ESIM
1.0.0
Implementación del modelo ESIM para la inferencia del lenguaje natural con Pytorch
Este repositorio contiene una implementación con Pytorch del modelo secuencial presentado en el documento "LSTM mejorado para la inferencia del lenguaje natural" por Chen et al. en 2016.
La siguiente figura ilustra una vista de alto nivel de la arquitectura del modelo.
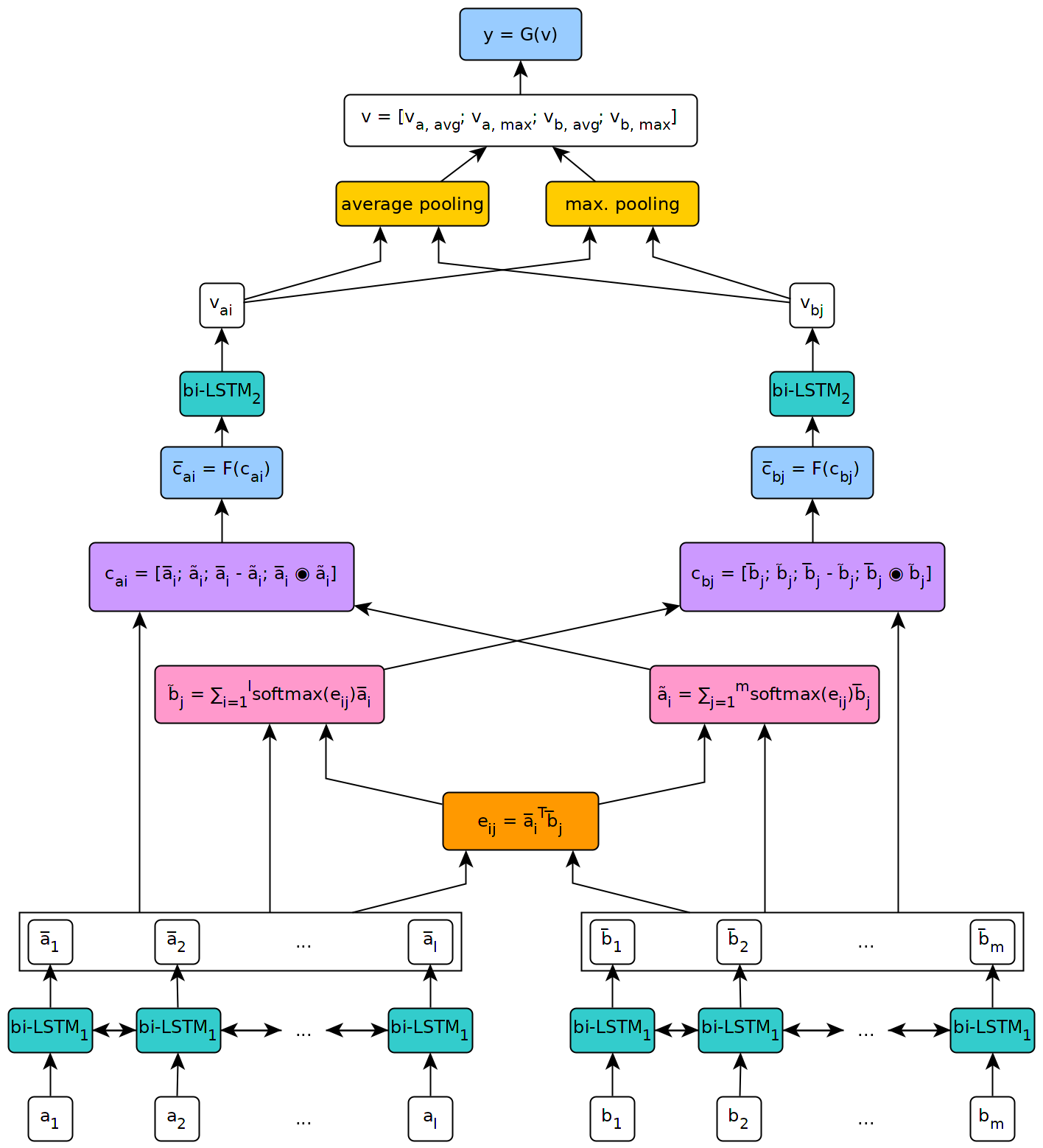
Este modelo se implementó en el contexto de la tesis de mi maestría en la Universidad de Ginebra.
Para usar el modelo definido en este repositorio, primero deberá instalar Pytorch en su máquina siguiendo los pasos descritos en la página oficial del paquete (este paso solo es necesario si usa Windows). Luego, para instalar las dependencias necesarias para ejecutar el modelo, simplemente ejecute el comando pip install --upgrade . desde dentro del repositorio clonado (en la raíz, y preferiblemente dentro de un entorno virtual).
El script fetch_data.py ubicado en los scripts/ carpeta de este repositorio se puede utilizar para descargar algunos conjuntos de datos NLI y incrustaciones de palabras previas a la aparición. Por defecto, el script obtiene el Corpus SNLI y los incrustaciones Glove 840B 300D. Otros conjuntos de datos se pueden descargar simplemente pasando su URL como argumento al script (por ejemplo, el conjunto de datos multnli).
El uso del script es el siguiente:
fetch_data.py [-h] [--dataset_url DATASET_URL]
[--embeddings_url EMBEDDINGS_URL]
[--target_dir TARGET_DIR]
Donde target_dir es la ruta a un directorio donde se deben guardar los datos descargados (predeterminados a ../data/ ).
Para multinli, los conjuntos de pruebas coincidentes y no coincidentes deben descargarse manualmente de Kaggle y los archivos .txt correspondientes copiados en la carpeta de datos de datos multinli_1.0 .
Antes de que se puedan usar el corpus y los incrustaciones descargados en el modelo ESIM, deben preprocesarse. Esto se puede hacer con el preproceso _*. PY Scripts en la carpeta scripts/preprocesamiento de este repositorio. El script preprocess_snli.py se puede usar para preprocesar snli, preprocess_mnli.py para preprocesar multinli y preprocess_bnli.py para preprocesar el conjunto de datos de ruptura nli (bnli). Tenga en cuenta que al llamar al script fot bnli, los datos de SNLI deberían haberse preprocesado primero, de modo que el descuento de palabras producido para ello se pueda usar en bnli.
El uso de los scripts es lo siguiente (reemplace el * con Snli , Mnli o Bnli ):
preprocess_*.py [-h] [--config CONFIG]
donde config es la ruta a un archivo de configuración que define los parámetros que se utilizarán para el preprocesamiento. Los archivos de configuración predeterminados se pueden encontrar en la carpeta Config/Preprocessing de este repositorio.
El tren _*. Los scripts PY en la carpeta de scripts/entrenamiento se pueden usar para entrenar el modelo ESIM en algunos datos de entrenamiento y validarlo en algunos datos de validación.
El uso del script es el siguiente (reemplace el * con snli o mnli ):
train_*.py [-h] [--config CONFIG] [--checkpoint CHECKPOINT]
donde config es un archivo de configuración (los predeterminados se encuentran en la carpeta config/entrenamiento ), y checkpoint es un punto de control opcional desde el cual se puede reanudar la capacitación. Los puntos de control son creados por el script después de cada época de entrenamiento, con el nombre ESIM _*. Pth.tar , donde '*' indica el número de la época.
La prueba _*. Los scripts de PY en la carpeta de scripts/prueba se pueden usar para probar un modelo ESIM previsto en algunos datos de prueba.
Para probar en SNLI, use el script test_snli.py de la siguiente manera:
test_snli.py [-h] test_data checkpoint
donde test_data es la ruta a algún conjunto de pruebas preprocesadas, y checkpoint es la ruta a un punto de control producido por el script trank_snli.py (uno de los puntos de control creados después de las épocas de entrenamiento, o el mejor modelo visto durante la capacitación, que se ahorra en datos/puntos de control/snli/best.pth.tar - la diferencia entre el eSim _*. Se utiliza para reanudar el entrenamiento, ya que no contiene el estado del optimizador).
El script test_snli.py también se puede usar en el conjunto de datos NLI de ruptura con un modelo previamente en SNLI.
Para probar en multinli, use el script test_mnli.py de la siguiente manera:
test_mnli.py [-h] [--config CONFIG] checkpoint
donde config es un archivo de configuración (uno predeterminado está disponible en config/testing ) y checkpoint es un punto de control producido por el script Train_mnli.py .
El script test_mnli.py hace predicciones en los conjuntos de pruebas coincidentes y no coincidentes de Multinli y los guarda en archivos .csv. Para obtener la precisión de clasificación asociada a las predicciones del modelo, los archivos .csv que produce deben enviarse a las competiciones de Kaggle para Multinli.
Un modelo previamente entrenado en SNLI se pone a disposición en la carpeta Data/Checkpoints/SNLI de este repositorio. El modelo se capacitó con los parámetros definidos en los archivos de configuración predeterminados proporcionados en config/ . Para probarlo, simplemente ejecute python test_snli.py ../../preprocessed/SNLI/test_data.pkl ../../data/checkpoints/best.pth.tar desde la carpeta scripts/testing .
El modelo previo alado logra el siguiente rendimiento en el conjunto de datos SNLI:
| Dividir | Exactitud (%) |
|---|---|
| Tren | 93.2 |
| Enchufe | 88.4 |
| Prueba | 88.0 |
Los resultados están en línea con los presentados en el documento por Chen et al.
En el conjunto de datos NLI Breaking, publicado por Glockner et al. En 2018, el modelo alcanza la precisión del 65.5% , como se informa en el documento.
En Multinli, el modelo alcanza la siguiente precisión:
| Dividir | Coincidente | No coincidente |
|---|---|---|
| Enchufe | 77.0 % | 76.8 % |
| Prueba | 76.6 % | 75.8 % |
Estos resultados están ligeramente por encima de lo que informó Williams et al. en su papel multinli.


