ESIM
1.0.0
자연 언어 추론을위한 ESIM 모델 구현
이 저장소에는 Chen et al.의 논문 "자연 언어 추론을위한 강화 된 LSTM"에 제시된 순차적 모델의 Pytorch와의 구현이 포함되어있다. 2016 년.
아래 그림은 모델 아키텍처에 대한 높은 수준의 관점을 보여줍니다.
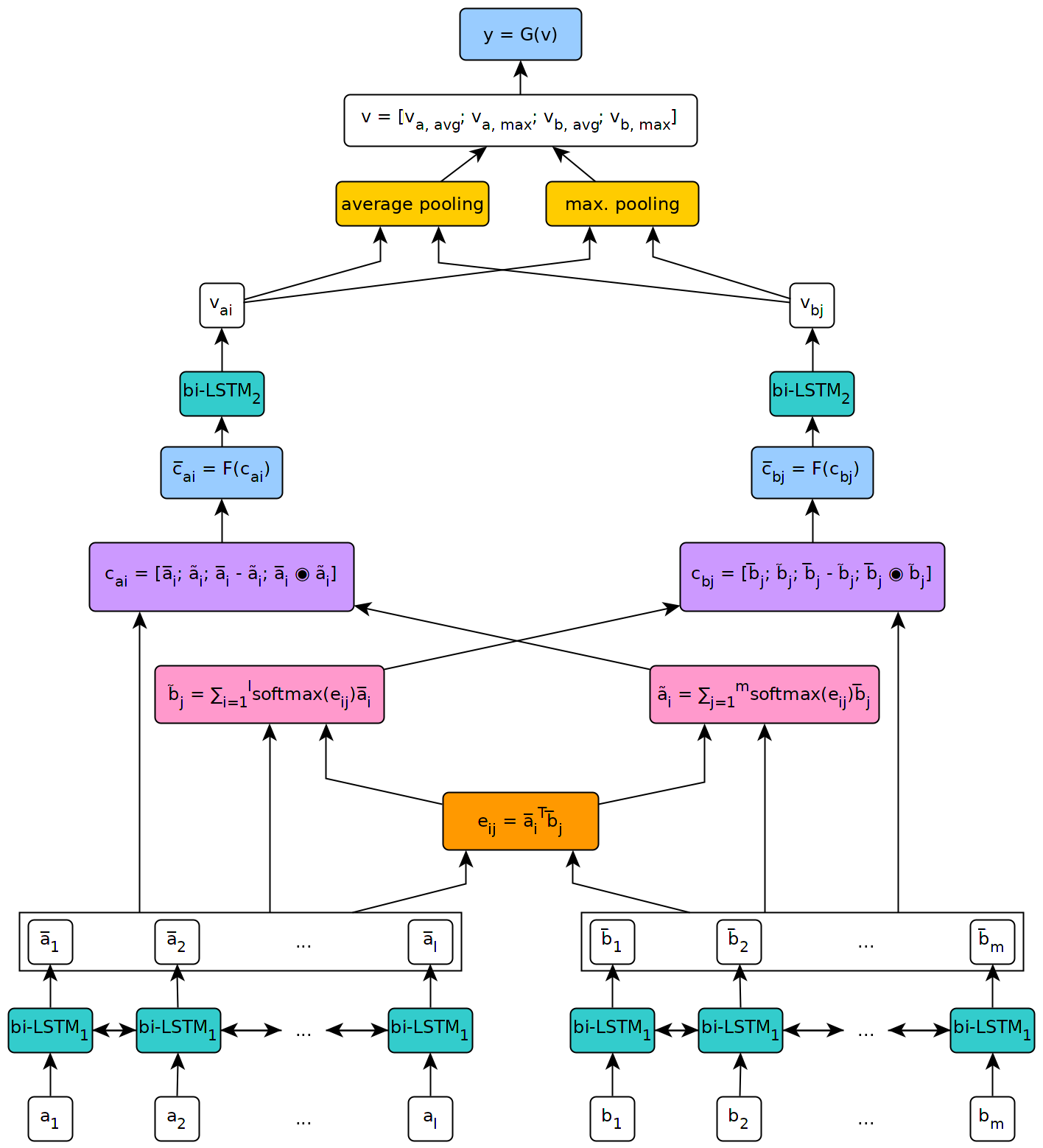
이 모델은 제네바 대학교의 석사 논문의 맥락에서 구현되었습니다.
이 저장소에 정의 된 모델을 사용하려면 먼저 패키지의 공식 페이지에 설명 된 단계를 따라 컴퓨터에 Pytorch를 설치해야합니다 (이 단계는 Windows를 사용하는 경우에만 필요합니다). 그런 다음 모델을 실행하는 데 필요한 종속성을 설치하려면 명령 pip install --upgrade . 복제 된 저장소 내에서 (루트, 바람직하게는 가상 환경 내부)에서.
이 저장소의 스크립트/ 폴더에 위치한 fetch_data.py 스크립트를 사용하여 일부 NLI 데이터 세트 및 전처리 된 단어 임베드를 다운로드 할 수 있습니다. 기본적으로 스크립트는 SNLI 코퍼스와 글러브 840B 300D 임베드를 가져옵니다. 다른 데이터 세트는 스크립트 (예 : Multnli 데이터 세트)로 인수로 URL을 전달하여 다운로드 할 수 있습니다.
스크립트의 사용법은 다음과 같습니다.
fetch_data.py [-h] [--dataset_url DATASET_URL]
[--embeddings_url EMBEDDINGS_URL]
[--target_dir TARGET_DIR]
여기서 target_dir 다운로드 된 데이터를 저장 해야하는 디렉토리로가는 경로입니다 (기본값으로 ../data/ ).
Multinli의 경우 일치 및 일치하지 않는 테스트 세트는 Kaggle에서 수동으로 다운로드하고 Multinli_1.0 데이터 세트 폴더에 복사 된 해당 .txt 파일을 수동으로 다운로드해야합니다.
다운로드 된 코퍼스와 임베딩이 ESIM 모델에 사용되기 전에 전처리해야합니다. 이 저장소의 스크립트/전처리 폴더의 PREPROCESS _*. PY 스크립트로 수행 할 수 있습니다. preprocess_snli.py 스크립트는 snli, preprocess_mnli.py를 preprocess multinli로, preprocess_bnli.py를 전제로 사용하여 NLI (BNLI) 데이터 세트를 전제로 처리하는 데 사용될 수 있습니다. 스크립트 FOT BNLI를 호출 할 때 SNLI 데이터가 먼저 전처리되어야하므로 BNLI에서 생성 된 WordDict를 사용할 수 있습니다.
스크립트의 사용법은 다음과 같습니다 ( *를 snli , mnli 또는 bnli 로 교체) :
preprocess_*.py [-h] [--config CONFIG]
여기서 config 전처리에 사용할 매개 변수를 정의하는 구성 파일의 경로입니다. 기본 구성 파일은이 저장소의 구성/사전 처리 폴더에서 찾을 수 있습니다.
스크립트/교육 폴더의 열차 _*. PY 스크립트를 사용하여 일부 교육 데이터에 대한 ESIM 모델을 교육하고 일부 유효성 검사 데이터에서 검증 할 수 있습니다.
스크립트의 사용법은 다음과 같습니다 ( *를 snli 또는 mnli 로 교체) :
train_*.py [-h] [--config CONFIG] [--checkpoint CHECKPOINT]
config 구성 파일 인 경우 (기본 파일은 구성/교육 폴더에있는 기본 파일), checkpoint 교육을 재개 할 수있는 선택적 체크 포인트입니다. 체크 포인트는 각 훈련 에포크 후 스크립트에 의해 작성되며, ESIM _*. PTH.TAR 이라는 이름은 '*'는 에포크 번호를 나타냅니다.
스크립트/테스트 폴더의 테스트 _*. PY 스크립트를 사용하여 일부 테스트 데이터에서 사전 배치 된 ESIM 모델을 테스트 할 수 있습니다.
SNLI를 테스트하려면 다음과 같이 test_snli.py 스크립트를 사용하십시오.
test_snli.py [-h] test_data checkpoint
test_data 일부 사전 처리 된 테스트 세트의 경로이며, checkpoint 는 Train_Snli.py 스크립트 (Train_Snli.py 스크립트 후 생성 된 체크 포인트 중 하나이거나 교육 중에 보이는 최상의 모델 중 하나이며, 데이터/체크 포인트/snli/best.pth.tar) 에 저장됩니다. 후자는 최적화 상태를 포함하지 않기 때문에 훈련을 재개하는 데 사용될 수 없습니다).
test_snli.py 스크립트는 SNLI에서 프리 트리 된 모델과 함께 NLI 데이터 세트를 깨뜨릴 수 있습니다.
multinli에서 테스트하려면 다음과 같이 test_mnli.py 스크립트를 사용하십시오.
test_mnli.py [-h] [--config CONFIG] checkpoint
config 구성 파일 인 경우 (기본 파일은 구성/테스트 에서 사용할 수 있음) checkpoint 는 Train_Mnli.py 스크립트에서 생성 한 체크 포인트입니다.
test_mnli.py 스크립트는 Multinli의 일치 및 불일치 테스트 세트를 예측하고 .CSV 파일에 저장합니다. 모델의 예측과 관련된 분류 정확도를 얻으려면 생성 된 .CSV 파일은 Multinli의 Kaggle 대회에 제출해야합니다.
SNLI에서 미리 훈련 된 모델은이 저장소의 데이터/체크 포인트/SNLI 폴더에서 사용할 수 있습니다. 모델은 구성/ 에 제공된 기본 구성 파일에 정의 된 매개 변수로 교육을 받았습니다. 테스트하려면 스크립트/테스트 폴더 내에서 python test_snli.py ../../preprocessed/SNLI/test_data.pkl ../../data/checkpoints/best.pth.tar 실행하십시오.
사전 예방 모델은 SNLI 데이터 세트에서 다음과 같은 성능을 달성합니다.
| 나뉘다 | 정확성 (%) |
|---|---|
| 기차 | 93.2 |
| 데브 | 88.4 |
| 시험 | 88.0 |
결과는 Chen et al.
Glockner et al. 2018 년 에이 모델은 논문에서보고 된 바와 같이 65.5% 정확도에 도달합니다.
Multinli에서 모델은 다음과 같은 정확도에 도달합니다.
| 나뉘다 | 일치합니다 | 불일치 |
|---|---|---|
| 데브 | 77.0 % | 76.8 % |
| 시험 | 76.6 % | 75.8 % |
이 결과는 Williams et al. 그들의 멀티 린 종이에서.


