฟ | 93.2 |
| คนกิน | 88.4 |
| ทดสอบ | 88.0 |
ผลลัพธ์เป็นไปตามที่นำเสนอในกระดาษโดยเฉินและคณะ
ในชุดข้อมูล NLI Breaking เผยแพร่โดย Glockner และคณะ ในปี 2561 แบบจำลองมีความแม่นยำ 65.5% ตามที่รายงานไว้ในกระดาษ
บน MultinLI โมเดลถึงความแม่นยำดังต่อไปนี้:
| แยก | ที่ได้เข้าคู่กัน | ไม่ตรงกัน |
|---|---|---|
| คนกิน | 77.0 % | 76.8 % |
| ทดสอบ | 76.6 % | 75.8 % |
ผลลัพธ์เหล่านี้สูงกว่าสิ่งที่รายงานโดย Williams และคณะ ในกระดาษ multinli ของพวกเขา


