ESIM
1.0.0
Implementierung des ESIM -Modells für die Inferenz für natürliche Sprache mit Pytorch
Dieses Repository enthält eine Implementierung mit Pytorch des sequentiellen Modells, das in der Arbeit "Enhanced LSTM for Natural Language Inference" von Chen et al. Dargestellt wurde. 2016.
Die folgende Abbildung zeigt eine hochrangige Ansicht der Architektur des Modells.
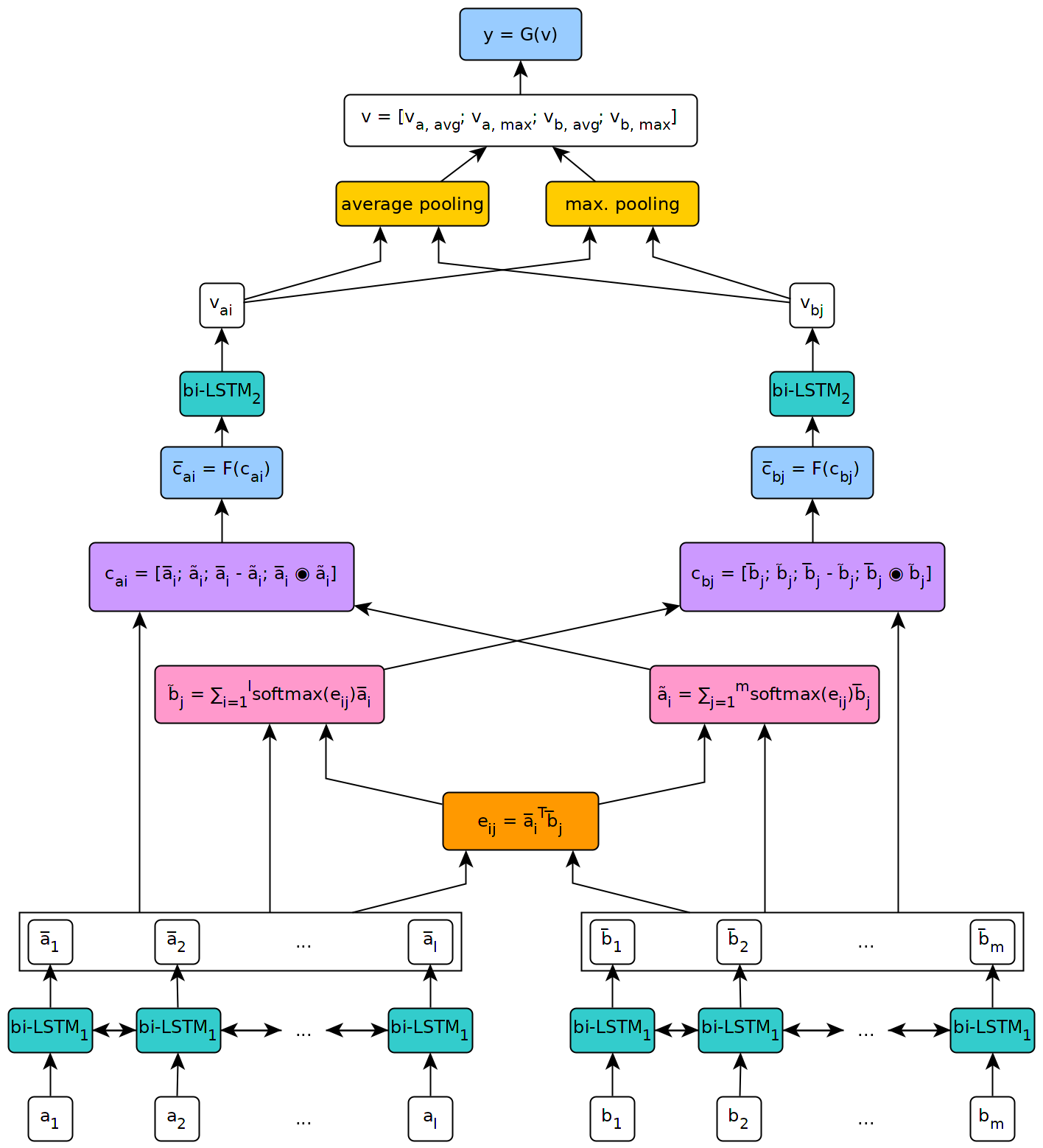
Dieses Modell wurde im Kontext meiner Masterarbeit an der Universität von Genf implementiert.
Um das in diesem Repository definierte Modell zu verwenden, müssen Sie zunächst PyTorch auf Ihrem Computer installieren, indem Sie die auf der offiziellen Seite des Pakets beschriebenen Schritte ausführen (dieser Schritt ist nur erforderlich, wenn Sie Windows verwenden). Um die zum Ausführen des Modells erforderlichen Abhängigkeiten zu installieren, führen Sie einfach die Befehls pip install --upgrade . Aus dem geklonten Repository (an der Wurzel und vorzugsweise innerhalb einer virtuellen Umgebung).
Das Skript fetch_data.py im Skript/ Ordner dieses Repositorys kann verwendet werden, um einige NLI -Datensatz- und vorbereitete Word -Einbettungen herunterzuladen. Standardmäßig holt das Skript den SNLI -Korpus und den Handschuh 840b 300D -Einbettungen ab. Andere Datensätze können heruntergeladen werden, indem einfach ihre URL als Argument an das Skript übergeben wird (z. B. den MultNLI -Datensatz).
Die Verwendung des Skripts ist Folgendes:
fetch_data.py [-h] [--dataset_url DATASET_URL]
[--embeddings_url EMBEDDINGS_URL]
[--target_dir TARGET_DIR]
wobei target_dir der Pfad zu einem Verzeichnis ist, in dem die heruntergeladenen Daten gespeichert werden müssen (Standardeinstellungen auf ../data/ ).
Für Multinli müssen die übereinstimmenden und nicht übereinstimmenden Testsets manuell von Kaggle und den entsprechenden .txt -Dateien, die im Datensatzordner multinli_1.0 kopiert wurden, manuell heruntergeladen werden.
Bevor das heruntergeladene Korpus und Einbettungen im ESIM -Modell verwendet werden können, müssen sie vorverarbeitet werden. Dies kann mit dem Vorverfahren _* . Das Skript precess_snli.py kann verwendet werden, um SNLI, Precess_Mnli.py zur Vorverarbeitung von Multinli und Precess_Bnli.py vorzubereiten, um den Datensatz von Breaking NLI (BNLI) vorzubereiten. Beachten Sie, dass die SNLI -Daten beim Aufrufen des Skriptfot -BNLI zuerst vorverarbeitet werden müssen, so dass das für sie erzeugte Wortdikt auf BNLI verwendet werden kann.
Die Verwendung der Skripte ist die folgende (ersetzen Sie das * durch SNLI , MNLI oder BNLI ):
preprocess_*.py [-h] [--config CONFIG]
wobei die config der Pfad zu einer Konfigurationsdatei ist, die die für die Vorverarbeitung verwendeten Parameter definiert. Standardkonfigurationsdateien finden Sie im Ordner Config/Preprocessing dieses Repositorys.
Mit dem Zug _*.
Die Verwendung des Skripts ist die folgende (ersetzen Sie das * durch SNLI oder MNLI ):
train_*.py [-h] [--config CONFIG] [--checkpoint CHECKPOINT]
Dabei config sich um eine Konfigurationsdatei (Standardeinstellungen befinden sich im Konfigurations-/Schulungsordner ), und checkpoint ist ein optionaler Checkpoint, aus dem das Training wieder aufgenommen werden kann. Checkpoints werden vom Skript nach jeder Trainings -Epoche erstellt, wobei der Name ESIM _*. Pth.tar , wobei '*' die Nummer der Epoche angibt.
Der Test _* .
Verwenden Sie zum Testen auf SNLI das Skript test_snli.py wie folgt:
test_snli.py [-h] test_data checkpoint
wobei test_data der Weg zu einem vorverarbeiteten Testsatz ist und der checkpoint der Weg zu einem Kontrollpunkt ist , der von dem Drehbuch des Train_snli.Py erstellt wurde (entweder einer der nach den Trainings -Epochen erstellten Trainingspunkte oder das beste Modell, das während des Trainings zu sehen ist . Kann nicht verwendet werden, um das Training wieder aufzunehmen, da es nicht den Status des Optimierers enthält.
Das Skript test_snli.py kann auch im brechenden NLI -Datensatz mit einem auf SNLI vorgebrachten Modell verwendet werden.
Verwenden Sie zum Testen auf Multinli das Skript test_mnli.py wie folgt:
test_mnli.py [-h] [--config CONFIG] checkpoint
wobei config eine Konfigurationsdatei ist (eine Standardeinstellung ist in config/testing verfügbar) und checkpoint ist ein Checkpoint, der vom Skript train_mnli.py erstellt wird.
Das Skript test_mnli.py macht Vorhersagen in den übereinstimmenden und nicht übereinstimmenden Testsätzen von Multinli und speichert sie in .csv -Dateien. Um die Klassifizierungsgenauigkeit zu den Vorhersagen des Modells zugeordnet zu haben, müssen die. CSV -Dateien, die er erzeugt, an die Kaggle -Wettbewerbe für Multinli eingereicht werden.
Ein auf SNLI vorgebildeter Modell wird im Ordner Daten/Checkpoints/SNLI dieses Repositorys verfügbar gemacht. Das Modell wurde mit den in den in config/ bereitgestellten Standardkonfigurationsdateien bereitgestellten Parametern trainiert. Um es zu testen, führen Sie einfach python test_snli.py ../../preprocessed/SNLI/test_data.pkl ../../data/checkpoints/best.pth.tar aus dem Ordner script/testing aus.
Das vorbereitete Modell erzielt die folgende Leistung im SNLI -Datensatz:
| Teilt | Genauigkeit (%) |
|---|---|
| Zug | 93.2 |
| Dev | 88,4 |
| Prüfen | 88.0 |
Die Ergebnisse stimmen mit denen überein, die Chen et al.
In dem von Glockner et al. Im Jahr 2018 erreicht das Modell eine Genauigkeit von 65,5% , wie in der Arbeit berichtet.
Auf Multinli erreicht das Modell die folgende Genauigkeit:
| Teilt | Angepasst | Nicht übereinstimmend |
|---|---|---|
| Dev | 77,0 % | 76,8 % |
| Prüfen | 76,6 % | 75,8 % |
Diese Ergebnisse liegen leicht über dem, was von Williams et al. in ihrem Multinli -Papier.


