ESIM
1.0.0
Pytorchとの自然言語推論のためのESIMモデルの実装
このリポジトリには、Chen et al。による「自然言語推論のためのLSTMの強化されたLSTM」に示されているシーケンシャルモデルのPytorchとの実装が含まれています。 2016年。
以下の図は、モデルのアーキテクチャの高レベルのビューを示しています。
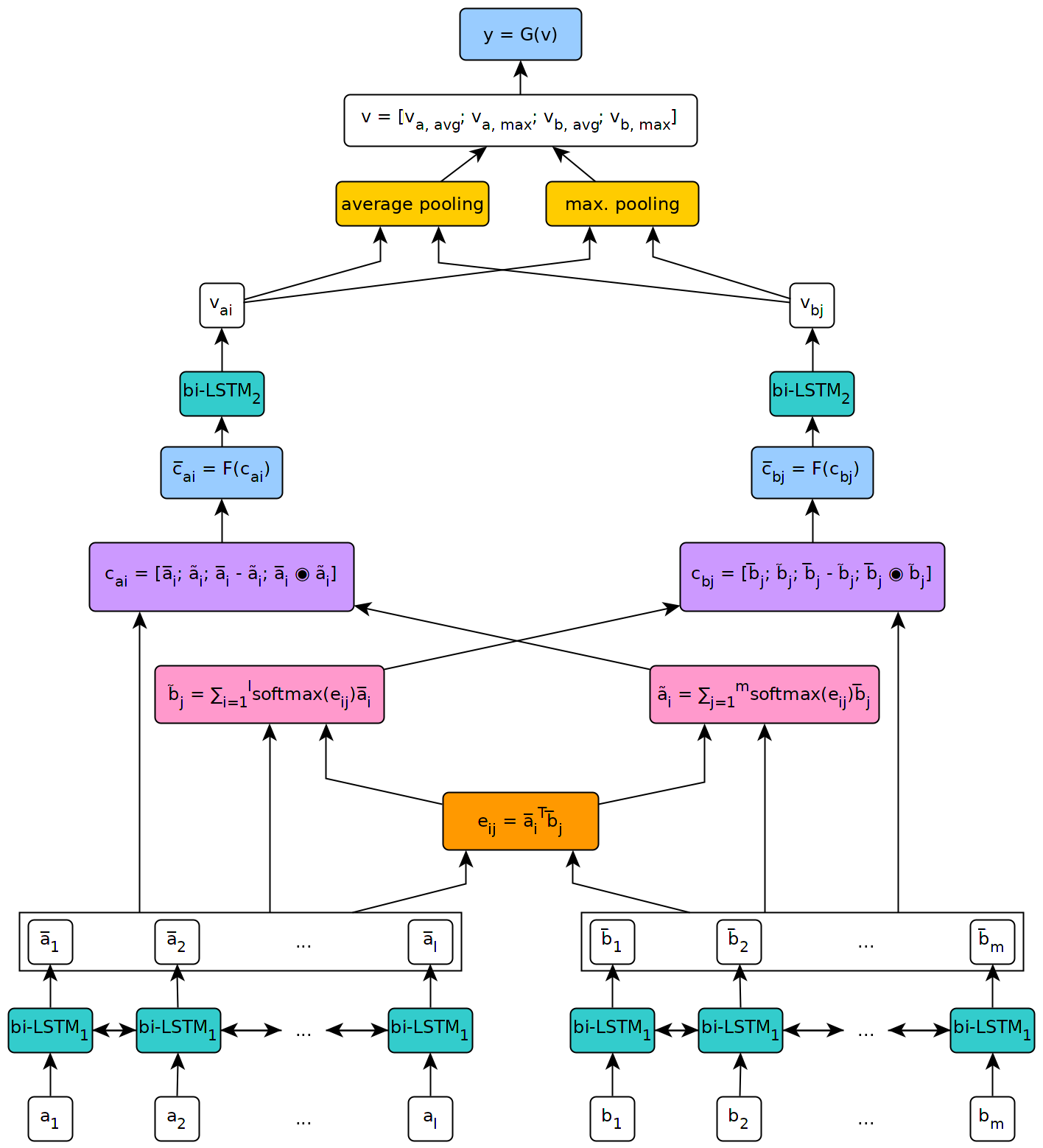
このモデルは、ジュネーブ大学での私の修士論文の文脈で実装されました。
このリポジトリで定義されているモデルを使用するには、パッケージの公式ページで説明されている手順に従って、まずマシンにPytorchをインストールする必要があります(この手順は、Windowsを使用する場合にのみ必要です)。次に、モデルの実行に必要な依存関係をインストールするには、コマンドpip install --upgrade .クローン化されたリポジトリ内(ルートで、できれば仮想環境内)から。
このリポジトリのスクリプト/フォルダーにあるFETCH_DATA.PYスクリプトは、いくつかのNLIデータセットと前処理された単語埋め込みをダウンロードするために使用できます。デフォルトでは、スクリプトはSNLIコーパスとグローブ840B 300D埋め込みを取得します。他のデータセットは、スクリプトに引数としてURLを渡すだけでダウンロードできます(たとえば、Multnliデータセット)。
スクリプトの使用法は次のとおりです。
fetch_data.py [-h] [--dataset_url DATASET_URL]
[--embeddings_url EMBEDDINGS_URL]
[--target_dir TARGET_DIR]
target_dirは、ダウンロードされたデータを保存する必要があるディレクトリへのパスです(デフォルトは../data/ )。
Multinliの場合、一致したテストと不一致のテストセットは、KaggleとMultiNli_1.0 Datasetフォルダーにコピーされた対応する.txtファイルから手動でダウンロードする必要があります。
ダウンロードされたコーパスと埋め込みをESIMモデルで使用する前に、それらを前処理する必要があります。これは、このリポジトリのスクリプト/プリプロセッシングフォルダーのプリプロース_*。pyスクリプトで実行できます。 preprocess_snli.pyスクリプトは、snli、 preprocess_mnli.pyをプリプロセスするmultinli、およびpreprocess_bnli.pyにプリプロセス_mnli.pyにプリプロセスを使用して、壊れたnli(bnli)データセットを事前に処理するために使用できます。 Bnliをfot fot fotに呼び出すとき、SNLIデータが最初に前処理され、それが作成されたWorddictがBNLIで使用できるようにする必要があることに注意してください。
スクリプトの使用法は次のものです( *をSNLI 、 MNLI 、またはBNLIに置き換えます):
preprocess_*.py [-h] [--config CONFIG]
ここで、 configは、前処理に使用されるパラメーターを定義する構成ファイルへのパスです。デフォルトの構成ファイルは、このリポジトリの構成/前処理フォルダーにあります。
スクリプト/トレーニングフォルダーのトレーニング_*
スクリプトの使用法は次のものです( *をSNLIまたはMNLIに置き換えます):
train_*.py [-h] [--config CONFIG] [--checkpoint CHECKPOINT]
configは構成ファイル(デフォルトのファイルは構成/トレーニングフォルダーにあります)であり、 checkpointトレーニングを再開できるオプションのチェックポイントです。チェックポイントは、各トレーニングエポックの後にスクリプトによって作成され、名前はesim _*。pth.tarという名前で作成されます。ここで、「*」はエポックの数を示します。
スクリプト/テストフォルダーのテスト_*。Pyスクリプトを使用して、いくつかのテストデータで前提条件のESIMモデルをテストできます。
SNLIでテストするには、次のようにtest_snli.pyスクリプトを使用します。
test_snli.py [-h] test_data checkpoint
test_data 、前処理されたテストセットへのパスであり、 checkpointはTrain_snli.pyスクリプトによって作成されたチェックポイントへのパスです(トレーニングエポックの後に作成されたチェックポイントのいずれか、またはデータ/チェックポイント/SN/best.pth.pth.tarの間の違いがあります。トレーニングを再開するために使用されます。これは、オプティマイザーの状態を含まないためです)。
test_snli.pyスクリプトは、snliで前提としたモデルを使用して、breaking nliデータセットでも使用できます。
Multinliでテストするには、次のようにtest_mnli.pyスクリプトを使用します。
test_mnli.py [-h] [--config CONFIG] checkpoint
configは構成ファイル(デフォルトのファイルは構成/テストで使用できます)であり、 checkpoint train_mnli.pyスクリプトによって生成されるチェックポイントです。
test_mnli.pyスクリプトは、Multinliのマッチングされたテストセットと不一致のテストセットを予測し、.csvファイルに保存します。モデルの予測に関連付けられた分類精度を取得するには、それが生成する.CSVファイルを、MultiNLIのKaggleコンペティションに提出する必要があります。
SNLIで事前に訓練されたモデルは、このリポジトリのデータ/チェックポイント/SNLIフォルダーで利用可能になります。モデルは、 config/で提供されるデフォルトの構成ファイルで定義されたパラメーターでトレーニングされました。それをテストするには、 python test_snli.py ../../preprocessed/SNLI/test_data.pkl ../../data/checkpoints/best.pth.tarをスクリプト/テストフォルダー内から実行するだけです。
事前に守られたモデルは、SNLIデータセットで次のパフォーマンスを実現します。
| スプリット | 正確さ (%) |
|---|---|
| 電車 | 93.2 |
| 開発者 | 88.4 |
| テスト | 88.0 |
結果は、Chenらによって論文に提示されたものと一致しています。
Glockner et al。 2018年、このモデルは、論文で報告されているように、 65.5%の精度に達します。
Multinliでは、モデルは次の精度に達します。
| スプリット | 一致した | 不一致 |
|---|---|---|
| 開発者 | 77.0% | 76.8% |
| テスト | 76.6% | 75.8% |
これらの結果は、ウィリアムズらによって報告されたものをわずかに上回っています。彼らの倍数の論文で。


