ESIM
1.0.0
تنفيذ نموذج ESIM لاستنتاج اللغة الطبيعية مع Pytorch
يحتوي هذا المستودع على تنفيذ مع Pytorch للنموذج المتسلسل المقدم في الورقة "LSTM المحسّن لاستنتاج اللغة الطبيعية" بواسطة Chen et al. في عام 2016.
يوضح الشكل أدناه رؤية رفيعة المستوى لهندسة النموذج.
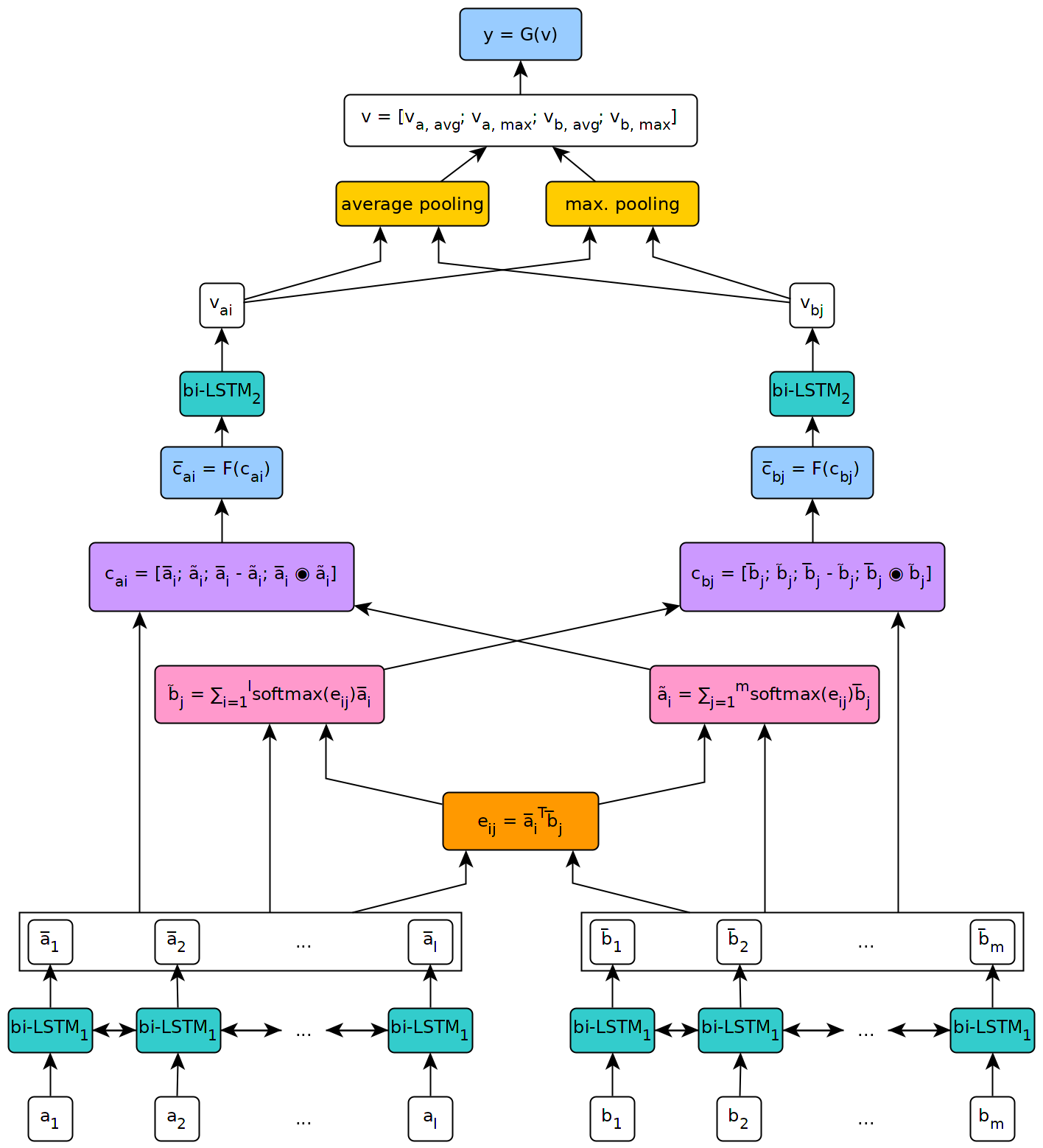
تم تنفيذ هذا النموذج في سياق أطروحة ماجستير في جامعة جنيف.
لاستخدام النموذج المحدد في هذا المستودع ، ستحتاج أولاً إلى تثبيت Pytorch على جهازك باتباع الخطوات الموضحة في الصفحة الرسمية للحزمة (هذه الخطوة ضرورية فقط إذا كنت تستخدم Windows). بعد ذلك ، لتثبيت التبعيات اللازمة لتشغيل النموذج ، ما عليك سوى تنفيذ ترتيب pip install --upgrade . من داخل المستودع المستنسخ (في الجذر ، ويفضل داخل بيئة افتراضية).
يمكن استخدام البرنامج النصي fetch_data.py الموجود في البرامج النصية/ المجلد من هذا المستودع لتنزيل بعض مجموعة بيانات NLI وتودمر الكلمات المسبق. بشكل افتراضي ، يجلب البرنامج النصي SNLI Corpus وتضمينات القفاز 840B 300D. يمكن تنزيل مجموعات البيانات الأخرى بمجرد تمرير عنوان URL الخاص بهم كوسيطة إلى البرنامج النصي (على سبيل المثال ، مجموعة بيانات multnli).
استخدام البرنامج النصي هو ما يلي:
fetch_data.py [-h] [--dataset_url DATASET_URL]
[--embeddings_url EMBEDDINGS_URL]
[--target_dir TARGET_DIR]
حيث يكون target_dir هو المسار إلى دليل حيث يجب حفظ البيانات التي تم تنزيلها (الافتراضيات إلى ../data/ ).
بالنسبة إلى Multinli ، يجب تنزيل مجموعات الاختبار المتطابقة وغير المتطابقة يدويًا من Kaggle وملفات .txt المقابلة في مجلد مجموعة بيانات multinli_1.0 .
قبل أن يتم استخدام المجموعة والتضمينات التي تم تنزيلها في نموذج ESIM ، يجب معالجتها مسبقًا. يمكن القيام بذلك مع المعالجة المسبقة _*. البرامج النصية PY في مجلد البرامج النصية/المعالجة المسبقة لهذا المستودع. يمكن استخدام البرنامج النصي preprocess_snli.py للمعالجة المسبقة SNLI ، و preprocess_mnli.py إلى مجموعة بيانات Multinli preprocess ، و preprocess_bnli.py . لاحظ أنه عند استدعاء البرنامج النصي fot bnli ، كان ينبغي معالجة بيانات SNLI أولاً ، بحيث يمكن استخدام كلمة WordDict التي تم إنتاجها على BNLI.
استخدام البرامج النصية هو ما يلي (استبدل * بـ * snli أو mnli أو bnli ):
preprocess_*.py [-h] [--config CONFIG]
عندما يكون config هو المسار إلى ملف التكوين الذي يحدد المعلمات المراد استخدامها للمعالجة المسبقة. يمكن العثور على ملفات التكوين الافتراضية في مجلد التكوين/المعالجة المسبقة لهذا المستودع.
يمكن استخدام قطار _*. البرامج النصية PY في مجلد البرامج النصية/التدريب لتدريب نموذج ESIM على بعض بيانات التدريب والتحقق من صحة بعض بيانات التحقق من الصحة.
استخدام البرنامج النصي هو ما يلي (استبدل * بـ * snli أو mnli ):
train_*.py [-h] [--config CONFIG] [--checkpoint CHECKPOINT]
عندما يكون config ملف تكوين (موجود الافتراضي في مجلد التكوين/التدريب ) ، ونقطة checkpoint هي نقطة تفتيش اختيارية يمكن من خلالها استئناف التدريب. يتم إنشاء نقاط التفتيش بواسطة البرنامج النصي بعد كل فترة تدريب ، مع اسم ESIM _*. pth.tar ، حيث يشير "*" إلى رقم الحقبة.
يمكن استخدام الاختبار _*. البرامج النصية PY في مجلد البرامج النصية/الاختبار لاختبار نموذج ESIM المسبق على بعض بيانات الاختبار.
لاختبار SNLI ، استخدم البرنامج النصي test_snli.py على النحو التالي:
test_snli.py [-h] test_data checkpoint
عندما يكون test_data هو المسار إلى مجموعة الاختبار المسبق مسبقًا ، ونقطة checkpoint هي المسار إلى نقطة تفتيش تنتجها البرنامج النصي Train_snli.py (إما إحدى نقاط التفتيش التي تم إنشاؤها بعد عصر التدريب ، أو أفضل نموذج يتم رؤيته أثناء التدريب ، والذي يتم حفظه في ملفات البيانات/snli/best.pth.tar - الفارق بين ESIM _*. لا يمكن استخدامه لاستئناف التدريب ، لأنه لا يحتوي على حالة المحسن).
يمكن أيضًا استخدام البرنامج النصي test_snli.py على مجموعة بيانات NLI المكسورة مع نموذج مسبق على SNLI.
لاختبار على multinli ، استخدم البرنامج النصي test_mnli.py على النحو التالي:
test_mnli.py [-h] [--config CONFIG] checkpoint
عندما يكون config ملف تكوين (يتوفر موقع افتراضي في التكوين/الاختبار ) ونقطة checkpoint هي نقطة تفتيش تنتجها البرنامج النصي train_mnli.py .
يقوم البرنامج النصي test_mnli.py بإجراء تنبؤات على مجموعات الاختبار المتطابقة والمتطابقة في Multinli وحفظها في ملفات .csv. للحصول على دقة التصنيف المرتبطة بتوقعات النموذج ، يجب تقديم ملفات .CSV التي تنتجها إلى مسابقات Kaggle لـ Multinli.
يتم توفير نموذج تم تدريبه مسبقًا على SNLI في مجلد البيانات/نقاط التفتيش/SNLI في هذا المستودع. تم تدريب النموذج مع المعلمات المحددة في ملفات التكوين الافتراضية المتوفرة في config/ . لاختبار ذلك ، ما عليك سوى تنفيذ python test_snli.py ../../preprocessed/SNLI/test_data.pkl ../../data/checkpoints/best.pth.tar من داخل مجلد البرامج النصية/الاختبار .
يحقق النموذج المسبق الأداء التالي على مجموعة بيانات SNLI:
| ينقسم | دقة (٪) |
|---|---|
| يدرب | 93.2 |
| ديف | 88.4 |
| امتحان | 88.0 |
تتماشى النتائج مع تلك المقدمة في الورقة بواسطة Chen et al.
على مجموعة بيانات Breaking NLI ، التي نشرتها Glockner et al. في عام 2018 ، يصل النموذج إلى دقة 65.5 ٪ ، كما ورد في الورقة.
على multinli ، يصل النموذج إلى الدقة التالية:
| ينقسم | متطابق | غير متطابق |
|---|---|---|
| ديف | 77.0 ٪ | 76.8 ٪ |
| امتحان | 76.6 ٪ | 75.8 ٪ |
هذه النتائج أعلى بقليل ما تم الإبلاغ عنه من قبل ويليامز وآخرون. في ورقة متعددة.


