ESIM
1.0.0
Implementasi model ESIM untuk inferensi bahasa alami dengan pytorch
Repositori ini berisi implementasi dengan pytorch dari model sekuensial yang disajikan dalam makalah "Enhanced LSTM untuk Inferensi Bahasa Alami" oleh Chen et al. pada 2016.
Gambar di bawah ini menggambarkan pandangan tingkat tinggi dari arsitektur model.
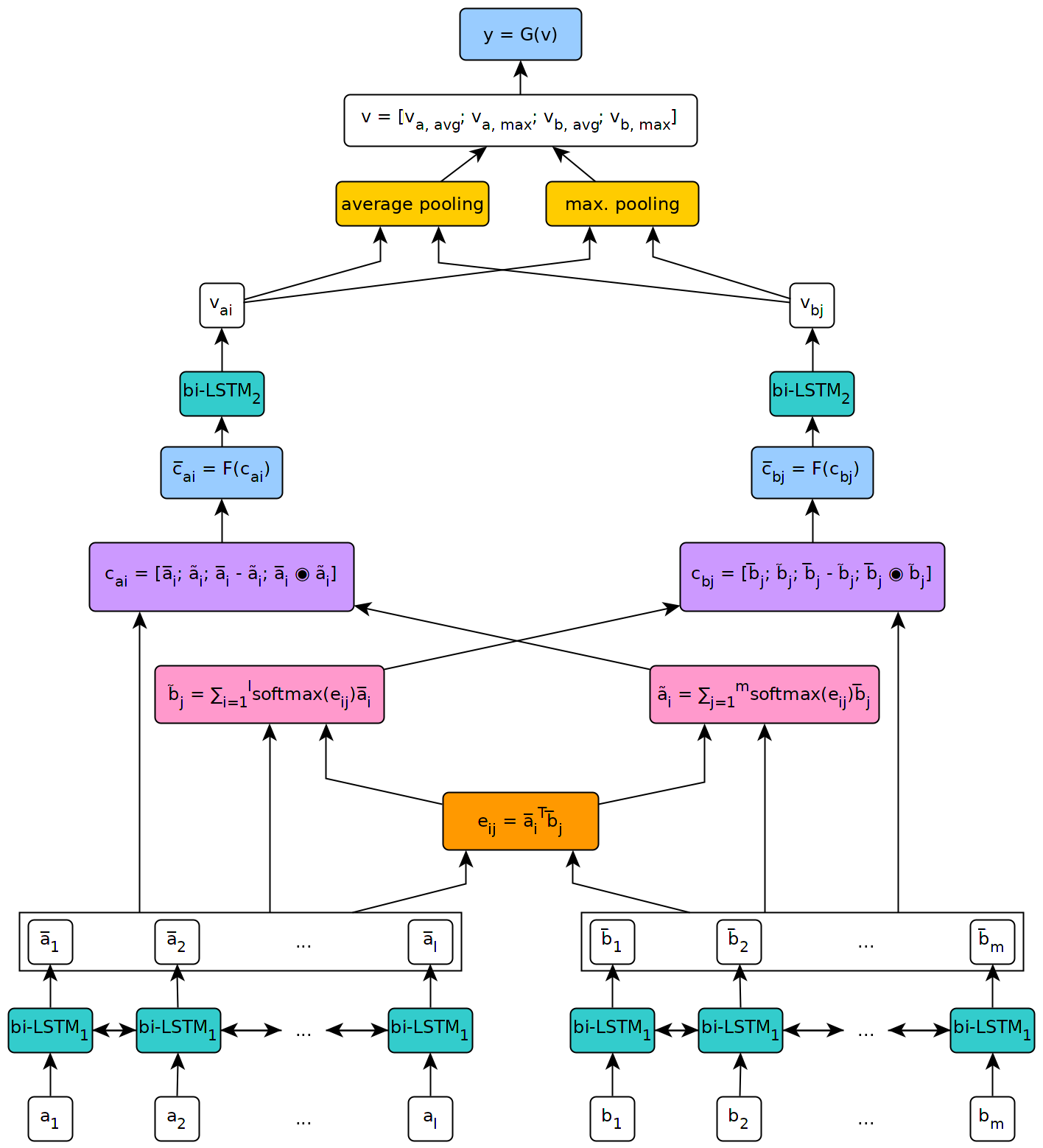
Model ini diimplementasikan dalam konteks tesis master saya di University of Geneva.
Untuk menggunakan model yang ditentukan dalam repositori ini, pertama -tama Anda harus menginstal pytorch pada mesin Anda dengan mengikuti langkah -langkah yang dijelaskan pada halaman resmi paket (langkah ini hanya diperlukan jika Anda menggunakan windows). Kemudian, untuk menginstal dependensi yang diperlukan untuk menjalankan model, cukup jalankan perintah pip install --upgrade . dari dalam repositori yang dikloning (pada root, dan lebih disukai di dalam lingkungan virtual).
Fetch_data.py Script yang terletak di skrip/ folder repositori ini dapat digunakan untuk mengunduh beberapa dataset NLI dan embeddings kata pretrained. Secara default, skrip mengambil snli corpus dan Glove 840b 300D embeddings. Dataset lain dapat diunduh hanya dengan meneruskan URL mereka sebagai argumen ke skrip (misalnya, dataset multnli).
Penggunaan skrip adalah sebagai berikut:
fetch_data.py [-h] [--dataset_url DATASET_URL]
[--embeddings_url EMBEDDINGS_URL]
[--target_dir TARGET_DIR]
di mana target_dir adalah jalur ke direktori di mana data yang diunduh harus disimpan (default ke ../data/ ).
Untuk multinli, set uji yang cocok dan tidak cocok perlu diunduh secara manual dari Kaggle dan file .txt yang sesuai yang disalin dalam folder dataset Multinli_1.0 .
Sebelum korpus dan embeddings yang diunduh dapat digunakan dalam model ESIM, mereka perlu diproses sebelumnya. Ini dapat dilakukan dengan preprocess _*. Py skrip dalam skrip/folder preprocessing dari repositori ini. Script preprocess_snli.py dapat digunakan untuk preprocess snli, preprocess_mnli.py untuk preprocess multinli, dan dataset preprocess_bnli.py untuk preprocess The Breaking NLI (BNLI). Perhatikan bahwa ketika memanggil skrip fot bnli, data SNLI seharusnya telah diproses terlebih dahulu, sehingga worddict yang diproduksi untuk itu dapat digunakan pada BNLI.
Penggunaan skrip adalah sebagai berikut (ganti * dengan snli , mnli atau bnli ):
preprocess_*.py [-h] [--config CONFIG]
di mana config adalah jalur ke file konfigurasi yang mendefinisikan parameter yang akan digunakan untuk preprocessing. File konfigurasi default dapat ditemukan di folder konfigurasi/preprocessing dari repositori ini.
Kereta _*. Skrip py dalam folder skrip/pelatihan dapat digunakan untuk melatih model ESIM pada beberapa data pelatihan dan memvalidasi pada beberapa data validasi.
Penggunaan skrip adalah sebagai berikut (ganti * dengan snli atau mnli ):
train_*.py [-h] [--config CONFIG] [--checkpoint CHECKPOINT]
Di mana config adalah file konfigurasi (yang default berada di folder konfigurasi/pelatihan ), dan checkpoint adalah pos pemeriksaan opsional dari pelatihan mana yang dapat dilanjutkan. Pos pemeriksaan dibuat oleh skrip setelah setiap zaman pelatihan, dengan nama ESIM _*. Pth.tar , di mana '*' menunjukkan nomor zaman.
Tes _*. Py skrip dalam skrip/folder pengujian dapat digunakan untuk menguji model ESIM pretrained pada beberapa data uji.
Untuk menguji snli, gunakan skrip test_snli.py sebagai berikut:
test_snli.py [-h] test_data checkpoint
di mana test_data adalah jalur menuju beberapa set tes praproses, dan checkpoint adalah jalur ke pos pemeriksaan yang dihasilkan oleh skrip train_snli.py (salah satu pos pemeriksaan yang dibuat setelah zaman pelatihan, atau model terbaik yang terlihat selama pelatihan, yang disimpan dalam data/pos . digunakan untuk melanjutkan pelatihan, karena tidak mengandung keadaan pengoptimal).
Script test_snli.py juga dapat digunakan pada dataset NLI yang melanggar dengan model pretrained pada SNLI.
Untuk menguji multinli, gunakan skrip test_mnli.py sebagai berikut:
test_mnli.py [-h] [--config CONFIG] checkpoint
Di mana config adalah file konfigurasi (yang default tersedia dalam konfigurasi/pengujian ) dan checkpoint adalah pos pemeriksaan yang diproduksi oleh skrip train_mnli.py .
Script test_mnli.py membuat prediksi pada set uji Multinli yang cocok dan tidak cocok dan menyimpannya di file .csv. Untuk mendapatkan akurasi klasifikasi yang terkait dengan prediksi model, file .csv yang dihasilkannya perlu diserahkan ke kompetisi Kaggle untuk multinli.
Model yang terlatih pada SNLI tersedia di folder data/pos pemeriksaan/SNLI dari repositori ini. Model dilatih dengan parameter yang ditentukan dalam file konfigurasi default yang disediakan dalam config/ . Untuk mengujinya, cukup jalankan python test_snli.py ../../preprocessed/SNLI/test_data.pkl ../../data/checkpoints/best.pth.tar dari dalam skrip/folder pengujian .
Model pretrain mencapai kinerja berikut pada dataset SNLI:
| Membelah | Akurasi (%) |
|---|---|
| Kereta | 93.2 |
| Dev | 88.4 |
| Tes | 88.0 |
Hasilnya sejalan dengan yang disajikan dalam makalah oleh Chen et al.
Pada dataset Breaking NLI, yang diterbitkan oleh Glockner et al. Pada tahun 2018, model mencapai akurasi 65,5% , seperti yang dilaporkan dalam makalah.
Di Multinli, model mencapai akurasi berikut:
| Membelah | Cocok | Tidak cocok |
|---|---|---|
| Dev | 77,0 % | 76,8 % |
| Tes | 76,6 % | 75,8 % |
Hasil ini sedikit di atas apa yang dilaporkan oleh Williams et al. di kertas multinli mereka.


